The GPU Computing Revolution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Intel CEO Remarks Pat Gelsinger Q2'21 Earnings Webcast July 22
Intel CEO Remarks Pat Gelsinger Q2’21 Earnings Webcast July 22, 2021 Good afternoon, everyone. Thanks for joining our second-quarter earnings call. It’s a thrilling time for both the semiconductor industry and for Intel. We're seeing unprecedented demand as the digitization of everything is accelerated by the superpowers of AI, pervasive connectivity, cloud-to-edge infrastructure and increasingly ubiquitous compute. Our depth and breadth of software, silicon and platforms, and packaging and process, combined with our at-scale manufacturing, uniquely positions Intel to capitalize on this vast growth opportunity. Our Q2 results, which exceeded our top and bottom line expectations, reflect the strength of the industry, the demand for our products, as well as the superb execution of our factory network. As I’ve said before, we are only in the early innings of what is likely to be a decade of sustained growth across the industry. Our momentum is building as once again we beat expectations and raise our full-year revenue and EPS guidance. Since laying out our IDM 2.0 strategy in March, we feel increasingly confident that we're moving the company forward toward our goal of delivering leadership products in every category in which we compete. While we have work to do, we are making strides to renew our execution machine: 7nm is progressing very well. We’ve launched new innovative products, established Intel Foundry Services, and made operational and organizational changes to lay the foundation needed to win in the next phase of our company’s great history. Here at Intel, we’re proud of our past, pragmatic about the work ahead, but, most importantly, confident in our future. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Recent International Trade Commission Representations
Recent International Trade Commission Representations Certain Mobile Electronic Devices and Radio Frequency and Processing Components Thereof (II), Inv. No. 337-TA-1093 (ITC 2019). Quinn Emanuel was lead counsel for Qualcomm in a patent infringement action against Apple in the International Trade Commission. Qualcomm alleged that Apple engaged in the unlawful importation and sale of iPhones that infringe one or more claims of five Qualcomm patents covering key technologies that enable important features and function in the iPhones. After a seven day hearing, Administrative Law Judge McNamara issued an Initial Determination finding for Qualcomm on all issues related to claim 1 of U.S. Patent 8,063,674 related to an improved “Power on Control” circuit. ALJ McNamara recommended that the Commission issue a limited exclusion order with respect to the accused iPhone devices. Although the case settled shortly after AJ McNamara recommended the exclusion order, the order would have resulted in the exclusion of all iPhones and iPads without Qualcomm baseband processors from being imported into the United States. Certain Magnetic Tape Cartridges and Components Thereof Inv. No. 337-TA-1058 (ITC 2019): We represented Sony in a multifront battle against Fujifilm arising from Fujifilm’s anticompetitive conduct seeking to exclude Sony from the Linear Tape-Open magnetic tape market. LTO tape products are used to store large quantities of data by companies in a wide range of industries, including health care, education, finance and banking. Sony filed a complaint in the ITC seeking an exclusion order of Fujifilm’s products based on its infringement of three Sony patents covering various aspects of magnetic data storage technology. -

PGI Fortran Guide
PGI® User’s Guide Parallel Fortran, C and C++ for Scientists and Engineers The Portland Group® STMicroelectronics Two Centerpointe Drive Lake Oswego, OR 97035 While every precaution has been taken in the preparation of this document, The Portland Group® (PGI®), a wholly-owned subsidiary of STMicroelectronics, Inc., makes no warranty for the use of its products and assumes no responsibility for any errors that may appear, or for damages resulting from the use of the information contained herein. The Portland Group ® retains the right to make changes to this information at any time, without notice. The software described in this document is distributed under license from STMicroelectronics, Inc. and/or The Portland Group® and may be used or copied only in accordance with the terms of the license agreement ("EULA"). No part of this document may be reproduced or transmitted in any form or by any means, for any purpose other than the purchaser's or the end user's personal use without the express written permission of STMicroelectronics, Inc and/or The Portland Group®. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this manual, STMicroelectronics was aware of a trademark claim. The designations have been printed in caps or initial caps. PGF95, PGF90, and PGI Unified Binary are trademarks; and PGI, PGHPF, PGF77, PGCC, PGC++, PGI Visual Fortran, PVF, Cluster Development Kit, PGPROF, PGDBG, and The Portland Group are registered trademarks of The Portland Group Incorporated. PGI CDK is a registered trademark of STMicroelectronics. *Other brands and names are the property of their respective owners. -

