Translation of ER-Diagram Into Relational Schema
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Foreign(Key(Constraints(
Foreign(Key(Constraints( ! Foreign(key:(a(rule(that(a(value(appearing(in(one(rela3on(must( appear(in(the(key(component(of(another(rela3on.( – aka(values(for(certain(a9ributes(must("make(sense."( – Po9er(example:(Every(professor(who(is(listed(as(teaching(a(course(in(the( Courses(rela3on(must(have(an(entry(in(the(Profs(rela3on.( ! How(do(we(express(such(constraints(in(rela3onal(algebra?( ! Consider(the(rela3ons(Courses(crn,(year,(name,(proflast,(…)(and( Profs(last,(first).( ! We(want(to(require(that(every(nonLNULL(value(of(proflast(in( Courses(must(be(a(valid(professor(last(name(in(Profs.( ! RA((πProfLast(Courses)((((((((⊆ π"last(Profs)( 23( Foreign(Key(Constraints(in(SQL( ! We(want(to(require(that(every(nonLNULL(value(of(proflast(in( Courses(must(be(a(valid(professor(last(name(in(Profs.( ! In(Courses,(declare(proflast(to(be(a(foreign(key.( ! CREATE&TABLE&Courses&(& &&&proflast&VARCHAR(8)&REFERENCES&Profs(last),...);& ! CREATE&TABLE&Courses&(& &&&proflast&VARCHAR(8),&...,&& &&&FOREIGN&KEY&proflast&REFERENCES&Profs(last));& 24( Requirements(for(FOREIGN(KEYs( ! If(a(rela3on(R(declares(that(some(of(its(a9ributes(refer( to(foreign(keys(in(another(rela3on(S,(then(these( a9ributes(must(be(declared(UNIQUE(or(PRIMARY(KEY(in( S.( ! Values(of(the(foreign(key(in(R(must(appear(in(the( referenced(a9ributes(of(some(tuple(in(S.( 25( Enforcing(Referen>al(Integrity( ! Three(policies(for(maintaining(referen3al(integrity.( ! Default(policy:(reject(viola3ng(modifica3ons.( ! Cascade(policy:(mimic(changes(to(the(referenced( a9ributes(at(the(foreign(key.( ! SetLNULL(policy:(set(appropriate(a9ributes(to(NULL.( -

Referential Integrity in Sqlite
CS 564: Database Management Systems University of Wisconsin - Madison, Fall 2017 Referential Integrity in SQLite Declaring Referential Integrity (Foreign Key) Constraints Foreign key constraints are used to check referential integrity between tables in a database. Consider, for example, the following two tables: create table Residence ( nameVARCHARPRIMARY KEY, capacityINT ); create table Student ( idINTPRIMARY KEY, firstNameVARCHAR, lastNameVARCHAR, residenceVARCHAR ); We can enforce the constraint that a Student’s residence actually exists by making Student.residence a foreign key that refers to Residence.name. SQLite lets you specify this relationship in several different ways: create table Residence ( nameVARCHARPRIMARY KEY, capacityINT ); create table Student ( idINTPRIMARY KEY, firstNameVARCHAR, lastNameVARCHAR, residenceVARCHAR, FOREIGNKEY(residence) REFERENCES Residence(name) ); or create table Residence ( nameVARCHARPRIMARY KEY, capacityINT ); create table Student ( idINTPRIMARY KEY, firstNameVARCHAR, lastNameVARCHAR, residenceVARCHAR REFERENCES Residence(name) ); or create table Residence ( nameVARCHARPRIMARY KEY, 1 capacityINT ); create table Student ( idINTPRIMARY KEY, firstNameVARCHAR, lastNameVARCHAR, residenceVARCHAR REFERENCES Residence-- Implicitly references the primary key of the Residence table. ); All three forms are valid syntax for specifying the same constraint. Constraint Enforcement There are a number of important things about how referential integrity and foreign keys are handled in SQLite: • The attribute(s) referenced by a foreign key constraint (i.e. Residence.name in the example above) must be declared UNIQUE or as the PRIMARY KEY within their table, but this requirement is checked at run-time, not when constraints are declared. For example, if Residence.name had not been declared as the PRIMARY KEY of its table (or as UNIQUE), the FOREIGN KEY declarations above would still be permitted, but inserting into the Student table would always yield an error. -

