Elements of Financial Engineering Course
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Sentiment Analysis Approach to the Prediction of Market Volatility
A Sentiment Analysis Approach to the Prediction of Market Volatility JUSTINA DEVEIKYTE, Dept. of Computer Science & Information Systems Birkbeck, University of London HELYETTE GEMAN, Dept. of Economics, Mathematics & Statistics Birkbeck, University of London CARLO PICCARI, Dept. of Economics, Mathematics & Statistics Birkbeck, University of London ALESSANDRO PROVETTI, Dept. of Computer Science & Information Systems Birkbeck, University of London Prediction and quantification of future volatility and returns play an important role in financial modelling, both in portfolio optimization and risk management. Natural language processing today allows to process news and social media comments to detect signals of investors’ confidence. We have explored the relationship between sentiment extracted from financial news and tweets and FTSE100 movements. We investigated the strength of the correlation between sentiment measures on a given day and market volatility and returns observed the next day. The findings suggest that there is evidence of correlation between sentiment and stock market movements: the sentiment captured from news headlines could be used as a signal to predict market returns; the same does not apply for volatility. Also, in a surprising finding, for the sentiment found in Twitter comments we obtained a correlation coefficient of -0.7, and p-value below 0.05, which indicates a strong negative correlation between positive sentiment captured from the tweets on a given day and the volatility observed the next day. We developed an accurate classifier for the prediction of market volatility in response to the arrival of new information by deploying topic modelling, based on Latent Dirichlet Allocation, to extract feature vectors from a collection of tweets and financial news. -
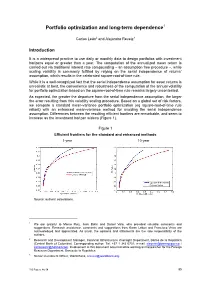
Portfolio Optimization and Long-Term Dependence1
Portfolio optimization and long-term dependence1 Carlos León2 and Alejandro Reveiz3 Introduction It is a widespread practice to use daily or monthly data to design portfolios with investment horizons equal or greater than a year. The computation of the annualized mean return is carried out via traditional interest rate compounding – an assumption free procedure –, while scaling volatility is commonly fulfilled by relying on the serial independence of returns’ assumption, which results in the celebrated square-root-of-time rule. While it is a well-recognized fact that the serial independence assumption for asset returns is unrealistic at best, the convenience and robustness of the computation of the annual volatility for portfolio optimization based on the square-root-of-time rule remains largely uncontested. As expected, the greater the departure from the serial independence assumption, the larger the error resulting from this volatility scaling procedure. Based on a global set of risk factors, we compare a standard mean-variance portfolio optimization (eg square-root-of-time rule reliant) with an enhanced mean-variance method for avoiding the serial independence assumption. Differences between the resulting efficient frontiers are remarkable, and seem to increase as the investment horizon widens (Figure 1). Figure 1 Efficient frontiers for the standard and enhanced methods 1-year 10-year Source: authors’ calculations. 1 We are grateful to Marco Ruíz, Jack Bohn and Daniel Vela, who provided valuable comments and suggestions. Research assistance, comments and suggestions from Karen Leiton and Francisco Vivas are acknowledged and appreciated. As usual, the opinions and statements are the sole responsibility of the authors. -

1 Investor Sentiment and the Market Reaction to Dividend News
Investor sentiment and the market reaction to dividend news: European evidence Abstract Purpose: This paper examines the effect of investor sentiment on the market reaction to dividend change announcements. Design/methodology/approach: We use the European Economic Sentiment Indicator data, from Directorate General for Economic and Financial Affairs (DG ECFIN), as a proxy for investor sentiment and focus on the market reaction to dividend change announcements, using panel data methodology. Findings: Using data from three European markets, our results indicate that the investor sentiment has some influence on the market reaction to dividend change announcements, for two of the three analysed markets. Globally, we find no evidence of investor sentiment influencing the market reaction to dividend change announcements for the Portuguese market. However, we find evidence that the positive share price reaction to dividend increases enlarges with sentiment, in the case of the UK markets, whereas the negative share price reaction to dividend decreases reduces with sentiment, in the French market. Research limitations/implications: We have no access to dividend forecasts, so, our findings are based on naïve dividend changes and not unexpected change dividends. Originality/value: This paper offers some insights on the effect of investor sentiment on the market reaction to firms’ news, a strand of finance that is scarcely developed and contributes to the analysis of European markets that are in need of research. As the best of our knowledge, this is the first study to analyse the effect of investor sentiment on the market reaction to dividend news, in the context of European markets. Key Words: Investor Sentiment, Dividend News, Market Reaction, Behavioural Finance Classification: Research Paper 1 1. -

