Programming C# 4.0, Sixth Edition by Ian Griffiths, Matthew Adams, and Jesse Liberty
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introducing LINQ 2
Please post comments or corrections to the Author Online forum at http://www.manning-sandbox.com/forum.jspa?forumID=302 MEAP Edition Manning Early Access Program Copyright 2007 Manning Publications For more information on this and other Manning titles go to www.manning.com Please post comments or corrections to the Author Online forum at http://www.manning-sandbox.com/forum.jspa?forumID=302 Contents Part I - Getting started 1. Introducing LINQ 2. C# and VB.NET language enhancements 3. LINQ building blocks - Part II - Querying objects in memory 4. Getting familiar with LINQ to Objects 5. Working with LINQ and DataSets 6. Beyond basic in-memory queries Part III - Manipulating XML 7. Introducing LINQ to XML 8. Querying and transforming XML 9. Common LINQ to XML scenarios Part IV - Mapping objects to relational databases 10. Getting started with LINQ to SQL 11. Retrieving objects efficiently 12. Advanced LINQ to SQL features Part V - LINQing it all together 13. Extending LINQ 14. LINQ in every layer Appendices Appendix A. The standard query operators Appendix B. Quick references for VB 8.0 and C# 2.0 features Features Appendix C. References Appendix D. Resources Please post comments or corrections to the Author Online forum at http://www.manning-sandbox.com/forum.jspa?forumID=302 1 Introducing LINQ Software is simple. It boils down to two things: code and data. Writing software is not so simple, and one of the major activities it involves is programming code to deal with data. To write code, we can choose from a variety of programming languages. -
UNIVERSITY of ENGINEERING & MANAGEMENT,JAIPUR Lecture
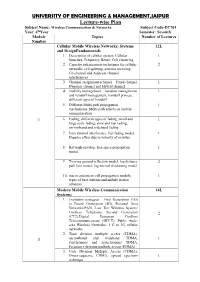
UNIVERSITY OF ENGINEERING & MANAGEMENT,JAIPUR Lecture-wise Plan Subject Name: Wireless Communication & Networks Subject Code-EC701 Year: 4thYear Semester: Seventh Module Topics Number of Lectures Number Cellular Mobile Wireless Networks: Systems 12L and DesignFundamentals 1. Description of cellular system, Cellular 1 Structure, Frequency Reuse, Cell clustering 2. Capacity enhancement techniques for cellular 2 networks, cell splitting, antenna sectoring, Co-channel and Adjacent channel interferences 3. Channel assignment schemes – Fixed channel, 1 Dynamic channel and Hybrid channel 4. mobility management – location management 1 and handoff management, handoff process, different types of handoff 5. Different Multi-path propagation 1 mechanisms, Multi-path effects on mobile communication 1 6. Fading, different types of fading, small and 1 large scale fading, slow and fast fading, narrowband and wideband fading 7. Inter symbol interference, fast fading model, 1 Doppler effect due to velocity of mobiles, 8. Rayleigh envelop, free space propagation 1 model 9. Two ray ground reflection model, log distance 2 path loss model, log normal shadowing model 10. macro and micro cell propagation models, 1 types of base stations and mobile station antennas Modern Mobile Wireless Communication 14L Systems: 1. Evolution strategies – First Generation (1G) to Fourth Generation (4G), Personal Area Networks:PAN, Low Tier Wireless System: Cordless Telephone, Second Generation 2 (CT2),Digital European Cordless Telecommunications (DECT), Public wide- area Wireless Networks: 1 G to 3G cellular networks 2. Time division multiple access (TDMA), 2 narrowband and wideband TDMA, 1 synchronous and asynchronous TDMA, Frequency division multiple access (FDMA) 3. Code Division Multiple Access (CDMA), Direct-sequence CDMA, spread spectrum 1 technique 4. -

