Bootstrapping Generators from Noisy Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tagesprogramm
TAGESPROGRAMM Highlights ab So. 26.09.2021 LaLiga 1 X 2 Ü/U + - H38 So 16:15 FC Barcelona : Levante UD 1,45 4,90 7,10 2,5 1,65 2,25 Premier League 1 X 2 Ü/U + - AF3 So 17:30 Arsenal FC : Tottenham Hotspur 2,25 3,30 3,50 2,5 2,00 1,80 Süper Lig 1 X 2 Ü/U + - DN5 Mo 19:00 Trabzonspor : Alanyaspor 1,60 4,40 5,50 2,5 1,75 2,05 Premier League 1 X 2 Ü/U + - F27 Mo 21:00 Crystal Palace : Brighton & Hove 3,15 3,15 2,50 2,5 2,25 1,65 UEFA Champions League Gruppe A 1 X 2 Ü/U + - BE4 Di 21:00 Paris St. Germain : Manchester City 3,05 3,50 2,35 2,5 1,60 2,35 UEFA Champions League Gruppe B 1 X 2 Ü/U + - DG6 Di 21:00 AC Mailand : Atlético Madrid 2,90 3,25 2,60 2,5 2,15 1,70 UEFA Champions League Gruppe C 1 X 2 Ü/U + - FK8 Di 21:00 Borussia Dortmund : Sporting Lissabon 1,35 5,50 8,80 3,5 2,25 1,65 Hier geht’s zum Download des aktuellen Wettprogramms programm.tipster.de FOLGE DEINEM INSTINKT Hier geht’s zum Download des aktuellen Wettprogramms programm.tipster.de FOLGE DEINEM INSTINKT Tagesprogramm Sonntag, 26.09.2021 Fußball - Deutschland Bundesliga 1 X 2 HC 1 X 2 1X 12 X2 Ü/U + - DM1 So 15:30 VfL Bochum : VfB Stuttgart 3,20 3,50 2,20 1:0 1,65 4,10 3,80 1,65 1,30 1,35 2,5 1,70 2,00 EN2 So 17:30 SC Freiburg : FC Augsburg 1,75 3,70 4,80 0:1 2,80 3,70 2,10 1,19 1,28 2,10 2,5 1,80 1,90 Aktuelle Ligatabelle SP S U N Pkt. -

Midweek Football Results Weekend Football
Issued Date Page WEEKENDMIDWEEK FOOTBALLFOOTBALL RESULTSRESULTS 18/10/2020 08:49 1 / 7 INFORMATION INFORMATION INFORMATION RESULTS RESULTS RESULTS GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM No CAT TIME HT FT No CAT TIME HT FT No CAT TIME HT FT Friday, 16 October, 2020 Saturday, 17 October, 2020 Saturday, 17 October, 2020 60012 ROM3 15:00 0:1 2:1 UNIREA BASCOV CS VEDITA COLONESTI .. 6032 ROM2 11:00 0:1 0:1 FK CSIKSZEREDA MIER.. FC UNIREA 2004 SLOBO.. 6957 RUS4 12:00 : : OKA-M STUPINO LEGION-KHOROSHOVO 6584 NIR 21:45 0:1 0:1 COLERAINE FC BALLYMENA UNITED FC 6033 ROM2 11:00 0:1 0:2 RIPENSIA TIMISOARA METALOGLOBUS BUCU.. 6958 RUS4 12:00 : : SH N2 VO ZVEZDA NOR.. NEVA LEGIRUS 6034 UKR19 11:00 : : FC MINAJ U19 ILLICHIVEC M U19 6959 RUS4 12:00 : : TSARSKOYE SELO PARUS Saturday, 17 October, 2020 6036 UKR19 11:00 : : FC RUKH LVIV U19 DYNAMO KIEV U19 60142 KAZ 12:00 2:0 2:2 FC TARAZ FC KAISAR KYZYLORDA 6001 AUST 06:00 : 5:0 SOUTH HOBART FC CLARENCE ZEBRAS FC 6039 UKR19 11:00 : : SHAKHTAR D. U19 FC LVIV U19 60143 NORW 12:00 : 0:6 IF FLOEYA ASANE FOTBALL DAMER 6002 AUST 06:15 : 1:0 DEVONPORT CITY SC LAUNCESTON CITY FC 6862 HUN19 11:00 0:1 1:2 BUDAPEST HONVED MTK HUNGARIA 60229 ITAW 12:00 : 5:1 CROTONE SPEZIA 6003 AUST 06:15 : 3:0 RIVERSIDE OLYMPIC FC KINGBOROUGH LIONS U.. 6946 RUSUW 11:00 : : CHELYABINSK YOUTH METALLURG MAGNITOG. -

