Web Search Result Clustering Based on Heuristic Search and K-Means
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
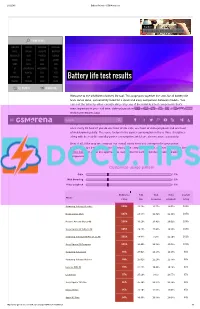
Battery Life Test Results HUAWEI TOSHIBA INTEX PLUM
2/12/2015 Battery life tests GSMArena.com Starborn SAMSUNG GALAXY S6 EDGE+ REVIEW PHONE FINDER SAMSUNG LENOVO VODAFONE VERYKOOL APPLE XIAOMI GIGABYTE MAXWEST MICROSOFT ACER PANTECH CELKON NOKIA ASUS XOLO GIONEE SONY OPPO LAVA VIVO LG BLACKBERRY MICROMAX NIU HTC ALCATEL BLU YEZZ MOTOROLA ZTE SPICE PARLA Battery life test results HUAWEI TOSHIBA INTEX PLUM ALL BRANDS RUMOR MILL Welcome to the GSMArena battery life tool. This page puts together the stats for all battery life tests we've done, conveniently listed for a quick and easy comparison between models. You can sort the table by either overall rating or by any of the individual test components that's most important to you call time, video playback or web browsing.TIP US 828K 100K You can find all about our84K 137K RSS LOG IN SIGN UP testing procedures here. SearchOur overall rating gives you an idea of how much battery backup you can get on a single charge. An overall rating of 40h means that you'll need to fully charge the device in question once every 40 hours if you do one hour of 3G calls, one hour of video playback and one hour of web browsing daily. The score factors in the power consumption in these three disciplines along with the reallife standby power consumption, which we also measure separately. Best of all, if the way we compute our overall rating does not correspond to your usage pattern, you are free to adjust the different usage components to get a closer match. Use the sliders below to adjust the approximate usage time for each of the three battery draining components. -

Аксессуары В Подарок При Покупке Huawei Nova 2I» Список Товара 2, Участвующего В Акции
Приложение 2 к Правилам Акции «Аксессуары в подарок при покупке Huawei Nova 2i» Список Товара 2, участвующего в Акции Артикул Наименование 0315-2319 Брелок Brillstone Кошка в сердце (21) золото 0313-2121 Чехол-кейс Clever ультратонкий Lumia 520 прозрачный 0313-2663 Чехол-книжка Gresso МТС Smart Sprint 4,5” Канцлер красный 0313-1728 Чехол-кейс Nokia Lumia 820 CC-3058 (Original) черный 0313-2996 Чехол-книжка Muvit Slim S Folio Sony Xperia M4 Aqua черный 0313-2631 Клип-кейс RedLine iBox Fresh Samsung G313 Galaxy Ace 4 DS белый 0313-1443 Сумка RedPoint кроко прайм XL 0400-0913 Чехол Sumdex ST3-820 BK Samsung Galaxy Tab 3 8" черный 0317-0679 Пленка защитная RedLine Sony Xperia Z3 матовая 0305-1162 USB Flash EMTEC 32Gb USB3.0/Lightning 8-pin iCobra2 (ECMMD32GT503V2B) черная 0305-0222 Карта памяти MS Micro M2 SanDisk 4Gb 0313-3178 Чехол-книжка Arvy универсальный размер M принт 190 0313-3363 Клип-кейс Deppa iPhone 6 Plus Black Коршун 0313-3367 Клип-кейс Deppa iPhone 6 Plus Military Бабочки 2 0313-4214 Клип-кейс RedLine Crystal Lenovo A2010 прозрачный 0400-1079 Чехол-книжка Clever SuperSlim Samsung Galaxy Tab S2 8 красный 0400-0902 Чехол-книжка iBox Premium Samsung Galaxy Tab S 10.5 черный 0313-3059 Клип-кейс Deppa Air Case Samsung I9300 Galaxy S3 мятный 0313-3061 Клип-кейс Deppa Air Case Samsung I9300 Galaxy S3 черный 0400-1080 Чехол-книжка Clever SuperSlim Samsung Galaxy Tab S2 8 черный 0202-0347 MP3-плеер teXet T-979HD 4Гб/TFT 4,3" черный 0307-0185 Дата-кабель Gal 2604 USB - microUSB 2.0 1м оранжевый 0313-3516 Чехол-книжка Puro Samsung Galaxy -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Phone Compatibility
Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. Last Updated: February 14, 2017 • Compatible with phone models using Android versions 4.1 (Jelly Bean) or higher, and that have the following four sensors: Accelerometer, Gyroscope, Magnetometer, GPS/Location Services. • Phone compatibility information is provided by phone manufacturers and third-party sources. While every attempt is made to ensure the accuracy of this information, this list should only be used as a guide. As phones are consistently introduced to market, this list may not be all inclusive and will be updated as new information is received. Please check your phone for the required sensors and operating system. Brand Phone Compatible Non-Compatible Acer Acer Iconia Talk S • Acer Acer Jade Primo • Acer Acer Liquid E3 • Acer Acer Liquid E600 • Acer Acer Liquid E700 • Acer Acer Liquid Jade • Acer Acer Liquid Jade 2 • Acer Acer Liquid Jade Primo • Acer Acer Liquid Jade S • Acer Acer Liquid Jade Z • Acer Acer Liquid M220 • Acer Acer Liquid S1 • Acer Acer Liquid S2 • Acer Acer Liquid X1 • Acer Acer Liquid X2 • Acer Acer Liquid Z200 • Acer Acer Liquid Z220 • Acer Acer Liquid Z3 • Acer Acer Liquid Z4 • Acer Acer Liquid Z410 • Acer Acer Liquid Z5 • Acer Acer Liquid Z500 • Acer Acer Liquid Z520 • Acer Acer Liquid Z6 • Acer Acer Liquid Z6 Plus • Acer Acer Liquid Zest • Acer Acer Liquid Zest Plus • Acer Acer Predator 8 • Alcatel Alcatel Fierce • Alcatel Alcatel Fierce 4 • Alcatel Alcatel Flash Plus 2 • Alcatel Alcatel Go Play • Alcatel Alcatel Idol 4 • Alcatel Alcatel Idol 4s • Alcatel Alcatel One Touch Fire C • Alcatel Alcatel One Touch Fire E • Alcatel Alcatel One Touch Fire S • 1 Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. -
Android Benchmarks - Geekbench Browser 11/05/2015 6:27 Pm Geekbench Browser Geekbench 3 Geekbench 2 Benchmark Charts Search Geekbench 3 Results Sign up Log In
Android Benchmarks - Geekbench Browser 11/05/2015 6:27 pm Geekbench Browser Geekbench 3 Geekbench 2 Benchmark Charts Search Geekbench 3 Results Sign Up Log In COMPARE Android Benchmarks Processor Benchmarks Mac Benchmarks iOS Benchmarks Welcome to Primate Labs' Android benchmark chart. The data on this chart is gathered from user-submitted Geekbench 3 results from the Geekbench Browser. Android Benchmarks Geekbench 3 scores are calibrated against a baseline score of 2500 (which is the score of an Intel Core i5-2520M @ 2.50 GHz). Higher scores are better, with double the score indicating double the performance. SHARE If you're curious how your computer compares, you can download Geekbench 3 and run it on your computer to find out your score. Tweet 0 This chart was last updated 30 minutes ago. 139 