Not ACID, Not BASE, but SALT a Transaction Processing Perspective on Blockchains
Not ACID, not BASE, but SALT A Transaction Processing Perspective on Blockchains Stefan Tai, Jacob Eberhardt and Markus Klems Information Systems Engineering, Technische Universitat¨ Berlin fst, je, [email protected] Keywords: SALT, blockchain, decentralized, ACID, BASE, transaction processing Abstract: Traditional ACID transactions, typically supported by relational database management systems, emphasize database consistency. BASE provides a model that trades some consistency for availability, and is typically favored by cloud systems and NoSQL data stores. With the increasing popularity of blockchain technology, another alternative to both ACID and BASE is introduced: SALT. In this keynote paper, we present SALT as a model to explain blockchains and their use in application architecture. We take both, a transaction and a transaction processing systems perspective on the SALT model. From a transactions perspective, SALT is about Sequential, Agreed-on, Ledgered, and Tamper-resistant transaction processing. From a systems perspec- tive, SALT is about decentralized transaction processing systems being Symmetric, Admin-free, Ledgered and Time-consensual. We discuss the importance of these dual perspectives, both, when comparing SALT with ACID and BASE, and when engineering blockchain-based applications. We expect the next-generation of decentralized transactional applications to leverage combinations of all three transaction models. 1 INTRODUCTION against. Using the admittedly contrived acronym of SALT, we characterize blockchain-based transactions There is a common belief that blockchains have the – from a transactions perspective – as Sequential, potential to fundamentally disrupt entire industries. Agreed, Ledgered, and Tamper-resistant, and – from Whether we are talking about financial services, the a systems perspective – as Symmetric, Admin-free, sharing economy, the Internet of Things, or future en- Ledgered, and Time-consensual. -

Data Analysis Expressions (DAX) in Powerpivot for Excel 2010
Data Analysis Expressions (DAX) In PowerPivot for Excel 2010 A. Table of Contents B. Executive Summary ............................................................................................................................... 3 C. Background ........................................................................................................................................... 4 1. PowerPivot ...............................................................................................................................................4 2. PowerPivot for Excel ................................................................................................................................5 3. Samples – Contoso Database ...................................................................................................................8 D. Data Analysis Expressions (DAX) – The Basics ...................................................................................... 9 1. DAX Goals .................................................................................................................................................9 2. DAX Calculations - Calculated Columns and Measures ...........................................................................9 3. DAX Syntax ............................................................................................................................................ 13 4. DAX uses PowerPivot data types ......................................................................................................... -

The Unconstrained Primary Key
IBM Systems Lab Services and Training The Unconstrained Primary Key Dan Cruikshank www.ibm.com/systems/services/labservices © 2009 IBM Corporation In this presentation I build upon the concepts that were presented in my article “The Keys to the Kingdom”. I will discuss how primary and unique keys can be utilized for something other than just RI. In essence, it is about laying the foundation for data centric programming. I hope to convey that by establishing some basic rules the database developer can obtain reasonable performance. The title is an oxymoron, in essence a Primary Key is a constraint, but it is a constraint that gives the database developer more freedom to utilize an extremely powerful relational database management system, what we call DB2 for i. 1 IBM Systems Lab Services and Training Agenda Keys to the Kingdom Exploiting the Primary Key Pagination with ROW_NUMBER Column Ordering Summary 2 www.ibm.com/systems/services/labservices © 2009 IBM Corporation I will review the concepts I introduced in the article “The Keys to the Kingdom” published in the Centerfield. I think this was the inspiration for the picture. I offered a picture of me sitting on the throne, but that was rejected. I will follow this with a discussion on using the primary key as a means for creating peer or subset tables for the purpose of including or excluding rows in a result set. The ROW_NUMBER function is part of the OLAP support functions introduced in 5.4. Here I provide some examples of using ROW_NUMBER with the BETWEEN predicate in order paginate a result set. -

Keys Are, As Their Name Suggests, a Key Part of a Relational Database
The key is defined as the column or attribute of the database table. For example if a table has id, name and address as the column names then each one is known as the key for that table. We can also say that the table has 3 keys as id, name and address. The keys are also used to identify each record in the database table . Primary Key:- • Every database table should have one or more columns designated as the primary key . The value this key holds should be unique for each record in the database. For example, assume we have a table called Employees (SSN- social security No) that contains personnel information for every employee in our firm. We’ need to select an appropriate primary key that would uniquely identify each employee. Primary Key • The primary key must contain unique values, must never be null and uniquely identify each record in the table. • As an example, a student id might be a primary key in a student table, a department code in a table of all departments in an organisation. Unique Key • The UNIQUE constraint uniquely identifies each record in a database table. • Allows Null value. But only one Null value. • A table can have more than one UNIQUE Key Column[s] • A table can have multiple unique keys Differences between Primary Key and Unique Key: • Primary Key 1. A primary key cannot allow null (a primary key cannot be defined on columns that allow nulls). 2. Each table can have only one primary key. • Unique Key 1. A unique key can allow null (a unique key can be defined on columns that allow nulls.) 2. -

Rdbmss Why Use an RDBMS
RDBMSs • Relational Database Management Systems • A way of saving and accessing data on persistent (disk) storage. 51 - RDBMS CSC309 1 Why Use an RDBMS • Data Safety – data is immune to program crashes • Concurrent Access – atomic updates via transactions • Fault Tolerance – replicated dbs for instant failover on machine/disk crashes • Data Integrity – aids to keep data meaningful •Scalability – can handle small/large quantities of data in a uniform manner •Reporting – easy to write SQL programs to generate arbitrary reports 51 - RDBMS CSC309 2 1 Relational Model • First published by E.F. Codd in 1970 • A relational database consists of a collection of tables • A table consists of rows and columns • each row represents a record • each column represents an attribute of the records contained in the table 51 - RDBMS CSC309 3 RDBMS Technology • Client/Server Databases – Oracle, Sybase, MySQL, SQLServer • Personal Databases – Access • Embedded Databases –Pointbase 51 - RDBMS CSC309 4 2 Client/Server Databases client client client processes tcp/ip connections Server disk i/o server process 51 - RDBMS CSC309 5 Inside the Client Process client API application code tcp/ip db library connection to server 51 - RDBMS CSC309 6 3 Pointbase client API application code Pointbase lib. local file system 51 - RDBMS CSC309 7 Microsoft Access Access app Microsoft JET SQL DLL local file system 51 - RDBMS CSC309 8 4 APIs to RDBMSs • All are very similar • A collection of routines designed to – produce and send to the db engine an SQL statement • an original -

MDA Process to Extract the Data Model from Document-Oriented Nosql Database
MDA Process to Extract the Data Model from Document-oriented NoSQL Database Amal Ait Brahim, Rabah Tighilt Ferhat and Gilles Zurfluh Toulouse Institute of Computer Science Research (IRIT), Toulouse Capitole University, Toulouse, France Keywords: Big Data, NoSQL, Model Extraction, Schema Less, MDA, QVT. Abstract: In recent years, the need to use NoSQL systems to store and exploit big data has been steadily increasing. Most of these systems are characterized by the property "schema less" which means absence of the data model when creating a database. This property brings an undeniable flexibility by allowing the evolution of the model during the exploitation of the base. However, query expression requires a precise knowledge of the data model. In this article, we propose a process to automatically extract the physical model from a document- oriented NoSQL database. To do this, we use the Model Driven Architecture (MDA) that provides a formal framework for automatic model transformation. From a NoSQL database, we propose formal transformation rules with QVT to generate the physical model. An experimentation of the extraction process was performed on the case of a medical application. 1 INTRODUCTION however that it is absent in some systems such as Cassandra and Riak TS. The "schema less" property Recently, there has been an explosion of data offers undeniable flexibility by allowing the model to generated and accumulated by more and more evolve easily. For example, the addition of new numerous and diversified computing devices. attributes in an existing line is done without Databases thus constituted are designated by the modifying the other lines of the same type previously expression "Big Data" and are characterized by the stored; something that is not possible with relational so-called "3V" rule (Chen, 2014). -

CHAPTER 3 - Relational Database Modeling
DATABASE SYSTEMS Introduction to Databases and Data Warehouses, Edition 2.0 CHAPTER 3 - Relational Database Modeling Copyright (c) 2020 Nenad Jukic and Prospect Press MAPPING ER DIAGRAMS INTO RELATIONAL SCHEMAS ▪ Once a conceptual ER diagram is constructed, a logical ER diagram is created, and then it is subsequently mapped into a relational schema (collection of relations) Conceptual Model Logical Model Schema Jukić, Vrbsky, Nestorov, Sharma – Database Systems Copyright (c) 2020 Nenad Jukic and Prospect Press Chapter 3 – Slide 2 INTRODUCTION ▪ Relational database model - logical database model that represents a database as a collection of related tables ▪ Relational schema - visual depiction of the relational database model – also called a logical model ▪ Most contemporary commercial DBMS software packages, are relational DBMS (RDBMS) software packages Jukić, Vrbsky, Nestorov, Sharma – Database Systems Copyright (c) 2020 Nenad Jukic and Prospect Press Chapter 3 – Slide 3 INTRODUCTION Terminology Jukić, Vrbsky, Nestorov, Sharma – Database Systems Copyright (c) 2020 Nenad Jukic and Prospect Press Chapter 3 – Slide 4 INTRODUCTION ▪ Relation - table in a relational database • A table containing rows and columns • The main construct in the relational database model • Every relation is a table, not every table is a relation Jukić, Vrbsky, Nestorov, Sharma – Database Systems Copyright (c) 2020 Nenad Jukic and Prospect Press Chapter 3 – Slide 5 INTRODUCTION ▪ Relation - table in a relational database • In order for a table to be a relation the following conditions must hold: o Within one table, each column must have a unique name. o Within one table, each row must be unique. o All values in each column must be from the same (predefined) domain. -

