Essentials of Programming Languages Third Edition Daniel P
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

Hal Abelson Education: Princeton AB (Summa Cum Laude)
Hal Abelson Education: Princeton A.B. (summa cum laude) 1969 MIT Ph.D. (Mathematics) 1973 Professional Appointments: 1994–present MIT Class of 1922 Professor MIT 1991–present Full Professor of Computer Sci. and Eng. MIT 1982–1991 Associate Professor of Electrical Eng. and Computer Sci. MIT 1979–1982 Associate Professor, Dept. of EECS and Division for Study and Res. in Education MIT 1977–1979 Assistant Professor, Dept. of EECS and DSRE MIT 1974–1979 Lecturer, Dept. of Mathematics and DSRE MIT 1974–1979 Instructor, Dept. of Mathematics and DSRE MIT Selected publications relevant to this proposal: 1. “Transparent Accountable Data Mining: New Strategies for Privacy Protection,” with T. Berners- Lee, C. Hanson, J, Hendler, L. Kagal, D. McGuinness, G.J. Sussman, K. Waterman, and D. Weitzner. MIT CSAIL Technical Report, 2006-007, January 2006. 2. “Information Accountability,” with Daniel J. Weitzner, Tim Berners-Lee, Joan Feigenbaum, James Hendler, and Gerald Jay Sussman, MIT CSAIL Technical Report, 2007-034, June 2007. Available at http://hdl.handle.net/1721.1/37600. 3. “The Creation of OpenCourseWare at MIT,” J. Science Education and Technology, May, 2007. 4. Structure and Interpretation of Computer Programs, Hal Abelson, Gerald Jay Sussman and Julie Sussman, MIT Press and McGraw-Hill, 1985, (published translations in French, Polish, Chinese, Japanese, Spanish, and German). Second Edition, 1996. 5. “The Risks of Key Recovery, Key Escrow, and Trusted Third-Party Encryption,” with Ross Ander- son, Steven Bellovin, Josh Benaloh, Matt Blaze, Whitfield Diffie, John Gilmore, Peter Neumann, Ronald Rivest, Jeffrey Schiller, and Bruce Schneier, in World Wide Web Journal, vol. 2, no. -

JHDF5 (HDF5 for Java) 19.04
JHDF5 (HDF5 for Java) 19.04 Introduction HDF5 is an efficient, well-documented, non-proprietary binary data format and library developed and maintained by the HDF Group. The library provided by the HDF Group is written in C and available under a liberal BSD-style Open Source software license. It has over 600 API calls and is very powerful and configurable, but it is not trivial to use. SIS (formerly CISD) has developed an easy-to-use high-level API for HDF5 written in Java and available under the Apache License 2.0 called JHDF5. The API works on top of the low-level API provided by the HDF Group and the files created with the SIS API are fully compatible with HDF5 1.6/1.8/1.10 (as you choose). Table of Content Introduction ................................................................................................................................ 1 Table of Content ...................................................................................................................... 1 Simple Use Case .......................................................................................................................... 2 Overview of the library ............................................................................................................... 2 Numeric Data Types .................................................................................................................... 3 Compound Data Types ................................................................................................................ 4 System -
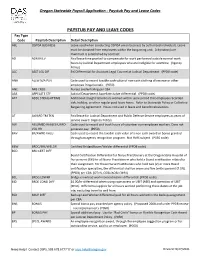
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes PAYSTUB PAY AND LEAVE CODES Pay Type Code Paystub Description Detail Description ABL OSPOA BUSINESS Leave used when conducting OSPOA union business by authorized individuals. Leave must be donated from employees within the bargaining unit. A donation/use maximum is established by contract. AD ADMIN LV Paid leave time granted to compensate for work performed outside normal work hours by Judicial Department employees who are ineligible for overtime. (Agency Policy) ALC ASST LGL DIF 5% Differential for Assistant Legal Counsel at Judicial Department. (PPDB code) ANA ALLW N/A PLN Code used to record taxable cash value of non-cash clothing allowance or other employee fringe benefit. (P050) ANC NRS CRED Nurses credentialing per CBA ASA APPELATE STF Judicial Department Appellate Judge differential. (PPDB code) AST ADDL STRAIGHTTIME Additional straight time hours worked within same period that employee recorded sick, holiday, or other regular paid leave hours. Refer to Statewide Policy or Collective Bargaining Agreement. Hours not used in leave and benefit calculations. AT AWARD TM TKN Paid leave for Judicial Department and Public Defense Service employees as years of service award. (Agency Policy) AW ASSUMED WAGES-UNPD Code used to record and track hours of volunteer non-employee workers. Does not VOL HR generate pay. (P050) BAV BP/AWRD VALU Code used to record the taxable cash value of a non-cash award or bonus granted through an agency recognition program. Not PERS subject. (P050 code) BBW BRDG/BM/WELDR Certified Bridge/Boom/Welder differential (PPDB code) BCD BRD CERT DIFF Board Certification Differential for Nurse Practitioners at the Oregon State Hospital of five percent (5%) for all Nurse Practitioners who hold a Board certification related to their assignment. -