Like 891 Single Core Multi-Core Device Score HTC Nexus 9 1890 NVIDIA Tegra K1 Denver 2499 MHz (2 cores) Samsung Galaxy S6 edge 1306 Samsung Exynos 7420 1500 MHz (8 cores) Samsung Galaxy S6 1241 Samsung Exynos 7420 1500 MHz (8 cores) Samsung Galaxy Note 4 1164 Samsung Exynos 5433 1300 MHz (8 cores) NVIDIA SHIELD Tablet 1087 NVIDIA Tegra K1 2218 MHz (4 cores) Motorola DROID Turbo 1052 Qualcomm APQ8084 Snapdragon 805 2649 MHz (4 cores) Samsung Galaxy S5 Plus 1027 Qualcomm APQ8084 Snapdragon 805 2457 MHz (4 cores) Motorola Nexus 6 1016 Qualcomm APQ8084 Snapdragon 805 2649 MHz (4 cores) Samsung Galaxy Note 4 986 Qualcomm APQ8084 Snapdragon 805 2457 MHz (4 cores) Motorola Moto X (2014) 970 Qualcomm MSM8974AC Snapdragon 801 2457 MHz (4 cores) HTC One (M8x) -

52 Связь И Техника Камелот Воронеж № 19 (3107) 13.02.2017 Понедельник
52 СВЯЗЬ И ТЕХНИКА КАМЕЛОТ Воронеж № 19 (3107) 13.02.2017 ПОНЕДЕЛЬНИК Принтер Xerox-Phaser-3250 лазерный, отл. сост., 4.5 тыс. р. Т.8- Для смартфона Xiaomi-Redmi-3S чехол новый, 700 р. Т.8-904- Для сотового телефона Sony-Ericsson устройство hands-free, 908-148-73-17 АВАРИЙНАЯ КОМПЬЮТЕРНАЯ ПО- 214-93-63 500 р. Т.8-905-052-33-00 Принтер Xerox-Phaser-3260 новый, целый картридж, 4.75 тыс. МОЩЬ. Установка Windows, удале- Для смартфона ZTE-Nubia-Z5S-mini тачскрин, новый, 500 р. Для сотового телефона Sony-Xperia-C чехол-книжка, цв. бе- р. Т.8-980-542-23-94 Т.8-951-866-56-66, Сергей лый, новый, в упаковке, 350 р. Т.290-78-68 Программа Wilcom-2012 для создания компьютерных выши- ние вирусов. Ремонт планшетов. Для смартфона стилус емкостный, с креплением, цв. черный, Для сотового телефона Sony-Xperia-C2305 задняя крышка, Ноутбук Acer-Aspire-5520G, 15.4 дюйма, ОЗУ 2 Гб, б/у, 7 тыс. р. разъем3.5,новый,49 р. Т.8-952-955-70-65 вальных дизайнов, 2.5 тыс. р. Т.8-920-453-69-46 Выезд бесплатно. Недорого. Гаран- 150 р. Т.8-951-866-56-66, Сергей Т.8-920-455-95-29 Для сотового телефона Apple-iPhone чехол, хор. сост., 50 р. Для сотового телефона Vertu аккумулятор, 430 р. Т.8-910-247- Процессор AMD, в комплекте с кулером, ОЗУ 512 Мб, б/у, 700 Ноутбук Acer-Aspire-One, 10.1 дюйма, процессор Intel-Atom тия. Т.292-95-30, т.8-908-131-01-93 Т.8-951-873-50-98 89-91, с 8.00 до 21.00 р. -

Fnac Reprise
FNAC REPRISE Liste des smartphones éligibles au programme de reprise au 19/08/2016 ACER LIQUID Z4 APPLE IPHONE 5 BLACK 64GB ACER INCORPORATED LIQUID Z530S APPLE IPHONE 5 WHITE 16GB ACER INCORPORATED LIQUID Z630S APPLE IPHONE 5 WHITE 32GB ALBA ALBA 4.5INCH 5MP 4G 8GB APPLE IPHONE 5 WHITE 64GB ALBA DUAL SIM APPLE IPHONE 5C ALCATEL IDOL 3 8GB APPLE IPHONE 5C BLUE 16GB ALCATEL ONE TOUCH 228 APPLE IPHONE 5C BLUE 32GB ALCATEL ONE TOUCH 903 APPLE IPHONE 5C BLUE 8GB ALCATEL ONE TOUCH 903X APPLE IPHONE 5C GREEN 16GB ALCATEL ONE TOUCH IDOL 2 MINI S APPLE IPHONE 5C GREEN 32GB ALCATEL ONE TOUCH TPOP APPLE IPHONE 5C GREEN 8GB ALCATEL ONETOUCH POP C3 APPLE IPHONE 5C PINK 16GB AMAZON FIRE PHONE APPLE IPHONE 5C PINK 32GB APPLE APPLE WATCH EDITION 42MM APPLE IPHONE 5C PINK 8GB APPLE IPHONE 3G APPLE IPHONE 5C WHITE 16GB APPLE IPHONE 3G BLACK 16GB APPLE IPHONE 5C WHITE 32GB