A Thesis Entitled Homology-Based Structural Prediction of the Binding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NIH Public Access Author Manuscript Proteins
NIH Public Access Author Manuscript Proteins. Author manuscript; available in PMC 2015 February 01. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Proteins. 2014 February ; 82(0 2): 208–218. doi:10.1002/prot.24374. One contact for every twelve residues allows robust and accurate topology-level protein structure modeling David E. Kim, Frank DiMaio, Ray Yu-Ruei Wang, Yifan Song, and David Baker* Department of Biochemistry, University of Washington, Seattle 98195, Washington Abstract A number of methods have been described for identifying pairs of contacting residues in protein three-dimensional structures, but it is unclear how many contacts are required for accurate structure modeling. The CASP10 assisted contact experiment provided a blind test of contact guided protein structure modeling. We describe the models generated for these contact guided prediction challenges using the Rosetta structure modeling methodology. For nearly all cases, the submitted models had the correct overall topology, and in some cases, they had near atomic-level accuracy; for example the model of the 384 residue homo-oligomeric tetramer (Tc680o) had only 2.9 Å root-mean-square deviation (RMSD) from the crystal structure. Our results suggest that experimental and bioinformatic methods for obtaining contact information may need to generate only one correct contact for every 12 residues in the protein to allow accurate topology level modeling. Keywords protein structure prediction; rosetta; comparative modeling; homology modeling; ab initio prediction; contact prediction INTRODUCTION Predicting the three-dimensional structure of a protein given just the amino acid sequence with atomic-level accuracy has been limited to small (<100 residues), single domain proteins. -

Homology Modeling and Analysis of Structure Predictions of the Bovine Rhinitis B Virus RNA Dependent RNA Polymerase (Rdrp)
Int. J. Mol. Sci. 2012, 13, 8998-9013; doi:10.3390/ijms13078998 OPEN ACCESS International Journal of Molecular Sciences ISSN 1422-0067 www.mdpi.com/journal/ijms Article Homology Modeling and Analysis of Structure Predictions of the Bovine Rhinitis B Virus RNA Dependent RNA Polymerase (RdRp) Devendra K. Rai and Elizabeth Rieder * Foreign Animal Disease Research Unit, United States Department of Agriculture, Agricultural Research Service, Plum Island Animal Disease Center, Greenport, NY 11944, USA; E-Mail: [email protected] * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel.: +1-631-323-3177; Fax: +1-631-323-3006. Received: 3 May 2012; in revised form: 3 July 2012 / Accepted: 11 July 2012 / Published: 19 July 2012 Abstract: Bovine Rhinitis B Virus (BRBV) is a picornavirus responsible for mild respiratory infection of cattle. It is probably the least characterized among the aphthoviruses. BRBV is the closest relative known to Foot and Mouth Disease virus (FMDV) with a ~43% identical polyprotein sequence and as much as 67% identical sequence for the RNA dependent RNA polymerase (RdRp), which is also known as 3D polymerase (3Dpol). In the present study we carried out phylogenetic analysis, structure based sequence alignment and prediction of three-dimensional structure of BRBV 3Dpol using a combination of different computational tools. Model structures of BRBV 3Dpol were verified for their stereochemical quality and accuracy. The BRBV 3Dpol structure predicted by SWISS-MODEL exhibited highest scores in terms of stereochemical quality and accuracy, which were in the range of 2Å resolution crystal structures. The active site, nucleic acid binding site and overall structure were observed to be in agreement with the crystal structure of unliganded as well as template/primer (T/P), nucleotide tri-phosphate (NTP) and pyrophosphate (PPi) bound FMDV 3Dpol (PDB, 1U09 and 2E9Z). -