Relational Query Languages
Relational Query Languages Universidad de Concepcion,´ 2014 (Slides adapted from Loreto Bravo, who adapted from Werner Nutt who adapted them from Thomas Eiter and Leonid Libkin) Bases de Datos II 1 Databases A database is • a collection of structured data • along with a set of access and control mechanisms We deal with them every day: • back end of Web sites • telephone billing • bank account information • e-commerce • airline reservation systems, store inventories, library catalogs, . Relational Query Languages Bases de Datos II 2 Data Models: Ingredients • Formalisms to represent information (schemas and their instances), e.g., – relations containing tuples of values – trees with labeled nodes, where leaves contain values – collections of triples (subject, predicate, object) • Languages to query represented information, e.g., – relational algebra, first-order logic, Datalog, Datalog: – tree patterns – graph pattern expressions – SQL, XPath, SPARQL Bases de Datos II 3 • Languages to describe changes of data (updates) Relational Query Languages Questions About Data Models and Queries Given a schema S (of a fixed data model) • is a given structure (FOL interpretation, tree, triple collection) an instance of the schema S? • does S have an instance at all? Given queries Q, Q0 (over the same schema) • what are the answers of Q over a fixed instance I? • given a potential answer a, is a an answer to Q over I? • is there an instance I where Q has an answer? • do Q and Q0 return the same answers over all instances? Relational Query Languages Bases de Datos II 4 Questions About Query Languages Given query languages L, L0 • how difficult is it for queries in L – to evaluate such queries? – to check satisfiability? – to check equivalence? • for every query Q in L, is there a query Q0 in L0 that is equivalent to Q? Bases de Datos II 5 Research Questions About Databases Relational Query Languages • Incompleteness, uncertainty – How can we represent incomplete and uncertain information? – How can we query it? . -

The Relational Data Model and Relational Database Constraints
chapter 33 The Relational Data Model and Relational Database Constraints his chapter opens Part 2 of the book, which covers Trelational databases. The relational data model was first introduced by Ted Codd of IBM Research in 1970 in a classic paper (Codd 1970), and it attracted immediate attention due to its simplicity and mathematical foundation. The model uses the concept of a mathematical relation—which looks somewhat like a table of values—as its basic building block, and has its theoretical basis in set theory and first-order predicate logic. In this chapter we discuss the basic characteristics of the model and its constraints. The first commercial implementations of the relational model became available in the early 1980s, such as the SQL/DS system on the MVS operating system by IBM and the Oracle DBMS. Since then, the model has been implemented in a large num- ber of commercial systems. Current popular relational DBMSs (RDBMSs) include DB2 and Informix Dynamic Server (from IBM), Oracle and Rdb (from Oracle), Sybase DBMS (from Sybase) and SQLServer and Access (from Microsoft). In addi- tion, several open source systems, such as MySQL and PostgreSQL, are available. Because of the importance of the relational model, all of Part 2 is devoted to this model and some of the languages associated with it. In Chapters 4 and 5, we describe the SQL query language, which is the standard for commercial relational DBMSs. Chapter 6 covers the operations of the relational algebra and introduces the relational calculus—these are two formal languages associated with the relational model. -
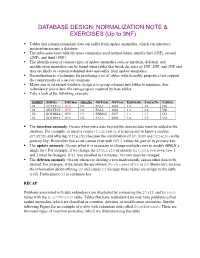
Normalization Exercises
DATABASE DESIGN: NORMALIZATION NOTE & EXERCISES (Up to 3NF) Tables that contain redundant data can suffer from update anomalies, which can introduce inconsistencies into a database. The rules associated with the most commonly used normal forms, namely first (1NF), second (2NF), and third (3NF). The identification of various types of update anomalies such as insertion, deletion, and modification anomalies can be found when tables that break the rules of 1NF, 2NF, and 3NF and they are likely to contain redundant data and suffer from update anomalies. Normalization is a technique for producing a set of tables with desirable properties that support the requirements of a user or company. Major aim of relational database design is to group columns into tables to minimize data redundancy and reduce file storage space required by base tables. Take a look at the following example: StdSSN StdCity StdClass OfferNo OffTerm OffYear EnrGrade CourseNo CrsDesc S1 SEATTLE JUN O1 FALL 2006 3.5 C1 DB S1 SEATTLE JUN O2 FALL 2006 3.3 C2 VB S2 BOTHELL JUN O3 SPRING 2007 3.1 C3 OO S2 BOTHELL JUN O2 FALL 2006 3.4 C2 VB The insertion anomaly: Occurs when extra data beyond the desired data must be added to the database. For example, to insert a course (CourseNo), it is necessary to know a student (StdSSN) and offering (OfferNo) because the combination of StdSSN and OfferNo is the primary key. Remember that a row cannot exist with NULL values for part of its primary key. The update anomaly: Occurs when it is necessary to change multiple rows to modify ONLY a single fact.