APPLE IPHONE 3G BLACK 8GB APPLE IPHONE 5C WHITE 8GB APPLE IPHONE 3G WHITE 16GB APPLE IPHONE 5C YELLOW 16GB APPLE IPHONE 3GS APPLE IPHONE 5C YELLOW 32GB APPLE IPHONE 3GS 8GB APPLE IPHONE 5C YELLOW 8GB APPLE IPHONE 3GS BLACK 16GB APPLE IPHONE 5S APPLE IPHONE 3GS BLACK 32GB APPLE IPHONE 5S BLACK 16GB APPLE IPHONE 3GS WHITE 16GB APPLE IPHONE 5S BLACK 32GB APPLE IPHONE 3GS WHITE 32GB APPLE IPHONE 5S BLACK 64GB APPLE IPHONE 4 APPLE IPHONE 5S GOLD 16GB APPLE IPHONE 4 BLACK 16GB APPLE IPHONE 5S GOLD 32GB APPLE IPHONE 4 BLACK 32GB APPLE IPHONE 5S GOLD 64GB APPLE IPHONE 4 BLACK 8GB APPLE IPHONE 5S WHITE 16GB APPLE IPHONE 4 WHITE 16GB APPLE IPHONE 5S WHITE 32GB APPLE IPHONE 4 WHITE 32GB APPLE IPHONE -
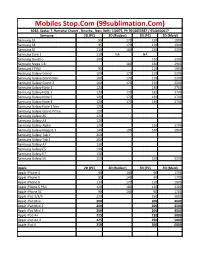
Mobiles Stop.Com (99Sublimation.Com)
Mobiles Stop.Com (99sublimation.Com) B282, Sector 7, Ramphal Chowk , Dwarka , New Delhi 110075, Ph 9910053987 / 9540300017 Samsung 2D (PC) 2D (Rubber) 3D (PC) 3D (Mold) Samsung S3 95 170 110 1900 Samsung S4 95 170 110 1900 Samsung S5 110 180 120 2200 Samsung Core 2 110 NA NA Samsung Quattro 100 120 2200 Samsung Mega 5.8 180 130 2900 Samsung S7562 95 110 1900 Samsung Galaxy Grand 100 170 110 2200 Samsung Galaxy Grand Neo 100 170 110 2200 Samsung Galaxy Grand 2 100 170 110 2200 Samsung Galaxy Note 1 120 130 2700 Samsung Galaxy Note 2 120 170 130 2700 Samsung Galaxy Note 3 120 170 130 2700 Samsung Galaxy Note 4 120 170 130 2700 Samsung Galaxy Note 3 Neo 120 Samsung Galaxy Grand Prime 120 Samsung Galaxy A5 120 Samsung Galaxy A3 120 Samsung Galaxy Alpha 120 130 2700 Samsung Galaxy Mega 6.3 140 190 140 2900 Samsung Galaxy Tab 2 200 Samsung Galaxy Tab 3 200 Samsung Galaxy A7 130 Samsung Galaxy E5 130 Samsung Galaxy E7 130 Samsung Galaxy S6 150 150 3200 Apple 2D (PC) 2D (Rubber) 3D (PC) 3D (Mold) Apple iPhone 4 90 140 90 1700 Apple iPhone 5 90 140 90 1700 Apple iPhone 6 110 170 110 1900 Apple iPhone 6 Plus 120 180 120 2200 Apple iPhone 5C 90 140 90 1700 Apple iPad 2/3/4 220 250 5000 Apple iPad Mini 200 200 4500 Apple iPad Mini 2 200 200 4500 Apple iPad Mini 3 200 200 4500 Apple iPad Air 225 250 5000 Apple iPad Air 2 225 250 5000 Apple iPad 6 250 300 6000 LG 2D (PC) 2D (Rubber) 3D (PC) 3D (Mold) LG G2 130 130 2700 LG G3 130 130 2700 LG L70 120 LG L90 120 LG Nexus 4 110 LG Nexus 5 110 110 2200 HTC HTC Desire 816 130 140 2900 HTC Desire 820 140 -

Source Camera Identification: a Distributed Computing Approach
Faiz et al. Journal of Cloud Computing: Advances, Systems Journal of Cloud Computing: and Applications (2017) 6:18 DOI 10.1186/s13677-017-0088-x Advances, Systems and Applications RESEARCH Open Access Source camera identification: a distributed computing approach using Hadoop Muhammad Faiz1, Nor Badrul Anuar1, Ainuddin Wahid Abdul Wahab1, Shahaboddin Shamshirband2,3* and Anthony T. Chronopoulos4,5 Abstract The widespread use of digital images has led to a new challenge in digital image forensics. These images can be used in court as evidence of criminal cases. However, digital images are easily manipulated which brings up the need of a method to verify the authenticity of the image. One