Evidence Collection for Forensic Investigation in Peer to Peer Systems Sai Giri Teja Myneedu Iowa State University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Security Analytics 8.1.X Reference Guide
Security Analytics 8.1.x Reference Guide Updated: Friday, November 15, 2019 Security Analytics Reference Guide Security Analytics 8.1 Copyrights, Trademarks, and Intellectual Property Copyright © 2019 Symantec Corp. All rights reserved. Symantec, the Symantec Logo, the Checkmark Logo, Blue Coat, and the Blue Coat logo are trademarks or registered trademarks of Symantec Corp. or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This document is provided for informational purposes only and is not intended as advertising. All warranties relating to the information in this document, either express or implied, are disclaimed to the maximum extent allowed by law. The information in this document is subject to change without notice. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. SYMANTEC CORPORATION PRODUCTS, TECHNICAL SERVICES, AND ANY OTHER TECHNICAL DATA REFERENCED IN THIS DOCUMENT ARE SUBJECT TO U.S. EXPORT CONTROL AND SANCTIONS LAWS, REGULATIONS AND REQUIREMENTS, AND MAY BE SUBJECT TO EXPORT OR IMPORT REGULATIONS IN OTHER COUNTRIES. YOU AGREE TO COMPLY STRICTLY WITH THESE LAWS, REGULATIONS AND REQUIREMENTS, AND ACKNOWLEDGE THAT YOU HAVE THE RESPONSIBILITY TO OBTAIN ANY LICENSES, PERMITS OR OTHER APPROVALS THAT MAY BE REQUIRED IN ORDER TO EXPORT, RE-EXPORT, TRANSFER IN COUNTRY OR IMPORT AFTER DELIVERY TO YOU. -

Looking up Data in P2p Systems
LOOKING UP DATA IN P2P SYSTEMS Hari Balakrishnan, M. Frans Kaashoek, David Karger, Robert Morris, Ion Stoica∗ MIT Laboratory for Computer Science 1. Introduction a good example of how the challenges of designing P2P systems The recent success of some widely deployed peer-to-peer (P2P) can be addressed. file sharing applications has sparked new research in this area. We The recent algorithms developed by several research groups for are interested in the P2P systems that have no centralized control the lookup problem present a simple and general interface, a dis- or hierarchical organization, where the software running at each tributed hash table (DHT). Data items are inserted in a DHT and node is equivalent in functionality. Because these completely de- found by specifying a unique key for that data. To implement a centralized systems have the potential to significantly change the DHT, the underlying algorithm must be able to determine which way large-scale distributed systems are built in the future, it seems node is responsible for storing the data associated with any given timely to review some of this recent research. key. To solve this problem, each node maintains information (e.g., The main challenge in P2P computing is to design and imple- the IP address) of a small number of other nodes (“neighbors”) in ment a robust distributed system composed of inexpensive com- the system, forming an overlay network and routing messages in puters in unrelated administrative domains. The participants in a the overlay to store and retrieve keys. typical P2P system might be home computers with cable modem One might believe from recent news items that P2P systems are or DSL links to the Internet, as well as computers in enterprises. -

