Cloud Connectivity and Embedded Sensory Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Flying Cloud 4/13/17 11:26 PM Flying Cloud 26RB
67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 1 2018 Flying Cloud 4/13/17 11:26 PM Flying Cloud 26RB 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 2 4/13/17 11:26 PM There’s a Flying Cloud on your horizon. 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 3 4/13/17 11:26 PM Wake up in a dream. No matter what configuration, the Airstream Flying Cloud is a dream written in metal, wood and glass. You see it from the perfectly riveted aluminum, to the gleaming cabinetry, to the windows – which are everywhere. Whether you’re lounging on one of the couches or spending a late morning in bed, you can choose between a panoramic view bathed in natural light – or draw the blinds to spend the day in cozy seclusion. Dinette? Lounge? Bed? Sure. 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 4 4/13/17 11:26 PM 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 5 4/13/17 11:26 PM 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 6 4/13/17 11:26 PM For something so sturdy, it sure is flexible. The Airstream Flying Cloud is our most popular, most versatile unit. With a wide range of sizes in multiple floorplans, there’s a Flying Cloud out there that’s “just right” for everyone. It’s the perfect balance of size, capability and signature Airstream style and quality. If you can’t find one that speaks to you, then you’re not listening. Choose between a queen for extra sprawl or two twins for ease of access. 67288_AIRSTR-4315_FlyingCloud Brochure_FFv.indd 7 4/13/17 11:26 PM Fun fact: One boot cubby saves 3000 hours of sweeping. -

Make up for Ever and Kehlani Launch Aqua Xl Color Collections: the 24-Hour Lasting* Athleisure Makeup Line
@makeupforeverofficial @kehlani #makeupforever #performincolor #athleisure MAKE UP FOR EVER AND KEHLANI LAUNCH AQUA XL COLOR COLLECTIONS: THE 24-HOUR LASTING* ATHLEISURE MAKEUP LINE Paris, France – April 28, 2017 – Esteemed makeup artistry brand MAKE UP FOR EVER and R&B sensation KEHLANI team up for a global artistic collaboration, revealing the launch of two new, high performance, long-wear, waterproof color collections for the eyes. AQUA XL COLOR PAINT cream eye shadows and AQUA XL INK LINER liquid eyeliners, available worldwide May 2017. Discover the video here: https://youtu.be/3NoF428Jlf8 The artistic collaboration, which includes the launch of 2 collections within MAKE UP FOR EVER’s AQUA XL franchise, provides KEHLANI with makeup artists and makeup for all her artistic endeavors, including tour dates and shoots. KEHLANI stars in the 2017 AQUA XL campaign visual and videos, produced in partnership with MAKE UP FOR EVER. “MAKE UP FOR EVER makes me feel powerful on stage because I feel like I look good - like I look like myself, so I can be confident and have fun. I also know MAKE UP FOR EVER makeup is not going to melt or come off while I’m performing, so I don’t have to think about what’s happening with my makeup,” said KEHLANI. “I feel very honored to be part of the close-knit MAKE UP FOR EVER community. This is my first artistic collaboration with any brand and I am so happy to be in this amazing group of people who inspire me daily with their passion for makeup and for this awesome brand.” Inspired by performers’ and backstage makeup artists’ needs since its 1984 beginnings, MAKE UP FOR EVER develops products to meet harsh environmental demands of discerning makeup users, and AQUA XL is no exception. -