Isoform-Specific Monobody Inhibitors of Small Ubiquitin-Related Modifiers Engineered Using Structure-Guided Library Design
Isoform-specific monobody inhibitors of small ubiquitin-related modifiers engineered using structure-guided library design Ryan N. Gilbretha, Khue Truongb, Ikenna Madub, Akiko Koidea, John B. Wojcika, Nan-Sheng Lia, Joseph A. Piccirillia,c, Yuan Chenb, and Shohei Koidea,1 aDepartment of Biochemistry and Molecular Biology, and cDepartment of Chemistry, University of Chicago, 929 East 57th Street, Chicago, IL 60637; and bDepartment of Molecular Medicine, Beckman Research Institute of the City of Hope, 1450 East Duarte Road, Duarte, CA 91010 Edited by David Baker, University of Washington, Seattle, WA, and approved March 16, 2011 (received for review February 10, 2011) Discriminating closely related molecules remains a major challenge which SUMOylation alters protein function appears to be in the engineering of binding proteins and inhibitors. Here we through SUMO-mediated interactions with other proteins con- report the development of highly selective inhibitors of small ubi- taining a short peptide motif known as a SUMO-interacting motif quitin-related modifier (SUMO) family proteins. SUMOylation is (SIM) (4, 7, 8). involved in the regulation of diverse cellular processes. Functional There are few inhibitors of SUMO/SIM interactions, a defi- differences between two major SUMO isoforms in humans, SUMO1 ciency that limits our ability to finely dissect SUMO biology. In and SUMO2∕3, are thought to arise from distinct interactions the only reported example of such an inhibitor, a SIM-containing mediated by each isoform with other proteins containing SUMO- linear peptide was used to inhibit SUMO/SIM interactions, estab- interacting motifs (SIMs). However, the roles of such isoform- lishing their importance in coordinating DNA repair by nonho- specific interactions are largely uncharacterized due in part to the mologous end joining (9). -

Lecture 5: Sequence Alignment – Global Alignment
Sequence Alignment COSC 348: Computing for Bioinformatics • Sequence alignment is a way of arranging two or more sequences of characters to identify regions of similarity – b/c similarities may be a consequence of functional or Lecture 5: evolutionary relationships between these sequences. Sequence Alignment – Global Alignment • Another definition: Procedure for comparing two or more sequences by searching for a series of individual characters that Lubica Benuskova, Ph.D. are in the same order in those sequences – Pair-wise alignment: compare two sequences – Multiple sequence alignment: compare > 2 sequences http://www.cs.otago.ac.nz/cosc348/ 1 2 Similarity versus identity Sequence alignment: example • In the process of evolution, from one generation to the next, and from one species to the next, the amino acid sequences of • Task: align abcdef with somehow similar abdgf an organism's proteins are gradually altered through the action of DNA mutations. For example, the sequence: • Write second sequence below the first one – ALEIRYLRD • could mutate into the sequence: ALEINYLRD abcdef abdgf • in one generation and possibly into AQEINYQRD • Move sequences to give maximum match between them. • over a longer period of evolutionary time. – Note: a hydrophobic amino acid is more likely to stay • Show characters that match using vertical bar. hydrophobic than not, since replacing it with a hydrophilic residue could affect the folding and/or activity of the protein. 3 4 Sequence alignment: example Quantitative global alignments abcdef • We are looking for an alignment, which || – maximizes the number of base-to-base matches; abdgf – if necessary to achieve this goal, inserts gaps in either sequence (a gap means a base-to-nothing match); • In order to maximise the alignment, we insert gap between – the order of bases in each sequence must remain and in lower sequence to allow and to align b d d f preserved and abcdef – gap-to-gap matches are not allowed. -

