Master Thesis Characterizing Sender Policy Framework Configurations At
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Electronic Mail Standard
IT Shared Services Standard: Electronic Mail Standard For South Carolina State Agencies Version 1.0 Effective: August 8, 2018 Revision History: Date Authored by Title Ver. Notes Recommended by the Security and Architecture 08.08.2018 Standards 1.0 Executive Oversight Group. Review Board Standard finalized. Electronic Mail Standard | 2 Contents Revision History: ................................................................................................................................... 1 Electronic Mail ...................................................................................................................................... 4 Rationale ........................................................................................................................................... 4 Agency Exception Requests ............................................................................................................... 4 Current State..................................................................................................................................... 4 Purchasing......................................................................................................................................... 4 Maintenance ..................................................................................................................................... 5 Service Level Agreements ............................................................................................................. 5 Security ............................................................................................................................................ -

Comodo Antispam Gateway Software Version 1.5
Comodo Antispam Gateway Software Version 1.5 Administrator Guide Guide Version 1.5.082412 Comodo Security Solutions 525 Washington Blvd. Jersey City, NJ 07310 Comodo Antispam Gateway - Administrator Guide Table of Contents 1 Introduction to Comodo Antispam Gateway........................................................................................................................... 4 1.1 Release Notes............................................................................................................................................................. 5 1.2 Purchasing License .................................................................................................................................................... 6 1.3 Adding more Users, Domains or Time to your Account .................................................................................................6 1.4 License Information................................................................................................................................................... 10 2 Getting Started................................................................................................................................................................... 13 2.1 Incoming Filtering Configuration ................................................................................................................................ 13 2.1.1 Configuring Your Mail Server.................................................................................................................................. -
DNS Manager User Guide VF
Vodafone Hosted Services: DNS Manager User Guide DNS Manager User Guide 1 Vodafone Hosted Services: DNS Manager User Guide DNS Manager What is DNS Manager ? DNS Manager allows the end-user to edit their domain’s zone file, including A (address) records, CNAME (canonical name) records and MX (mail exchange) records. What is the Default Zone File ? If the end-user selects “Edit Zone File” and clicks “Next”, their current zone file will be displayed at the top of the screen. By default, their zone file will contain several important records. Any changes to these records may cause serious problems with their website and email performance. What is DNS ? DNS (Domain Name System or Domain Name Service) catalogs and updates information in regards to domain names. DNS converts domain names into IP addresses. DNS usually contains a set of zone files that lists the types of redirection that will be done. 2 Vodafone Hosted Services: DNS Manager User Guide What are Zone Files ? Four types of records are important in a zone file: • A records • CNAME records • MX records • Start of Authority (SOA) domain.com points to 216.251.43.17 mail.domain.com points to 69.49.123.241 mail will be delivered to 10 mx1c1.megamailservers.com first mail will be delivered to 100 mx2c1.megamailservers.com second mail will be delivered to 110 Resource Record Abbreviations The end-users domain name is called their “origin”. The origin is appended to all names in the zone file that do not end in a dot. For example, if their domain is yourname.com, the entry “www” in the zone file is equal to www.yourname.com. -

What Is DMARC, SPF, and DKIM? • How to Configure • Common Mistakes • Best Practices • How Phishes Get By
How to Prevent 81% of Phishing Attacks From Sailing Right Through DMARC, SPF, and DKIM Roger A. Grimes Data-Driven Defense Evangelist [email protected] About Roger • 30 years plus in computer security • Expertise in host and network security, IdM, crypto, PKI, APT, honeypot, cloud security • Consultant to world’s largest companies and militaries for decades • Previous worked for Foundstone, McAfee, Microsoft • Written 11 books and over 1,000 magazine articles • InfoWorld and CSO weekly security columnist since 2005 • Frequently interviewed by magazines (e.g. Newsweek) and radio shows (e.g. NPR’s All Things Considered) Roger A. Grimes Certification exams passed include: Data-Driven Defense Evangelist KnowBe4, Inc. • CPA • CISSP Twitter: @RogerAGrimes • CISM, CISA LinkedIn: https://www.linkedin.com/in/rogeragrimes/ • MCSE: Security, MCP, MVP • CEH, TISCA, Security+, CHFI • yada, yada Roger’s Books 3 KnowBe4, Inc. • The world’s most popular integrated Security Awareness Training and Simulated Phishing platform • Based in Tampa Bay, Florida, founded in 2010 • CEO & employees are ex-antivirus, IT Security pros • 200% growth year over year • We help tens of thousands of organizations manage the problem of social engineering 4 Today’s Presentation • What is DMARC, SPF, and DKIM? • How to Configure • Common Mistakes • Best Practices • How Phishes Get By 5 • What is DMARC, SPF, and DKIM? § How to Configure Agenda • Best Practices • How Phishes Get By 6 DMARC, DKIM, SPF Global Phishing Protection Standards • Sender Policy Framework (SPF) • Domain -

A Security Analysis of Email Communications
A security analysis of email communications Ignacio Sanchez Apostolos Malatras Iwen Coisel Reviewed by: Jean Pierre Nordvik 2 0 1 5 EUR 28509 EN European Commission Joint Research Centre Institute for the Protection and Security of the Citizen Contact information Ignacio Sanchez Address: Joint Research Centre, Via Enrico Fermi 2749, I - 21027 Ispra (VA), Italia E-mail: [email protected] JRC Science Hub https://ec.europa.eu/jrc Legal Notice This publication is a Technical Report by the Joint Research Centre, the European Commission’s in-house science service. It aims to provide evidence-based scientific support to the European policy-making process. The scientific output expressed does not imply a policy position of the European Commission. Neither the European Commission nor any person acting on behalf of the Commission is responsible for the use which might be made of this publication. All images © European Union 2015, except: Frontpage : © bluebay2014, fotolia.com JRC 99372 EUR 28509 EN ISSN 1831-9424 ISBN 978-92-79-66503-5 doi:10.2760/319735 Luxembourg: Publications Office of the European Union, 2015 © European Union, 2015 Reproduction is authorised provided the source is acknowledged. Printed in Italy Abstract The objective of this report is to analyse the security and privacy risks of email communications and identify technical countermeasures capable of mitigating them effectively. In order to do so, the report analyses from a technical point of view the core set of communication protocols and standards that support email communications in order to identify and understand the existing security and privacy vulnerabilities. On the basis of this analysis, the report identifies and analyses technical countermeasures, in the form of newer standards, protocols and tools, aimed at ensuring a better protection of the security and privacy of email communications. -

98-367: Security Fundamentals
98-367: Security Fundamentals 1. Understand security layers (25–30%) 1.1. Understand core security principles Confidentiality; integrity; availability; how threat and risk impact principles; principle of least privilege; social engineering; attack surface analysis; threat modelling 1.2. Understand physical security Site security; computer security; removable devices and drives; access control; mobile device security; disable Log On Locally; keyloggers 1.3. Understand Internet security Browser security settings; zones; secure websites 1.4. Understand wireless security Advantages and disadvantages of specific security types; keys; service set identifiers (SSIDs); MAC filters 2. Understand operating system security (30–35%) 2.1. Understand user authentication Multifactor authentication; physical and virtual smart cards; Remote Authentication Dial- In User Service (RADIUS); Public Key Infrastructure (PKI); understand the certificate chain; biometrics; Kerberos and time skew; use Run As to perform administrative tasks; password reset procedures 2.2. Understand permissions File system permissions; share permissions; registry; Active Directory; NT file system (NTFS) versus file allocation table (FAT); enable or disable inheritance; behavior when moving or copying files within the same disk or on another disk; multiple groups with different permissions; basic permissions and advanced permissions; take ownership; delegation; inheritance 2.3. Understand password policies Password complexity; account lockout; password length; password history; time -