Do Sentiment Indicators Improve Dynamic Asset Allocation?
EDHEC RISK AND ASSET MANAGEMENT RESEARCH CENTRE 393-400 promenade des Anglais 06202 Nice Cedex 3 Tel.: +33 (0)4 93 18 32 53 E-mail: [email protected] Web: www.edhec-risk.com When to Pick the Losers: Do Sentiment Indicators Improve Dynamic Asset Allocation? October 2006 Devraj Basu EDHEC Business School Chi-Hsiou Hun Durham Business School, University of Durham Roel Oomen Warwick Business School, University of Warwick Alexander Stremme Warwick Business School, University of Warwick Abstract Recent finance research that draws on behavioral psychology suggests that investors systematically make errors in forming expectations about asset returns. These errors are likely to cause significant mis-pricing in the short run, and the subsequent reversion of prices to their fundamental level implies that measures of investor sentiment are likely to be correlated with stock returns. A number of empirical studies using both market and survey data as proxies for investor sentiment have found support for this hypothesis. In this paper we investigate whether investor sentiment (as measured by certain components of the University of Michigan survey) can help improve dynamic asset allocation over and above the improvement achieved based on commonly used business cycle indicators. We find that the addition of sentiment variables to business cycle indicators considerably improves the performance of dynamically managed portfolio strategies, both for a standard market-timer as well as for a momentum investor. For example, sentiment-based dynamic trading strategies, even out-of-sample, would not have incurred any significant losses during the October 1987 crash or the collapse of the dot.com bubble in late 2000. -

The Capital Asset Pricing Model (CAPM) of William Sharpe (1964)
Journal of Economic Perspectives—Volume 18, Number 3—Summer 2004—Pages 25–46 The Capital Asset Pricing Model: Theory and Evidence Eugene F. Fama and Kenneth R. French he capital asset pricing model (CAPM) of William Sharpe (1964) and John Lintner (1965) marks the birth of asset pricing theory (resulting in a T Nobel Prize for Sharpe in 1990). Four decades later, the CAPM is still widely used in applications, such as estimating the cost of capital for firms and evaluating the performance of managed portfolios. It is the centerpiece of MBA investment courses. Indeed, it is often the only asset pricing model taught in these courses.1 The attraction of the CAPM is that it offers powerful and intuitively pleasing predictions about how to measure risk and the relation between expected return and risk. Unfortunately, the empirical record of the model is poor—poor enough to invalidate the way it is used in applications. The CAPM’s empirical problems may reflect theoretical failings, the result of many simplifying assumptions. But they may also be caused by difficulties in implementing valid tests of the model. For example, the CAPM says that the risk of a stock should be measured relative to a compre- hensive “market portfolio” that in principle can include not just traded financial assets, but also consumer durables, real estate and human capital. Even if we take a narrow view of the model and limit its purview to traded financial assets, is it 1 Although every asset pricing model is a capital asset pricing model, the finance profession reserves the acronym CAPM for the specific model of Sharpe (1964), Lintner (1965) and Black (1972) discussed here. -

The Capital Asset Pricing Model (Capm)
THE CAPITAL ASSET PRICING MODEL (CAPM) Investment and Valuation of Firms Juan Jose Garcia Machado WS 2012/2013 November 12, 2012 Fanck Leonard Basiliki Loli Blaž Kralj Vasileios Vlachos Contents 1. CAPM............................................................................................................................................... 3 2. Risk and return trade off ............................................................................................................... 4 Risk ................................................................................................................................................... 4 Correlation....................................................................................................................................... 5 Assumptions Underlying the CAPM ............................................................................................. 5 3. Market portfolio .............................................................................................................................. 5 Portfolio Choice in the CAPM World ........................................................................................... 7 4. CAPITAL MARKET LINE ........................................................................................................... 7 Sharpe ratio & Alpha ................................................................................................................... 10 5. SECURITY MARKET LINE ................................................................................................... -

Sentiment and Speculation in a Market with Heterogeneous Beliefs
Online seminar via Zoom Thursday, September 17, 2020 11:00 am Sentiment and speculation in a market with heterogeneous beliefs Ian Martin Dimitris Papadimitriou∗ April, 2020 Abstract We present a model featuring risk-averse investors with heterogeneous beliefs. Individuals who are correct in hindsight, whether through luck or judgment, be- come relatively wealthy. As a result, market sentiment is bullish following good news and bearish following bad news. Sentiment drives up volatility, and hence also risk premia. In a continuous-time Brownian limit, moderate investors trade against market sentiment in the hope of capturing a variance risk premium created by the presence of extremists. In a Poisson limit that features sudden arrivals of information, CDS rates spike following bad news and decline during quiet times. ∗Martin: London School of Economics, http://personal.lse.ac.uk/martiniw/. Papadimitriou: University of Bristol, https://sites.google.com/site/papadimitrioudea/. We thank Brandon Han, Nobu Kiyotaki, John Moore, Jeremy Stein, Andrei Shleifer, John Campbell, Eben Lazarus, Pe- ter DeMarzo and seminar participants at LSE, Arizona State University, Harvard University, HKUST, Shanghai Jiao Tong University (SAIF) and the NBER Summer Institute for comments. Ian Martin is grateful for support from the Paul Woolley Centre and from the ERC under Starting Grant 639744. 1 In the short run, the market is a voting machine, but in the long run it is a weighing machine. |Benjamin Graham. In this paper, we study the effect of heterogeneity in beliefs on asset prices. We work with a frictionless dynamically complete market populated by a continuum of risk-averse agents who differ in their beliefs about the probability of good news. -