The Business World of Russian Football
THESIS – BACHELOR'S DEGREE PROGRAMME SOCIAL SCIENCES, BUSINESS AND ADMINISTRATION THE BUSINESS WORLD OF RUSSIAN FOOTBALL Issues and Prospects AUTHOR : Roman Andreev LI17SP SAVONIA UNIVERSITY OF APPLIED SCIENCES THESIS Abstract Field of Study Social Sciences, Business and Administration Degree Programme Degree Programme in Business and Administration Author Roman Andreev Title of Thesis The Business World of Russian Football. Issues and Prospects Date 10.12.2020 Pages/Appendices 70/0 Client Organisation /Partners Abstract Beyond any doubt, football, known as soccer in North America, remains to be one of the most influential sport games in the history of humanity. Up to this day, soccer continues to captivate billions of sports enthu- siasts all over the globe. Football has achieved great recognition, and it is now considered the most popular sport in the world. Nowadays it is appropriate and entirely justified to talk about the emergence of the foot- ball industry. Basically, modern soccer can be viewed as an international business, since global player trans- fers are made on a regular basis and international professional tournaments are organized. Moreover, soccer leagues may be now rightfully classified as separate commercialized industries. Certain football tournaments perform much better than their competitors in a business sense. In this work, the Russian Premier League in particular is discussed. The aim of the study is to investigate the historic and current issues of Russian soccer, the reasons for their emergence, and the present state. Furthermore, the commercial prospects and possibilities for local football’s business development are inspected. Potential solu- tions to the outlined problems are demonstrated as well. -
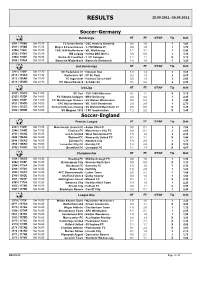
Results 25.09.2021.-26.09.2021
RESULTS 25.09.2021.-26.09.2021. Soccer-Germany Bundesliga HT FT OT/AP Tip Odd 2301 | 1358B Sat 15:30 FC Union Berlin - DSC Arminia Bielefeld 0:0 1:0 1 1,65 2303 | 1358D Sat 15:30 Bayer 04 Leverkusen - 1. FSV Mainz 05 0:0 1:0 1 1,70 2305 | 1358F Sat 15:30 TSG 1899 Hoffenheim - VfL Wolfsburg 1:1 3:1 1 2,50 2302 | 1358C Sat 15:30 RB Leipzig - Hertha BSC Berlin 3:0 6:0 1 1,30 2304 | 1358E Sat 15:30 Eintracht Frankfurt - 1. FC Cologne 1:1 1:1 X 3,75 2306 | 1359A Sat 18:30 Borussia M'gladbach - Borussia Dortmund 1:0 1:0 1 3,20 2nd Bundesliga HT FT OT/AP Tip Odd 2311 | 1359F Sat 13:30 SC Paderborn 07 - Holstein Kiel 1:0 1:2 2 3,65 2313 | 135AC Sat 13:30 Karlsruher SC - FC St. Pauli 0:2 1:3 2 2,85 2312 | 135AB Sat 13:30 FC Ingolstadt - Fortuna Düsseldorf 0:0 1:2 2 2,00 2314 | 135AD Sat 20:30 FC Hansa Rostock - Schalke 04 0:1 0:2 2 2,30 3rd Liga HT FT OT/AP Tip Odd 2323 | 135CF Sat 14:00 SC Verl - TSV 1860 München 0:1 1:1 X 3,75 2325 | 135DF Sat 14:00 FC