Gpus: the Hype, the Reality, and the Future
Uppsala Programming for Multicore Architectures Research Center GPUs: The Hype, The Reality, and The Future David Black-Schaffer Assistant Professor, Department of Informaon Technology Uppsala University David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 2 Today 1. The hype 2. What makes a GPU a GPU? 3. Why are GPUs scaling so well? 4. What are the problems? 5. What’s the Future? David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 3 THE HYPE David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 4 How Good are GPUs? 100x 3x David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 5 Real World SoVware • Press release 10 Nov 2011: – “NVIDIA today announced that four leading applicaons… have added support for mul<ple GPU acceleraon, enabling them to cut simulaon mes from days to hours.” • GROMACS – 2-3x overall – Implicit solvers 10x, PME simulaons 1x • LAMPS – 2-8x for double precision – Up to 15x for mixed • QMCPACK – 3x 2x is AWESOME! Most research claims 5-10%. David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 6 GPUs for Linear Algebra 5 CPUs = 75% of 1 GPU StarPU for MAGMA David Black-Schaffer Uppsala University / Department of Informaon Technology 25/11/2011 | 7 GPUs by the Numbers (Peak and TDP) 5 791 675 4 192 176 3 Intel 32nm vs. 40nm 36% smaller per transistor 2 244 250 3.0 Normalized to Intel 3960X 130 172 51 3.3 2.3 2.4 1 1.5 0.9 0 WaEs GFLOP Bandwidth -
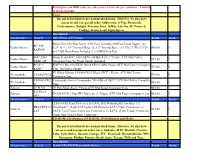
Retail Prices in RED Color Are Sale Prices. Limit One Per Customer
Retail prices in RED color are sale prices. Limit one per customer. Limited to stock on hand. Cases The parts listed below are normal stock items. However, we also have access to and can special order Addtronics, A-Top, Boomrack, Coolermaster, Enlight, Foxconn, Intel, InWin, Lite-On, PC Power & Cooling, Startech and SuperMicro. Description Manufacturer Model# Mid-Tower ATX Cases Retail Stock Black Elite 350 Mid-Tower ATX Case, Includes 500Watt Power Supply, (4) RC-350- Cooler Master 5.25" & (1) 3.5" External Bays, (6) 3.5" Internal Bays, 16.1"Hx7.1"Wx17.9"D, $95.00 3 KKR500 w/2-USB Front Ports, Includes (1) 120MM Rear Fan SGC-2000- Storm Scout SGC-2000-KKN1-GP Black Steel / Plastic ATX Mid Tower Cooler Master $95.00 1 KKN1-GP Computer Case No Power Supply Included RC-912- HAF 912 RC-912-KKN1 Black SECC/ ABS Plastic ATX Mid Tower Computer Cooler Master $75.00 0 KKN1 Case, No Power Supply V3 Black Edition VL80001W2Z Black SECC / Plastic ATX Mid Tower Thermaltake VL80001W2Z $70.00 4 Computer Case VN900A1W2 Commander Series Commander MS-II Black SECC ATX Mid Tower Computer Thermaltake $80.00 1 N Case Zalman Z9 PLUS Z9 Plus Black Steel / Plastic ATX Mid Tower Computer Case $80.00 1 Z11 PLUS Zalman ZALMAN Z11 Plus HF1 Black Steel / Plastic ATX Mid Tower Computer Case $95.00 1 HF1 Manufacturer Model# Retail Stock 2.5in SATA Hard Drive to 3.5in Drive Bay Mounting Kit (Includes 1 x BRACKET25 Combined 7+15 pin SATA plus LP4 Power to SATA Cable Connectors 1x Startech $15.00 7 SAT SATA 7 pin Female Connector Connectors 1x SATA 15 pin Female Connector Connectors 1x LP4 Male Connector) CD-ROM, CD-Burners, DVD-ROM, DVD-Burners and Media The parts listed below are normal stock items. -

The Portland Group
® PGI Compiler User's Guide Parallel Fortran, C and C++ for Scientists and Engineers Release 2011 The Portland Group While every precaution has been taken in the preparation of this document, The Portland Group® (PGI®), a wholly-owned subsidiary of STMicroelectronics, Inc., makes no warranty for the use of its products and assumes no responsibility for any errors that may appear, or for damages resulting from the use of the information contained herein. The Portland Group retains the right to make changes to this information at any time, without notice. The software described in this document is distributed under license from STMicroelectronics and/or The Portland Group and may be used or copied only in accordance with the terms of the end-user license agreement ("EULA"). PGI Workstation, PGI Server, PGI Accelerator, PGF95, PGF90, PGFORTRAN, and PGI Unified Binary are trademarks; and PGI, PGHPF, PGF77, PGCC, PGC++, PGI Visual Fortran, PVF, PGI CDK, Cluster Development Kit, PGPROF, PGDBG, and The Portland Group are registered trademarks of The Portland Group Incorporated. Other brands and names are property of their respective owners. No part of this document may be reproduced or transmitted in any form or by any means, for any purpose other than the purchaser's or the end user's personal use without the express written permission of STMicroelectronics and/or The Portland Group. PGI® Compiler User’s Guide Copyright © 2010-2011 STMicroelectronics, Inc. All rights reserved. Printed in the United States of America First Printing: Release 2011, 11.0, December, 2010 Second Printing: Release 2011, 11.1, January, 2011 Third Printing: Release 2011, 11.2, February, 2011 Fourth Printing: Release 2011, 11.3, March, 2011 Fourth Printing: Release 2011, 11.4, April, 2011 Technical support: [email protected] Sales: [email protected] Web: www.pgroup.com ID: 1196151 Contents Preface ..................................................................................................................................... -

The Portland Group
® PGI Compiler Reference Manual Parallel Fortran, C and C++ for Scientists and Engineers Release 2011 The Portland Group While every precaution has been taken in the preparation of this document, The Portland Group® (PGI®), a wholly-owned subsidiary of STMicroelectronics, Inc., makes no warranty for the use of its products and assumes no responsibility for any errors that may appear, or for damages resulting from the use of the information contained herein. The Portland Group retains the right to make changes to this information at any time, without notice. The software described in this document is distributed under license from STMicroelectronics and/or The Portland Group and may be used or copied only in accordance with the terms of the end-user license agreement ("EULA"). PGI Workstation, PGI Server, PGI Accelerator, PGF95, PGF90, PGFORTRAN, and PGI Unified Binary are trademarks; and PGI, PGHPF, PGF77, PGCC, PGC++, PGI Visual Fortran, PVF, PGI CDK, Cluster Development Kit, PGPROF, PGDBG, and The Portland Group are registered trademarks of The Portland Group Incorporated. Other brands and names are property of their respective owners. No part of this document may be reproduced or transmitted in any form or by any means, for any purpose other than the purchaser's or the end user's personal use without the express written permission of STMicroelectronics and/or The Portland Group. PGI® Compiler Reference Manual Copyright © 2010-2011 STMicroelectronics, Inc. All rights reserved. Printed in the United States of America First printing: Release 2011, 11.0, December, 2010 Second Printing: Release 2011, 11.1, January 2011 Third Printing: Release 2011, 11.3, March 2011 Fourth Printing: Release 2011, 11.4, April 2011 Fifth Printing: Release 2011, 11.5, May 2011 Technical support: [email protected] Sales: [email protected] Web: www.pgroup.com ID: 111162228 Contents Preface ..................................................................................................................................... -

Accelerating Applications with Pattern-Specific Optimizations On
Accelerating Applications with Pattern-specific Optimizations on Accelerators and Coprocessors Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Linchuan Chen, B.S., M.S. Graduate Program in Computer Science and Engineering The Ohio State University 2015 Dissertation Committee: Dr. Gagan Agrawal, Advisor Dr. P. Sadayappan Dr. Feng Qin ⃝c Copyright by Linchuan Chen 2015 Abstract Because of the bottleneck in the increase of clock frequency, multi-cores emerged as a way of improving the overall performance of CPUs. In the recent decade, many-cores begin to play a more and more important role in scientific computing. The highly cost- effective nature of many-cores makes them extremely suitable for data-intensive computa- tions. Specifically, many-cores are in the forms of GPUs (e.g., NVIDIA or AMD GPUs) and more recently, coprocessers (Intel MIC). Even though these highly parallel architec- tures offer significant amount of computation power, it is very hard to program them, and harder to fully exploit the computation power of them. Combing the power of multi-cores and many-cores, i.e., making use of the heterogeneous cores is extremely complicated. Our efforts have been made on performing optimizations to important sets of appli- cations on such parallel systems. We address this issue from the perspective of commu- nication patterns. Scientific applications can be classified based on the properties (com- munication patterns), which have been specified in the Berkeley Dwarfs many years ago. By investigating the characteristics of each class, we are able to derive efficient execution strategies, across different levels of the parallelism. -