Does Sentiment Matter for Stock Market Returns? Evidence from a Small European Market
Does sentiment matter for stock market returns? Evidence from a small European market Carla Fernandes †1 University of Aveiro Paulo Gama ‡ University of Coimbra/ISR-Coimbra * Elisabete Vieira University of Aveiro/GOVCOPP March, 2010 † Address: ISCA-UA, R. Associação Humanitária dos Bombeiros de Aveiro, Apartado 58, 3811-902 Aveiro, Portugal. Phone: +351 234 380 110 . Fax: +351 234 380 111 . E-mail: [email protected] . ‡ Address: Faculdade de Economia, Av. Dias da Silva, 165, 3004-512 Coimbra, Portugal. Phone: +351 239 790 523. Fax: +351 239 403 511. E-mail: [email protected] . * Address: ISCA-UA, R. Associação Humanitária dos Bombeiros de Aveiro, Apartado 58, 3811-902 Aveiro, Portugal. Phone: +351 234 380 110 . Fax: +351 234 380 111 . E-mail: [email protected] . Does sentiment matter for stock market returns? Evidence from a small European market Abstract An important issue in finance is whether noise traders, those who act on information that has no value, influence prices. Recent research indicates that investor sentiment affects the return distribution of a few categories of assets in some stock markets. Other studies also document that US investor sentiment is contagious. This paper investigates whether Consumer Confidence (CC) and the Economic Sentiment Indicator (ESI) – as proxies for investor sentiment – affects Portuguese stock market returns, at aggregate and industry levels, for the period between 1997 to 2009. Moreover the impact of US investor sentiment on Portuguese stock market returns is also addressed. We find several interesting results. First, our results provide evidence that consumer confidence index and ESI are driven by both, rational and irrational factors. -

“Mean Variance Optimization Via Factor Models in the Emerging Markets: Evidence on the Istanbul Stock Exchange”
“Mean variance optimization via factor models in the emerging markets: evidence on the Istanbul Stock Exchange” AUTHORS Fazıl Gökgöz Fazıl Gökgöz (2009). Mean variance optimization via factor models in the ARTICLE INFO emerging markets: evidence on the Istanbul Stock Exchange. Investment Management and Financial Innovations, 6(3) RELEASED ON Friday, 21 August 2009 JOURNAL "Investment Management and Financial Innovations" FOUNDER LLC “Consulting Publishing Company “Business Perspectives” NUMBER OF REFERENCES NUMBER OF FIGURES NUMBER OF TABLES 0 0 0 © The author(s) 2021. This publication is an open access article. businessperspectives.org Investment Management and Financial Innovations, Volume 6, Issue 3, 2009 Fazil Gökgöz (Turkey) Mean variance optimization via factor models in the emerging markets: evidence on the Istanbul Stock Exchange Abstract Markowitz’s mean-variance analysis, a well known financial optimization technique, has a crucial role for the financial decision makers. This quadratic programming method determines the optimal portfolios within the risk-return perspec- tive. Estimation of the expected returns and the covariances for the financial assets has a significant importance in quantitative portfolio management. The famous financial models used in estimating the input parameters are CAPM, Three Factor Model and Characteristic Model. The goal of this study is to investigate the significance of asset pricing models in the Markowitz’s mean-variance optimization technique for the different Turkish benchmark indices. The optimized risky financial assets have demonstrated higher portfolio risks rather than risky portfolios with risk-free assets. Portfolio risk is found lower for CAPM, Three Factor Model and Characteristics Model, however higher for naive returns. The performances of optimized CAPM portfolios are higher than multi-factor models. -