Fostering Learning in the Networked World: the Cyberlearning Opportunity and Challenge
Inquiries or comments on this report may be directed to the National Science Foundation by email to: [email protected] “Any opinions, findings, conclusions and recommendations expressed in this report are those of the Task Force and do not necessarily reflect or represent the views of the National Science Foundation.” Fostering Learning in the Networked World: The Cyberlearning Opportunity and Challenge A 21st Century Agenda for the National Science Foundation1 Report of the NSF Task Force on Cyberlearning June 24, 2008 Christine L. Borgman (Chair), Hal Abelson, Lee Dirks, Roberta Johnson, Kenneth R. Koedinger, Marcia C. Linn, Clifford A. Lynch, Diana G. Oblinger, Roy D. Pea, Katie Salen, Marshall S. Smith, Alex Szalay 1 We would like to acknowledge and give special thanks for the continued support and advice from National Science Foundation staff Daniel Atkins, Cora Marrett, Diana Rhoten, Barbara Olds, and Jim Colby. Andrew Lau of the University of California at Los Angeles provided exceptional help and great spirit in making the distributed work of our Task Force possible. Katherine Lawrence encapsulated the Task Force’s work in a carefully crafted Executive Summary. Fostering Learning in the Networked World: The Cyberlearning Opportunity and Challenge A 21st Century Agenda for the National Science Foundation Science Foundation the National for A 21st Century Agenda Report of the NSF Task Force on Cyberlearning Table of Contents Executive Summary...............................................................................................................................................................................................................................5 -

Small Group Instructional Diagnosis: Final Report
DOCUMENT RESUME JC 820 333 , ED 217 954 AUTHOR Clark, D. Joseph; Redmond, Mark V. TITLE Small Group Instructional Diagnosis: Final Report. INSTITUTION Washington Univ., Seattle. Dept. of Biology c Education. ., 'SPONS AGENCY Fund for the Improwsent of Postsecondary Education . (ED), Washington, D.C. , PUB DATE [82] NOTE 21p.; Appendices mentioned in the report are not _ included. EDRS PRICE , 401/PC01 Plus Postage. DESCRIPTORS *Course Evaluation; *Evaluation Methods; *Instructional Improvement; Postsecondary Education; *Student Evaluation of Teacher Performance;- tudent , Reaction; *Teacher Attitudes; Teacher Workshop IDENTIFIERS *Small group Instructional Diagnosis, ABSTRACT- A procedure for student evaluation andfeedback on faculty instruction was developed at the University of Washington. The system involved the use of,faculty members as facilitatorsin ,conducting Small Group Instructional Diagnosis (SGID) to generate student feedback to instructors about- the courses' strengths, areas needing improvement, and suggestions for bringing about these improvements. The SGID.procedure involves a number of steps:contact between the facilitator and instructor; classroomintervention to ascertain student opinions; a feedback session between facilitator and instructor; instructor. review of the SGID with the class;and ,a follow-up session between the facilitator and instructor.Following the development of the SGID process, handouts andvideotapes were produced to explain the procedure and the SGID technique was demonstrated in over 130 classes -