NVIDIA Corp NVDA (XNAS)
Morningstar Equity Analyst Report | Report as of 14 Sep 2020 04:02, UTC | Page 1 of 14 NVIDIA Corp NVDA (XNAS) Morningstar Rating Last Price Fair Value Estimate Price/Fair Value Trailing Dividend Yield % Forward Dividend Yield % Market Cap (Bil) Industry Stewardship Q 486.58 USD 250.00 USD 1.95 0.13 0.13 300.22 Semiconductors Exemplary 11 Sep 2020 11 Sep 2020 20 Aug 2020 11 Sep 2020 11 Sep 2020 11 Sep 2020 21:37, UTC 01:27, UTC Morningstar Pillars Analyst Quantitative Important Disclosure: Economic Moat Narrow Wide The conduct of Morningstar’s analysts is governed by Code of Ethics/Code of Conduct Policy, Personal Security Trading Policy (or an equivalent of), Valuation Q Overvalued and Investment Research Policy. For information regarding conflicts of interest, please visit http://global.morningstar.com/equitydisclosures Uncertainty Very High High Financial Health — Moderate Nvidia to Buy ARM in $40 Billion Deal with Eyes Set on Data Center Source: Morningstar Equity Research Dominance; Maintain FVE Quantitative Valuation NVDA Business Strategy and Outlook could limit Nvidia’s future growth. a USA Abhinav Davuluri, CFA, Analyst, 19 August 2020 Undervalued Fairly Valued Overvalued Nvidia is the leading designer of graphics processing units Analyst Note that enhance the visual experience on computing Abhinav Davuluri, CFA, Analyst, 13 September 2020 Current 5-Yr Avg Sector Country Price/Quant Fair Value 1.67 1.43 0.77 0.83 platforms. The firm's chips are used in a variety of end On Sept. 13, Nvidia announced it would acquire ARM from Price/Earnings 89.3 37.0 21.4 20.1 markets, including high-end PCs for gaming, data centers, the SoftBank Group in a transaction valued at $40 billion. -

Intel® Compute Stick STK2M3W64CC STK2MV64CC STK2M364CC Technical Product Specification
Intel® Compute Stick STK2M3W64CC STK2MV64CC STK2M364CC Technical Product Specification October 2017 Order Number: H86345-004 Revision History Revision Revision History Date 001 First release February 2016 002 Updated Section 1.3 Operating System Overview May 2016 003 Updated Section 1.3 Operating System Overview June 2016 004 Updated HDMI audio section October 2017 Disclaimer This product specification applies to only the standard Intel® Compute Stick with BIOS identifier CCSKLM30.86A or CCSKLM5V.86A. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. All Compute Sticks are evaluated as Information Technology Equipment (I.T.E.) for installation in homes, offices, schools, computer rooms, and similar locations. The suitability of this product for other PC or embedded non-PC applications or other environments, such as medical, industrial, alarm systems, test equipment, etc. may not be supported without further evaluation by Intel. Intel Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights that relate to the presented subject matter. -

Content Marketing Members-Only Conference
Content Marketing Members-Only Conference Wednesday, March 12, 2014 | Charles Schwab & Co. Inc. | San Francisco, CA at We’ll be live tweeting throughout the conference (@ANAMarketers), as well as posting photos and other information at facebook.com/ANA. www.ana.net Table of Contents ANA Content Marketing Members-Only Conference at Charles Schwab & Co. Agenda ............................................................................ pg 2 Speaker Bios .................................................................... pg 4 Attendees ........................................................................ pg 7 ANA Member Benefits .....................................................pg 15 www.ana.net 1 Agenda ANA Content Marketing Members-Only Conference at Charles Schwab & Co. WEDNESDAY, MARCH 12, 2014 to expand the opportunity to engage balance different content strategies for consumers and to build brand affinity different types of brands, or measure Breakfast (8:15 a.m.) in a new way that complements tradi- real results? The next five years will see tional advertising. a strategic inflection for marketing and advertising, and content will be at the Helen Loh General Session (9:00 a.m.) core. This session will talk through the Vice President, Content and Digital Marketing business case, the process, the tactics Charles Schwab & Co. Inc. BENJAMIN MOORE USES CONTENT TO and real-life examples of how real CONNECT WITH DIFFERENT AUDIENCE Tami Dorsey brands are using content to drive real SEGMENTS Editorial Director marketing results. Charles Schwab & Co. Inc. Staying true to their namesake’s 130+ Robert Rose Chief Strategist year-old vision, Benjamin Moore & Co. INTEL DEVELOPS A BRANDED Content Marketing Institute is committed to producing the highest CONTENT FORMULA TO ENSURE quality paints and finishes in the indus- try. But marketing to their disparate REPEATED SUCCESS Lunch (12:50 p.m.) target markets (contractors to home- When Intel & Toshiba launched “The owners, as well as designers and archi- Inside Experience” in 2011 it was General Session Cont.