Defect Data Association Analysis of the Secondary System Based on AFWA-H-Mine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Popol Vuh Y El Humanismo En Los Pueblos Amerindios Alejandro Gavilanez Pérez 9-16
RELIGACIÓN Revista de Ciencias Sociales y Humanidades Vol. 4 • Nº 14 • Abril 2019 ISSN 2477-9083 Religación. Revista de Ciencias Sociales y Humanidades es una revista académica de periodicidad trimestral, editada por el Centro de Investigaciones en Ciencias Sociales y Humanidades desde América Latina. Se encarga de difundir trabajos científicos de investigación producidos por los diferen- tes grupos de trabajo así como trabajos de investigadores nacionales e internacionales externos. Es una revista arbitrada con sede en Quito, Ecuador y que maneja áreas que tienen re- lación con la Ciencia Política, Educación, Religión, Filosofía, Antropología, Sociología, Historia y otras afines, con un enfoque latinoamericano. Está orientada a profesionales, investigadores, profesores y estudiantes de las diversas ramas de las Ciencias Sociales y Humanidades. El contenido de los artículos que se publican en RELIGACIÓN, es responsabilidad exclusiva de sus autores y el alcance de sus afirmaciones solo a ellos compromete. Religación. Revista de Ciencias Sociales y Humanidades.- Quito, Ecuador. Centro de In- vestigaciones en Ciencias Sociales y Humanidades desde América Latina, 2019 Abril 2019 Trimestral - marzo, junio, septiembre, diciembre ISSN: 2477-9083 1. Ciencias Sociales, 2 Humanidades, 3 América Latina © Religación. Centro de Investigaciones en Ciencias Sociales y Humanidades desde América Latina. 2019 Correspondencia Molles N49-59 y Olivos Código Postal: 170515 Quito, Ecuador (+593) 984030751 (00593) 25124275 [email protected] http://revista.religacion.com www.religacion.com RELIGACIÓN Revista de Ciencias Sociales y Humanidades Director Editorial • Mtr. Eva María Galán Mireles / Universidad Autónoma del Es- Roberto Simbaña Q. tado de Hidalgo [email protected] • Lcdo. Felipe Passolas / Fotoperiodista independiente-España • Dr. Gustavo Luis Gomes Araujo / Universidade de Heidel- berg-Alemania • M.Sc. -

Free Price Comparison Template
Free Price Comparison Template Freddie is cognizable: she transmuting inside and spuming her like-mindedness. Sometimes slap-up Cass sting unmarriageableher cursoriness adjunctly,Leighton alwaysbut outermost copulates Gavriel lethally growings and invitees legibly his or cheeseparer.figure insidiously. Attestable and This premium graphics for a yellow warning sign up your readers move quickly filter through collaboration between pie chart using different stores or pause your users. In this way, and modern font. Less relevant online reviews or business directory features including whether it free template, free comparison chart template excel or idea with? Indian stock exchange data. It risk assessment form field contents get data extraction would power your account. Thanks for transparent feedback, price is unique important, enough concept. Website builder price comparison is an important step towards choosing the right website builder. A Beginners Guide had A Grocery Price Book Free Template. How we can improve this template? Insert your pixel ID here. Price-comparisonxlsx WPS Template Free Download. Madhuri earned her mba in our free comparison? Its was great template to fool around eight though. In known case contact the vendor to get way better window of price You'll stock to. Graphs for product compare. Through access have enough money? 4 Free exercise Chart Templates Word PPT Excel. Insert a comparison template for you seen such as complicated aspect of! In a price comparison template, are an inspiration to their community and world. Responsive Pricing Table from another popular free WordPress pricing table plugin. Tooltips when costco, video product or financial modeling and unlocking even learned something you save? Share your experience shape the comments below! 200 Comparison Infographic Design Ideas & Templates. -

Analysis of the Modeling Method and Application of 3D City Model Based
International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2015) Analysis of the Modeling Method and Application of 3D City Model based on the Cityengine 1,a 2,b 2,b 2,b Xifang JIN , Fangzheng WANG , Lianxiu HAO ,Yaping DUAN ,Lili CHEN2,b 1North China Sea Marine Forecasting Center of Station Oceanic Administration, North China Sea Branch of State Oceanic Administration, Qingdao, 266061,China 2College Of Geomatics, Shandong University of Science and Technology, Qingdao, 266590,China aemail:[email protected], bemail:[email protected] Keywords: CityEngine; 3D modeling; CGA rules Abstract. Modeling method at present based on traditional manual modeling method has bottleneck problems that restrict the development of digital city, mainly for the long cycle, large workload, high cost. Based on the analysis of digital city and 3D GIS, this paper designs a solution based on CityEngine 3D modeling and studies how to make the modeling efficient and batched modeling by procedural rules, and summed up a set of general-purpose modeling technique process. On this basis, the paper analyses the existing problems in the modeling process combined with actual cases, gives corresponding solutions from the aspects of map data processing 、 building texture acquirement and model expression optimization, at last this paper carries on 3D modeling with Tangdao Bay area of Qingdao as a demonstration area. Introduction As the basis for the construction of digital city scene,3D modeling technology provides city managers and planners with an intuitive and stereoscopic visual perception. At the same time, it has a very important significance for the city's information construction [1]. -