Download the Jukebox Music List
Jukebox Music List December 2020 110 RAPTURE 2 PAC CALIFORNIA LOVE 28 DAYS RIP IT UP 28 DAYS RIP IT UP 28 DAYS AND APOLLO FOUR FORTY SAY WHAT 3 DOORS DOWN KRYPTONITE 3 DOORS DOWN LET ME GO 3 DOORS DOWN LOSER 3 DOORS DOWN KRYPTONITE 3 DOORS DOWN HERE WITHOUT YOU 3 DOORS DOWN HERE WITHOUT YOU 3 DOORS DOWN ITS NOT MY TIME 3 DOORS DOWN BE LIKE THAT 3 JAYS FEELING IT TOO 3 JAYS IN MY EYES 3 THE HARDWAY ITS ON 360 FT GOSSLING BOYS LIKE YOU 360 FT JOSH PYKE THROW IT AWAY 3LW NO MORE 3O!H3 FT KATY PERRY STARSTRUKK 3OH!3 DONT TRUST ME 3OH!3 DONT TRUST ME 3OH!3 DOUBLE VISION 3OH!3 STARSTRUKK ALBUM VERSION 3OH!3 AND KESHA MY FIRST KISS 4 NON BLONDES WHATS UP 4 NON BLONDES MORPHINE AND CHOCOLATE 4 NON BLONDES SUPERFLY 4 NON BLONDES DEAR MR PRESIDENT 4 NON BLONDES CALLING ALL THE PEOPLE 4 NON BLONDES DRIFTING 4 NON BLONDES NO PLACE LIKE HOME 4 NON BLONDES PLEASANTLY BLUE 4 NON BLONDES TRAIN 4 NON BLONDES OLD MR HEFFER 4 NON BLONDES SPACEMAN 48 MAY LEATHER AND TATTOOS 48 MAY INTO THE SUN 48 MAY HOME BY 2 48 MAY HOME BY 2 48 MAY NERVOUS WRECK 48 MAY NERVOUS WRECK 48 MAY BIGSHOCK 5 SECONDS OF SUMMER EVERYTHING I DIDNT SAY 5 SECONDS OF SUMMER YOUNGBLOOD 5 SECONDS OF SUMMER KISS ME KISS ME 5 SECONDS OF SUMMER SHE LOOKS SO PERFECT 5 SECONDS OF SUMMER GOOD GIRLS 5 SECONDS OF SUMMER AMNESIA 5 SECONDS OF SUMMER EASIER 5 SECONDS OF SUMMER DONT STOP 5 SECONDS OF SUMMER TEETH 5 SECONDS OF SUMMER SHES KINDA HOT 50 CENT WINDOW SHOPPER 50 CENT 21 QUESTIONS 50 CENT IN DA CLUB 50 CENT JUST A LIL BIT 50 CENT STRAIGHT TO THE BANK 50 CENT CANDY SHOP 50 CENT CANDY SHOP -

Tony G DJ and Karaoke Services 520-250-8669 [email protected]
Tony G DJ and Karaoke Services 520-250-8669 [email protected] 10 CC - I'm Not In Love 99 Problems - Hugo Abba - Waterloo 10,000 Maniacs - Candy Everybody WantsA Chorus Line- At The Ballet Abelardo Pulido Buenrostro - Entrega Total 10,000 Maniacs - More Than This A Cruz Lavana - Qiero Una Novia PechugonaAC DC - Back In Black 10,000 Maniacs - These Are The Days 10,000A Day Maniacs To Remember • If It Means a Lot toAC You DC - Big Balls 10,000 Maniacs - Trouble Me A Great Big World ft. Futuristic - Hold EachAC Other DC - Dirty Deeds Done Dirt Cheap 112 - Dance With Me A Great Big World, Christina Aguilera - SayAC Something DC - Girls Got( Version, Rhythm No Backing 112 Feat Ludacris - Hot and Wet (Rap) Vocals) AC DC - Hard As A Rock 1910 Fruitgum Co. - Simon Says A Little Dive Bar In Dahlonega (In the StyleA Cof DC Ashley - Hell's McBride) Bells with 2 Live Crew - Me So Horny (Rap) A New Found Glory - Heaven AC DC - It's A Long Way To The Top 21 Savage - Bank Account A Perfect Circle - Judith AC DC - Money Talks 3 Doors Down - Be Like That A Perfect Circle - Weak and Powerless AC DC - Problem Child 3 Doors Down - Here Without You A Taste Of Honey - Boogie Oogie Oogie Ac Dc - Sin City 3 Doors Down - Kryptonite A Través Del Vaso - - Grupo Arranke AC DC - Stiff Upper Lip 3 Doors Down - Kryptonite A. Campbell & L. Mann - Dark End Of TheAC Street DC - Thunderstruck 3 Doors Down - When I’m Gone A. -

Songs Albums
RIAA AUGUST 2018 GOLD & PLATINUM John Mayer | Continuum AWARDS ALBUMS Columbia Records DJ Snake | Encore In August, RIAA certified Interscope Records 253 Song Awards and 57 Album Awards. All RIAA Awards dating back to 1958 are available at riaa.com/gold- platinum! Don’t miss the NEW riaa.com/goldandplatinum60 site celebrating 60 years of Anne-Marie | Speak Your Mind Kyle | Light of Mine Warner Bros Records Gold & Platinum Awards in the Atlantic Records United States and many more #RIAATopCertified milestones for your favorite artists! SONG ALBUM AWARDS 253 AWARDS 57 Travis Scott | Astroworld Epic Records SONGS OneRepublic | Counting Stars Camila Cabello | Havana Niall Horan | Slow Hands Russ | Losin Control Cam | Burning House Mosley Music/Interscope (Feat. Young Thug) Capitol Records Columbia/Russ My Way Inc Arista Nashville Epic Records Chris Janson | Buy Me A Boat Trace Adkins | You're Gonna Selena Gomez | Back To You Kaleo | All the Pretty Girls Kenny Chesney | Get Along Warner Bros Miss This Interscope Records Elektra/Atlantic Records Blue Chair Records/Warner Capitol Nashville Bros Nashville www.riaa.com // // // GOLD & PLATINUM AWARDS AUGUST | 8/1/18 - 8/31/18 MULTI PLATINUM SINGLE | 67 Cert Date | Title | Artist | Genre | Label | Plat Level | Release Date | R&B/ 8/10/2018 Big Sean Def Jam 10/31/2016 Bounce Back Hip Hop R&B/ 8/20/2018 Big Sean Def Jam 1/30/2015 Blessings Hip Hop 8/28/2018 Burning House Cam Country Arista Nashville 3/31/2015 8/30/2018 Havana Camila Cabello Pop Epic 8/3/2017 (Feat. Young Thug) R&B/ 8/3/2018 I Like It (Feat. -

Biocoder DIY/BIO NEWSLETTER SUMMER 2014
BioCoder DIY/BIO NEWSLETTER SUMMER 2014 Implanting Evolution Mitch “Rez” Muenster Open Source Biotech Consumables John Schloendorn Why the Synthetic Biology Movement Needs Product Design Sim Castle Chemical Safety in DIYbio Courtney Webster Beer Bottle Minipreps Joe Rokicki Did you enjoy this issue of BioCoder? Sign up and we’ll deliver future issues and news about the community for FREE. http://oreilly.com/go/biocoder-news BioCoder SUMMER 2014 BIOCODER Copyright © 2014 O’Reilly Media. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or [email protected]. Editors: Mike Loukides and Nina DiPrimio Proofreader: Amanda Kersey Production Editor: Kara Ebrahim Cover Designer: Randy Comer Copyeditor: Charles Roumeliotis Illustrator: Rebecca Demarest July 2014 The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. BioCoder and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the infor‐ mation contained herein. -

Choir Reflects on Carnegie Hall Performance NEWS
The Collegian Volume 112 2014-2015 Article 24 5-5-2015 Volume 112, Number 24 - Tuesday, May 5, 2015 Saint Mary's College of California Follow this and additional works at: https://digitalcommons.stmarys-ca.edu/collegian Part of the Higher Education Commons Recommended Citation Saint Mary's College of California (2015) "Volume 112, Number 24 - Tuesday, May 5, 2015," The Collegian: Vol. 112 , Article 24. Available at: https://digitalcommons.stmarys-ca.edu/collegian/vol112/iss1/24 This Issue is brought to you for free and open access by Saint Mary's Digital Commons. It has been accepted for inclusion in The Collegian by an authorized editor of Saint Mary's Digital Commons. For more information, please contact [email protected]. MORAGA, CALIFornia • VOLUME 112, NUMBER 24 • TuesdAY, MAy 5, 2015 • sTMARYSCOLLEGIAN.COM • TwiTTER: @SMC_COLLEgian • FACEBOOK.COM/SmccOLLEGIAN What’s Inside Choir reflects on Carnegie Hall performance NEWS EDITORIALS ON SAINT MARy’S First, a look at four areas that SMC needs to improve on. Second, advice for students to care about campus activities and why to get involved. PAGE 2 BEYOND THE BUBBLE A brief look at the state of world affairs, including gang violence erupting in Mexico, progress on the case of Freddie Gray, and more. PAGE 3 OPINION SHORTLY AFTER performing at Carnegie Hall, the Saint Mary’s choir and glee club also performed at the Saint Mary’s convocation on Wednesday, April 22 in celebration of De La Salle Week. (Andrew Nguyen/ COLLEGIAN) HARVARD BUSINESS SCHOOL CREATES PROGRAM TO ENCOURAGE FEMALE APPLICANTS F irst-year members emphasize humility and honor of the performance Program fails to make a substantial BY ELIZABETH MAGNO on Saturday night. -

Kehlani-Press-Kit-2015.Pdf
December 8, 2015 The 107 Best Songs of 2015 27. Kehlani f. Coucheron, “Alive” Being a fan of Kehlani is like being a fan of J. Cole. You believe that full projects should be loved as much as singles, that stars should be socially conscious, and that lyrics should be revealing. You want them to make it to radio, but by defying radio’s norms. You cling to others who feel the same way. You see them at the concerts you buy tickets for, wearing the same T-shirt you purchased. Kehlani isn’t for every target demo, she’s just for her people. Lots of young women, more than a few young men, and anyone who’s felt good after proving—to themselves or others—a capability to pick themselves up after a shitty time. Resilience is the subject of countless pop songs, but few people embody it as well as Kehlani, who looked after herself through a tumultuous childhood, and has found purpose in looking after others. “Alive,” the closer of her album-presented-as-mixtape You Should Be Here, is a pact between one self-empowered artist and her self-empowered fans. You can start over as many times as you want, it promises. I believe her. —Naomi Zeichner October 6, 2015 Catching up with Kehlani She discusses her writing process, being inspired by partynextdoor, and rainy days "Sorry, I'm just writing a song," Kehlani says between interview questions as her French tips clack away at her iPhone screen. Her genuine apology proves two things: One, that she has enviable multitasking skills, and two, that even with all of the attention she's gained, the R&B singer hasn't lost sight of what it is that drew her dedicated fanbase—her uncanny ability to write lyrics that strike a chord within her listeners, and to sing them with a raw and moving emotion. -

FRANKIE CARLL PRODUCTIONS DJ SONG LIST Song Title Artist Song Title Artist Song Title Artist