Viktoria Cologne - MSV Duisburg 2:0 4:2 1 2,45 2326 | 135EF Sat 14:00 FC Wurzburger Kickers - SV Wehen Wiesbaden 0:0 0:4 2 2,40 2321 | 135CD Sat 14:00 1 FC Kaiserslautern - VfL 1899 Osnabrück 2:0 2:0 1 2,70 2322 | 135CE Sat 14:00 Eintracht Braunschweig - SV Waldhof Mannheim 07 0:0 0:0 X 3,25 2324 | 135DE Sat 14:00 SV Meppen 1912 - 1 FC Saarbrucken 1:2 2:2 X 3,40 Soccer-England Premier League HT FT OT/AP Tip Odd 2347 | 1369F Sat 13:30 Manchester United FC - Aston Villa FC 0:0 0:1 2 7,00 2346 | 1369E Sat 13:30 Chelsea FC - Manchester City FC 0:0 0:1 2 2,60 2351 | 136AE Sat 16:00 Leeds United - West -

Page 1 of 48 100 Fri 18:30 3.00 3.10 2.30 1.60
www.eurobet.com.gh Page 1 of 48 .Germany - 2nd Bundesliga (Min.Bet 3) 100 Fri 18:30 MSV Duisburg v 1 FC Kaiserslautern 3.00 3.10 2.30 105 Under/Over 2,5 - / + 1.60 2.20 101 Double chance 1X 12 X2 1.54 1.30 1.33 106 Under/Over 1,5 - / + 2.70 1.35 102 Handicap 1:0 1 X 2 1.54 3.75 4.50 107 Under/Over 3,5 - / + 1.21 3.65 103 Handicap 0:1 1 X 2 6.70 4.35 1.33 110 Draw no bet 1 / 2 2.10 1.57 111 Who wins the 1.half? 1 X 2 3.65 1.95 2.90 115 Both teams to score? Y / N 1.80 1.80 112 Number of goals 0-1 2-3 4+ 2.65 2.05 3.65 116 1.half Under/Over 0,5 - / + 2.45 1.45 114 1st goal 1 X 2 2.30 7.50 1.85 117 1.half Under/Over 1,5 - / + 1.33 2.80 118 Who will score the last goal? 1 X 2 2.25 7.20 1.80 122 Both teams to score 1.H? Y / N 5.30 1.12 119 Number of goals team 1 0 1-2 3+ 2.50 1.60 8.60 123 Team 1 goal Y / N 1.40 2.50 120 Number of goals team 2 0 1-2 3+ 3.10 1.57 5.75 124 Team 2 goal Y / N 1.27 3.10 121 Which half most goal? 1 X 2 3.20 3.20 2.00 125 Team 1 goal 1.H? Y / N 2.35 1.48 126 Team 2 goal 1.H? Y / N 2.05 1.60 127 Sat 11:00 Greuther Furth v Karlsruher SC 2.50 3.10 2.60 132 Under/Over 2,5 - / + 1.60 2.20 128 Double chance 1X 12 X2 1.40 1.30 1.45 133 Under/Over 1,5 - / + 2.70 1.35 129 Handicap 0:1 1 X 2 5.75 3.85 1.45 134 Under/Over 3,5 - / + 1.21 3.65 130 Handicap 1:0 1 X 2 1.40 4.05 5.75 137 Draw no bet 1 / 2 1.75 1.85 138 Who wins the 1.half? 1 X 2 3.10 1.95 3.40 142 Both teams to score? Y / N 1.80 1.80 139 Number of goals 0-1 2-3 4+ 2.65 2.05 3.65 143 1.half Under/Over 1,5 - / + 1.33 2.80 141 1st goal 1 X 2 1.95 7.50 2.15 144 1.half Under/Over 0,5 - / + 2.45 1.45 145 Who will score the last goal? 1 X 2 1.90 7.20 2.10 149 Both teams to score 1.H? Y / N 5.30 1.12 146 Number of goals team 1 0 1-2 3+ 2.90 1.57 6.40 150 Team 1 goal Y / N 1.30 2.90 147 Number of goals team 2 0 1-2 3+ 2.70 1.57 7.20 151 Team 2 goal Y / N 1.33 2.70 148 Which half most goal? 1 X 2 3.20 3.20 2.00 152 Team 1 goal 1.H? Y / N 2.15 1.57 153 Team 2 goal 1.H? Y / N 2.20 1.55 154 Sat 13:30 FC St. -

Uefa Champions League