A Critique of Abelson and Sussman Why Calculating Is Better Than
A critique of Abelson and Sussman - or - Why calculating is better than scheming Philip Wadler Programming Research Group 11 Keble Road Oxford, OX1 3QD Abelson and Sussman is taught [Abelson and Sussman 1985a, b]. Instead of emphasizing a particular programming language, they emphasize standard engineering techniques as they apply to programming. Still, their textbook is intimately tied to the Scheme dialect of Lisp. I believe that the same approach used in their text, if applied to a language such as KRC or Miranda, would result in an even better introduction to programming as an engineering discipline. My belief has strengthened as my experience in teaching with Scheme and with KRC has increased. - This paper contrasts teaching in Scheme to teaching in KRC and Miranda, particularly with reference to Abelson and Sussman's text. Scheme is a "~dly-scoped dialect of Lisp [Steele and Sussman 19781; languages in a similar style are T [Rees and Adams 19821 and Common Lisp [Steele 19821. KRC is a functional language in an equational style [Turner 19811; its successor is Miranda [Turner 1985k languages in a similar style are SASL [Turner 1976, Richards 19841 LML [Augustsson 19841, and Orwell [Wadler 1984bl. (Only readers who know that KRC stands for "Kent Recursive Calculator" will have understood the title of this There are four language features absent in Scheme and present in KRC/Miranda that are important: 1. Pattern-matching. 2. A syntax close to traditional mathematical notation. 3. A static type discipline and user-defined types. 4. Lazy evaluation. KRC and SASL do not have a type discipline, so point 3 applies only to Miranda, Philip Wadhr Why Calculating is Better than Scheming 2 b LML,and Orwell. -

The Computer As a Teaching Tool: Promising Practices. Conference Report (Cambridge, Massachusetts, July 12-13, 1984)
DOCUMENT RESUME ED 295 g'6 IR 013 322 AUTHOR McDonald, Joseph P.; And Others TITLE The Computer as a Teaching Tool: Promising Practices. Conference Report (Cambridge, Massachusetts, July 12-13, 1984). CR85-10. INSTITUTION Educational Technology Center, Cambridge, MA. SPONS AGENCY Education Collaborative for Greater Boston, Inc., Cambridge, Mass. PUB DATE Apr 85 NOTE 25p.; For a report of a related conference, see IR 013 326. PUB TYPE Collected Works - Conference Proceedings (021) -- Reports - Descriptive (141) EDRS PRICE MF01/PC01 Plus Postage. DESCRIPTORS *Computer Assisted Instruction; *Computer Literacy; Computer Simulation; Curriculum Development; Elementrry Secondary Education; *Language Arts; *Mathematics Instruction; Microcomputers; Professional Development; Research Needs; *Science Instruction; Teacher Education; Teacher Role IDENTIFIERS Reality ABSTRACT This report of a 1984 conference on the computer as a teaching tool provides summaries of presentations on the role of the computer in the teaching of science, mathematics, computer literacy, and language arts. Analyses of themes emerging from the conference are then presented under four headings: (1) The Computer and the Curriculum (the computer keeps learning connected to experience; the computer provides access to the underlying disciplines of subjects; the computer challenges the curricular status quo; and the computer aids implementation of the curriculum); (2) The Computer and Reality (computer-based models and simulations only imperfectly represent reality; a program may mask operations that students should experience to give depth and stability to their learning; and computers sometimes need to be used in conjunction with other, more concrete, experiences); (3) Perspectives on Teaching Practice (teaching is rooted in a teacher's own interests, need to understand, and social commitment; and teaching is, to a significant extent, a product of circumstance, not an entirely rational enterprise); and (4) Teachers' Professional Development (strategies and goals are needed for teacher training). -