A Multi-Objective Approach to Portfolio Optimization
Rose-Hulman Undergraduate Mathematics Journal Volume 8 Issue 1 Article 12 A Multi-Objective Approach to Portfolio Optimization Yaoyao Clare Duan Boston College, [email protected] Follow this and additional works at: https://scholar.rose-hulman.edu/rhumj Recommended Citation Duan, Yaoyao Clare (2007) "A Multi-Objective Approach to Portfolio Optimization," Rose-Hulman Undergraduate Mathematics Journal: Vol. 8 : Iss. 1 , Article 12. Available at: https://scholar.rose-hulman.edu/rhumj/vol8/iss1/12 A Multi-objective Approach to Portfolio Optimization Yaoyao Clare Duan, Boston College, Chestnut Hill, MA Abstract: Optimization models play a critical role in determining portfolio strategies for investors. The traditional mean variance optimization approach has only one objective, which fails to meet the demand of investors who have multiple investment objectives. This paper presents a multi- objective approach to portfolio optimization problems. The proposed optimization model simultaneously optimizes portfolio risk and returns for investors and integrates various portfolio optimization models. Optimal portfolio strategy is produced for investors of various risk tolerance. Detailed analysis based on convex optimization and application of the model are provided and compared to the mean variance approach. 1. Introduction to Portfolio Optimization Portfolio optimization plays a critical role in determining portfolio strategies for investors. What investors hope to achieve from portfolio optimization is to maximize portfolio returns and minimize portfolio risk. Since return is compensated based on risk, investors have to balance the risk-return tradeoff for their investments. Therefore, there is no a single optimized portfolio that can satisfy all investors. An optimal portfolio is determined by an investor’s risk-return preference. -

Keynes Meets Markowitz: the Trade-Off Between Familiarity and Diversification
Keynes Meets Markowitz: The Trade-off Between Familiarity and Diversification January 2011 Phelim Boyle, Wilfrid Laurier University Lorenzo Garlappi, University of British Columbia Raman Uppal, EDHEC Business School Tan Wang, University of British Columbia Abstract We develop a model of portfolio choice that nests the views of Keynes—who advocates concentration in a few familiar assets—and Markowitz—who advocates diversification across assets. We rely on the concepts of ambiguity and ambiguity aversion to formalize the idea of an investor's "familiarity" toward assets. The model shows that when an investor is equally ambiguous about all assets, then the optimal portfolio corresponds to Markowitz's fully-diversied portfolio. In contrast, when an investor exhibits different degrees of familiarity across assets, the optimal portfolio depends on (i) the relative degree of ambiguity across assets, and (ii) the standard deviation of the estimate of expected return on each asset. If the standard deviation of the expected return estimate and the difference between the ambiguity about familiar and unfamiliar assets are low, then the optimal portfolio is composed of a mix of both familiar and unfamiliar assets; moreover, an increase in correlation between assets causes an investor to increase concentration in the assets with which they are familiar (flight to familiarity). Alternatively, if the standard deviation of the expected return estimate and the difference in the ambiguity of familiar and unfamiliar assets are high, then the optimal portfolio contains only the familiar asset(s) as Keynes would have advocated. In the extreme case in which the ambiguity about all assets and the standard deviation of the estimated mean are high, then no risky asset is held (non-participation). -

Achieving Portfolio Diversification for Individuals with Low Financial
sustainability Article Achieving Portfolio Diversification for Individuals with Low Financial Sustainability Yongjae Lee 1 , Woo Chang Kim 2 and Jang Ho Kim 3,* 1 Department of Industrial Engineering, Ulsan National Institute of Science and Technology (UNIST), Ulsan 44919, Korea; [email protected] 2 Department of Industrial and Systems Engineering, Korea Advanced Institute of Science and Technology (KAIST), Daejeon 34141, Korea; [email protected] 3 Department of Industrial and Management Systems Engineering, Kyung Hee University, Yongin-si 17104, Gyeonggi-do, Korea * Correspondence: [email protected] Received: 5 August 2020; Accepted: 26 August 2020; Published: 30 August 2020 Abstract: While many individuals make investments to gain financial stability, most individual investors hold under-diversified portfolios that consist of only a few financial assets. Lack of diversification is alarming especially for average individuals because it may result in massive drawdowns in their portfolio returns. In this study, we analyze if it is theoretically feasible to construct fully risk-diversified portfolios even for the small accounts of not-so-rich individuals. In this regard, we formulate an investment size constrained mean-variance portfolio selection problem and investigate the relationship between the investment amount and diversification effect. Keywords: portfolio size; portfolio diversification; individual investor; financial sustainability 1. Introduction Achieving financial sustainability is a basic goal for everyone and it has become a shared concern globally due to increasing life expectancy. Low financial sustainability may refer to individuals with low financial wealth, as well as investors with a lack of financial literacy. Especially for individuals with limited wealth, financial sustainability after retirement is a real concern because of uncertainty in pension plans arising from relatively early retirement age and change in the demographic structure (see, for example, [1,2]).