UEFA CHAMPIONS LEAGUE - 2016/17 SEASON MATCH PRESS KITS BayArena - Leverkusen Wednesday 14 September 2016 20.45CET (20.45 local time) Bayer 04 Leverkusen Group E - Matchday 1 PFC CSKA Moskva Last updated 28/08/2017 18:32CET UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Previous meetings 2 Match background 4 Squad list 6 Head coach 8 Match officials 9 Fixtures and results 10 Match-by-match lineups 13 Competition facts 14 Team facts 15 Legend 17 1 Bayer 04 Leverkusen - PFC CSKA Moskva Wednesday 14 September 2016 - 20.45CET (20.45 local time) Match press kit BayArena, Leverkusen Previous meetings Head to Head No UEFA competition matches have been played between these two teams Bayer 04 Leverkusen - Record versus clubs from opponents' country UEFA Champions League Date Stage Match Result Venue Goalscorers Rondón 89; Son 04/11/2014 GS FC Zenit - Bayer 04 Leverkusen 1-2 St Petersburg Heung-Min 68, 73 Donati 58, 22/10/2014 GS Bayer 04 Leverkusen - FC Zenit 2-0 Leverkusen Papadopoulos 63 UEFA Cup Date Stage Match Result Venue Goalscorers 0-1 10/04/2008 QF FC Zenit - Bayer 04 Leverkusen St Petersburg Bulykin 18 agg: 4-2 Kiessling 33; Arshavin 20, Pogrebnyak 52, 03/04/2008 QF Bayer 04 Leverkusen - FC Zenit 1-4 Leverkusen Anyukov 61, Denisov 64 Pavlyuchenko 63 (P), FC Spartak Moskva - Bayer 04 08/11/2007 GS 2-1 Moscow Mozart 77 (P); Freier Leverkusen 90+1 UEFA Champions League Date Stage Match Result Venue Goalscorers Bayer 04 Leverkusen - FC 25/10/2000 GS1 1-0 Leverkusen Ballack 52 Spartak Moskva FC Spartak Moskva - Bayer 04 12/09/2000 GS1 2-0 Moscow -

ICCA Report 8.Indb
INTERNATIONAL COUNCIL FOR COMMERCIAL ARBITRATION REPORT OF THE CROSS-INSTITUTIONAL TASK FORCE ON GENDER DIVERSITY IN ARBITRAL APPOINTMENTS AND PROCEEDINGS THE ICCA REPORTS NO. 8 2020 ICCA is pleased to present the ICCA Reports series in the hope that these occasional papers, prepared by ICCA interest groups and project groups, will stimulate discussion and debate. INTERNATIONAL COUNCIL FOR COMMERCIAL ARBITRATION REPORT OF THE ASIL-ICCAINTERNATIONAL COUNCIL JOINT FOR TASK FORCE ON COMMERCIAL ARBITRATION ISSUE CONFLICTS IN INVESTOR-STATE ARBITRATION REPORT OF THE CROSS-INSTITUTIONAL TASKTHE FORCE ICCA ON REPORTS GENDER DIVERSITY NO. 3 IN ARBITRAL APPOINTMENTS AND PROCEEDINGS THE17 ICCA March REPORTS 2016 NO. 8 2020 with the assistance of the Permanentwith the Courtassistance of Arbitration of the PermanentPeace Palace, Court Theof Arbitration Hague Peace Palace, The Hague www.arbitration-icca.org www.arbitration-icca.org Published by the International Council for Commercial Arbitration <www.arbitration-icca.org>, on behalf of the Cross-Institutional Task Force on Gender Diversity in Arbitral Appointments and Proceedings ISBN 978-94-92405-20-3 All rights reserved. © 2020 International Council for Commercial Arbitration © International Council for Commercial Arbitration (ICCA). All rights reserved. ICCA and the Cross-Institutional Task Force on Gender Diversity in Arbitral Appointments and Proceedings wish to encourage the use of this Report for the promotion of diversity in arbitration. Accordingly, it is permitted to reproduce or copy this Report, provided that the Report is reproduced accurately, without alteration and in a non-misleading con- text, and provided that the authorship of the Cross-Institutional Task Force on Gender Diversity in Arbitral Appointments and Proceedings and ICCA’s copyright are clearly acknowledged. -

Weekend Regular Coupon 31/05/2019 10:47 1 / 11
Issued Date Page WEEKEND REGULAR COUPON 31/05/2019 10:47 1 / 11 BOTH TEAMS INFORMATION 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 1ST HALF - 3-WAY HT/FT TO SCORE HANDICAP (1X2) GAME CODE HOME TEAM 1 / 2 AWAY TEAM 1/ 12 /2 2.5- 2.5+ 01 0/ 02 1-1 /-1 2-1 1-/ /-/ 2-/ 2-2 /-2 1-2 ++ -- No CAT TIME DET NS L 1 X 2 1X 12 X2 U O 1 X 2 1/1 X/1 2/1 1/X X/X 2/X 2/2 X/2 1/2 YES NO HC 1 X 2 Sunday, 02 June, 2019 7001 USL 06:00 SACRAMENTO REPUBLIC.. 14 - - - 16 SAN ANTONIO FC - - - - - - - - - - - - - - - - - - - - - - - 7003 JAP3 07:00 AZUL CLARO NUMAZU 9 - - - 17 YOKOHAMA SCC - - - - - - - - - - - - - - - - - - - - - - - 7004 JAP3 07:00 BLAUBLITZ AKITA 13 - - - 16 FUKUSHIMA UNITED FC - - - - - - - - - - - - - - - - - - - - - - - 7002 AUNQW 07:00 L SUNSHINE COAST FC - - - CAPALABA FC - - - - - - - - - - - - - - - - - - - - - - - 7005 JAP2 07:05 3 L AVISPA FUKUOKA 19 3.40 2.95 2.15 3 OMIYA ARDIJA 1.58 1.32 1.24 1.50 2.45 4.20 1.90 2.90 6.90 7.00 35.0 15.0 4.40 14.0 3.80 4.80 27.0 2.05 1.70 1:0 1.60 3.60 4.20 7006 AST 07:30 HAMILTON OLYMPIC FC 7 - - - 2 WESTON WORKERS FC - - - - - - - - - - - - - - - - - - - - - - - 7007 AST 07:30 LAKE MACQUARIE CITY FC 11 - - - 5 LAMBTON JAFFAS FC - - - - - - - - - - - - - - - - - - - - - - - 7008 AST 07:30 NEWCASTLE JETS YOUTH 4 - - - 8 CHARLESTOWN CITY - - - - - - - - - - - - - - - - - - - - - - - 7009 AST 07:30 VALENTINE FC 9 - - - 10 ADAMSTOWN ROSEBUD . -

Uefa Champions League
UEFA CHAMPIONS LEAGUE - 2017/18 SEASON MATCH PRESS KITS Estadio Ramón Sánchez Pizjuán - Seville Wednesday 1 November 2017 Sevilla FC 20.45CET (20.45 local time) FC Spartak Moskva Group E - Matchday 4 Last updated 30/10/2017 23:25CET UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Fixtures and results 2 Legend 6 1 Sevilla FC - FC Spartak Moskva Wednesday 1 November 2017 - 20.45CET (20.45 local time) Match press kit Estadio Ramón Sánchez Pizjuán, Seville Fixtures and results Sevilla FC Date Competition Opponent Result Goalscorers 16/08/2017 UCL İstanbul Başakşehir (A) W 2-1 Escudero 16, Ben Yedder 84 19/08/2017 League RCD Espanyol (H) D 1-1 Lenglet 26 22/08/2017 UCL İstanbul Başakşehir (H) D 2-2 Escudero 52, Ben Yedder 75 27/08/2017 League Getafe CF (A) W 1-0 Ganso 83 09/09/2017 League SD Eibar (H) W 3-0 Ganso 46, Ben Yedder 76, Nolito 90+2 13/09/2017 UCL Liverpool FC (A) D 2-2 Ben Yedder 5, Correa 72 17/09/2017 League Girona FC (A) W 1-0 Muriel 69 20/09/2017 League UD Las Palmas (H) W 1-0 Jesús Navas 83 23/09/2017 League Club Atlético de Madrid (A) L 0-2 26/09/2017 UCL NK Maribor (H) W 3-0 Ben Yedder 27, 38, 83 (P) 30/09/2017 League Málaga CF (H) W 2-0 Banega 68 (P), Muriel 70 14/10/2017 League Athletic Club (A) L 0-1 17/10/2017 UCL FC Spartak Moskva (A) L 1-5 Kjær 30 21/10/2017 League Valencia CF (A) L 0-4 24/10/2017 Cup Cartagena FS (A) W 3-0 Sarabia 25, Correa 35, Muriel 51 28/10/2017 League CD Leganés (H) W 2-1 Ben Yedder 20, Sarabia 54 01/11/2017 UCL FC Spartak Moskva (H) 04/11/2017 League FC Barcelona (A) 19/11/2017 League RC Celta de Vigo -

2009/10 UEFA Champions League Statistics Handbook, Part 2
Debreceni VSC UEFA CHAMPIONS LEAGUE | SEASON 2009/10 | GROUP E Founded: 12.03.1902 Telephone: +36 52 535 408 Address: Oláh Gabor U 5 Telefax: +36 52 340 817 HU-4032 Debrecen E-mail: [email protected] Hungary Website: www.dvsc.hu CLUB HONOURS National Championship (4) 2005, 2006, 2007, 2009 National Cup (3) 1999, 2001, 2008 National Super Cup (4) 2005, 2006, 2007, 2009 Debreceni VSC UEFA CHAMPIONS LEAGUE | SEASON 2009/10 | GROUP E GENERAL INFORMATION Managing Director: Sándor Szilágyi Supporters: 2,700 Secretary: Judit Balla Other sports: None Press Officers: Gabór Ganczer Zoltán Csubák Captain: Zoltán Kiss PRESIDENT CLUB RECORDS Gábor Szima Most Appearances: Sándor Csaba - 399 league matches (1984-2000) Date of Birth: 02.10.1959 Most Goals: Sandór Tamás - Date of Election: 92 goals in 301 matches (1991-97 & 08.01.2002 2002-08) STADIUM – FERENC PUSKÁS (Budapest) Ground Capacity: 36,160 Floodlight: 1,400 lux Record Attendance: 104,000 (v Austria on 16.10.1955) Size of Pitch: 105m x 68m HEAD COACH – András HERCZEG Date of Birth: 11.07.1956 in Gyöngyös Nationality: Hungarian Player: DSI (1970-74) Debreceni VSC (1974-79) Honvéd Szabó Lajos SE (1979-81) Hajdúböszörmény (1981) Hajdúszoboszló (1981-84) Karcag (1984-86) Hajdúszoboszló (1986-88) Coach: DSI (1988-95) Debreceni VSC (Assistant Coach 1994-97 / Head Coach 1997-98) Hungarian Olympic Team (1998-99) Tiszaújváros (2000-01) Debreceni VSC (Assistant Coach 2004-2007 / Head Coach since January 2008) Hungarian Championship Winner 2005, 2006, 2007, 2009 Hungarian Cup Winner 2008 Hungarian Super Cup -

PFC CSKA Moskva - FC Shakhtar Donetsk MATCH PRESS KIT Luzhniki, Moscow Thursday 12 March 2009 - 18.00CET (20.00 Local Time) Matchday 8 - Round of 16, First Leg