of the methods is by identifying the source camera. In spite of that, it takes a large amount of time to be completed by using traditional desktop computers. To tackle the problem, we aim to increase the performance of the process by implementing it in a distributed computing environment. We evaluate the camera identification process using conditional probability features and Apache Hadoop. The evaluation process used 6000 images from six different mobile phones of the different models and classified them using Apache Mahout, a scalable machine learning tool which runs on Hadoop. We ran the source camera identification process in a cluster of up to 19 computing nodes. The experimental results demonstrate exponential decrease in processing times and slight decrease in accuracies as the processes are distributed across the cluster. Our prediction accuracies are recorded between 85 to 95% across varying number of mappers. Keywords: Source camera identification, Distributed computing, Hadoop, Mahout Introduction and authenticity of the digital image to be questioned As we live in an era of high technology, digital images [12]. -

CDP Rental Items Product List
IT PRODUCTS AVAILABLE ON RENT DESKTOP DUAL CORE / 2GB / 120 GB / 15.4” TFT / KBD / MOUSE / DOS DUAL CORE / 2 GB RAM / 120 GB HDD OR ABOVE / 18.5” TFT / KBD / MOUSE / DOS CORE i3 / 4 GB RAM / 500 GB HDD OR ABOVE / 18.5” TFT / KBD / MOUSE / DOS CORE i5 / CORE i7 / QUAD CORE DESKTOP ALSO AVAILABLE / DOS LAPTOP ATOM / 1GB / 120 GB / WIFI / LAN / 10” TFT / DOS DUAL CORE / 2GB / 160 GB OR ABOVE / DVD RW / WIFI / LAN / 14-15” TFT / DOS CORE I3 / 4 GB / 320 GB / DVD RW / WIF / LAN / 14” TFT / DOS CORE I5 / 4 GB / 320 GB / DVD RW / WIF / LAN / 14” TFT / DOS CORE I7 / 8 GB / 500 GB / DVD RW / WIF / LAN / 15” TFT / DOS CORE I7 / 16 GB / 1 TB / DVD RW / WIF / 15.4” TFT / GRAPHICS CARD WITH 1-2 GB RAM / DOS SERVER INTEL XEON QUAD CORE / 8 GB / 500 GB / DVD RW / TOWER / GIGABIT LAN / DOS XEON QUAD CORE 2.13 * 2 / 16-32 GB / 500 GB * 2 / DVD RW / TOWER / GLAN * 2 XEON HEXA CORE 2 GHZ * 2 / 32 GB / 1 TB SAS * 2 / DVD RW / TOWER / G LAN * 2 XEON OCTA CORE 2 GHZ * 2 / 64 GB / 1 TB SAS * 2 / DVD RW / TOWER / G LAN * 2 XEON OCTA CORE 2 GHZ * 2 / 128 GB / 256 GB SSD / TOWER / 10 G LAN PORT / RAID CARD SUN SERVER / UNIX SERVER / AIX SERVER ALSO AVAILABLE ON RENT WORKSTATION INTEL CORE i7 / 8 GB / 500 GB / GRAPHICS CARD WITH 1 GB / DOS INTEL CORE i7 / 32 GB / 1 TB / NVIDIA QUADRO CARD / 22" TFT SCREEN / DOS HP XW 4600 / QUAD CORE / 4 GB / 500 GB / NVDIA QUADRO FX 1800 WITH 768 MB INTEL XEON QUAD CORE / 64 GB RAM / 1 TB / NVIDIA QUADRO FX 3450 / DVD RW / 3D STEREO DISPLAY TFT / NVIDIA 3D VISION KIT / DOS CUSTOMIZED WORKSTATIONS ALSO AVAILABLE ON DEMAND STORAGE -

List of Type Approved Telecom Equipment by Telecommunication Regulatory Authority
List of Type Approved Telecom Equipment by Telecommunication Regulatory Authority Equipment Type Device Description Model Manufacturer Expiry Date Note Terminal Devices Mobile Phone mPhone 380 mPhone DWC LLC 23-Dec-20 Terminal Devices ASUS Phone ZC521TL ASUSTeK Computer 25-Dec-20 Inc., Terminal Devices DELL SONIC WALL 01-SSC-0651 SONICWALL INC. 25-Dec-20 Terminal Devices Galaxy Grand Prime Pro SM-J250F/DS Samsung Electronics 25-Dec-20 Terminal Devices Galaxy A8 SM-A530F/DS Samsung Electronics 25-Dec-20 Terminal Devices Galaxy A8+ SM-A730F/DS Samsung Electronics 25-Dec-20 Terminal Devices Galaxy J7 Core SM-J701F/DS Samsung Electronics 25-Dec-20 Terminal Devices GPS Tracker ST-908 Auto Leader Co., Ltd 26-Dec-20 Terminal Devices FLEET MANAGEMENT SYSTEM FMB630 TELTONIKA 26-Dec-20 Terminal Devices FLEET MANAGEMENT SYSTEM FMB100 TELTONIKA 26-Dec-20 Terminal Devices FLEET MANAGEMENT SYSTEM FMB920 TELTONIKA 26-Dec-20 Terminal Devices Vantage K175 Avaya Inc. 26-Dec-20 Terminal Devices Bond-L21C Bond-L21C HUAWEI 26-Dec-20 TECHNOLOGIES CO., Ltd. Terminal Devices IP PBX Appliance UCM 6208 Grandstream 1-Jan-21 Networks, Inc. Terminal Devices Polycom VVX300 VVX300 Polycom, Inc. 1-Jan-21 Terminal Devices Polycom VVX400 VVX400 Polycom, Inc. 1-Jan-21 Terminal Devices GNSS Antenna R10 [SBSMA-110A] Trimble Inc. 1-Jan-21 Terminal Devices Mitel SIP-DECT Phone Mitel 612d v2 Mitel Deutschland 2-Jan-21 GmbH Terminal Devices 3D Universal Edge Router JNP204 Juniper Networks Inc. 2-Jan-21 Terminal Devices 3D Universal Edge Router MX204 Juniper Networks Inc. 2-Jan-21 Terminal Devices SONY XPERIA LT22i Sony Mobile 3-Jan-21 Communications Inc., Terminal Devices BROTHER FAX MACHINE FAX-2840 BROTHER INDUSTRIES, 3-Jan-21 Ltd. -

Устройства, Которые Не Подходят Для Работы С Таксометром: 4Good S450m 4G Acer A1
Устройства, которые не подходят для работы с Таксометром: 4good s450m 4g Acer A1-713 Acer A1-811 Acer Iconia Tab 7 Acer Iconia TalkTab 7 Acer liquid z530 Alcatel Alcatel onetouch pixi 3 (4.5) Alcatel 4047d Alcatel 5023f Alcatel 5038D Alcatel 5051d Alcatel 6037y Alcatel 6039y Alcatel 6043D Alcatel 6044d Alcatel 7045Y Alcatel 9003x Alcatel 9005X Alcatel Alcatel one touch 5036d Alcatel ALCATEL ONE TOUCH 7041D Alcatel ALCATEL ONE TOUCH 7047D Alcatel ALCATEL ONE TOUCH P310X Alcatel ALCATEL ONE TOUCH P320X Alcatel Alcatel onetouch pixi 3 (4.5) Alcatel Alcatel onetouch pixi 4 (4) Alcatel Alcatel onetouch pop 3 (5.5) Alcatel Alcatel onetouch pop 3 (5) Alcatel Alcatel pixi 4 (5) Alcatel i216x Alcatel pixi3(4.5) Alcatel pixi3(4) Alcatel PLAY P1 Alcatel playp1 Alcatel pop 2 Alcatel pop 2 (5) Alps Tesla Asus Asusx018d Asus Fonepad 7 (ME175CG) Asus PadFone S (PF500KL) Asus zb500kg Asus zb551kl Asus zb555kl Asus zc520kl Asus zc554kl Asus zenfone 2 laser (ze500kg) Asus zenfone 2 laser (ze500kl) Asus zenfone 2 laser (ze550kl) Asus zenfone 3 max (zc520tl) Asus zenfone 4 (a400cg) Asus ZenFone 4 (A450CG) Asus zenfone 5 Asus ZenFone 5 (A502CG) Asus ZenFone 5 LTE (A500KL) Asus zenfone 6 Asus zenfone c (zc451cg) Asus zenfone go (zc451tg) Asus zenfone go (zc500tg) Asus zenfone max Asus zenpad 8.0 (z380kl) Asus zenpad c 7.0 Asus zenpad c 7.0 (z170mg) Beeline pro 6 Beeline Tab Beeline Tab 2 Blackview a7 Blackview bv6000s BQ BQ-5059 BQ BQs-5020 BQ BQs-5050 BQ BQs-5065 BQ BQs-5070 BQ BQs-5520 BQ-5059 strike power BQru BQ-4072 strike mini BQru BQ-5000l BQru BQ-5009l