Estimation of Gini-Index from Continuous Distribution Based on Ranked Set Sampling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

William Lazonick
September 2010 WILLIAM LAZONICK Center for Industrial Competitiveness University of Massachusetts Lowell One University Avenue, Lowell, MA 01854 Phone: 1 617 576-0880 Fax: 1 425 491-4964 Email: [email protected] Personal website: http://www.uml.edu/centers/CIC/lazonick.html Date and Place of Birth: June 8, 1945 at Toronto, Ontario, Canada Countries of Citizenship: USA, Canada Current Principal Academic Positions: Professor, University of Massachusetts Lowell, Department of Economics (1993-1997 Policy & Planning; 1997-2010 Regional Economic and Social Development) Director, Center for Industrial Competitiveness, University of Massachusetts Lowell Previous Principal Academic Positions: Research Professor, INSEAD 1996-2007 Professor of Economics, University of Tokyo 1996-1997 Professor of Economics, Barnard College, Columbia University 1985-1993 Research Fellow, Harvard Graduate School of Business Administration 1984-1986 Associate Professor of Economics, Harvard University 1980-1984 Assistant Professor of Economics, Harvard University 1975-1980 Academic Honors: Schumpeter Prize, International Schumpeter Society 2010 Honorary Doctor of Philosophy, Uppsala University 1991 President, Business History Conference 1990-1991 Visiting Member, Social Sciences, Institute for Advanced Study, Princeton 1989-1990 German Marshall Fund of the United States Research Fellow 1985-1986 Harvard-Newcomen Business History Research Fellow 1984-1985 Newcomen Award in Business History for the outstanding article in Business History Review in 1983 1984 -

Università Del Salento in Brief
Università del Salento for European Universities in Brief: Local Roots with a Global Mindset Situated in the Southeast of Italy, the Università del Salento is a young, dynamic university, keen to expand and to prove itself at a national and international level, while consolidating and reinforcing its role as the guiding light of the local culture and society. With 95,000 inhaBitants and its favourable geographical position, right in the centre of the Mediterranean and between two seas, Lecce has Been throughout its long history a cross-road of cultures, contacts and trading between the Middle East, the Balkans and Western Europe, as well as a bridge between North Africa and Southern Europe. Gifted with unique natural sceneries and architectural styles, Lecce and the Salento region offer a vibrant and authentic lifestyle, which allows University students to get qualitative education at affordable costs, with housing, entertainment and shopping opportunities for every budget. Since 1955, the Università del Salento has aimed to promote knowledge and skills acquisition by offering a large range of educational opportunities. From Law to Science, Economics to Engineering, Humanities to Media Studies, the University provides academic pathways to a range of professions as well as post- graduate and specialist courses tailor-made to meet the needs of the joB market. 8 Departments with more than 600 staff and 500 administrative staff, cater for approximately 18,000 students. With more than 60 Degree Programs, 30 Research Centres and 150 international partners, the University del Salento demonstrates its commitment to teaching, research as well as social engagement and impact on the local community (Terza Missione), with a strong interdisciplinary and international stance. -

Handbook of Research an Grid Technologies and Utility Computing: Concepts for Managing Large-Scale Applications
Handbook of Research an Grid Technologies and Utility Computing: Concepts for Managing Large-Scale Applications Emmanuel Udoh Indiana University-Purdue University, USA Frank Zhigang Wang Cranfield University, UK Information Science INFORMATION SCIENCE REFERENCE REFERENCE Hershey • New York Table of Contents Foreword xxvi Preface xxviii Acknowledgment xxxii Section I Introduction Chapter I Overview of Grid Computing 1 Emmanuel Udoh, Indiana University—Purdue University, USA Frank Zhigang Wang, Cranfield University, UK Vineet R. Khare, Cranfield University, UK Section II Grid Scheduling and Optimization Chapter II Resource-Aware Load Balancing of Parallel Applications 12 Eric Aubanel, University of New Brunswick, Faculty of Computer Science, Canada Chapter III Assisting Efficient Job Planning and Scheduling in the Grid 22 Enis Afgan, University of Alabama at Birmingham, USA Purushotham Bangalore, University of Alabama at Birmingham, USA Chapter IV Effective Resource Allocation and Job Scheduling Mechanisms for Load Sharing in a Computational Grid 31 Kuo-Chan Huang, National Taichung University, Taiwan Po-Chi Shih, National Tsing Hua University, Taiwan Yeh-Ching Chung, National Tsing Hua University, Taiwan Chapter V Data-Aware Distributed Batch Scheduling 41 Tevfik Kosar, Louisiana State University, USA Chapter VI Consistency of Replicated Datasets in Grid Computing 49 Gianni Pucciani, CERN, European Organization for Nuclear Research, Switzerland Flavia Donno, CERN, European Organization for Nuclear Research, Switzerland Andrea Domenici, -