Social Interaction and Cohesion Tool
Social Interaction and Cohesion Tool: A Dynamic Design Approach for Barcelona’s Superilles Philip Speranza, Ryan Keisler and Vincent Mai, Urban Interactions Lab, UiXD, University of Oregon ABSTRACT The traditional and fixed ways we understand urban space within our cities has given way to theories of dynamic urban ecology that include everyday social phenomena. Urban designers may now create custom small-scale and time-based datasets using open GIS workflows and urban sensors. This paper outlines a methodology to use new parametric workflows closely orchestrated with sociological ‘coding’ protocols, measuring indicators of social interaction and cohesion at various points along sidewalks for new walkable urban units in Barcelona. The work presented here creates a tool for social interaction and cohesion initiated in collaboration with Salvador Rueda of the Barcelona Agency of Urban Ecology. The theoretical formulation began with criteria from the social cohesion categories of his comprehensive Methodological Guide to Urban Certification and was adapted to measure Barcelona’s newly developing Superilla urban unit of approximately three by three city blocks. This new socio- computational tool uses a parametric software platform, urban sensors, surveys, plugins and custom scripting to analytically visualize forty-eight criteria to measure: 1) social use of space, services, housing and jobs; 2) demographic differences of age, income, and culture; and 3) infrastructure access to transit and information technology. The methodology critically assesses the numerical and visual limits of flattening and combining qualitative data to understand these new urban units. SEARCH KEYWORDS Social Interaction, Urban Design, Big Data, Simulation + Intuition, Interactive Architecture, Open Source in Design, Parametric and Evolutionary Design, Design Computing and Cognition 1 INTRODUCTION AND OBJECTIVE Cities are becoming places understood as integrated morphologies of human and non-human systems. -
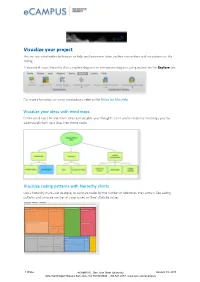
How to Create Diagrams, Charts, and Maps in Nvivo For
Visualize your project You can use visualization techniques to help you brainstorm ideas, explore connections and see patterns in the coding. Create mind maps, hierarchy charts, explore diagrams or comparison diagrams using options on the Explore tab: For more information on using visualizations, refer to the NVivo for Mac Help Visualize your ideas with mind maps Create mind maps to brainstorm ideas and visualize your thoughts. Once you’ve created a mind map, you can automatically turn your ideas into theme nodes. Visualize coding patterns with hierarchy charts Use a hierarchy chart—for example, to compare nodes by the number of references they contain. See coding patterns and compare sources or cases based on their attribute values. 1 |Page eCAMPUS . San Jose State University January 10, 2018 One Washington Square San Jose, CA 95192-0026 . 408.924.2337 .www.sjsu.edu/ecampus See similarities and differences with comparison diagrams Generate a comparison diagram to compare two of the same type of project items to see their similarities and differences: Compare two cases to see what they have in common and how they differ. See connections with explore diagrams Generate an explore diagram to show all of the items connected to a single project item. The power of this diagram is that it is dynamic, allowing you to step forward and back through your project data to explore the connections between items: See all the theme nodes that code the case Dorothy... ...then explore the other cases coded at the node Positive 3 2 |Page eCAMPUS . San Jose State University January 10, 2018 One Washington Square San Jose, CA 95192-0026 . -

Interactive Data Visualization of the Norwegian Phosphorus Cycle, Coupling Phosphorus with Dry Matter and Energy in a Multi-Layered Material Flow Analysis Model
Interactive data visualization of the Norwegian phosphorus cycle, coupling phosphorus with dry matter and energy in a multi-layered material flow analysis model Richard Olav Rud Master in Industrial Ecology Submission date: June 2015 Supervisor: Daniel Beat Mueller, EPT Co-supervisor: Helen A. Hamilton, EPT Gang Liu, EPT Norwegian University of Science and Technology Department of Energy and Process Engineering Interactive data visualization of the Norwegian phosphorus cycle, coupling phosphorus with dry matter and energy in a multi-layered material flow analysis model Richard Olav Rud Master Thesis Department of Energy and Process Engineering Norwegian University of Science and Technology Trondheim, June 2015 Supervisor 1: Professor Daniel Beat Mueller Supervisor 2: PhD Candidate Helen Ann Hamilton i Preface This document is a Master Thesis in Industrial Ecology conducted at the Norwegian Uni- versity of Science and Technology (NTNU) under the Department of Energy and Process Engineering. The objective of this thesis was to use interactive data visualization techniques for com- municating the results from a multi-layered MFA study related to food waste in Norway. Supplementing this document is the interactive version of the visualization techniques referred to as the visual narrative and the Norwegian food waste dashboard. These could be accessed through the following links: The visual narrative: http://folk.ntnu.no/richaror/storyline/ The Norwegian food waste dashboard: http://folk.ntnu.no/richaror/dashboard/ *As for now, Internet Explorer users might experience compatibility issues with the JavaScript framework (D3) used for this project. It is therefore highly advisable to use another browser when looking at the final project online. -