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

What Is Peer-To-Peer File Transfer? Bandwidth It Can Use
sharing, with no cap on the amount of commonly used to trade copyrighted music What is Peer-to-Peer file transfer? bandwidth it can use. Thus, a single NSF PC and software. connected to NSF’s LAN with a standard The Recording Industry Association of A peer-to-peer, or “P2P,” file transfer 100Mbps network card could, with KaZaA’s America tracks users of this software and has service allows the user to share computer files default settings, conceivably saturate NSF’s begun initiating lawsuits against individuals through the Internet. Examples of P2P T3 (45Mbps) internet connection. who use P2P systems to steal copyrighted services include KaZaA, Grokster, Gnutella, The KaZaA software assesses the quality of material or to provide copyrighted software to Morpheus, and BearShare. the PC’s internet connection and designates others to download freely. These services are set up to allow users to computers with high-speed connections as search for and download files to their “Supernodes,” meaning that they provide a How does use of these services computers, and to enable users to make files hub between various users, a source of available for others to download from their information about files available on other create security issues at NSF? computers. users’ PCs. This uses much more of the When configuring these services, it is computer’s resources, including bandwidth possible to designate as “shared” not only the and processing capability. How do these services function? one folder KaZaA sets up by default, but also The free version of KaZaA is supported by the entire contents of the user’s computer as Peer to peer file transfer services are highly advertising, which appears on the user well as any NSF network drives to which the decentralized, creating a network of linked interface of the program and also causes pop- user has access, to be searchable and users. -
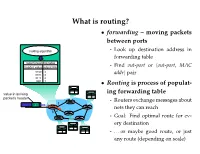
What Is Routing?
What is routing? • forwarding – moving packets between ports - Look up destination address in forwarding table - Find out-port or hout-port, MAC addri pair • Routing is process of populat- ing forwarding table - Routers exchange messages about nets they can reach - Goal: Find optimal route for ev- ery destination - . or maybe good route, or just any route (depending on scale) Routing algorithm properties • Static vs. dynamic - Static: routes change slowly over time - Dynamic: automatically adjust to quickly changing network conditions • Global vs. decentralized - Global: All routers have complete topology - Decentralized: Only know neighbors & what they tell you • Intra-domain vs. Inter-domain routing - Intra-: All routers under same administrative control - Intra-: Scale to ∼100 networks (e.g., campus like Stanford) - Inter-: Decentralized, scale to Internet Optimality A 6 1 3 2 F 1 E B 4 1 9 C D • View network as a graph • Assign cost to each edge - Can be based on latency, b/w, utilization, queue length, . • Problem: Find lowest cost path between two nodes - Must be computed in distributed way Distance Vector • Local routing algorithm • Each node maintains a set of triples - (Destination, Cost, NextHop) • Exchange updates w. directly connected neighbors - periodically (on the order of several seconds to minutes) - whenever table changes (called triggered update) • Each update is a list of pairs: - (Destination, Cost) • Update local table if receive a “better” route - smaller cost - from newly connected/available neighbor • Refresh existing -

The Edonkey File-Sharing Network
The eDonkey File-Sharing Network Oliver Heckmann, Axel Bock, Andreas Mauthe, Ralf Steinmetz Multimedia Kommunikation (KOM) Technische Universitat¨ Darmstadt Merckstr. 25, 64293 Darmstadt (heckmann, bock, mauthe, steinmetz)@kom.tu-darmstadt.de Abstract: The eDonkey 2000 file-sharing network is one of the most successful peer- to-peer file-sharing applications, especially in Germany. The network itself is a hybrid peer-to-peer network with client applications running on the end-system that are con- nected to a distributed network of dedicated servers. In this paper we describe the eDonkey protocol and measurement results on network/transport layer and application layer that were made with the client software and with an open-source eDonkey server we extended for these measurements. 1 Motivation and Introduction Most of the traffic in the network of access and backbone Internet service providers (ISPs) is generated by peer-to-peer (P2P) file-sharing applications [San03]. These applications are typically bandwidth greedy and generate more long-lived TCP flows than the WWW traffic that was dominating the Internet traffic before the P2P applications. To understand the influence of these applications and the characteristics of the traffic they produce and their impact on network design, capacity expansion, traffic engineering and shaping, it is important to empirically analyse the dominant file-sharing applications. The eDonkey file-sharing protocol is one of these file-sharing protocols. It is imple- mented by the original eDonkey2000 client [eDonkey] and additionally by some open- source clients like mldonkey [mlDonkey] and eMule [eMule]. According to [San03] it is with 52% of the generated file-sharing traffic the most successful P2P file-sharing net- work in Germany, even more successful than the FastTrack protocol used by the P2P client KaZaa [KaZaa] that comes to 44% of the traffic. -