Download the Final Program
FINAL PROGRAM Monday, October 7 8:30 AM - 10:00 AM Participants’ Registration 10:00 AM - 10:20 AM - Welcome Addresses Leopoldo Angrisani, M&N 2013 General Chairman Claudio Quintano, Rector of the University of Naples “Parthenope” Nicola Mazzocca, Head of the Department of Information Technologies and Electrical Engineering, University of Naples Federico II Vito Pascazio, Head of the Department of Engineering, University of Naples “Parthenope” Giovanni Betta, President of GMEE - Italian Association of Electrical and Electronic Measurements 10:20 AM – 10:45 AM - Keynote Speech Dr. Federico Flaviano, Director of AGCOM Consumer Protection Directorate “Mobile Internet Access Service QoS Measurements: the Italian project” 10:45 AM - 11:10 AM Coffee Break Room: Richard Wagner Main Hall 11:10 AM - 12:50 PM Oral Session 1 – Wireless Sensor Networks Synchronization Room: Conference Room Chairpersons: Achim Berger (Linz Center of Mechatronics, Austria) Domenico Grimaldi (Università della Calabria, Italy) 11:10 Robust synchronization for IEEE 802.15.4 CSS Wireless Sensor Networks Paolo Ferrari (University of Brescia, Italy); Giada Giorgi (University of Padova, Italy); Claudio Narduzzi (Universita' di Padova, Italy); Stefano Rinaldi (University of Brescia, Italy); Mattia Rizzi (University of Brescia, Italy) 11:30 Synchronized Industrial Wireless Sensor Network with IEEE 802.11 Ad Hoc Data Transmission Achim Berger (Linz Center of Mechatronics); Albert Potsch (Linz Center of Mechatronics); Andreas Springer (University) 11:50 Synchronization for Hot-plugging -

Table of Contents
Table of Contents Volume I Foreword ........................................................................................................................................xxxvii Preface ................................................................................................................................................... xl Acknowledgment ................................................................................................................................ xlv Section I Infrastructures and Services for HealthGrids and BioGrids Chapter I SHARE: A European Healthgrid Roadmap ............................................................................................ 1 Mark Olive, University of the West of England, UK Hanene Boussi Rahmouni, University of the West of England, UK Tony Solomonides, University of the West of England, UK Vincent Breton, IN2P3, CNRS, Clermont-Ferrand, France Nicolas Jacq, HealthGrid (International) Yannick Legré, HealthGrid (International), IN2P3, CNRS, Clermont-Ferrand, France Ignacio Blanquer, Universidad Politécnica de Valencia, Spain Vicente Hernandez, Universidad Politécnica de Valencia, Spain Isabelle Andoulsi, Universitaires Notre-Dame de la Paix, Belgium Jean Herveg, Universitaires Notre-Dame de la Paix, Belgium Celine Van Doosselaere, European Health Management Association (International) Petra Wilson, European Health Management Association (International) Alexander Dobrev, Empirica GmbH, Germany Karl Stroetmann, Empirica GmbH, Germany Veli Stroetmann, Empirica GmbH, Germany Chapter -