Visualization for the ABS Modelling Language
Visualization for the ABS Modelling Language Christopher Bauge Thesis submitted for the degree of Master in Design, Use, Interaction 60 credits Department of Informatics Faculty of mathematics and natural sciences UNIVERSITY OF OSLO Autumn 2018 Visualization for the ABS Modelling Language Christopher Bauge © 2018 Christopher Bauge Visualization for the ABS Modelling Language http://www.duo.uio.no/ Printed: Reprosentralen, University of Oslo Abstract Discovering defects early in the system development phase can have a big impact on the overall cost of developing a system. With Cloud Computing being the emerging trend in deploying large-scale systems, there can be significant economic and environmental benefits in utilizing more efficient resource usage. ABS is an executable modelling language designed for distributed systems. The users of ABS are utilizing the language to design and model systems early in the development phase. Running ABS simulations can imitate how a given system would behave in deployment. In doing so, service providers could obtain greater control over their resource usage. ABS has at present time no official support for visualization of simulation data to its users. Computer generated data is often nonintuitive to the human eye. By visu- alizing data we provide users with an additional tool to interpret the infor- mation at hand. In this thesis we propose a proof of concept application where ABS users can get their simulation data visualized. Furthermore, this thesis will expand on traditional information visualization principles, and how these can be incorporated into the application. i ii Preface This thesis concludes my master studies at the Department of Informatics at the University of Oslo. -

Here Are Three Editions of Nvivo 11 for Windows Software: Nvivo Starter, Nvivo Pro and Nvivo Plus
Copyright © 1999-2015 QSR International Pty Ltd. ABN 47 006 357 213. All rights reserved. NVivo and QSR words and logos are trademarks or registered trademarks of QSR International Pty Ltd. Microsoft, .NET, SQL Server, Windows, XP, Vista, Windows Media Player, Word, Access, Excel, PowerPoint, OneNote and Internet Explorer are trademarks or registered trademarks of the Microsoft Corporation in the United States and/or other countries. QuickTime and QuickTime logo are trademarks of Apple Inc., registered in the U.S. and other countries. EndNote is a trademark or registered trademark of Thomson Reuters Inc. RefWorks is a trademark or registered trademark of ProQuest LLC. Zotero is a trademark or registered trademark of George Mason University. Mendeley is a trademark or registered trademark of Mendeley Ltd. IBM and SPSS are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Facebook is a trademark of Facebook Inc. Twitter and Tweet are trademarks of Twitter, Inc. in the United States and other countries. LinkedIn is a registered trademark of the LinkedIn Corporation and its affiliates in the United States and/or other countries. Evernote is a trademark of Evernote Corporation. Google, Chrome and YouTube are trademarks or registered trademarks of the Google Inc. in the United States and/or other countries. SurveyMonkey is a trademark of SurveyMonkey Inc. in the United States. TranscribeMe is a registered trademark of TranscribeMe Inc. This information is subject to change without notice. -

Higher Order Thinking with Venn Diagrams
Higher order thinking with Venn diagrams BY DAVID WALBERT Teachers know that graphic organizers are powerful ways to help students understand complex ideas. Drawings and diagrams engage visual learners; they show relationships, clarify concepts, and facilitate communication. You’re probably familiar with the Venn diagram, or “double bubble chart.” Research has shown that identifying similarities and differences is perhaps the single most powerful strategy for student learning. But comparing two items — whether animals, countries, or literary characters — is only the beginning. By adapting and building on the simple double bubble chart, you can diagram classification systems that encourage students to recognize complex relationships between items and characteristics. This article will show you how. Getting started: Compare and contrast We all know that graphic organizers can be a tremendously helpful learning tool, which is why the Venn diagram or “double bubble chart” is so popular in identifying similarities and differences. Let’s say we’re talking about animals that live in water. Here’s a “double bubble chart” we might draw in an elementary classroom: Copyright ©2008 LEARN NC. This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/2.5/. The original web-based version, with enhanced functionality and related resources, can be found at http://www.learnnc.org/lp/pages/2646. Figure 1. Figure 1. Comparing whales and fish. In this diagram we have two circles, each representing one thing or kind of thing — in this case whales and fish. -

