A Runtime Assertion Checker for the Java Modeling Language Yoonsik Cheon Iowa State University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Java Modeling Language
The Java Modeling Language Software Fiável Mestrado em Engenharia Informática Mestrado em Informática Faculdade de Ciências da Universidade de Lisboa 2015/2016 Vasco T. Vasconcelos, Antónia Lopes Software Fiável The Java Modeling Language Contracts I The key ingredient of Design by contract, software design methodology promoted by Bertrand Meyer and the Eiffel programming language in 1986. I Inspired by assertions of Hoare logic, contracts place special obligations on both clients and suppliers of a procedure or method. I What does a method require from it’s caller? I What does the method ensure? Software Fiável The Java Modeling Language DBC DBC key idea is to associate a specification with every software element. These specifications (or contracts) govern the interaction of the element with the rest of the world. I Forces the programmer to write exactly what the method does and needs I No need to program defensively (defensive checks can be exensive and increases the complexity of the code of the method and worsen its maintainability) I Assigns blame: specifies who is to blame for not keeping the contract I Provides a standard way to document classes: client programmers are provided with a proper description of the interface properties of a class that is stripped of all implementation information but retains the essential usage information: the contract. Software Fiável The Java Modeling Language Language support for Contracts Language support for contracts exists in different forms: I Eiffel is an object-oriented language that includes contracts I JML adds contracts to the Java language. JML specifications are conventional Java boolean expressions, with a few extensions I Spec# adds contracts to C# I Code Contracts is an API (part of .NET) to author contracts In this course we focus on JML. -

Génération Automatique De Tests Unitaires Avec Praspel, Un Langage De Spécification Pour PHP the Art of Contract-Based Testing in PHP with Praspel
CORE Metadata, citation and similar papers at core.ac.uk Provided by HAL - Université de Franche-Comté G´en´erationautomatique de tests unitaires avec Praspel, un langage de sp´ecificationpour PHP Ivan Enderlin To cite this version: Ivan Enderlin. G´en´eration automatique de tests unitaires avec Praspel, un langage de sp´ecificationpour PHP. Informatique et langage [cs.CL]. Universit´ede Franche-Comt´e,2014. Fran¸cais. <NNT : 2014BESA2067>. <tel-01093355v2> HAL Id: tel-01093355 https://hal.inria.fr/tel-01093355v2 Submitted on 19 Oct 2016 HAL is a multi-disciplinary open access L'archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destin´eeau d´ep^otet `ala diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publi´esou non, lished or not. The documents may come from ´emanant des ´etablissements d'enseignement et de teaching and research institutions in France or recherche fran¸caisou ´etrangers,des laboratoires abroad, or from public or private research centers. publics ou priv´es. Thèse de Doctorat école doctorale sciences pour l’ingénieur et microtechniques UNIVERSITÉ DE FRANCHE-COMTÉ No X X X THÈSE présentée par Ivan Enderlin pour obtenir le Grade de Docteur de l’Université de Franche-Comté K 8 k Génération automatique de tests unitaires avec Praspel, un langage de spécification pour PHP The Art of Contract-based Testing in PHP with Praspel Spécialité Informatique Instituts Femto-ST (département DISC) et INRIA (laboratoire LORIA) Soutenue publiquement -

OOP with Java 16
OOP with Java 16. Inheritance and Overriding Thomas Weise · 汤卫思 [email protected] · http://iao.hfuu.edu.cn Hefei University, South Campus 2 合肥学院 南艳湖校区/南2区 Faculty of Computer Science and Technology 计算机科学与技术系 Institute of Applied Optimization 应用优化研究所 230601 Shushan District, Hefei, Anhui, China 中国 安徽省 合肥市 蜀山区 230601 Econ. & Tech. Devel. Zone, Jinxiu Dadao 99 经济技术开发区 锦绣大道99号 Outline 1 Introduction 2 Extending Classes and Class Hierarchy 3 Multi-Level Inheritance 4 The Class Object 5 static vs. instance methods 6 Summary website OOPwithJava ThomasWeise 2/23 Introduction • So far, we have basically treated as objects as data structures and used methods to work on them OOPwithJava ThomasWeise 3/23 Introduction • So far, we have basically treated as objects as data structures and used methods to work on them • But Object-Oriented Programming is much more OOPwithJava ThomasWeise 3/23 Introduction • So far, we have basically treated as objects as data structures and used methods to work on them • But Object-Oriented Programming is much more • The true power of OOP arises from class inheritance and extension (often called specialization) OOPwithJava ThomasWeise 3/23 Extending Classes • A class Student can extend another class Person OOPwithJava ThomasWeise 4/23 Extending Classes • A class Student can extend another class Person • Student inherits all the fields and functionality of the original class Person OOPwithJava ThomasWeise 4/23 Extending Classes • A class Student can extend another class Person • Student inherits all the fields and functionality -

