Computing Science: Master's Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Advancing Mac OS X Rootkit Detecron
Advancing Mac OS X Rootkit Detec4on Andrew Case (@attrc) Volatility Foundation Golden G. Richard III (@nolaforensix) University of New Orleans 2 hot research areas State of Affairs more established Live Forensics and Tradional Storage Memory Analysis Forensics Digital Forensics Reverse Engineering Incident Response Increasingly encompasses all the others Copyright 2015 by Andrew Case and Golden G. Richard III 3 Where’s the Evidence? Files and Filesystem Applica4on Windows Deleted Files metadata metadata registry Print spool Hibernaon Temp files Log files files files Browser Network Slack space Swap files caches traces RAM: OS and app data Volale Evidence structures Copyright 2015 by Andrew Case and Golden G. Richard III 4 Volale Evidence 1 011 01 1 0 1 111 0 11 0 1 0 1 0 10 0 1 0 1 1 1 0 0 1 0 1 1 0 0 1 Copyright 2015 by Andrew Case and Golden G. Richard III 5 Awesomeness Progression: File Carving Can carve Chaos: files, but More can't Faster Almost not very accurate Hurray! carve files well Tools Manual File type Fragmentaon, appear, MulDthreading, hex editor aware damned but have beer design stuff carving, et al spinning disks! issues Images: hLps://easiersaidblogdotcom.files.wordpress.com/2013/02/hot_dogger.jpg hLp://cdn.bigbangfish.com/555/Cow/Cow-6.jpg, hLp://f.tqn.com/y/bbq/1/W/U/i/Big_green_egg_large.jpg hLp://i5.walmarDmages.com/dfw/dce07b8c-bb22/k2-_95ea6c25-e9aa-418e-a3a2-8e48e62a9d2e.v1.jpg Copyright 2015 by Andrew Case and Golden G. Richard III 6 Awesomeness Progression: Memory Forensics Pioneering Chaos: More, efforts Beyond run more, show great Windows ?? strings? more promise pt_finder et al More aenDon Manual, Mac, … awesome but to malware, run strings, Linux, BSD liLle context limited filling in the gaps funcDonality Images: hLps://s-media-cache-ak0.pinimg.com/736x/75/5a/37/755a37727586c57a19d42caa650d242e.jpg,, hLp://img.photobucket.com/albums/v136/Hell2Pay77/SS-trucks.jpg hLp://skateandannoy.com/wp-content/uploads/2007/12/sportsbars.jpg, hLp://gainesvillescene.com/wp-content/uploads/2013/03/dog-longboard.jpg Copyright 2015 by Andrew Case and Golden G. -

Ultimate++ Forum Probably with These Two Variables You Could Try to Integrate D-BUS
Subject: DBus integration -- need help Posted by jlfranks on Thu, 20 Jul 2017 15:30:07 GMT View Forum Message <> Reply to Message We are trying to add a DBus server to existing large U++ application that runs only on Linux. I've converted from X11 to GTK for Upp project config to be compatible with GIO dbus library. I've created a separate thread for the DBus server and ran into problems with event loop. I've gutted my DBus server code of everything except what is causing an issue. DBus GIO examples use GMainLoop in order for DBus to service asynchronous events. Everything compiles and runs except the main UI is not longer visible. There must be a GTK main loop already running and I've stepped on it with this code. Is there a way for me to obtain a pointer to the UI main loop and use it with my DBus server? How/where can I do that? Code snipped example as follows: ---- code snippet ---- myDBusServerMainThread() { //========================================================== ===== // // Enter main service loop for this thread // while (not needsExit ()) { // colaborate with join() GMainLoop *loop; loop = g_main_loop_new(NULL, FALSE); g_main_loop_run(loop); } } Subject: Re: DBus integration -- need help Posted by Klugier on Thu, 20 Jul 2017 22:30:17 GMT View Forum Message <> Reply to Message Hello, You could try use following methods of Ctrl to obtain gtk & gdk handlers: GdkWindow *gdk() const { return top ? top->window->window : NULL; } GtkWindow *gtk() const { return top ? (GtkWindow *)top->window : NULL; } Page 1 of 3 ---- Generated from Ultimate++ forum Probably with these two variables you could try to integrate D-BUS. -