BOD-18-01 Original Release Date: Applies To: All Federal Executive Branch Departments and Agencies
Secretary U.S. Department of Homeland Security Washington,DC 20528 Homeland Security Binding Operational Directive BOD-18-01 Original Release Date: Applies to: All Federal Executive Branch Departments and Agencies FROM: Elaine C. Duke Acting Secretary OCT 1 6 20t7 CC: Mick Mulvaney Director, Office of Management and Budget SUBJECT: Enhance Email and Web Security A binding operational directive is a compulsory direction to federal, executive branch, departments and agencies for purposes of safeguardingfederal information and information systems. 44 U.S.C. § 3552(b)(l). The Department ofHomeland Security (DHS) develops and oversees the implementation ofbinding operational directivespursuant to the Federal InformationSecurity Modernization Act of2014 ("FISMA"). Id.§ 3553(b)(2). Federal agencies are required to comply with these DHS-developed directives. Id. § 3554(a)(l)(B)(ii). DHS binding operational directivesdo not apply to statutorily defined"National Security Systems" or to certain systems operated by the Department ofDefense orthe Intelligence Community. Id. § 3553(d)-(e). I. Background Federal agency 'cyber hygiene' greatly impacts user security. By implementing specific security standards that have been widely adopted in industry, federal agencies can ensure the integrity and confidentiality of internet-delivered data, minimize spam, and better protect users who might otherwise fall victim to a phishing email that appears to come from a government-owned system. Based on current network scandata and a clear potential forharm, this directive requires actions related to two topics: email security and web security. A. Email Security STARTTLS When enabled by a receiving mail server, STARTTLS signals to a sending mail server that the capability to encrypt an email in transit is present. -

Composition Kills: a Case Study of Email Sender Authentication
Composition Kills: A Case Study of Email Sender Authentication Jianjun Chen, Vern Paxson, and Jian Jiang Component-based software design has been widely adopted as a way to manage complexity and improve reusability. The approach divides complex systems into smaller modules that can be independently created and reused in different systems. One then combines these components together to achieve desired functionality. Modern software systems are commonly built using components made by different developers who work independently. While having wide-ranging benefits, the security research community has recognized that this practice also introduces security concerns. In particular, when faced with crafted adversarial inputs, different components can have inconsistent interpretations when operating on the input in sequence. Attackers can exploit such inconsistencies to bypass security policies and subvert the system’s operation. In this work we provide a case study of such composition issues in the context of email (SMTP) sender authentication. We present 18 attacks for widely used email services to bypass their sender authentication checks by misusing combinations of SPF, DKIM and DMARC, which are crucial defenses against email phishing and spear-phishing attacks. Leveraging these attack techniques, an attacker can impersonate arbitrary senders without breaking email authentication, and even forge DKIM-signed emails with a legitimate site’s signature. Email spoofing, commonly used in phishing attacks, poses a serious threat to both individuals and organiza- tions. Over the past years, a number of attacks used email spoofing or phishing attacks to breach enterprise networks [5] or government officials’ accounts [10]. To address this problem, modern email services and websites employ authentication protocols—SPF, DKIM, and DMARC—to prevent email forgery. -

Email Services Deployment Administrator Guide Email Services Deployment Administrator Guide
Email Services Deployment Administrator Guide Email Services Deployment Administrator Guide Documentation version: 1.0 Legal Notice Copyright 2016 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, and the Checkmark Logo are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be commercial computer software as defined in FAR 12.212 and subject to restricted rights as defined in FAR Section 52.227-19 "Commercial Computer Software - Restricted Rights" and DFARS 227.7202, et seq. "Commercial Computer Software and Commercial Computer Software Documentation," as applicable, and any successor regulations, whether delivered by Symantec as on premises or hosted services. Any use, modification, reproduction release, performance, display or disclosure of the Licensed Software and Documentation by the U.S. -