Vincenzo Zonno University of Salento Lecce, Italy Researchresearch Centrecentre
Thursday 5 November EU-India PARTNERING EVENT Theme: Life sciences, biotechnology and biochemistry for sustainable non-food products and processes VINCENZO ZONNO UNIVERSITY OF SALENTO LECCE, ITALY RESEARCHRESEARCH CENTRECENTRE Life sciences, Life sciences, Life sciences, Life sciences Marine Aquaculture and Fisheries Research Centred ¾ Technology for effluent treatment and waste reuse ¾ Biology and genetics of new fish species for aquaculture ¾ Sea food safety and quality monitoring ¾ Physiology of fish gastrointestinal tract ¾ Search for alternative raw materials ¾ Development of recirculation technology ¾ Cryo-biology and fish gamete cryopreservation ¾ Development of animal welfare indicators ¾ Marine fish stocks assessment ¾ Models for integrated management of coastal zones Coordinator FP6 Collective research AQUAETREAT FP6 Coordination Action AQUAGRIS FP7 Marie-Curie IRSES PASSA TECNOSEA – Academic Spin-off PROJECTPROJECT IDEAIDEA Life sciences, Life sciences, Life sciences, Life sciences Biotechnological Application in wastewater treatment for the Prevention of Pollution and Bioremediation in Intensive Aquaculture (Acronym AQUAETREAT Biotech) KEY OBJECTIVE To make innovative improvement in the aquaculture effluent treatment systems through the application of novel biotechnological solutions EXPECTED OUTPUT Development of a comprehensive integrated bioremediation technological package for water use optimisation and waste re-use and valorisation promoting sustainable aquaculture industry PARTNERPARTNER SOUGHTSOUGHT Life sciences, Life -

First Records of the Crayfish Procambarus Clarkii
BioInvasions Records (2017) Volume 6, Issue 2: 153–158 Open Access DOI: https://doi.org/10.3391/bir.2017.6.2.11 © 2017 The Author(s). Journal compilation © 2017 REABIC Rapid Communication First records of the crayfish Procambarus clarkii (Girard, 1852) (Decapoda, Cambaridae) in Lake Varano and in the Salento Peninsula (Puglia region, SE Italy), with review of the current status in southern Italy Lucrezia Cilenti1,*, Giuseppe Alfonso4, Marco Gargiulo2, Francesco Salvatore Chetta2, Anita Liparoto3, Raffaele D’Adamo1 and Giorgio Mancinelli4,* 1Institute of Marine Science (ISMAR) – National Research Council (CNR), Lesina (FG), Italy 2“Flora e Fauna del Salento”, https://it-it.facebook.com/Salentofloraefauna/ 3Department of Ecological and Biological Sciences, Tuscia University, Viterbo, Italy 4Department of Biological and Environmental Sciences and Technologies, University of Salento, Lecce, Italy Author e-mails: [email protected] (LC), [email protected] (GM) *Corresponding authors Received: 8 November 2016 / Accepted: 3 March 2017 / Published online: 21 March 2017 Handling editor: Elena Tricarico Abstract The occurrence of the red swamp crayfish Procambarus clarkii is documented in the surroundings of Lake Varano (Puglia region, SE Italy), testifying to the ongoing diffusion of this invasive crayfish in north-eastern Puglia, an area characterised by an extensive network of natural and artificial watercourses. In addition, the species is recorded for the first time in the Salento Peninsula, in the south-western part of the region. The hydrology of the area is dominated by karstic phenomena, and the ecological consequences of the colonization of hypogean environments by P. clarkii are discussed. These records, in conjunction with a number of recent observations made in Puglia and in other regions of southern Italy including Sicily and Sardinia, indicate that the species is far more widespread in the area than previous studies have suggested. -