Fundamentals of Xlib Programming by Examples
Fundamentals of Xlib Programming by Examples by Ross Maloney Contents 1 Introduction 1 1.1 Critic of the available literature . 1 1.2 The Place of the X Protocol . 1 1.3 X Window Programming gotchas . 2 2 Getting started 4 2.1 Basic Xlib programming steps . 5 2.2 Creating a single window . 5 2.2.1 Open connection to the server . 6 2.2.2 Top-level window . 7 2.2.3 Exercises . 10 2.3 Smallest Xlib program to produce a window . 10 2.3.1 Exercises . 10 2.4 A simple but useful X Window program . 11 2.4.1 Exercises . 12 2.5 A moving window . 12 2.5.1 Exercises . 15 2.6 Parts of windows can disappear from view . 16 2.6.1 Testing overlay services available from an X server . 17 2.6.2 Consequences of no server overlay services . 17 2.6.3 Exercises . 23 2.7 Changing a window’s properties . 23 2.8 Content summary . 25 3 Windows and events produce menus 26 3.1 Colour . 26 3.1.1 Exercises . 27 i CONTENTS 3.2 A button to click . 29 3.3 Events . 33 3.3.1 Exercises . 37 3.4 Menus . 37 3.4.1 Text labelled menu buttons . 38 3.4.2 Exercises . 43 3.5 Some events of the mouse . 44 3.6 A mouse behaviour application . 55 3.6.1 Exercises . 58 3.7 Implementing hierarchical menus . 58 3.7.1 Exercises . 67 3.8 Content summary . 67 4 Pixmaps 68 4.1 The pixmap resource . -

Chapter 1. Origins of Mac OS X
1 Chapter 1. Origins of Mac OS X "Most ideas come from previous ideas." Alan Curtis Kay The Mac OS X operating system represents a rather successful coming together of paradigms, ideologies, and technologies that have often resisted each other in the past. A good example is the cordial relationship that exists between the command-line and graphical interfaces in Mac OS X. The system is a result of the trials and tribulations of Apple and NeXT, as well as their user and developer communities. Mac OS X exemplifies how a capable system can result from the direct or indirect efforts of corporations, academic and research communities, the Open Source and Free Software movements, and, of course, individuals. Apple has been around since 1976, and many accounts of its history have been told. If the story of Apple as a company is fascinating, so is the technical history of Apple's operating systems. In this chapter,[1] we will trace the history of Mac OS X, discussing several technologies whose confluence eventually led to the modern-day Apple operating system. [1] This book's accompanying web site (www.osxbook.com) provides a more detailed technical history of all of Apple's operating systems. 1 2 2 1 1.1. Apple's Quest for the[2] Operating System [2] Whereas the word "the" is used here to designate prominence and desirability, it is an interesting coincidence that "THE" was the name of a multiprogramming system described by Edsger W. Dijkstra in a 1968 paper. It was March 1988. The Macintosh had been around for four years. -

Kqueue Madness Have to Ponder These Questions Or Write a Began
Kqueuemadness by Randall Stewart ome time ago I was asked to participate in the creation of a Performance SEnhancing Proxy (PEP) for TCP. The concept behind a PEP is to split a TCP connec- tion into three separate connections. The first connection (1) is the normal TCP con- nection that goes from the client towards the server (the client is usually unaware that its connection is not going to the end server). The next connection (2) goes between two middle boxes (M1 and M2), the first middle box (M1) terminates the connection of the client pretending to be the server and uses a different connection to talk to the tail middle box (M2). This middle connection provides the “enhanced” service to the end-to-end connection. The final connection (3) goes between the tail middle box (M2) and the actual server. The figure below shows a diagram of such a connection. A connection (1) (2) (3) through a PEP Client M1 M2 Server 24 FreeBSD Journal Now, as you can imagine, if you have a very event for a socket descriptor, yet do not close busy PEP you could end up with thousands of the socket? TCP connections being managed by M1 and b) Could I possibly see stale queued events M2. In such an environment using poll(2) or that were yet to be read? select(2) comes with an extreme penalty. Each c) How does connect interact with kqueue? time a I/O event completes, every one of those d) What about listen? thousands of connections would need to be e) What is the difference between all of the looked at to see if an event occurred on them, kqueue flags that I can add on to events and and then the appropriate structure would need when do I use them properly? to be reset to look for an event next time. -