Programming in JAVA Topic: • a Closer Look at Methods And
B. Sc. (H) Computer Science Semester II BHCS03 – Programming in JAVA Topic: A Closer Look at Methods and Classes Inheritance Command Line Arguments The java command-line argument is an argument i.e. passed at the time of running the java program. The arguments passed from the console can be received in the java program and it can be used as an input. So, it provides a convenient way to check the behavior of the program for the different values. You can pass N (1,2,3 and so on) numbers of arguments from the command prompt. Simple example of command-line argument In this example, we are receiving only one argument and printing it. To run this java program, you must pass at least one argument from the command prompt. class CommandLineExample{ public static void main(String args[]){ System.out.println("Your first argument is: "+args[0]); } } compile by > javac CommandLineExample.java run by > java CommandLineExample sonoo Output: Your first argument is: sonoo Varargs: Variable length arguments A method with variable length arguments(Varargs) in Java can have zero or multiple arguments. Variable length arguments are most useful when the number of arguments to be passed to the method is not known beforehand. They also reduce the code as overloaded methods are not required. Example public class Demo { public static void Varargs(String... str) { System.out.println("\nNumber of arguments are: " + str.length); System.out.println("The argument values are: "); for (String s : str) System.out.println(s); } public static void main(String args[]) { Varargs("Apple", "Mango", "Pear"); Varargs(); Varargs("Magic"); } } Output Number of arguments are: 3 The argument values are: Apple Mango Pear Number of arguments are: 0 The argument values are: Number of arguments are: 1 The argument values are: Magic Overloading Varargs Methods Overloading allows different methods to have same name, but different signatures where signature can differ by number of input parameters or type of input parameters or both. -

The Java Modeling Language
The Java Modeling language JML Erik Poll Digital Security Radboud University Nijmegen JML • formal specification language for sequential Java by Gary Leavens et. al. – to specify behaviour of Java classes & interfaces – to record detailed design decisions by adding annotations to Java source code in Design-By- Contract style, using eg. pre/postconditions and invariants • Design goal: meant to be usable by any Java programmer Lots of info on http://www.jmlspecs.org Erik Poll, JML introduction - CHARTER meeting - 2 to make JML easy to use • JML annotations added as special Java comments, between /*@ .. @*/ or after //@ • JML specs can be in .java files, or in separate .jml files • Properties specified using Java syntax, extended with some operators \old( ), \result, \forall, \exists, ==> , .. and some keywords requires, ensures, invariant, .... Erik Poll, JML introduction - CHARTER meeting - 3 JML example public class ePurse{ private int balance; //@ invariant 0 <= balance && balance < 500; //@ requires amount >= 0; //@ ensures balance <= \old(balance); public debit(int amount) { if (amount > balance) { throw (new BankException("No way"));} balance = balance – amount; } Erik Poll, JML introduction - CHARTER meeting - 4 What can you do with this? • documentation/specification – record detailed design decisions & document assumptions (and hence obligations!) – precise, unambiguous documentation • parsed & type checked • use tools for – runtime assertion checking • eg when testing code – compile time (static) analyses • up to full formal program -

Module 3 Inheritance in Java
Module 3 Inheritance in Java Inheritance in java is a mechanism in which one object acquires all the properties and behaviors of parent object. The idea behind inheritance in java is that you can create new classes that are built upon existing classes. When you inherit from an existing class, you can reuse methods and fields of parent class, and you can add new methods and fields also. Inheritance represents the IS-A relationship, also known as parent-child relationship. For Method Overriding (so runtime polymorphism can be achieved). For Code Reusability. Syntax of Java Inheritance class Subclass-name extends Superclass-name { KTUNOTES.IN //methods and fields } The extends keyword indicates that you are making a new class that derives from an existing class. In the terminology of Java, a class that is inherited is called a super class. The new class is called a subclass. As displayed in the above figure, Programmer is the subclass and Employee is the superclass. Relationship between two classes is Programmer IS-A Employee.It means that Programmer is a type of Employee. class Employee{ float salary=40000; } class Programmer extends Employee{ int bonus=10000; public static void main(String args[]){ Programmer p=new Programmer(); System.out.println("Programmer salary is:"+p.salary); System.out.println("Bonus of Programmer is:"+p.bonus); } } Programmer salary is:40000.0 Bonus of programmer is:10000 In the above example, Programmer object can access the field of own class as well as of Employee class i.e. code reusability. Downloaded from Ktunotes.in Types of inheritance in java On the basis of class, there can be three types of inheritance in java: single, multilevel hierarchical. -