Dear Prof. Wilson, According to a Suggestion by Sergio Bertolucci, I Send You Information About the Request of the Lecce Group to Join DUNE Collaboration
Dear prof. Wilson, according to a suggestion by Sergio Bertolucci, I send you information about the request of the Lecce group to join DUNE Collaboration. At the moment we are only two staff people. As usual in Italy, we are from University and from INFN. Best wishes, Paolo ------------------------------------------------------------------------ Our possible contributions to the DUNE program: - MC simulation of near detector and its physics reach - contribution to SBL program at FNAL, mainly simulation and data analysis - contribution to the activities required to install and operate detector components that will be contributed by INFN ------------------------------------------------------------------------ The group: Paolo Bernardini Associate Professor, Dipartimento di Matematica e Fisica "Ennio De Giorgi", Università del Salento, Lecce, Italy Born on 1954 and graduated on 1978, Paolo Bernardini is an Italian experimental particle physicist. At the very beginning of the career he was at N. Bohr Institutet in Copenaghen and at the ENEA Frascati laboratories. On 1983 he got a position at the Università di Urbino, Italy. Presently he is associate professor at the Dipartimento di Matematica e Fisica and member of the Administration Council at the Università del Salento, Lecce, Italy. P. Bernardini wrote more than 130 papers on peer-review journals and gave talks in many international conferences. His research activity has been focused on astroparticle and neutrino physics, indeed he contributed to the analysis of neutrino-induced events collected with the MACRO detector in the Gran Sasso underground laboratory. This measurement of the atmospheric neutrino flux supported the claim on neutrino oscillation in 1998. After the MACRO experience, P. Bernardini was active in the ARGO-YBJ experiment in Tibet devoted to cosmic-ray studies and gamma-ray astronomy. -

Carducci, Michele
Full Professor of "Comparative Constitutional Law and Constitutional Ecology " in the University of Salento – Italy. Before Salento, he taught in the Universities of Parma and Urbino - Italy. Once taken the Doctorate in Constitutional Law, he studied in the Universities of Vienna, Münster and Erlangen (Germany), and Carlos III of Madrid. CNR scholarship in the Pontificia Universidade Católica de São Paulo in Brazil, in 2003 he was Professor Estrangeiro Visitante for the UNISINOS- Rio Grande do Sul, within the program FAPERGS on designation of Prof. Dr. José Luis Bolzan De Morais. He was also Visiting Reseracher in the Cardozo School of Law (NY) and Wisconsin and Visiting Professor in the Universidad Autónoma de Tlaxcala in México, the Universidade Católica de Pernambuco, the Pontificia Universidade Católica do Paraná (Curitiba), in the Pontificia Universidad Católica del Perú, and UniRosario and UniNorte Colombia. Now he has won the title of adjunct professor of Comparative Regionalism in the Pontificia Universidad Católica del Perú. In 2003, he was awarded of the Diploma of Alta Distinção da Cultura Juridica Comenda Jurista “Tobias Barreto” from the Instituto Brasileiro de Estudos do Direito of Recife, and he is “membro honorario” of the “Instituto de Direito Constitucional e Cidadania” and “Profesor Honorario” in the Universidad Ricardo Palma de Lima. Past Coordinator of the international Doctorate in Legal, Political and Social Compared Systems in the University of Lecce, he was european referent of Circulo Constitucional Euro Americano and First President of the “Sezione Italiana del Instituto Iberoamericano de Derecho Constituticional”. The didactic and scientific activities of the last years have been developed and based on six trends of experiences of teaching and study: 1. -
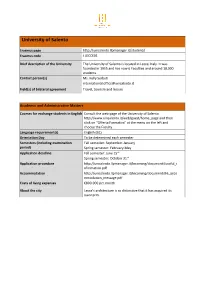
University of Salento
University of Salento Erasmus page http://unisalento.llpmanager.it/studenti/ Erasmus code I LECCE01 Brief description of the University The University of Salento is located in Lecce, Italy. It was founded in 1955 and has now 6 Faculties and around 18,000 students. Contact person(s) Ms. Kelly Serbeti [email protected] Field(s) of bilateral agreement Travel, tourism and leisure Academic and Administrative Matters Courses for exchange students in English Consult the web-page of the University of Salento http://www.unisalento.it/web/guest/home_page and then click on “Offerta Formativa” at the menu on the left and choose the Faculty. Language requirement(s) English (B1) Orientation Day To be determined each semester Semesters (including examination Fall semester: September-January period) Spring semester: February-May Application deadline Fall semester: June 15th Spring semester: October 31st Application procedure http://unisalento.llpmanager.it/Incoming/documenti/useful_i nformation.pdf Accommodation http://unisalento.llpmanager.it/Incoming/documenti/Hi_acco mmodation_message.pdf Costs of living expenses €800-900 per month About the city Lecce's architecture is so distinctive that it has acquired its own term. USEFUL INFORMATION FOR INTERNATIONAL EXCHANGE STUDENTS APPLICATION FORMS AND DEADLINES • Before the on-line application submission, the Partner Institution has to communicate the selected candidates to the Student Mobility Office at the Università del Salento certifying she/he has been selected as an Erasmus or exchange -