Roles of Ubiquitination and Sumoylation in the Regulation of Angiogenesis
Curr. Issues Mol. Biol. (2020) 35: 109-126. Roles of Ubiquitination and SUMOylation in the Regulation of Angiogenesis Andrea Rabellino1*, Cristina Andreani2 and Pier Paolo Scaglioni2 1QIMR Berghofer Medical Research Institute, Brisbane City, Queensland, Australia. 2Department of Internal Medicine, Hematology and Oncology; University of Cincinnati, Cincinnati, OH, USA. *Correspondence: [email protected] htps://doi.org/10.21775/cimb.035.109 Abstract is tumorigenesis-induced angiogenesis, during Te generation of new blood vessels from the which hypoxic and starved cancer cells activate existing vasculature is a dynamic and complex the molecular pathways involved in the formation mechanism known as angiogenesis. Angiogenesis of novel blood vessels, in order to supply nutri- occurs during the entire lifespan of vertebrates and ents and oxygen required for the tumour growth. participates in many physiological processes. Fur- Additionally, more than 70 diferent disorders have thermore, angiogenesis is also actively involved been associated to de novo angiogenesis including in many human diseases and disorders, including obesity, bacterial infections and AIDS (Carmeliet, cancer, obesity and infections. Several inter-con- 2003). nected molecular pathways regulate angiogenesis, At the molecular level, angiogenesis relays on and post-translational modifcations, such as phos- several pathways that cooperate in order to regulate phorylation, ubiquitination and SUMOylation, in a precise spatial and temporal order the process. tightly regulate these mechanisms and play a key In this context, post-translational modifcations role in the control of the process. Here, we describe (PTMs) play a central role in the regulation of these in detail the roles of ubiquitination and SUMOyla- events, infuencing the activation and stability of tion in the regulation of angiogenesis. -

BC-Box Protein Domain-Related Mechanism for VHL Protein Degradation
BC-box protein domain-related mechanism for VHL protein degradation Maria Elena Pozzebona,1,2, Archana Varadaraja,1, Domenico Mattoscioa, Ellis G. Jaffrayb, Claudia Miccoloa, Viviana Galimbertic, Massimo Tommasinod, Ronald T. Hayb, and Susanna Chioccaa,3 aDepartment of Experimental Oncology, European Institute of Oncology, 20139 Milan, Italy; cSenology Division, European Institute of Oncology, 20141 Milan, Italy; dInternational Agency for Research on Cancer, World Health Organization, 69372 Lyon, France; and bCentre for Gene Regulation and Expression, University of Dundee, Dundee DD1 5EH, United Kingdom Edited by William G. Kaelin, Jr., Harvard Medical School, Boston, MA, and approved September 23, 2013 (received for review June 18, 2013) The tumor suppressor VHL (von Hippel–Lindau) protein is a sub- effects of the wild-type Gam1 protein (18, 20, 21), supporting the strate receptor for Ubiquitin Cullin Ring Ligase complexes (CRLs), idea that these effects may depend on Gam1 ability to act as containing a BC-box domain that associates to the adaptor Elongin substrate-receptor protein. B/C. VHL targets hypoxia-inducible factor 1α to proteasome- VHL (von Hippel–Lindau) protein is a cellular BC box-con- dependent degradation. Gam1 is an adenoviral protein, which also taining substrate receptor and associates with Cullin2-based E3 possesses a BC-box domain that interacts with the host Elongin B/C, ligases (22–24). VHL is a tumor suppressor, and its loss leads to – thereby acting as a viral substrate receptor. Gam1 associates with the von Hippel Lindau syndrome that often develops into renal both Cullin2 and Cullin5 to form CRL complexes targeting the host clear-cell carcinoma and other highly vascularized tumors (25, 26). -
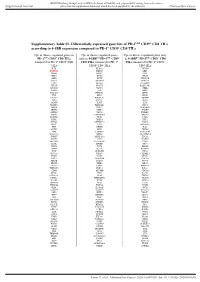
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Serum Albumin OS=Homo Sapiens
Protein Name Cluster of Glial fibrillary acidic protein OS=Homo sapiens GN=GFAP PE=1 SV=1 (P14136) Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 Cluster of Isoform 3 of Plectin OS=Homo sapiens GN=PLEC (Q15149-3) Cluster of Hemoglobin subunit beta OS=Homo sapiens GN=HBB PE=1 SV=2 (P68871) Vimentin OS=Homo sapiens GN=VIM PE=1 SV=4 Cluster of Tubulin beta-3 chain OS=Homo sapiens GN=TUBB3 PE=1 SV=2 (Q13509) Cluster of Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 (P60709) Cluster of Tubulin alpha-1B chain OS=Homo sapiens GN=TUBA1B PE=1 SV=1 (P68363) Cluster of Isoform 2 of Spectrin alpha chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTAN1 (Q13813-2) Hemoglobin subunit alpha OS=Homo sapiens GN=HBA1 PE=1 SV=2 Cluster of Spectrin beta chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTBN1 PE=1 SV=2 (Q01082) Cluster of Pyruvate kinase isozymes M1/M2 OS=Homo sapiens GN=PKM PE=1 SV=4 (P14618) Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 Clathrin heavy chain 1 OS=Homo sapiens GN=CLTC PE=1 SV=5 Filamin-A OS=Homo sapiens GN=FLNA PE=1 SV=4 Cytoplasmic dynein 1 heavy chain 1 OS=Homo sapiens GN=DYNC1H1 PE=1 SV=5 Cluster of ATPase, Na+/K+ transporting, alpha 2 (+) polypeptide OS=Homo sapiens GN=ATP1A2 PE=3 SV=1 (B1AKY9) Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 Dihydropyrimidinase-related protein 2 OS=Homo sapiens GN=DPYSL2 PE=1 SV=1 Cluster of Alpha-actinin-1 OS=Homo sapiens GN=ACTN1 PE=1 SV=2 (P12814) 60 kDa heat shock protein, mitochondrial OS=Homo -