IPFS and Friends: a Qualitative Comparison of Next Generation Peer-To-Peer Data Networks Erik Daniel and Florian Tschorsch
1 IPFS and Friends: A Qualitative Comparison of Next Generation Peer-to-Peer Data Networks Erik Daniel and Florian Tschorsch Abstract—Decentralized, distributed storage offers a way to types of files [1]. Napster and Gnutella marked the beginning reduce the impact of data silos as often fostered by centralized and were followed by many other P2P networks focusing on cloud storage. While the intentions of this trend are not new, the specialized application areas or novel network structures. For topic gained traction due to technological advancements, most notably blockchain networks. As a consequence, we observe that example, Freenet [2] realizes anonymous storage and retrieval. a new generation of peer-to-peer data networks emerges. In this Chord [3], CAN [4], and Pastry [5] provide protocols to survey paper, we therefore provide a technical overview of the maintain a structured overlay network topology. In particular, next generation data networks. We use select data networks to BitTorrent [6] received a lot of attention from both users and introduce general concepts and to emphasize new developments. the research community. BitTorrent introduced an incentive Specifically, we provide a deeper outline of the Interplanetary File System and a general overview of Swarm, the Hypercore Pro- mechanism to achieve Pareto efficiency, trying to improve tocol, SAFE, Storj, and Arweave. We identify common building network utilization achieving a higher level of robustness. We blocks and provide a qualitative comparison. From the overview, consider networks such as Napster, Gnutella, Freenet, BitTor- we derive future challenges and research goals concerning data rent, and many more as first generation P2P data networks, networks. -

The Routing Table V1.12 – Aaron Balchunas 1
The Routing Table v1.12 – Aaron Balchunas 1 - The Routing Table - Routing Table Basics Routing is the process of sending a packet of information from one network to another network. Thus, routes are usually based on the destination network, and not the destination host (host routes can exist, but are used only in rare circumstances). To route, routers build Routing Tables that contain the following: • The destination network and subnet mask • The “next hop” router to get to the destination network • Routing metrics and Administrative Distance The routing table is concerned with two types of protocols: • A routed protocol is a layer 3 protocol that applies logical addresses to devices and routes data between networks. Examples would be IP and IPX. • A routing protocol dynamically builds the network, topology, and next hop information in routing tables. Examples would be RIP, IGRP, OSPF, etc. To determine the best route to a destination, a router considers three elements (in this order): • Prefix-Length • Metric (within a routing protocol) • Administrative Distance (between separate routing protocols) Prefix-length is the number of bits used to identify the network, and is used to determine the most specific route. A longer prefix-length indicates a more specific route. For example, assume we are trying to reach a host address of 10.1.5.2/24. If we had routes to the following networks in the routing table: 10.1.5.0/24 10.0.0.0/8 The router will do a bit-by-bit comparison to find the most specific route (i.e., longest matching prefix). -

Conducting and Optimizing Eclipse Attacks in the Kad Peer-To-Peer Network
Conducting and Optimizing Eclipse Attacks in the Kad Peer-to-Peer Network Michael Kohnen, Mike Leske, and Erwin P. Rathgeb University of Duisburg-Essen, Institute for Experimental Mathematics, Ellernstr. 29, 45326 Essen [email protected], [email protected], [email protected] Abstract. The Kad network is a structured P2P network used for file sharing. Research has proved that Sybil and Eclipse attacks have been possible in it until recently. However, the past attacks are prohibited by newly implemented secu- rity measures in the client applications. We present a new attack concept which overcomes the countermeasures and prove its practicability. Furthermore, we analyze the efficiency of our concept and identify the minimally required re- sources. Keywords: P2P security, Sybil attack, Eclipse attack, Kad. 1 Introduction and Related Work P2P networks form an overlay on top of the internet infrastructure. Nodes in a P2P network interact directly with each other, i.e., no central entity is required (at least in case of structured P2P networks). P2P networks have become increasingly popular mainly because file sharing networks use P2P technology. Several studies have shown that P2P traffic is responsible for a large share of the total internet traffic [1, 2]. While file sharing probably accounts for the largest part of the P2P traffic share, also other P2P applications exist which are widely used, e.g., Skype [3] for VoIP or Joost [4] for IPTV. The P2P paradigm is becoming more and more accepted also for professional and commercial applications (e.g., Microsoft Groove [5]), and therefore, P2P technology is one of the key components of the next generation internet. -