PFC CSKA Moskva - FC Shakhtar Donetsk MATCH PRESS KIT Luzhniki, Moscow Thursday 12 March 2009 - 18.00CET (20.00 local time) Matchday 8 - Round of 16, first leg Contents 1 - Match background 6 - Competition facts 2 - Squad list 7 - Team facts 3 - Match officials 8 - Competition information 4 - Domestic information 9 - Legend 5 - Match-by-match lineups This press kit includes information relating to this UEFA Cup match. For more detailed factual information, and in-depth competition statistics, please refer to the matchweek press kit, which can be downloaded at: http://www.uefa.com/uefa/mediaservices/presskits/index.html Match background PFC CSKA Moskva and FC Shakhtar Donetsk will meet for the their first competitive fixture since the collapse of the former Soviet Union in the UEFA Cup Round of 16 in the season's second Russia-against-Ukraine blockbuster. • The two teams have never met in European club competition, and CSKA have never played a Ukrainian club in a UEFA tournament before. • Shakhtar have played three games against Russian sides in Europe, losing 4-1 to SC Rotor Volgograd in the 1996 UEFA Intertoto Cup, and then bowing out to FC Lokomotiv Moskva in the 2003/04 UEFA Champions League third qualifying round, winning 1-0 at home but going down 3-1 in their last competitive game in Moscow. • CSKA are traditionally the club of the Russian army. Founded in 1911, their initials stand for Central Sports Army Club. Their honours include seven Soviet titles, five USSR Cups, three Russian titles, four Russian Cups and the 2004/05 UEFA Cup. -

Brasilien WM-Favorit!
Jeden Dienstag neu | € 1,90 Nr. 24 | 12. Juni 2018 FOTOS: GEPA PICTURES 50 Wien 16 SEITEN EXTRA Europas Meister von A bis Z 21 ab Seite NEYMAR NERVT: ABER NACH 3:0-SIEG GEGEN ÖSTERREICH RÖCHER WEG, ALAR AUCH? Sturms Aderlass geht weiter! Seite 38 Brasilien WM-TOTOTOTO Dreimal 100.000 WM-Favorit! Euro für den 13er! ab Seite 6 Österreichische Post AG WZ 02Z030837 W – Sportzeitung Verlags-GmbH, Linke Wienzeile 40/2/22, 1060 Wien Retouren an PF 100, 13 Der Sky Chatbot zur Weltmeisterschaft Fredls Wöd Tipp Jetzt gleich tippen und gewinnen www.facebook.com/fredlchatbot PR_AZ_Coverbalken_Sportzeitung_169x31_2018_V01.indd 1 06.06.18 15:46 Exklusiv und gratis nur für Montag: Abonnenten! EPAPER Dienstag: AB SOFORT ZEITUNG IST HEUTE MORGEN! Gratis: DIE SPORTZEITUNG NEU: ePaper Exklusiv und gratis nur für Abonnenten! SCHON MONTAGS ALS Jetzt Vorteilsabo bestellen! Holen Sie sich das 1-Jahres-Abo Print und ePaper zum Preis von € 74,90 (EU-Ausland € 129,90) EPAPER ONLINE LESEN. und Sie können kostenlos 52 x TOTO tippen. AM DIENSTAG IM [email protected] | +43 2732 82000 1 Jahr SPORTZEITUNG Print und ePaper zum Preis von € 74,90. Das Abonnement kann bis zu sechs Wochen vor Ablauf der Bezugsfrist schriftlich gekündigt werden, ansonsten verlängert sich das Abo um ein weiteres Jahr zum jeweiligen Tarif. Preise inklusive Umsatzsteuer und Versand. POSTKASTEN. Zusendung des Zusatzartikels etwa zwei Wochen nach Zahlungseingang bzw. ab Verfügbarkeit. Solange der Vorrat reicht. © Shutterstock Shutterstock epaper.sportzeitung.at Exklusiv und gratis nur für Montag: