The Thin Lines Between Data Analysis and Surveillance: Reflections on a Research History
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Retail for Lease 2987 Granville Street Vancouver, British Columbia
RETAIL FOR LEASE 2987 GRANVILLE STREET VANCOUVER, BRITISH COLUMBIA Exceptional Yaletown Retail Opportunity CONTACT US Mario Negris Nolan Toigo Personal Real Estate Corporation Sales Representative Executive Vice President +1 778 372 3938 +1 604 662 3000 [email protected] [email protected] URBAN | PROPERTIES | GROUP WEST 5TH AVENUE UNO LANGANN INE ART AVAILABLE TAL SHOP CHEESECAE ETC. IRA HAA SPA ATINSONS WEST 6TH AVENUE UNER CONSTRUCTION ASTERPIECE PAULS PLACE OLETTERY ART|ANTIUES|ESIGN URBAN ITNESS ARARAT RUGS SCOTT ART RAIN SONS ART AVYAN CARPETS CANAIAN CANNABIS CANCER RESERACH ASTERS GALLERY HEEL INE ART STARBUCS AUCTION GALLERY WEST 7TH AVENUE VACANT INUSTRIAL REVOLUTION ONA NELLIS IAN TAN GALLERY AVAILABLE CACHE COUTURE VANCOUVER HAIR ACAEY URBAN BARN OUGLAS REYNOLS GALLERY SUYA HOE ECOR ALISON BOUTIUE THE BRIC GRANVILLE STREET AVAILABLE WEST 8TH AVENUE STRUCTUBE PA PAYRY RUG VILLA BEAU INTERIORS VERANAH ANTIUES CALIORNIA CLOSETS URBANITY SG P GALLERY ALLURE NAILS SPA UBREAITII RESH SLICE LE SALON HAE SOE SHOP URBATO GALLERY RE RUBY HAIR STUIO RBC AVAILABLE WEST BROADWAY BLEN COEE CONALS RESTAURANT CHOW SANG INIGO 2 LEVELS EWELLERY E3 URNITURE BURRITO CURRENCY STARBUCS ECHANGE SUSHI VAN GRANVILLE GREEN RHINO EICAL CLINIC IREHALL CANNABIS VANCOUVER SHOE REPAIR PHARASAVE RESTORATION HARWARE PUBLIC LIBRARY EWAR CHAPAN WOAN W 10TH AVENUE BAN O ONTREAL POTTERY BARN AVAILABLE 2 LEVELS ASON . REE PEOPLE AS BEER WINE SPIRITS SOT OC THE ARUIS HOUSE O NIVES ASHIA OE ASHION ROOTS ECCO STARBUCS COEE EYES OR YOU LUSSO BABY WIRELESS -

Microsoft Software License Terms for a Virtual Hard Disk Image of Evaluation Copies of the Microsoft Products Identified in Exhibit A
MICROSOFT SOFTWARE LICENSE TERMS FOR A VIRTUAL HARD DISK IMAGE OF EVALUATION COPIES OF THE MICROSOFT PRODUCTS IDENTIFIED IN EXHIBIT A These license terms are an agreement between Microsoft Corporation (or based on where you live, one of its affiliates) and you. Please read them. They apply to the evaluation software named above, which includes the media on which you received it, if any. The terms also apply to any Microsoft Internet-based services for this software. BY ACCESSING OR USING THE SOFTWARE, YOU ACCEPT THIS AGREEMENT. IF YOU DO NOT ACCEPT THIS AGREEMENT, YOU MAY NOT ACCESS OR USE THE SOFTWARE. AS DESCRIBED BELOW, USING SOME FEATURES ALSO OPERATES AS YOUR CONSENT TO THE TRANSMISSION OF CERTAIN STANDARD COMPUTER INFORMATION FOR INTERNET-BASED SERVICES. If you comply with this agreement, you have the rights below. 1. ACCESS AND USE RIGHTS. The terms of this agreement supersede the terms of any Microsoft software license term agreement that you may encounter in this software. You may use the Virtual Hard Disk (VHD) formats, including Microsoft Virtual PC or Microsoft Virtual Server. You may use the software only to demonstrate and internally evaluate it. You may not use the software in a live operating environment. The software is licensed as a single piece of software. You may not separate its component parts. You may access or use on more than one device. The Exceptions and Additional Terms for Particular Products as included in Exhibit A. 2. INTERNET-BASED SERVICES. Microsoft may provide Internet-based services with the software. It may change or cancel them at any time. -