System Administrator's Guide
ePrism Email Security System Administrator’s Guide - V11.0 4225 Executive Sq, Ste 1600 Give us a call: Send us an email: For more info, visit us at: La Jolla, CA 92037-1487 1-800-782-3762 [email protected] www.edgewave.com © 2001—2017 EdgeWave. All rights reserved. The EdgeWave logo is a trademark of EdgeWave Inc. All other trademarks and registered trademarks are hereby acknowledged. Microsoft and Windows are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Other product and company names mentioned herein may be the trademarks of their respective owners. The Email Security software and its documentation are copyrighted materials. Law prohibits making unauthorized copies. No part of this software or documentation may be reproduced, transmitted, transcribed, stored in a retrieval system, or translated into another language without prior permission of EdgeWave. 11.0 Contents Chapter 1 Overview 1 Overview of Services 1 Email Filtering (EMF) 2 Archive 3 Continuity 3 Encryption 4 Data Loss Protection (DLP) 4 Personal Health Information 4 Personal Financial Information 5 ThreatCheck 6 Vx Service 6 Document Conventions 7 Supported Browsers 7 Reporting Spam to EdgeWave 7 Contacting Us 8 Additional Resources 8 Chapter 2 ePrism Appliance 9 Planning for the ePrism Appliance 9 About MX Records 9 Configuration Examples 10 Email Security Outside Corporate Firewall 10 Email Security Behind Corporate Firewall 10 Mandatory 11 Optional 12 Accessing the ePrism Appliance 12 ePrism Appliance -
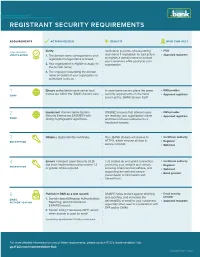
Registrant Security Requirements
REGISTRANT SECURITY REQUIREMENTS REQUIREMENTS ACTION NEEDED BENEFIT WHO CAN HELP PRELIMINARY Verify: Verification prevents cybersquatting fTLD VERIFICATION 1. The domain name corresponds to your and makes it impossible for bad actors Approved registrars organization's legal name or brand; to register a domain name or contact your customers while posing as your 2. Your organization is eligible to apply for organization. the domain name; 3. The employee requesting the domain name on behalf of your organization is authorized to do so. 1 Ensure authoritative name server host In-zone name servers place the same DNS provider ZONE names are within the .BANK domain zone. security requirements on the name Approved registrars server as the .BANK domain itself. 2 Implement Domain Name System DNSSEC ensures that internet users DNS provider Security Extensions (DNSSEC) with are reaching your organization online Approved registrars ZONE strong cryptographic algorithms. and have not been redirected to a fraudulent website. 3 Obtain a digital identity certificate. Your .BANK domain will resolve to Certificate authority ENCRYPTION HTTPS, which ensures all data is Registrar secure in transit. Web host 4 Ensure Transport Layer Security (TLS) TLS creates an encrypted connection, Certificate authority has been implemented using version 1.2 protecting your website and visitors, ENCRYPTION Registrar or greater where required. securing email communications, and Web host supporting the safe and secure Email provider transmission of information and transactions. 5 Publish in DNS as a text record: DMARC helps protect against phishing Email security and spoofing, and increases the provider EMAIL 1. Domain-based Message Authentication, Approved registrars AUTHENTICATION Reporting, and Conformance deliverability of email to your customers, (DMARC) record; especially when used in combination with SPF and/or DKIM. -

Cisa-Dmarc.Pdf
Domain-Based Message Authentication, Reporting and Conformance Domain-Based Message Authentication, Reporting and Conformance (DMARC) is an email authentication policy that protects against bad actors using fake email addresses disguised to look like legitimate emails from trusted sources. DMARC makes it easier for email senders and receivers to determine whether or not an email legitimately originated from the identified sender. Further, DMARC provides the user with instructions for handling the email if it is fraudulent. Why should State and Local Election Officials be interested in DMARC? State and local election officials face a high volume of spam and phishing attacks on their internet accessible systems. Fraudulent emails are easy to design and cheap to send, which provides malicious actors incentive to use repeated email attacks. Unfortunately, employees are often the point of failure for these attacks, when they are forced to repeatedly determine whether emails are legitimate or fake. DMARC provides an automated solution to this issue, making it easier to identify spam and phishing messages before they ever reach an employee’s inbox. How does DMARC work? DMARC removes guesswork from the receiver’s handling of failed emails, limiting or eliminating the user’s exposure to potentially fraudulent and harmful messages. A DMARC policy allows a sender to indicate that their emails are protected by Sender Policy Framework (SPF) and/or Domain Keys Identified Message (DKIM), both of which are industry-recognized email authentication techniques. DMARC also provides instructions on how the receiver should handle emails that fail to pass SPF or DKIM authentication. Options typically include sending the email to quarantine or rejecting it entirely.