Defi International Students Brochure
Department of Engineering for Innovation (DEfI) #exchange students #enrolment #Erasmus+ students BACK TO NEXT HOME Outline of he Department of Engineering for Innovation (DEfI) The Department of Engineering for Innovation focuses on new technologies and aims at promoting and disseminating technology innovation. Staff includes 98 tenured faculties and 130 among PhDs, post-docs and research fellows active in the research fields of: Renewable Energies, Materials Science & Technologies, ICTs, IoT, HPC, V&A Reality, Nanotechnologies, Automation & Robotics, Machine Processing Systems & Technologies, Mechanical & Aerospace Design, Intelligent & Clean Manufacturing Techs, Management Engineering, Design and Testing in Mechanical & Civil Engineering, Fluid Dynamics & Machinery, Bio- applications. Many prestigious results and awards in several research areas have been and are being obtained at international level by the Department research staff. Research activities have been carried out in several national and international projects funded by the Italian Ministry for Education University and Research, by main Italian research centres (ENEA, ASI CNR, INFM, INFN) and by the European Union (in the FP5, FP6 and FP7 programs). Find a place Find a contact BACK TO HOME BACK NEXT 7 Master Programs Focus • Civil Engineering • Mechanical Engineering New Technologies • Aerospace Engineering (taught in Promotion of Innovation English) • Management Engineering (taught in Technology Transfer English) • Communication Engineering & Electronic Technologies (taught -

Student Recruitment Fair 2019 - Exhibitor List Friday, 3 May 2019, 16:20-19:00 Aliathon Resort, Multifunctional Conference Centre, Aphrodite Hall, Paphos
Student Recruitment Fair 2019 - Exhibitor List Friday, 3 May 2019, 16:20-19:00 Aliathon Resort, Multifunctional Conference Centre, Aphrodite Hall, Paphos Stand Country Institution Name 1 Armenia Russian-Armenian University 2 Belgium VIVES University of Applied Sciences 3 Bulgaria American University in Bulgaria 4 Cyprus Cyprus University of Technology 5 Cyprus Neapolis University Paphos 6 Cyprus University of Cyprus 7 Czech Republic Mendel University in Brno 8 Czech Republic University of Finance and Administration 9 Czech Republic University of South Bohemia 10 Czech Republic University of South Bohemia in Ceske Budejovice 11 Czech Republic VSB - Technical University of Ostrava 12 France Institut Mines-Telecom Business School 13 Greece University of Piraeus 14 India Institute for Career and Skill Development 15 Italy Universita Degli Studi Di Brescia 16 Italy University of Salento 17 Kazakhstan KazNAU 18 Latvia Riga Stradins university 19 Lithuania Kaunas University of Technology 20 Lithuania Klaipeda State University of Applied Sciences 21 Poland Military University of Technology 22 Poland Opole University of Technology 23 Poland WSB University 24 Romania Romanian-American University 25 Romania Universitatea "1 Decembrie 1918” Alba Iulia 26 Spain University of Almeria 27 Tunisia JackSoove 28 United Kingdom Nottingham Trent University 29 United Kingdom The University for the Creative Arts 30 United Kingdom University College Birmingham 31 United kingdom University of Hull 32 Belgium Karel de Grote University College 32 Bulgaria Higher