Efficient Parallel I/O on Multi-Core Architectures
Lecture series title/ lecture title Efficient parallel I/O on multi-core architectures Adrien Devresse CERN IT-SDC-ID Thematic CERN School of Computing 2014 1 Author(s) names – Affiliation Lecture series title/ lecture title How to make I/O bound application scale with multi-core ? What is an IO bound application ? → A server application → A job that accesses big number of files → An application that uses intensively network 2 Author(s) names – Affiliation Lecture series title/ lecture title Stupid example: Simple server monothreaded // create socket socket_desc = socket(AF_INET , SOCK_STREAM , 0); // bind the socket bind(socket_desc,(struct sockaddr *)&server , sizeof(server)); listen(socket_desc , 100); //accept connection from an incoming client while(1){ // declarations client_sock = accept(socket_desc, (struct sockaddr *)&client, &c); //Receive a message from client while( (read_size = recv(client_sock , client_message , 2000 , 0)) > 0{ // Wonderful, we have a client, do some useful work std::string msg("hello bob"); write(client_sock, msg.c_str(), msg.size()); } } 3 Author(s) names – Affiliation Lecture series title/ lecture title Stupid example: Let's make it parallel ! int main(int argc, char** argv){ // creat socket void do_work(int socket){ socket_desc = socket(AF_INET , SOCK_STREAM , 0); //Receive a message while( (read_size = // bind the socket recv(client_sock , bind(socket_desc, server , sizeof(server)); client_message , 2000 , 0)) > 0{ listen(socket_desc , 100); // Wonderful, we have a client // useful works //accept connection -
Mac OS X for UNIX Users the Power of UNIX with the Simplicity of Macintosh
Mac OS X for UNIX Users The power of UNIX with the simplicity of Macintosh. Features Mac OS X version 10.3 “Panther” combines a robust and open UNIX-based foundation with the richness and usability of the Macintosh interface, bringing UNIX technology Open source, standards-based UNIX to the mass market. Apple has made open source and standards a key part of its foundation strategy and delivers an operating system built on a powerful UNIX-based foundation •Based on FreeBSD 5 and Mach 3.0 • Support for POSIX, Linux, and System V APIs that is innovative and easy to use. • High-performance math libraries, including There are over 8.5 million Mac OS X users, including scientists, animators, developers, vector/DSP and PowerPC G5 support and system administrators, making Mac OS X the most widely used UNIX-based desktop • Optimized X11 window server for UNIX GUIs operating system. In addition, Mac OS X is the only UNIX-based environment that •Open source code available via the natively runs Microsoft Office, Adobe Photoshop, and thousands of other consumer Darwin project applications—all side by side with traditional command-line, X11, and Java applications. Standards-based networking For notebook computer users, Mac OS X delivers full power management and mobility •Open source TCP/IP-based networking support for Apple’s award-winning PowerBook G4. architecture, including IPv4, IPv6, and L2TP/IPSec •Interoperability with NFS, AFP, and Windows (SMB/CIFS) file servers •Powerful web server (Apache) •Open Directory 2, an LDAP-based directory services -
Introduction to Asynchronous Programming
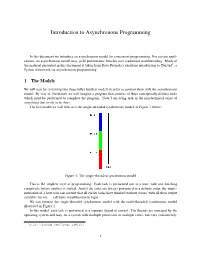
Introduction to Asynchronous Programming In this document we introduce an asynchronous model for concurrent programming. For certain appli- cations, an asynchronous model may yield performance benefits over traditional multithreading. Much of the material presented in this document is taken from Dave Peticola’s excellent introduction to Twisted1, a Python framework for asynchronous programming. 1 The Models We will start by reviewing two (hopefully) familiar models in order to contrast them with the asynchronous model. By way of illustration we will imagine a program that consists of three conceptually distinct tasks which must be performed to complete the program. Note I am using task in the non-technical sense of something that needs to be done. The first model we will look at is the single-threaded synchronous model, in Figure 1 below: Figure 1: The single-threaded synchronous model This is the simplest style of programming. Each task is performed one at a time, with one finishing completely before another is started. And if the tasks are always performed in a definite order, the imple- mentation of a later task can assume that all earlier tasks have finished without errors, with all their output available for use — a definite simplification in logic. We can contrast the single-threaded synchronous model with the multi-threaded synchronous model illustrated in Figure 2. In this model, each task is performed in a separate thread of control. The threads are managed by the operating system and may, on a system with multiple processors or multiple cores, run truly concurrently, 1http://krondo.com/?page_id=1327 1 CS168 Async Programming Figure 2: The threaded model or may be interleaved together on a single processor. -