Georgia Department of Transportation Automated Traffic Signal
Georgia Department of Transportation Automated Traffic Signal Performance Measures Installation Manual Prepared for: Georgia Department of Transportation 600 West Peachtree Street, NW Atlanta, Georgia 30308 Prepared by: Atkins North America 1600 RiverEdge Parkway, NW Suite 600 Atlanta, GA 30328 Special Thanks to the Utah Department of Transportation: 2/23/2017 Document Control Panel File Name: ATSPM_Installation_Manual.docx Version No.: Created By: Philip Blaiklock, Atkins Date of First Submission: Updated By: Client Comments Received: Revision History Control Panel CREATED BY: Philip Blaiklock, Atkins David Bremer, Atkins Brian Ritchson, Atkins REVIEWED BY: Ron Meyer, Atkins 12/13/2016 TECHNICAL REVIEW: Mark Taylor, UDOT Jamie Mackey, UDOT Shane Johnson, UDOT Derek Lowe, UDOT MODIFIED BY: COMPLETED BY: 2 3 Table of Contents 1. Prerequisites 7 1.1. Server Requirements 7 1.2. Other Requirements 8 2. New Install Procedure 8 2.1. Create the Website using IIS 8 2.2. Launch Website and Populate Database 10 2.3. Set up Regions 11 2.4. Set up User Accounts 12 2.5. Configure Signals, Approaches, and Routes 12 2.6. Configure the “Generate Add Data Script” Component 13 2.7. Create Web Services 15 2.8. Install the “Import Controller Logs” Component(s) 16 2.8.1. Install the “FTPFromAllControllers” component 16 2.8.2. Install the “GetMaxTimeRecords” Component 17 2.9. Install the “Decode and Import” Component(s) 17 2.9.1. Install the “DecodeAndImportASC3Logs” Component 17 2.9.2. Install the “DecodePeekLogs” Component 18 2.9.3. Install the “DecodeSiemensLogs” Component 18 2.9.4. Install the “DecodeTrafficwareLogs” Component 19 2.10. -
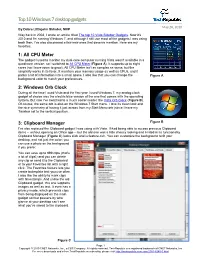
Top 10 Windows 7 Desktop Gadgets May 28, 2010 by Debra Littlejohn Shinder, MVP Way Back in 2008, I Wrote an Article Titled the Top 10 Vista Sidebar Gadgets
Top 10 Windows 7 desktop gadgets May 28, 2010 By Debra Littlejohn Shinder, MVP Way back in 2008, I wrote an article titled The top 10 Vista Sidebar Gadgets. Now it's 2010 and I'm running Windows 7, and although I still use most of the gadgets I was using back then, I've also discovered a few new ones that deserve mention. Here are my favorites. 1: All CPU Meter The gadget I used to monitor my dual-core computer running Vista wasn't available in a quad-core version, so I switched to All CPU Meter (Figure A). It supports up to eight cores (so I have room to grow). All CPU Meter isn't as complex as some, but the simplicity works in its favor. It monitors your memory usage as well as CPUs, and it packs a lot of information into a small space. I also like that you can change the Figure A background color to match your preferences. 2: Windows Orb Clock During all the time I used Vista and the first year I used Windows 7, my analog clock gadget of choice was the electric blue version of the one that comes with the operating system. But now I've switched to a much cooler model: the Vista Orb Clock (Figure B). Of course, the same orb is also on the Windows 7 Start menu. I love its clean look and the nice symmetry of having it just across from my Start Menu orb (since I have my Taskbar set to the vertical position. -

GDOT ATSPM Installation Manual
Georgia Department of Transportation Automated Traffic Signal Performance Measures Installation Manual Prepared for: Georgia Department of Transportation 600 West Peachtree Street, NW Atlanta, Georgia 30308 Prepared by: Atkins North America 1600 RiverEdge Parkway, NW Suite 600 Atlanta, GA 30328 Special Thanks to the Utah Department of Transportation: 12/16/2016 GDOT/UDOT Automated Traffic Signal Performance Measures Installation Manual Table of Contents 1. Prerequisites ..................................................................................................................................... 1 1.1. Server Requirements ..................................................................................................................... 1 1.2. Other Requirements ...................................................................................................................... 2 2. New Install Procedure ................................................................................................................. 2 2.1. Create the Website using IIS ......................................................................................................... 2 2.2. Launch Website and Populate Database ...................................................................................... 4 2.3. Set up Regions ............................................................................................................................... 5 2.4. Set up User Accounts ................................................................................................................... -

A/B Testing Challenges in Large Scale Social Networks
From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks Ya Xu, Nanyu Chen, Adrian Fernandez, Omar Sinno, Anmol Bhasin LinkedIn Corp, 2029 Stierlin Court, Mountain View, CA 94043 {yaxu, nchen, afernandez, osinno, abhasin}@linkedin.com ABSTRACT experiments. The theory of controlled experiment dates back to Sir Ronald A. A/B testing, also known as bucket testing, split testing, or Fisher’s experiments at the Rothamsted Agricultural Experimental controlled experiment, is a standard way to evaluate user Station in England in the 1920s [11]. Since then, many textbooks engagement or satisfaction from a new service, feature, or and papers from different fields have provided theoretical product. It is widely used among online websites, including social foundations [20, 21, 32, 33] for running controlled experiments. network sites such as Facebook, LinkedIn, and Twitter to make While the theory may be straightforward, the deployment and data-driven decisions. At LinkedIn, we have seen tremendous mining of experiments in practice and at scale can be complex and growth of controlled experiments over time, with now over 400 challenging [13, 14]. In particular, several past KDD papers have concurrent experiments running per day. General A/B testing discussed at length the experimentation systems used at Microsoft frameworks and methodologies, including challenges and pitfalls, Bing and Google [8, 9], including best practices and pitfalls [7, have been discussed extensively in several previous KDD work 10]. Facebook also introduces the PlanOut language which [7, 8, 9, 10]. In this paper, we describe in depth the provides a toolkit for parameter-based experiments [12]. -