FRANKIE CARLL PRODUCTIONS DJ SONG LIST Song Title Artist Song Title Artist Song Title Artist BEACH BOYS 25 OR 6 TO 4 CHICAGO A SONG FOR MAMA (Shortened Version) METRO STATION 2U DAVID GUETTA FT. JUSTIN BIEBERA SONG FOR MY DAUGHTER RAY ALLAIRE # 41 DAVE MATTHEWS BAND 3 BRITNEY SPEARS A SONG FOR MY SON DONNA LEE HONEYWELL #1 NELLY 3 (REMIX) A SONG FOR MY SON (Shortened Version) #BEAUTIFUL MARIAH CAREY 360 WILL HOGE A SONG FOR MY SON (Shortened Version) MIKKI VIERICK (EVERYTHING I DO) I DO IT FOR YOU BRYAN ADAMS 4 MINUTES MADONNA ft Justin Timberlake A STRING OF PEARLS GLENN MILLER ORCHESTRA (GET UP) I FEEL LIKE BEING A SEX MACHINE JAMES BROWN 4 ON THE FLOOR (Bridal Party Intro) GERALD ALBRIGHT A SUMMER SONG CHAD & JEREMY (GOD MUST HAVE SPENT) A LITTLE MORE TIME NSYNC 4:44 JAY Z A TEENAGER IN LOVE DION & THE BELMONTS (HOT S**T) COUNTRY GRAMMAR NELLY 409 BEACH BOYS A THOUSAND MILES VANESSA CARLTON (I CAN'T GET NO) SATISFACTION ROLLING STONES 5 O'CLOCK (CLEAN VERSION) T-PAIN FT. LILY ALLEN A THOUSAND STAR KATHY YOUNG & THE INNOCENTS (I CAN'T HELP) FALLING IN LOVE UB40 50 WAYS TO LEAVE YOUR LOVER PAUL SIMON A THOUSAND YEARS CHRISTINA PERRI (IT MUST'VE BEEN OL') SANTA CLAUS HARRY CONNICK, JR. 50 WAYS TO SAY GOODBYE TRAIN A THOUSAND YEARS THE PIANO GUYS (IT) FEELS SO GOOD STEVEN TYLER 500 MILES (I'M GONNA BE) PROCLAIMERS A WELL RESPECTED MAN THE KINKS (I'VE HAD) THE TIME OF MY LIFE BILL MEDLEY / JENNIFER WARNES5-1-5-0 DIERKS BENTLEY A WHITE SPORT COAT (AND A PINK CARNATION) MARTY ROBBINS (KEEP FEELING) FASCINATION HUMAN LEAGUE 7 DRAKE F./WIZKID & KYLA A WHOLE NEW WORLD PEABO BRYSON / REGINA BELLE (KISSED YOU) GOOD NIGHT GLORIANA 7 RINGS ARIANA GRANDE A WINK AND A SMILE HARRY CONNICK JR. -

Vrealize Operations Cloud Configuration Guide
vRealize Operations Cloud Configuration Guide 04 AUG 2021 VMware vRealize Operations Cloud services vRealize Operations Cloud Configuration Guide You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ VMware, Inc. 3401 Hillview Ave. Palo Alto, CA 94304 www.vmware.com © Copyright 2021 VMware, Inc. All rights reserved. Copyright and trademark information. VMware, Inc. 2 Contents About Configuration 11 1 Accessibility Compliance 12 2 Connecting to Data Sources 15 Solutions Repository 17 Managing Solutions in vRealize Operations Cloud 19 Manage Cloud Accounts 20 Manage Other Accounts 22 Adding Solutions 24 Marketplace for Solutions 25 Managing Solution Credentials 26 Credentials 27 Manage Credentials 28 Managing Collector Groups 28 Collector Group Workspace 29 Adding a Collector Group 30 Editing Collector Groups 31 vSphere 32 Configure a vCenter Server Cloud Account in vRealize Operations Cloud 33 Configure User Access for Actions 38 Cloud Account Information - vSphere Account Options 39 VMware Cloud on AWS 41 Configuring a VMware Cloud on AWS Instance in vRealize OperationsvRealize Operations Cloud 41 Azure VMware Solution 46 Configuring an Azure VMware Solution Instance in vRealize Operations Cloud 46 Known Limitations 46 Google Cloud VMware Engine 47 Configuring a Google Cloud VMware Engine Instance in vRealize Operations Cloud 47 Known Limitations 47 VMware Cloud on Dell EMC 48 Configuring a VMware Cloud on Dell EMC Instance in vRealize Operations Cloud 48 Known Limitations 48 AWS 49 -

ST/LIFE/PAGE<LIF-005>