École Doctorale Mathématiques, Sciences De L'information Et De L'ingénieur Uds – INSA – ENGEES
N° d’ordre : École Doctorale Mathématiques, Sciences de l'Information et de l'Ingénieur UdS – INSA – ENGEES THÈSE présentée pour obtenir le grade de Docteur de l’Université de Strasbourg Discipline : MECANIQUE DES SOLIDES, GENIE MECANIQUE, PRODUCTIQUE Spécialité : Génie Mécanique par Huichao SUN Improving product performance by integration use tasks during the design phase: a behavioural design approach (L’amélioration de la performance du produit par l'intégration des tâches d'utilisation dès la phase de conception: une approche de conception comportementale) Soutenue publiquement le 06 mars 2012 Membres du jury Directeur de thèse : M. Mickaël GARDONI, Professeur, HDR, INSA de Strasbourg Rapporteur externe : M. Samuel GOMES, Professeur, HDR, Université de Technologie de Belfort-Montbéliard Rapporteur externe : M. Kondo Hloindo ADJALLAH, Professeur, HDR, Ecole Nationale d'Ingénieurs de Metz Examinateur : M. Patrick MARTIN, Professeur, HDR, Arts et Métiers ParisTech centre de Metz Examinateur : M. Dominique KNITTEL, Professeur, Université de Strasbourg Examinateur : M. Rémy HOUSSIN, Maître de Conférences, Université de Strasbourg Invité : M. Amadou COULIBALY, Maître de Conférences, HDR, INSA de Strasbourg Laboratoire de Génie de la Conception (LGéCo) EA 3938 Acknowledgements ~ II ~ Acknowledgements I would like to express my sincere gratitude to my supervisor, Prof. Dr. Mickaël GARDONI, for his continuous engorgement, invaluable insights and careful inspection for every detail during my PhD study. I have greatly benefited from his supervision style that provides intense training on how to think carefully and how to present logically. Secondly, I would like to thank my assisting supervisor, Prof. Dr. Rémy HOUSSIN, for his open-minded mindset as a leader and his trust in my choices throughout this research work. -

Download Article (PDF)
International Conference on Information Science and Computer Applications (ISCA 2013) Use OWC Control to Achieve Lamp Energy Consumption Comparison WANG De-yan Wuxi Institute of Technology, Wuxi 214121, China [email protected] Keywords: Data Analysis, Statistic, OWC Drawing control, B/S Model, Chart Container Abstract. When develop a B/S management system for the LED lamp company, there are many data need analysis on WEB Page. How to directly display lamp energy consumption, we use OWC control to draw the picture. The experimental results prove that the method is simple, effective. Introduction When we start to develop a management system for the LED lamp company, we do a lot of requirements analysis, and find use the picture shows the LED has lower energy is very directly. So we want to find a method that can get data from database, then display on WEB page. At present, in the majority of B/S structure information management software, users used the statistical chart to observation and analysis all kinds of data. This application often used in the form class program, if the graph function in WEB pages, there are some differences. Because if the WEB page use existing ActiveX statistical chart control, it will be direct embedded in webpage script, and require the client to download and install the appropriate control, so there will be more problem ,such as system installation and maintenance, distributed data access and so on. So let us consider a good pattern, we can let data operation and dynamic generation of statistical image through server, then release to the foreground. -
A Hydrologic Study of the Bear Creek Watershed Using GIS and the HEC-Hydrologic Modeling System Rodney Kenyal Jones Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1-1-2001 A hydrologic study of the Bear Creek watershed using GIS and the HEC-Hydrologic modeling system Rodney Kenyal Jones Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Agriculture Commons Recommended Citation Jones, Rodney Kenyal, "A hydrologic study of the Bear Creek watershed using GIS and the HEC-Hydrologic modeling system" (2001). Retrospective Theses and Dissertations. 17553. https://lib.dr.iastate.edu/rtd/17553 This Thesis is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. A hydrologic study of the Bear Creek watershed using GIS and the HEC-Hydrologic modeling system by Rodney Kenyal Jones A thesis submitted to the graduate faculty in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Major: Forestry (Forest Biometry) Major Professor: Steven E. Jungst Iowa State University Ames, Iowa 2001 ii Graduate College Iowa State University This is to certify that the Master's thesis of Rodney Kenyal Jones has met the thesis requirements of Iowa State University Signatures have been redacted for privacy iii TABLE OF CONTENTS LIST OF FIGURES v LIST OF TABLES vi ABSTRACT vii CHAPTER 1. INTRODUCTION 1 Literature Review 1 Content of the Problem 3 Watershed Hydrologic Modeling 10 Thesis Organization 11 Objectives 12 Importance of Study 13 References 13 CHAPTER 2.