Fsmonitor: Scalable File System Monitoring for Arbitrary Storage Systems
FSMonitor: Scalable File System Monitoring for Arbitrary Storage Systems Arnab K. Paul∗, Ryan Chardy, Kyle Chardz, Steven Tueckez, Ali R. Butt∗, Ian Fostery;z ∗Virginia Tech, yArgonne National Laboratory, zUniversity of Chicago fakpaul, [email protected], frchard, [email protected], fchard, [email protected] Abstract—Data automation, monitoring, and management enable programmatic management, and even autonomously tools are reliant on being able to detect, report, and respond manage the health of the system. Enabling scalable, reliable, to file system events. Various data event reporting tools exist for and standardized event detection and reporting will also be of specific operating systems and storage devices, such as inotify for Linux, kqueue for BSD, and FSEvents for macOS. How- value to a range of infrastructures and tools, such as Software ever, these tools are not designed to monitor distributed file Defined CyberInfrastructure (SDCI) [14], auditing [9], and systems. Indeed, many cannot scale to monitor many thousands automating analytical pipelines [11]. Such systems enable of directories, or simply cannot be applied to distributed file automation by allowing programs to respond to file events systems. Moreover, each tool implements a custom API and and initiate tasks. event representation, making the development of generalized and portable event-based applications challenging. As file systems Most storage systems provide mechanisms to detect and grow in size and become increasingly diverse, there is a need report data events, such as file creation, modification, and for scalable monitoring solutions that can be applied to a wide deletion. Tools such as inotify [20], kqueue [18], and FileSys- range of both distributed and local systems. -

Qcontext, and Supporting Multiple Event Loop Threads in QEMU
IBM Linux Technology Center QContext, and Supporting Multiple Event Loop Threads in QEMU Michael Roth [email protected] © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . Historically (earlier this year), there were 2 main types of threads in QEMU: . vcpu threads – handle execution of guest code, and emulation of hardware access (pio/mmio) and other trapped instructions . QEMU main loop (iothread) – everything else (mostly) GTK/SDL/VNC UIs QMP/HMP management interfaces Clock updates/timer callbacks for devices device I/O on behalf of vcpus © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . All core qemu code protected by global mutex . vcpu threads in KVM_RUN can run concurrently thanks to address space isolation, but attempt to acquire global mutex immediately after an exit . Iothread requires global mutex whenever it's active © 2006 IBM Corporation IBM Linux Technology Center High contention as threads or I/O scale vcpu 1 vcpu 2 vcpu n iothread . © 2006 IBM Corporation IBM Linux Technology Center QEMU Thread Types . vcpu threads . iothread . virtio-blk-dataplane thread Drives a per-device AioContext via aio_poll Handles event fd callbacks for virtio-blk virtqueue notifications and linux_aio completions Uses port of vhost's vring code, doesn't (currently) use core QEMU code, doesn't require global mutex Will eventually re-use QEMU block layer code © 2006 IBM Corporation IBM Linux Technology Center QEMU Block Layer Features . Multiple image format support . Snapshots . Live Block Copy . Live Block migration . Drive-mirroring . Disk I/O limits . Etc... © 2006 IBM Corporation IBM Linux Technology Center More dataplane in the future . -

The Design and Use of the ACE Reactor an Object-Oriented Framework for Event Demultiplexing
The Design and Use of the ACE Reactor An Object-Oriented Framework for Event Demultiplexing Douglas C. Schmidt and Irfan Pyarali g fschmidt,irfan @cs.wustl.edu Department of Computer Science Washington University, St. Louis 631301 1 Introduction create concrete event handlers by inheriting from the ACE Event Handler base class. This class specifies vir- This article describes the design and implementation of the tual methods that handle various types of events, such as Reactor pattern [1] contained in the ACE framework [2]. The I/O events, timer events, signals, and synchronization events. Reactor pattern handles service requests that are delivered Applications that use the Reactor framework create concrete concurrently to an application by one or more clients. Each event handlers and register them with the ACE Reactor. service of the application is implemented by a separate event Figure 1 shows the key components in the ACE Reactor. handler that contains one or more methods responsible for This figure depicts concrete event handlers that implement processing service-specific requests. In the implementation of the Reactor pattern described in this paper, event handler dispatching is performed REGISTERED 2: accept() by an ACE Reactor.TheACE Reactor combines OBJECTS 5: recv(request) 3: make_handler() the demultiplexing of input and output (I/O) events with 6: process(request) other types of events, such as timers and signals. At Logging Logging Logging Logging Handler Acceptor LEVEL thecoreoftheACE Reactor implementation is a syn- LEVEL Handler Handler chronous event demultiplexer, such as select [3] or APPLICATION APPLICATION Event Event WaitForMultipleObjects [4]. When the demulti- Event Event Handler Handler Handler plexer indicates the occurrence of designated events, the Handler ACE Reactor automatically dispatches the method(s) of 4: handle_input() 1: handle_input() pre-registered event handlers, which perform application- specified services in response to the events.