Comparative Protein Structure Modeling of Genes and Genomes
P1: FPX/FOZ/fop/fok P2: FHN/FDR/fgi QC: FhN/fgm T1: FhN January 12, 2001 16:34 Annual Reviews AR098-11 Annu. Rev. Biophys. Biomol. Struct. 2000. 29:291–325 Copyright c 2000 by Annual Reviews. All rights reserved COMPARATIVE PROTEIN STRUCTURE MODELING OF GENES AND GENOMES Marc A. Mart´ı-Renom, Ashley C. Stuart, Andras´ Fiser, Roberto Sanchez,´ Francisco Melo, and Andrej Sˇali Laboratories of Molecular Biophysics, Pels Family Center for Biochemistry and Structural Biology, Rockefeller University, 1230 York Ave, New York, NY 10021; e-mail: [email protected] Key Words protein structure prediction, fold assignment, alignment, homology modeling, model evaluation, fully automated modeling, structural genomics ■ Abstract Comparative modeling predicts the three-dimensional structure of a given protein sequence (target) based primarily on its alignment to one or more pro- teins of known structure (templates). The prediction process consists of fold assign- ment, target–template alignment, model building, and model evaluation. The number of protein sequences that can be modeled and the accuracy of the predictions are in- creasing steadily because of the growth in the number of known protein structures and because of the improvements in the modeling software. Further advances are nec- essary in recognizing weak sequence–structure similarities, aligning sequences with structures, modeling of rigid body shifts, distortions, loops and side chains, as well as detecting errors in a model. Despite these problems, it is currently possible to model with useful accuracy significant parts of approximately one third of all known protein sequences. The use of individual comparative models in biology is already rewarding and increasingly widespread. -