The LINQ Project .NET Language Integrated Query May 2006
The LINQ Project .NET Language Integrated Query May 2006 Don Box, Architect, Microsoft Corporation and Anders Hejlsberg, Technical Fellow, Microsoft Corporation Copyright © Microsoft Corporation 2006. All Rights Reserved. .NET Language Integrated Query .NET Language Integrated Query After two decades, the industry has reached a stable point in the evolution of object oriented programming technologies. Programmers now take for granted features like classes, objects, and methods. In looking at the current and next generation of technologies, it has become apparent that the next big challenge in programming technology is to reduce the complexity of accessing and integrating information that is not natively defined using OO technology. The two most common sources of non-OO information are relational databases and XML. Rather than add relational or XML-specific features to our programming languages and runtime, with the LINQ project we have taken a more general approach and are adding general purpose query facilities to the .NET Framework that apply to all sources of information, not just relational or XML data. This facility is called .NET Language Integrated Query (LINQ). We use the term language integrated query to indicate that query is an integrated feature of the developer’s primary programming languages (e.g., C#, Visual Basic). Language integrated query allows query expressions to benefit from the rich metadata, compile- time syntax checking, static typing and IntelliSense that was previously available only to imperative code. Language integrated query also allows a single general purpose declarative query facility to be applied to all in-memory information, not just information from external sources. .NET Language Integrated Query defines a set of general purpose standard query operators that allow traversal, filter, and projection operations to be expressed in a direct yet declarative way in any .NET-based programming language. -

CONCURRENCY EDITOR’S NOTE Simplify Asynchronous Programming with Tasks U.S
THE MICROSOFT JOURNAL FOR DEVELOPERS SEPTEMBER 2010 VOL 25 NO 9 COLUMNS CONCURRENCY EDITOR’S NOTE Simplify Asynchronous Programming with Tasks U.S. Schools Not Getting It Done Igor Ostrovsky . 24 Keith Ward page 4 CUTTING EDGE Throttling Concurrency in the CLR 4.0 ThreadPool Better Web Forms with the Erika Fuentes . 32 MVP Pattern Dino Esposito page 6 Actor-Based Programming with the GOING PLACES Asynchronous Agents Library IronRuby on Windows Phone 7 Michael Chu and Krishnan Varadarajan . 38 Shay Friedman page 16 TEST RUN Request-Response Testing PLUS: Using IronPython James McCaffrey page 79 Migrate Your ASP.NET 1.1 Apps SECURITY BRIEFS to Visual Studio 2010 The MSF-Agile+SDL Process Jonathan Waldman . 50 Template for TFS 2010 Bryan Sullivan page 84 Create a Silverlight 4 Web Part for SharePoint 2010 UI FRONTIERS Paul Stubbs . 64 Touch and Response Charles Petzold page 92 Making MapPoint 2010 and SQL Server DON’T GET ME STARTED Spatial Work Together Weasel Words Eric Frost and Richard Marsden . 70 David Platt page 96 This month at msdn.microsoft.com/magazine: THE WORKING PROGRAMMER Multiparadigmatic .NET, Part 1 Ted Neward Untitled-5 2 3/5/10 10:16 AM Sure, Visual Studio 2010 has a lot of great functionality— we’re excited that it’s only making our User Interface components even better! We’re here to help you go beyond what Visual Studio 2010 gives you so you can create Killer Apps quickly, easily and without breaking a sweat! Go to infragistics.com/beyondthebox today to expand your toolbox with the fastest, best-performing and most powerful UI controls available. -

COPYRIGHTED MATERIAL 54 Summary 56
CONTENTS INTRODUCTION xxxi PART I: LANGUAGE CONSTRUCTS AND ENVIRONMENT CHAPTER 1: VISUAL STUDIO 2012 3 Visual Studio 2012 4 Visual Basic Keywords and Syntax 5 Console Applications 10 Creating a Project from a Project Template 11 The Solution Explorer 14 Project Properties 15 Assembly Information Screen 16 Compiler Settings 18 Debug Properties 21 References 23 Resources 24 Settings 26 Other Project Property Tabs 27 Project ProVB_VS2012 28 Enhancing a Sample Application 31 Customizing the Code 33 Building Applications 44 Running an Application in the Debugger 45 Reusing Your First Windows Form 52 Useful Features of Visual Studio 2012 52 The Task List 52 Server Explorer 53 Class DiagramsCOPYRIGHTED MATERIAL 54 Summary 56 CHAPTER 2: THE COMMON LANGUAGE RUNTIME 57 Framework Profi les and Platforms 58 Client and Full Framework Profi les 59 Framework for Metro 59 Silverlight, Windows Phone, and Others 60 .NET 4.5 Portable Class Library 60 fftoc.inddtoc.indd xxviivii 111/28/20121/28/2012 44:27:36:27:36 PPMM CONTENTS Elements of a .NET Application 61 Types 61 Modules 62 Assemblies 63 Cross-Language Integration 65 The Common Type System 65 Metadata 66 The Refl ection API 69 IL Disassembler 70 Memory Management 71 Traditional Garbage Collection 72 Faster Memory Allocation for Objects 77 Garbage Collector Optimizations 79 Namespaces 81 What Is a Namespace? 81 Namespaces and References 84 Common Namespaces 86 Importing and Aliasing Namespaces 86 Aliasing Namespaces 89 Referencing Namespaces in ASP.NET 89 Creating Your Own Namespaces 90 The My Keyword -