User Manual for Ox: an Attribute-Grammar Compiling System Based on Yacc, Lex, and C Kurt M
Computer Science Technical Reports Computer Science 12-1992 User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C Kurt M. Bischoff Iowa State University Follow this and additional works at: http://lib.dr.iastate.edu/cs_techreports Part of the Programming Languages and Compilers Commons Recommended Citation Bischoff, Kurt M., "User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C" (1992). Computer Science Technical Reports. 21. http://lib.dr.iastate.edu/cs_techreports/21 This Article is brought to you for free and open access by the Computer Science at Iowa State University Digital Repository. It has been accepted for inclusion in Computer Science Technical Reports by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. User Manual for Ox: An Attribute-Grammar Compiling System based on Yacc, Lex, and C Abstract Ox generalizes the function of Yacc in the way that attribute grammars generalize context-free grammars. Ordinary Yacc and Lex specifications may be augmented with definitions of synthesized and inherited attributes written in C syntax. From these specifications, Ox generates a program that builds and decorates attributed parse trees. Ox accepts a most general class of attribute grammars. The user may specify postdecoration traversals for easy ordering of side effects such as code generation. Ox handles the tedious and error-prone details of writing code for parse-tree management, so its use eases problems of security and maintainability associated with that aspect of translator development. The translators generated by Ox use internal memory management that is often much faster than the common technique of calling malloc once for each parse-tree node. -

Sun 64-Bit Binary Alignment Proposal
1 KMIP 64-bit Binary Alignment Proposal 2 3 To: OASIS KMIP Technical Committee 4 From: Matt Ball, Sun Microsystems, Inc. 5 Date: May 1, 2009 6 Version: 1 7 Purpose: To propose a change to the binary encoding such that each part is aligned to an 8-byte 8 boundary 9 10 Revision History 11 Version 1, 2009-05-01: Initial version 12 Introduction 13 The binary encoding as defined in the 1.0 version of the KMIP draft does not maintain alignment to 8-byte 14 boundaries within the message structure. This causes problems on hard-aligned processors, such as the 15 ARM, that are not able to easily access memory on addresses that are not aligned to 4 bytes. 16 Additionally, it reduces performance on modern 64-bit processors. For hard-aligned processors, when 17 unaligned memory contents are requested, either the compiler has to add extra instructions to perform 18 two aligned memory accesses and reassemble the data, or the processor has to take a „trap‟ (i.e., an 19 interrupt generated on unaligned memory accesses) to correctly assemble the memory contents. Either 20 of these options results in reduced performance. On soft-aligned processors, the hardware has to make 21 two memory accesses instead of one when the contents are not properly aligned. 22 This proposal suggests ways to improve the performance on hard-aligned processors by aligning all data 23 structures to 8-byte boundaries. 24 Summary of Proposed Changes 25 This proposal includes the following changes to the KMIP 0.98 draft submission to the OASIS KMIP TC: 26 Change the alignment of the KMIP binary encoding such that each part is aligned to an 8-byte 27 boundary. -

Making Classes Provable Through Contracts, Models and Frames
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by CiteSeerX DISS. ETH NO. 17610 Making classes provable through contracts, models and frames A dissertation submitted to the SWISS FEDERAL INSTITUTE OF TECHNOLOGY ZURICH (ETH Zurich)¨ for the degree of Doctor of Sciences presented by Bernd Schoeller Diplom-Informatiker, TU Berlin born April 5th, 1974 citizen of Federal Republic of Germany accepted on the recommendation of Prof. Dr. Bertrand Meyer, examiner Prof. Dr. Martin Odersky, co-examiner Prof. Dr. Jonathan S. Ostroff, co-examiner 2007 ABSTRACT Software correctness is a relation between code and a specification of the expected behavior of the software component. Without proper specifica- tions, correct software cannot be defined. The Design by Contract methodology is a way to tightly integrate spec- ifications into software development. It has proved to be a light-weight and at the same time powerful description technique that is accepted by software developers. In its more than 20 years of existence, it has demon- strated many uses: documentation, understanding object-oriented inheri- tance, runtime assertion checking, or fully automated testing. This thesis approaches the formal verification of contracted code. It conducts an analysis of Eiffel and how contracts are expressed in the lan- guage as it is now. It formalizes the programming language providing an operational semantics and a formal list of correctness conditions in terms of this operational semantics. It introduces the concept of axiomatic classes and provides a full library of axiomatic classes, called the mathematical model library to overcome prob- lems of contracts on unbounded data structures. -

Multithreaded Programming Guide
Multithreaded Programming Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 816–5137–10 January 2005 Copyright 2005 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements.