Downloaded All 621 Driver Tarballs (.Tar.Gz) from Fars Robotics Website [Nd]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netpbm Format - Wikipedia, the Free Encyclopedia
Netpbm format - Wikipedia, the free encyclopedia http://en.wikipedia.org/wiki/Portable_anymap Netpbm format From Wikipedia, the free encyclopedia (Redirected from Portable anymap) The phrase Netpbm format commonly refers to any or all Portable pixmap of the members of a set of closely related graphics formats used and defined by the Netpbm project. The portable Filename .ppm, .pgm, .pbm, pixmap format (PPM), the portable graymap format extension .pnm (PGM) and the portable bitmap format (PBM) are image file formats designed to be easily exchanged between Internet image/x-portable- platforms. They are also sometimes referred to collectively media type pixmap, -graymap, [1] as the portable anymap format (PNM). -bitmap, -anymap all unofficial Developed Jef Poskanzer Contents by 1 History Type of Image file formats 2 File format description format 2.1 PBM example 2.2 PGM example 2.3 PPM example 3 16-bit extensions 4 See also 5 References 6 External links History The PBM format was invented by Jef Poskanzer in the 1980s as a format that allowed monochrome bitmaps to be transmitted within an email message as plain ASCII text, allowing it to survive any changes in text formatting. Poskanzer developed the first library of tools to handle the PBM format, Pbmplus, released in 1988. It mainly contained tools to convert between PBM and other graphics formats. By the end of 1988, Poskanzer had developed the PGM and PPM formats along with their associated tools and added them to Pbmplus. The final release of Pbmplus was December 10, 1991. In 1993, the Netpbm library was developed to replace the unmaintained Pbmplus. -

Supported File Types and Size Limits
Data Security Supported File Formats and Size Limits Supported File Formats and Size Limits | Data Security Solutions | Version 7.7.x This article provides a list of all the Supported File Formats that can be analyzed by Websense Data Security, as well as the File Size Limits for network, endpoint, and discovery functions. Supported File Formats Supported File Formats and Size Limits | Data Security Solutions | Version 7.7.x This article provides a list of all the file formats that Websense Data Security supports. The file formats supported are constantly being updated and added to. File Type Description 7-Zip 7-Zip format Ability Comm Communication Ability Ability DB Database Ability Ability Image Raster Image Ability Ability SS Spreadsheet Ability Ability WP Word Processor Ability AC3 Audio File Format AC3 Audio File Format ACE ACE Archive ACT ACT AD1 AD1 evidence file Adobe FrameMaker Adobe FrameMaker Adobe FrameMaker Book Adobe FrameMaker Book Adobe Maker Interchange Adobe Maker Interchange format Adobe PDF Portable Document Format Advanced Streaming Microsoft Advanced Streaming file Advanced Systems Format Advanced Systems Format (ASF) Data Security - Supported Files Types and Size Limits 1 Data Security Supported File Formats and Size Limits File Type Description Advanced Systems Format Advanced Systems Format (WMA) Advanced Systems Format Advanced Systems Format (WMV) AES Multiplus Comm Multiplus (AES) Aldus Freehand Mac Aldus Freehand Mac Aldus PageMaker (DOS) Aldus PageMaker for Windows Aldus PageMaker (Mac) Aldus PageMaker -

Raster Data Implemented in a FPGA Device J
ISSN 2395-8618 Raster data implemented in a FPGA device J. Sandoval-Gutierrez, J.A. Alvarez-Cedillo, J.C. Herrera-Lozada, T. Alvarez-Sanchez and M. Olguin-Carbajal Abstract—The instrumentation for image processing sends file. In a review of various applications aimed at image pro- the information through a communication interface, and the cessing, the characteristics of an image were found in different applications are developed by two general methods: a Software disciplines. Specifically an overview of the major file formats Development Kit as a PC-based programming language and a hardware implementation. In the first method, the users are currently used in medical imaging, define universal concepts to limited by other processess that are being executed at the same all file formats such as pixel depth, photometric interpretation, time, energy consumption, size of the system, mobility, and the metadata and pixel data [12]. A particular software package visual interface. Conversely, an embedded system provides more for image processing of electron, micrographs, interpretation efficient features than general purpose software. To confirm this of reconstructions, molecular modeling and general image idea, in this paper VGA display is used as the output reference to compare the results applying a set of raster data as portable processing generate a text file [13]. pixmap (*.ppm), graymap (*.pgm) and bitmap (*.pbm). Two tests Some image file format provided by GIMP software are: in a different field of study are comparing: pre-processing of an Animation .flic, Animation .mng, PostScript .ps, Icon .ico, image format with four operations: original, grayscale, binary Digital Imaging and Comunications in Medicine .dcm .dicom, and inverted; the other test is a laser triangulation measurement system. -

MIPAV Online Help
Glossary This glossary defines all acronyms and selected terms used in this guide. Numerics 2D. Two dimensional. 3D. Three dimensional. 4D. Four dimensional. 5D. Five dimensional. A ACR. American College of Radiology. The ACR, in conjunction with National Electrical Manufacturers Association, developed the Digital Image Communication in Medicine standard. AE. Application entity. Analyze. Unix-based medical-imaging display and analysis software developed by the Mayo Foundation. MIPAV allows researchers to process, analyze, and visualize Analyze-formatted image files on virtually any platform. MIPAV User Guide Volume 1 708 12/2/08 MIPAV User’s Guide, Volume 1, Basics M I P A V M e d i c a l I m a g e P r o c e s s i n g, A n a l y s i s, & V i s u a l i z a t i o n API. Application program interface. Pieces of code that are used to perform common tasks, such as generate a standard window frame. Software developers often incorporate these pieces of code into their programs. An API is analogous to a package of form letters; APIs reduce programming time because common functions have already been written. BMP. Extension for Windows Bitmap formatted files. BMP is the standard bitmap graphics file format that is used in the MS Windows environment. boolean. This data type refers to data that represents symbolic relationships between entities, such as those implied by the logical operators AND, NOT, and OR. Examples of valid boolean values are TRUE and FALSE. bytecode. Compiled format for Java code. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -
Opentext Brava Enterprise Supported Formats
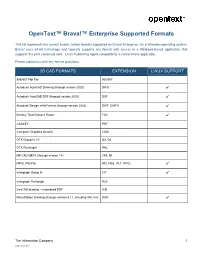
OpenText™ Brava!™ Enterprise Supported Formats This list represents the current known, tested formats supported by Brava! Enterprise. On a Windows operating system, Brava! uses 64-bit technology and typically supports any format with access to a Windows-based application that supports the print canonical verb. Linux Publishing Agent compatibility is noted where applicable. Please contact us with any format questions. 2D CAD FORMATS EXTENSION LINUX SUPPORT 906/907 Plot File 906/907 Autodesk AutoCAD Drawing (through version 2020) DWG ✓ Autodesk AutoCAD DXF (through version 2020) DXF ✓ Autodesk Design Web Format (through version 2020) DWF, DWFX ✓ Bentley Tiled Group 4 Raster TG4 ✓ CADKEY PRT Computer Graphics Metafile CGM GTX Group III, IV G3, G4 GTX Runlength RNL HP CAD ME10 (through version 13) CMI, MI HPGL Plot File 000, HGL, PLT, HPGL ✓ Intergraph Group IV CIT ✓ Intergraph Runlength RLE IronCAD drawing – embedded PDF ICD MicroStation Drawing (through version 8.11, including XM, V8i) DGN ✓ The Information Company 1 2020-09 16 EP7 Brava! Enterprise Formats 3D CAD FORMATS 1 EXTENSION LINUX SUPPORT Adobe 3D PDF 7 PDF ✓ Autodesk AutoCAD Drawing DWG ✓ Autodesk Design Web Format DWF ✓ Autodesk Inventor (through version 2019) IPT, IAM ✓ Autodesk Revit 8 (2015 to 2020) RVT, RFA ✓ CATIA V4 MODEL, SESSION, DLV, EXP ✓ CATIA V5 CATPart, CATProduct, ✓ CATShape, CGR CATIA V6 3DXML ✓ HOOPS Streaming Format 2 HSF ✓ I-DEAS and NX I-DEAS 6 MF1, ARC, UNV, PKG ✓ Industry Foundation Classes (versions 2, 3, 4) IFC ✓ Initial Graphics Exchange Specification -

Scape D10.1 Keeps V1.0
Identification and selection of large‐scale migration tools and services Authors Rui Castro, Luís Faria (KEEP Solutions), Christoph Becker, Markus Hamm (Vienna University of Technology) June 2011 This work was partially supported by the SCAPE Project. The SCAPE project is co-funded by the European Union under FP7 ICT-2009.4.1 (Grant Agreement number 270137). This work is licensed under a CC-BY-SA International License Table of Contents 1 Introduction 1 1.1 Scope of this document 1 2 Related work 2 2.1 Preservation action tools 3 2.1.1 PLANETS 3 2.1.2 RODA 5 2.1.3 CRiB 6 2.2 Software quality models 6 2.2.1 ISO standard 25010 7 2.2.2 Decision criteria in digital preservation 7 3 Criteria for evaluating action tools 9 3.1 Functional suitability 10 3.2 Performance efficiency 11 3.3 Compatibility 11 3.4 Usability 11 3.5 Reliability 12 3.6 Security 12 3.7 Maintainability 13 3.8 Portability 13 4 Methodology 14 4.1 Analysis of requirements 14 4.2 Definition of the evaluation framework 14 4.3 Identification, evaluation and selection of action tools 14 5 Analysis of requirements 15 5.1 Requirements for the SCAPE platform 16 5.2 Requirements of the testbed scenarios 16 5.2.1 Scenario 1: Normalize document formats contained in the web archive 16 5.2.2 Scenario 2: Deep characterisation of huge media files 17 v 5.2.3 Scenario 3: Migrate digitised TIFFs to JPEG2000 17 5.2.4 Scenario 4: Migrate archive to new archiving system? 17 5.2.5 Scenario 5: RAW to NEXUS migration 18 6 Evaluation framework 18 6.1 Suitability for testbeds 19 6.2 Suitability for platform 19 6.3 Technical instalability 20 6.4 Legal constrains 20 6.5 Summary 20 7 Results 21 7.1 Identification of candidate tools 21 7.2 Evaluation and selection of tools 22 8 Conclusions 24 9 References 25 10 Appendix 28 10.1 List of identified action tools 28 vi 1 Introduction A preservation action is a concrete action, usually implemented by a software tool, that is performed on digital content in order to achieve some preservation goal. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.4.x, v8.5.x This article provides a list of the file formats that can be analyzed by Forcepoint DLP, as well as the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2018 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.4.x, v8.5.x The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive Formats, page 3 ● Backup Formats, page 5 ● Computer-Aided Design Formats, page 6 ● Cryptography Formats, page 7 ● Database Formats, page 8 ● Desktop Publishing Formats, page 9 ● Executable Formats, page 10 ● Font Formats, page 11 ● Library Formats, page 12 ● Mail Formats, page 13 ● Miscellaneous Formats, page 14 ● Multimedia Formats, page 16 ● Object Formats, page 17 ● Presentation Formats, page 18 ● Project Management Formats, page 19 ● Raster Graphics Formats, page 20 ● Spreadsheet Formats, page 22 ● Text and Markup Formats, page 24 ● Vector Graphics Formats, page 25 ● Word Processing Formats, page 27 Supported file formats are added to and updated frequently. Supported File Formats and Size Limits 2 Archive Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.4.x, v8.5.x File Format Description 7-Zip 7-Zip format ACE ACE Archive AppleDouble AppleDouble AppleSingle AppleSingle ARC/PAK Archive ARC/PAK Archive ARJ ARJ Archive ARJ -

Non-DICOM Conformance Statement Easyviz 8.2
Non-DICOM Conformance Statement EasyViz 8.2 March 24. 2021 Revision 1.2 Document ID: 2020.02.001 Vital Images A/S Vital Images shall not be liable for errors Krumtappen 4, Etage 3 contained herein or for incidental or DK-2500 Valby consequential damages in connection with the furnishing, performance or use of this Denmark publication. Vital Images reserves the right to revise this publication and to make changes www.vitalimages.com/contact to its content at any time, without obligation to notify any person or entity of such revisions and changes. This publication may only be used in connection with the promotion, sales, installation and use of Vital Images products. Prepared By: Vital Images Form # 2019.06.011-20190619-v1 Vital Images Company Confidential Table of Contents 1 Non-DICOM Conformance Statement Overview ................................................... 3 2 Specification ................................................................................................................ 3 3 Supported MIME types ............................................................................................. 3 4 Annotations on non-DICOM images ........................................................................ 4 5 No export or transfer of MHD data .......................................................................... 4 Revision History Revision Date Author Changes 1.0 March 20, 2020 Karen Piech New for 8.0 1.1 September 25, 2020 Karen Piech Updated for 8.1 1.2 March 24, 2021 Karen Piech Updated for 8.2 EasyViz 8.2 Page 2 of 4 Non-DICOM Conformance Statement v1.2 Vital Images Company Confidential 1 Non-DICOM Conformance Statement Overview The EasyViz image display implements the necessary IHE Mobile access to Health Documents (MHD) services necessary to query, retrieve and display non-DICOM images and other text-based documents. 2 Specification Non-DICOM content is obtained in accordance with the Find Document References [ITI- 67] specification using the following parameters. -

Solaris X Window System Reference Manual
Solaris X Window System Reference Manual Sun Microsystems, Inc. 2550 Garcia Avenue Mountain View, CA 94043 U.S.A. 1995 Sun Microsystems, Inc., 2550 Garcia Avenue, Mountain View, California 94043-1100 USA. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Portions of this product may be derived from the UNIX system, licensed from UNIX System Laboratories, Inc., a wholly owned subsidiary of Novell, Inc., and from the Berkeley 4.3 BSD system, licensed from the University of California. Third- party software, including font technology in this product, is protected by copyright and licensed from Sun's Suppliers. RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013 and FAR 52.227-19. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, Sun Microsystems, the Sun logo, SunSoft, the SunSoft logo, Solaris, SunOS, OpenWindows, DeskSet, ONC, ONC+, and NFS are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. OPEN LOOK is a registered trademark of Novell, Inc. -

Statistical Graphics Using ODS This Document Is an Individual Chapter from SAS/STAT® 13.1 User’S Guide
SAS/STAT® 13.1 User’s Guide Statistical Graphics Using ODS This document is an individual chapter from SAS/STAT® 13.1 User’s Guide. The correct bibliographic citation for the complete manual is as follows: SAS Institute Inc. 2013. SAS/STAT® 13.1 User’s Guide. Cary, NC: SAS Institute Inc. Copyright © 2013, SAS Institute Inc., Cary, NC, USA All rights reserved. Produced in the United States of America. For a hard-copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others’ rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a) and DFAR 227.7202-4 and, to the extent required under U.S. -

MIME Types MIME Content-Types Supported by Most Web Servers, Identified with File Extensions, Are Listed in the Following Table
MIME Types MIME content-types supported by most web servers, identified with file extensions, are listed in the following table. MIME Tpe Identification File Extension application/acad AutoCAD dwg application/arj compressed archive arj application/astound Astound asd, asn application/clariscad ClarisCAD ccad application/drafting MATRA Prelude drafting drw application/dxf DXF (AutoCAD) dxf application/i-deas SDRC I-DEAS unv application/iges IGES graphics format iges, igs application/java-archive Java archive jar application/mac-binhex40 Macintosh binary BinHex 4.0 hqx application/msaccess Microsoft Access mdb application/msexcel Microsoft Excel xla, xls, xlt, xlw application/mspowerpoint Microsoft PowerPoint pot, pps, ppt application/msproject Microsoft Project mpp application/msword Microsoft Word doc, word, w6w application/mswrite Microsoft Write wri application/octet-stream uninterpreted binary bin application/oda ODA oda application/pdf Adobe Acrobat pdf application/postscript PostScript ai, eps, ps application/pro_eng PTC Pro/ENGINEER part, prt application/rtf Rich Text Format rtf application/set SET (French CAD) set application/sla stereolithography stl application/solids MATRA Prelude Solids sol application/STEP ISO-10303 STEP data st, step, stp application/vda VDA-FS Surface data vda application/x-bcpio binary CPIO bcpio application/x-cpio POSIX CPIO cpio application/x-csh C-shell script csh application/x-director Macromedia Director dcr, dir, dxr application/x-dvi TeX DVI dvi application/x-dwf AutoCAD dwf application/x-gtar GNU