Microsoft Visual Basic 2010 Developer's Handbook
Microsoft Microsoft Visual Basic 2010 Developer's Handbook Klaus Loffelmann Sarika Calla Purohit ble of Contents Foreword xxiii Introduction xxvii I Beginning with Language and Tools 1 Beginners All-Purpose Symbolic Instruction Code 3 Starting Visual Studio for the First Time 4 Console Applications 6 Starting an Application 8 Anatomy of a (Visual Basic) Program 10 Starting Up with the Main Method 12 Methods with and Without Return Values 15 Defining Methods Without Return Values by Using Sub 16 Defining Methods with Return Values by Using Function 16 Declaring Variables 16 Nullables 19 Expressions and Definitions of Variables 21 Defining and Declaring Variables at the Same Time 21 Complex Expressions 22 Boolean Expressions 23 Comparing Objects and Data Types 24 Deriving from Objects and Abstract Objects 25 Properties 26 Type Literal for Determining Constant Types 27 Type Safety 29 Local Type Inference 32 Arrays and Collections 34 What do you think of this book? We want to hear from you! Microsoft is interested in hearing your feedback so we can continually improve our books and learning resources for you. To participate in a brief online survey, please visit: microsoft.com/learning/booksurvey viii Table of Contents Executing Program Code Conditionally 36 36 Else ... Elself ... End If If... Then ... The Logical Operators And, Or, Xor, and Not 37 Comparison Operators That Return Boolean Results 39 Short Circuit Evaluations with OrElse and AndAlso 41 Select 42 Select... Case ... End Loops 44 For... Next Loops 45 47 For ... Each Loops End While 49 Do ... Loop and While ... Loops Exit—Leaving Loops Prematurely 50 Continue—Repeating Loops Prematurely 51 Simplified Access to Object Properties and Methods Using With 51 .. -

EVOLUTIONVOLUTION As Visual Studio 2010 Takes New Form, Will Your User Experience Be Enhanced?
VisualStudioMagazine.com IIDEDE EEVOLUTIONVOLUTION As Visual Studio 2010 takes new form, will your user experience be enhanced? PLUS Build Web Parts with SharePoint Extensions Create Templates with XML Literals, WCF and LINQ Work with Managed Extensibility Framework APRIL 2009 Volume 19, No. 4 APRIL 2009 Volume Project8 3/17/09 12:39 PM Page 1 Be The Master OnAnyPlatform VTC–Virtual Training Center for SharePoint SharePoint is a trademark or a registered trademark of Microsoft Corporation. DataParts is a registered trademark of Software FX, Inc. Other names are trademarks or registered trademarks of their respective owners. Project8 3/17/09 12:40 PM Page 2 Choose A Higher Power For DataVisualization To master the art of data visualization, you must seek out the leader. For nearly 20 years, Software FX has risen above all others by supplying top-of-the-line data visualization tools to enterprise developers working with diverse markets, platforms and environments. This wisdom has evolved into a vast body of products including best-of-breed data presentation solutions, virtual training for SharePoint, and the most powerful selection of data monitoring and analysis components. For a world of software that can raise your work to a higher level, depend on the source that’s clearly on top. Our most popular product, Chart FX allows you to build charts, gauges and maps with additional vertical visualization functionality for business intelligence (OLAP), geographic data, financial technical analysis, and statistical studies and formulas. Recognized for the past 15 years as the innovator and industry leader in charting components, Chart FX delivers incomparable gallery options, aesthetics and data analysis features. -