You Say 'JML' ? Wikipedia (En)
You say 'JML' ? Wikipedia (en) PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Mon, 06 Jan 2014 09:58:42 UTC Contents Articles Java Modeling Language 1 Design by contract 5 Formal methods 10 References Article Sources and Contributors 15 Image Sources, Licenses and Contributors 16 Article Licenses License 17 Java Modeling Language 1 Java Modeling Language The Java Modeling Language (JML) is a specification language for Java programs, using Hoare style pre- and postconditions and invariants, that follows the design by contract paradigm. Specifications are written as Java annotation comments to the source files, which hence can be compiled with any Java compiler. Various verification tools, such as a runtime assertion checker and the Extended Static Checker (ESC/Java) aid development. Overview JML is a behavioural interface specification language for Java modules. JML provides semantics to formally describe the behavior of a Java module, preventing ambiguity with regard to the module designers' intentions. JML inherits ideas from Eiffel, Larch and the Refinement Calculus, with the goal of providing rigorous formal semantics while still being accessible to any Java programmer. Various tools are available that make use of JML's behavioral specifications. Because specifications can be written as annotations in Java program files, or stored in separate specification files, Java modules with JML specifications can be compiled unchanged with any Java compiler. Syntax JML specifications are added to Java code in the form of annotations in comments. Java comments are interpreted as JML annotations when they begin with an @ sign. -

Conformity Behavior of Dissimilar Methods for Object Oriented
K. LOUZAOUUI Conformity behavior of dissimilar methods for object oriented constraint programming 212 Conformity Behavior of Dissimilar Methods for Object Oriented Constraint Programming Khadija Louzaoui Khalid Benlhachmi Department of Mathematics Department of Computer Sciences Faculty of Sciences, Ibn Tofail University Faculty of Sciences, Ibn Tofail University Kenitra, Morocco Kenitra, Morocco Abstract—This paper presents an approach for testing the number of test cases is infinite, therefore, testing is very conformity of overridden and overriding methods using expensive. So, how to select the most proper set of test cases? inheritance principle. The first objective of this work is the In practice, various techniques are used for that, some of them reduction of the test sequences by using only one generation of are based on the specification of the program under test using test data. The second result is the conformity testing of methods precondition, postcondition and invariant constraints. In this even if they are not similar: Our approach shows how the similarity partitioning can be used for testing not the similarity way the specifications by constraints in an object oriented behavior between methods but the conformity behavior of paradigm can be specified by formal languages as OCL [3] and subclasses for an object oriented model. JML [4], and are used for generating test data from formal specifications [5]. This software verification by constraints can In this work we use a mathematical modeling such as domain help for creating a mathematical modeling and building the partitioning and states graph for testing the conformity of parts of different classes of errors (equivalence partitioning). -
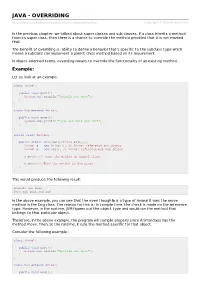
JAVA - OVERRIDING Copyright © Tutorialspoint.Com
JAVA - OVERRIDING http://www.tutorialspoint.com/java/java_overriding.htm Copyright © tutorialspoint.com In the previous chapter, we talked about super classes and sub classes. If a class inherits a method from its super class, then there is a chance to override the method provided that it is not marked final. The benefit of overriding is: ability to define a behavior that's specific to the subclass type which means a subclass can implement a parent class method based on its requirement. In object-oriented terms, overriding means to override the functionality of an existing method. Example: Let us look at an example. class Animal{ public void move(){ System.out.println("Animals can move"); } } class Dog extends Animal{ public void move(){ System.out.println("Dogs can walk and run"); } } public class TestDog{ public static void main(String args[]){ Animal a = new Animal(); // Animal reference and object Animal b = new Dog(); // Animal reference but Dog object a.move();// runs the method in Animal class b.move();//Runs the method in Dog class } } This would produce the following result: Animals can move Dogs can walk and run In the above example, you can see that the even though b is a type of Animal it runs the move method in the Dog class. The reason for this is: In compile time, the check is made on the reference type. However, in the runtime, JVM figures out the object type and would run the method that belongs to that particular object. Therefore, in the above example, the program will compile properly since Animal class has the method move. -