Novel Bioinformatics Applications for Protein Allergology
AND ! "#$% &'()* +% + ,-.,-/,0 + 121,..0-10- ! 3 4 33!!3 ,,,1/ !"# $% # $# &'()$ $*+,'-./ $ "Por la ciencia, como por el arte, se va al mismo sitio: a la verdad" Gregorio Marañón Madrid, 19-05-1887 - Madrid, 27-03-1960 List of Papers This thesis is based on the following papers, which are referred to in the text by their Roman numerals. I Martínez Barrio, Á., Soeria-Atmadja, D., Nister, A., Gustafsson, M.G., Hammerling, U., Bongcam-Rudloff, E. (2007) EVALLER: a web server for in silico assessment of potential protein allergenicity. Nucleic Acids Research, 35(Web Server issue):W694-700. II Martínez Barrio, Á.∗, Lagercrantz, E.∗, Sperber, G.O., Blomberg, J., Bongcam-Rudloff, E. (2009) Annotation and visualization of endogenous retroviral sequences using the Distributed Annotation System (DAS) and eBioX. BMC Bioinformatics, 10(Suppl 6):S18. III Martínez Barrio, Á., Xu, F., Lagercrantz, E., Bongcam-Rudloff, E. (2009) GeneFinder: In silico positional cloning of trait genes. Manuscript. IV Martínez Barrio, Á., Ekerljung, M., Jern, P., Benachenhou, F., Sperber, -

SUMO and Ubiquitin in the Nucleus: Different Functions, Similar Mechanisms?
Downloaded from genesdev.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW SUMO and ubiquitin in the nucleus: different functions, similar mechanisms? Grace Gill1 Department of Pathology, Harvard Medical School, Boston, Massachusetts 02115, USA The small ubiquitin-related modifier SUMO posttrans- tin, SUMO modification regulates protein localization lationally modifies many proteins with roles in diverse and activity. processes including regulation of transcription, chroma- This review focuses on recent advances in our under- tin structure, and DNA repair. Similar to nonproteolytic standing of SUMO function and regulation, drawing on a roles of ubiquitin, SUMO modification regulates protein limited set of examples relating to gene expression, chro- localization and activity. Some proteins can be modified matin structure, and DNA repair. Comparison of SUMO by SUMO and ubiquitin, but with distinct functional and ubiquitin activities in the nucleus reveals interest- consequences. It is possible that the effects of ubiquiti- ing differences in function and suggests surprising simi- nation and SUMOylation are both largely due to binding larities in mechanism. Thus, for example, modification of proteins bearing specific interaction domains. Both of transcription factors and histones by ubiquitin is gen- modifications are reversible, and in some cases dynamic erally associated with increased gene expression whereas cycles of modification may be required for activity. Stud- modification of transcription factors and histones by ies of SUMO and ubiquitin in the nucleus are yielding SUMO is generally associated with decreased gene ex- new insights into regulation of gene expression, genome pression. In some cases, SUMO and ubiquitin may di- maintenance, and signal transduction. -

FORCE FIELDS for PROTEIN SIMULATIONS by JAY W. PONDER
FORCE FIELDS FOR PROTEIN SIMULATIONS By JAY W. PONDER* AND DAVIDA. CASEt *Department of Biochemistry and Molecular Biophysics, Washington University School of Medicine, 51. Louis, Missouri 63110, and tDepartment of Molecular Biology, The Scripps Research Institute, La Jolla, California 92037 I. Introduction. ...... .... ... .. ... .... .. .. ........ .. .... .... ........ ........ ..... .... 27 II. Protein Force Fields, 1980 to the Present.............................................. 30 A. The Am.ber Force Fields.............................................................. 30 B. The CHARMM Force Fields ..., ......... 35 C. The OPLS Force Fields............................................................... 38 D. Other Protein Force Fields ....... 39 E. Comparisons Am.ong Protein Force Fields ,... 41 III. Beyond Fixed Atomic Point-Charge Electrostatics.................................... 45 A. Limitations of Fixed Atomic Point-Charges ........ 46 B. Flexible Models for Static Charge Distributions.................................. 48 C. Including Environmental Effects via Polarization................................ 50 D. Consistent Treatment of Electrostatics............................................. 52 E. Current Status of Polarizable Force Fields........................................ 57 IV. Modeling the Solvent Environment .... 62 A. Explicit Water Models ....... 62 B. Continuum Solvent Models.......................................................... 64 C. Molecular Dynamics Simulations with the Generalized Born Model........