What's New in the .NET Framework 3.5
http://en.wikipedia.org/wiki/.NET_Framework http://msdn.microsoft.com/en-us/netframework/default.aspx http://en.wikipedia.org/wiki/Silverlight http://silverlight.net/ .NET Framework & Silverlight Platform Overview Marc Schweigert ([email protected]) Principal Developer Evangelist DPE US Federal Government Team http://blogs.msdn.com/devkeydet http://twitter.com/devkeydet The .NET Framework And WPF ASP.NET ADO.NET WCF WF LINQ more! Base Class Libraries The CLR JIT & Garbage Security Exception Loader & NGEN Collector Model Handling Binder A Look Back… SP1 3.5 3.0 .NET 1.0 .NET 1.1 .NET 2.0 .NET 4 2002 2003 2005-08 2009 BETA CLR 1.0 CLR 1.1 CLR 2.0 CLR 4 .NET Framework 1.0 • February 13, 2002 • 1.0.3705.0 • CLR • 1.0 • IL, GC, JIT, CAS, GAC, … • Languages • C# 1.0 - properties, delegates, events • VB.NET (VB7) – OO, threading • Libraries • ASP.NET – web applications and services • WinForms • ADO.NET • Tools • Visual Studio .NET .NET Framework 1.1 • April 3, 2003 • 1.1.4322.573 • CLR • 1.1 • Side-by-side deployment • Partial trust for WinForms and ASP.NET • Languages • No changes • Libraries • ASP.NET – mobile controls • Compact Framework for Windows CE • Tools • Visual Studio 2003 .NET Framework 2.0 • November 7, 2005 • 2.0.50727.42 • CLR • 2.0 • Robustness and hosting API changes for SQL Server 2005 hosting • Generics • 64-bit support • Languages • C# 2.0 and VB.NET (VB8) • Generics, anonymous methods, iterators, partial classes • Libraries • ASP.NET –web parts, master pages, templating, data binding, application building blocks • WinForms -

Visual Basic® 2015 UNLEASHED
Alessandro Del Sole Visual Basic® 2015 UNLEASHED 800 East 96th Street, Indianapolis, Indiana 46240 USA Visual Basic® 2015 Unleashed Editor-in-Chief Copyright © 2016 by Pearson Education, Inc. Greg Wiegand All rights reserved. No part of this book shall be reproduced, stored in a retrieval Acquisitions Editor system, or transmitted by any means, electronic, mechanical, photocopying, record- Joan Murray ing, or otherwise, without written permission from the publisher. No patent liability is assumed with respect to the use of the information contained herein. Although every Development Editor precaution has been taken in the preparation of this book, the publisher and author Mark Renfrow assume no responsibility for errors or omissions. Nor is any liability assumed for damages resulting from the use of the information contained herein. Managing Editor ISBN-13: 978-0-672-33450-4 Kristy Hart ISBN-10: 0-672-33450-X Senior Project Editor Library of Congress Control Number: 2015906633 Betsy Gratner Printed in the United States of America First Printing July 2015 Indexer Tim Wright Trademarks All terms mentioned in this book that are known to be trademarks or service marks have Proofreader been appropriately capitalized. Sams Publishing cannot attest to the accuracy of this Katie Matejka information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. Technical Editors Anthony D. Green Warning and Disclaimer Lucian Wischik Every effort has been made to make this book as complete and as accurate as possible, but no warranty or fitness is implied. The information provided is on an “as Publishing Coordinator is” basis. -

COPYRIGHTED MATERIALXML Data Sets, 370 Administrators Role, 730 Advanced Encryption Standard (AES), 758, ADO
INDEX A common tasks, 372–376 components, 378–380 ABC model, 441–442 connection pooling, 403 abstract base class, 213–215 connection string formats, 380–381 abstract interfaces, 217–225 data providers, 378, 380 abstract method, 214 DataAdapter objects, 389–394 abstraction, 104, 180, 225–227 database structure, 408 access modifi ers, 209 DataException class, 264 access permissions, 722–723 DataReader object, 385–386 ActionLink HTML Helper, 613, 616 DataSet component, 395–401 actions, 605–609, 615, 617–618, 620 DataTable objects, 398–401 Activator class, 714 deleting data, 375–376 Active Database Objects (ADO), 407 design goals, 371 Active Directory, 730 Entity Data Model, 410 ActiveX Data Objects, 369 Entity Framework comparison, 409–410 Adapter, 684 inserting data, 373–374 Add New Item dialog, 641 multi-tiered environments, 371–372 Add Reference dialog, 27, 84 namespaces and classes, 377–378 Add Service Reference dialog, 445–447, .NET data providers, 379–380 456–457 selecting data, 372–373 Add View dialog, 606–607, 610 stored procedures, 382–385 AddHandler, 156, 158–160 transactions, 403–406 lambda expressions, 244 updating data, 374–375 AddressOf, 759 COPYRIGHTED MATERIALXML data sets, 370 Administrators role, 730 Advanced Encryption Standard (AES), 758, ADO. See Active Database Objects 765 ADO.NET, 120, 315, 369, 407 Advanced properties, 548–549 architecture, 371–372 AES. See Advanced Encryption Standard asynchronous command execution, AesCryptoServiceProvider, 744 387–389 AesManaged, 773 basic features, 372–380 AggregateException, 785,