Method Overriding
Method Overriding OOC 4th Sem, ‘B’ Div 2016-17 Prof. Mouna M. Naravani ➢ In a class hierarchy, when a method in a subclass has the same name and type signature as a method in its superclass, then the method in the subclass is said to override the method in the superclass. ➢ When an overridden method is called from within a subclass, it will always refer to the version of that method defined by the subclass. ➢ The version of the method defined by the superclass will be hidden. class A { class B extends A { int i, j; int k; A(int a, int b) { B(int a, int b, int c) { i = a; super(a, b); j = b; k = c; } } // display i and j // display k -- this overrides show() in A void show() { void show() { System.out.println("i and j: " + i + " " + j); System.out.println("k: " + k); } } } } class Override { Output: public static void main(String args[]) k : 3 { B subOb = new B(1, 2, 3); subOb.show(); // this calls show() in B } } ➢ When show( ) is invoked on an object of type B, the version of show( ) defined within B is used. ➢ That is, the version of show( ) inside B overrides the version declared in A. ➢ If you wish to access the superclass version of an overridden method, you can do so by using super. class B extends A { int k; B(int a, int b, int c) { super(a, b); Output: k = c; i and j : 1 2 } k : 3 void show() { super.show(); // this calls A's show() System.out.println("k: " + k); } } ➢ Method overriding occurs only when the names and the type signatures of the two methods are identical. -

Introduction to JML the Java Modeling Language
Goal: JML should be easy to use for any Java programmer. Outline of this tutorial First • introduction to JML Introduction to JML • overview of tool support for JML, esp. runtime assertion checking (using jmlrac) and extended static David Cok, Joe Kiniry, and Erik Poll checking ESC/Java2 Then Eastman Kodak Company, University College Dublin, • ESC/Java2: Use and Features and Radboud University Nijmegen • ESC/Java2: Warnings • Specification tips and pitfalls • Advanced JML: more tips and pitfalls interspersed with demos. David Cok, Joe Kiniry & Erik Poll - ESC/Java2 & JML Tutorial – p.1/30 David Cok, Joe Kiniry & Erik Poll - ESC/Java2 & JML Tutorial – p.2/30 JML by Gary Leavens et al. Formal specification language for Java • to specify behaviour of Java classes • to record design &implementation decisions The Java Modeling Language by adding assertions to Java source code, eg • preconditions JML • postconditions • invariants www.jmlspecs.org as in Eiffel (Design by Contract), but more expressive. David Cok, Joe Kiniry & Erik Poll - ESC/Java2 & JML Tutorial – p.3/30 David Cok, Joe Kiniry & Erik Poll - ESC/Java2 & JML Tutorial – p.4/30 JML by Gary Leavens et al. JML Formal specification language for Java To make JML easy to use: to specify behaviour of Java classes • • JML assertions are added as comments in .java file, • to record design &implementation decisions between /*@ . @*/, or after //@, by adding assertions to Java source code, eg • Properties are specified as Java boolean expressions, extended with a few operators (nold, nforall, nresult, • preconditions . ). • postconditions • using a few keywords (requires, ensures, • invariants signals, assignable, pure, invariant, non null, . -

Unit 2 – Part 4. Polymorphism(OOP)
Unit 2 – part 4. Polymorphism(OOP) BCIS 222. Object Oriented Programming Instructor: Dr. Carlo A. Mora LMS: http://l earn.nmsu.ed u OOP Principles y Piece of Cake!! A (Abstraction) E P (Encapsulation) (Polymorphism) I (Inheritance) protected Members y Intermediate level of protection between public and private y prottdtected members accessible to y superclass members y subclass members y Clbhlass members in the same namespace y Subclass access superclass member y Keyword base and a dot (.) y E.g. base.toString() y Method overloading vs. Method overriding y Overloading Having several methods with same name but different parameters y Overriding redefining a method in a subclass y How to access and overridden method? super keyword UiUsing protec tdted iitnstance variiblables y Advantages y subclasses can modify values directly y Slight increase in performance y Avoid set/get function call overhead y Disadvantages y No validityyg checking y subclass can assign illegal value y Implementation dependent y subcl ass method s more likliklely depend ent on superclass iilmplemen ta tion y superclass implementation changes may result in subclass modifications y Fragile (brittle) software Wrapping up the Case Study y What advantages do we have by having a class Hierarchy? y No need to declare common members in subclasses (e.g. name) y Simplified version of methods (e.g. toString) y Wha t is the purpose of y GetGraduationDate method? y Rethink the TestClass y What if I need to create an array to hold different types of students? Polymorphism y Dictionary