Diapositiva 1
TRANSFERENCIA O DISTRIBUCIÓN DE ARCHIVOS ENTRE IGUALES (peer-to-peer) Características, Protocolos, Software, Luis Villalta Márquez Configuración Peer-to-peer Una red peer-to-peer, red de pares, red entre iguales, red entre pares o red punto a punto (P2P, por sus siglas en inglés) es una red de computadoras en la que todos o algunos aspectos funcionan sin clientes ni servidores fijos, sino una serie de nodos que se comportan como iguales entre sí. Es decir, actúan simultáneamente como clientes y servidores respecto a los demás nodos de la red. Las redes P2P permiten el intercambio directo de información, en cualquier formato, entre los ordenadores interconectados. Peer-to-peer Normalmente este tipo de redes se implementan como redes superpuestas construidas en la capa de aplicación de redes públicas como Internet. El hecho de que sirvan para compartir e intercambiar información de forma directa entre dos o más usuarios ha propiciado que parte de los usuarios lo utilicen para intercambiar archivos cuyo contenido está sujeto a las leyes de copyright, lo que ha generado una gran polémica entre defensores y detractores de estos sistemas. Las redes peer-to-peer aprovechan, administran y optimizan el uso del ancho de banda de los demás usuarios de la red por medio de la conectividad entre los mismos, y obtienen así más rendimiento en las conexiones y transferencias que con algunos métodos centralizados convencionales, donde una cantidad relativamente pequeña de servidores provee el total del ancho de banda y recursos compartidos para un servicio o aplicación. Peer-to-peer Dichas redes son útiles para diversos propósitos. -

Downloading Copyrighted Materials
What you need to know before... Downloading Copyrighted Materials Including movies, TV shows, music, digital books, software and interactive games The Facts and Consequences Who monitors peer-to-peer file sharing? What are the consequences at UAF The Motion Picture Association of America for violators of this policy? (MPAA), Home Box Office, and other copyright Student Services at UAF takes the following holders monitor file-sharing on the Internet minimum actions when the policy is violated: for the illegal distribution of their copyrighted 1st Offense: contents. Once identified they issue DMCA Loss of Internet access until issue is resolved. (Digital Millennium Copyright Act) take-down 2nd Offense: notices to the ISP (Internet Service Provider), in Loss of Internet access pending which the University of Alaska is considered as resolution and a $100 fee assessment. one, requesting the infringement be stopped. If 3rd Offense: not stopped, lawsuit against the user is possible. Loss of Internet access pending resolution and a $250 fee assessment. What is UAF’s responsibility? 4th, 5th, 6th Offense: Under the Digital Millennium Copyright Act and Loss of Internet access pending resolution and Higher Education Opportunity Act, university a $500 fee assessment. administrators are obligated to track these infractions and preserve relevent logs in your What are the Federal consequences student record. This means that if your case goes for violators? to court, your record may be subpoenaed as The MPAA, HBO and similar organizations are evidence. Since illegal file sharing also drains becoming more and more aggressive in finding bandwidth, costing schools money and slowing and prosecuting alleged offenders in criminal Internet connections, for students trying to use court. -

Seedboxes Cc Forum
Seedboxes Cc Forum It's simple to get started with, and incredibly functional. Never had problems using. cc Mobile Apps for ios and android user. cc German- English Dictionary: Translation for Sumpf. Ellenkező esetben a webhely funkcionalitása korlátozott. Ask questions regarding our services or generic seedbox related tasks. Gradstein & Celis, M. 2021, 19:09 Replies: 3 [Wait for Plugin Update] Pornhub plugin - only HLS - duplicate problem. Seedbucket was developed in-house by Seedboxes. eu e as velocidades de UP e DOWN são muitos boas mas a limitação de tráfego complica. OB Config for seedboxes. Seedbox & Hosting. A lot slower to post updates though. 2011-05-18: Added a link to a post on HP’s support forum where the post helped a bit. A good starting place for additional information about Rapidleech is the Wiki and the official forum. cc, byte-sized-hosting. ---Description---Tellytorrent is an Indian private tracker for Indian movies & series with a collection of BD50, 4kUHD, DVD9, NetFlix DL & Amazon DL- Source. cc often offers special discounts – called “promo codes” on its website. We have not put down all the specifications but you can read more about them in this post. The Raspberry Pi 4 dropped and it's a major update for the flagship single-board computer. On September 2, 2009, isoHunt announced the launch of a spinoff site, hexagon. 53GHz HyperThreading),. cc - Quality and affordable seedbox with premium bandwidth Seedboxes. Sdedi propose des solutions Seedbox uniques et innovantes : un espace disque illimité, un réseau de 10 Gigas, une app seedbox mobile et plus encore, à partir de 2,99 euros.