| FRIDAY, MAY 18, 2018 | THE STRAITS TIMES | happenings life D5 Singtel-Singapore Cancer GIGS Anjali Raguraman recommends Society Race Against Cancer It is the 10th anniversary of the Cantopop With Alex Chia annual run and this year’s event will The home-grown singer performs Picks feature the 10km and 15km classics of the 1970s and 1980s made competitive runs and a 5km fun run. popular by Cantopop legends Sam The race raises funds for cancer Hui, Alan Tam, The Wynners, Beyond Gigs treatment subsidies, welfare and Leslie Cheung. Chia, signed to assistance, cancer rehabilitation, Hong Kong’s Sun Entertainment hospice care, cancer screenings, Culture, was invited in 2015 to sing research, public education and the theme song of Hong Kong movie cancer support group initiatives. SPL 2 in Mandarin and Cantonese. The WHERE: Angsana Green, East Coast film stars Louis Koo and Simon Yam. Park MRT: Bedok WHEN: July 22, WHERE: Esplanade Outdoor Theatre, 7 - 10am ADMISSION: Past 1 Esplanade Drive MRT: Esplanade/ participants $39 - $51; first-timers City Hall WHEN: Tomorrow, 7.15, 8.30 & $48 - $62 ($43 - $56 for early birds 9.45pm ADMISSION: Free who register by June 10); INFO: esplanade.com students $34 - $39 ($30 - $35) INFO: Register at Cheryl Fong: Songs We raceagainstcancer.org.sg by July 9 Grew Up With Cheryl Fong and her acoustic trio revisit some of the songs they heard growing up by adding their own jazzy TALKS swing and bossa nova twist. She will also sing some of her favourite tunes, Taming Cancer Naturally Forum including Night In Shanghai and Little Can cancer survivors have longevity, Umbrella. -
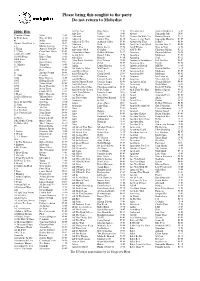
Please Bring This Songlist to the Party Do Not Return to Mobydisc
Please bring this songlist to the party Do not return to Mobydisc Act Yo Age Bliss N Eso 13-08 Already Gone Taylor Henderson 14-08 2000s Hits Add Suv Uffie 10-09 Always Samantha Jade 2016- Counting Sheep Safia 15-05 Addicted Saving Abel 09-02 Always Be With You Human Nature 01-1104 In Your Arms Nico & Vinz 14-10 Addicted Simple Plan 04-10 Always Come Back Samantha Mumba 01-05 #1 Nelly 02-01 Addicted To You Anthony Callea 07-01 Always On Time Ja Rule 02-04 (Don't) Give Hate A Jamiroquai 06-02 Adelante Sash 00-05 Am I On Your Mind Oxygen Feat A 03-05 +1 Martin Solveig 15-12 Adore You Harry Styles 20-04 Am I Wrong Nico & Vinz 14-06 1 Thing Amerie Feat Eve 05-06 Adventure Of A Coldplay 15-12 AM To PM Christina Milian 01-12 1, 2 Step Ciara Feat Missy 05-01 Advertising Space Robbie Williams 05-12 Amazing George Michael 04-04 1-800 -273 -8255 Logic 17-08 Aerial Love Daniel Johns 15-04 Amazing Madonna 01-08 10,000 Hours Dan + Shay 19-11 Afrodisiac Brandy 04-10 Amazing Seal 07-12 1000 Stars Natalie 09-05 After Party [Explicit] Don Toliver 20-06 America's Suitehearts Fall Out Boy 09-02 1000X Jarryd James 2016- Afterglow INXS 06-07 American Boy Estelle 08-06 07 11 Minutes Yungblud 19-03 Again Lenny Kravitz 01-03 American Dream MKTO 14-05 123 Sofia Reyes 18-04 Ah Yeah So What Will Sparks 14-12 Amer ican Girl Bonnie McKee 13-10 1234 Feist 08-02 Ain't Been Done Jessie J 15-08 American Life Madonna 03-05 16 Sneaky Sound 09-04 Ain't Giving Up Craig David 2016- American Pie Madonna 00-03 19 -2000 Gorillaz 01-10 Ain't It Fun Paramore 13-1010 Amnesia Ian