UI Design and Interaction Guide for Windows Phone 7
UI Design and Interaction Guide 7 for Windows Phone 7 July 2010 Version 2.0 UI Design and Interaction Guide for Windows Phone 7 July 2010 Version 2.0 This is pre-release documentation and is subject to change in future releases. This document supports a preliminary release of a software product that may be changed substantially prior to final commercial release. This docu- ment is provided for informational purposes only and Microsoft makes no warranties, either express or implied, in this document. Information in this document, including URL and other Internet Web site references, is subject to change without notice. The entire risk of the use or the results from the use of this document remains with the user. Unless otherwise noted, the companies, organizations, products, domain names, e-mail addresses, logos, people, places, and events depicted in examples herein are fictitious. No association with any real company, organization, product, domain name, e-mail address, logo, person, place, or event is intended or should be inferred. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this docu- ment. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property. -

We Are Living CRM Philosophy
We are Living CRM Philosophy www.inskysolutions.com www.inskysolutions.com ContactInSky Instead of expensive and complicated software, central place where users can get the informa- InSky Solutions has developed a very simple tion on related activities, but also perform some but rich business solution based on trusted and of the activities required. Some of the business accepted Microsoft products: Microsoft Dynam- benefits resulting from implementation: tomers are informed of the possibility to upgrade ever, to share their bad experiences with new, immediately – it was designed holistically and potential users. Until now, an insufficient number ics 365, SkypeforBusiness, Office 365, ASP.NET, • Improving and providing consistent quality implemented in parts. of CRM providers were focused on smaller organ- HTML, Bing maps, Power BI, Team Foundation information to users Server, Exchange, Edge and SharePoint. The system offers a wide range of security isations, partially due to the complexity of the • Enabled communication with the persons implementation, which is almost equal to that of The ContactInSky solution is unique and modelling features, and it is important to choose that are best addressed in a specific area a medium-sized company, and due to the prices, innovative, and does not require separate phone the most appropriate approach to implementing • Improved productivity, better access and which were too high for smaller companies. infrastructure such as telephone switchboards a solution. Each feature offers a combination of better records Nowadays, the option of acquiring software as a or PBX infrastructure networks; Internet access characteristics that provide a balance between service, e.g. a cloud solution, led to larger price is the only requirement. -

Model Ensemble for Click Prediction in Bing Search Ads
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Weiwei Deng Chen Gu Microsoft Bing Microsoft Bing Microsoft Bing No. 5 Dan Ling Street No. 5 Dan Ling Street No. 5 Dan Ling Street Beijing, China Beijing, China Beijing, China [email protected] [email protected] [email protected] ∗ Hucheng Zhou Cui Li Feng Sun Microsoft Research Microsoft Research Microsoft Bing No. 5 Dan Ling Street No. 5 Dan Ling Street No. 5 Dan Ling Street Beijing, China Beijing, China Beijing, China [email protected] [email protected] [email protected] ABSTRACT Google [21], Facebook [14] and Yahoo! [3]. Recently, factoriza- Accurate estimation of the click-through rate (CTR) in sponsored tion machines (FMs) [24, 5, 18, 17], gradient boosting decision ads significantly impacts the user search experience and businesses’ trees (GBDTs) [25] and deep neural networks (DNNs) [29] have revenue, even 0.1% of accuracy improvement would yield greater also been evaluated and gradually adopted in industry. earnings in the hundreds of millions of dollars. CTR prediction is A single model would lead to suboptimal accuracy, and the above- generally formulated as a supervised classification problem. In this mentioned models all have various different advantages and dis- paper, we share our experience and learning on model ensemble de- advantages. They are usually ensembled together in an industry sign and our innovation. Specifically, we present 8 ensemble meth- setting (or even machine learning competition like Kaggle [15]) to ods and evaluate them on our production data. Boosting neural net- achieve better prediction accuracy. For instance, apps recommen- works with gradient boosting decision trees turns out to be the best. -

Review of Web Mapping: Eras, Trends and Directions
International Journal of Geo-Information Review Review of Web Mapping: Eras, Trends and Directions Bert Veenendaal 1,*, Maria Antonia Brovelli 2 ID and Songnian Li 3 ID 1 Department of Spatial Sciences, Curtin University, GPO Box U1987, Perth 6845, Australia 2 Department of Civil and Environmental Engineering (DICA), Politecnico di Milano, P.zza Leonardo da Vinci 32, 20133 Milan, Italy; [email protected] 3 Department of Civil Engineering, Ryerson University, 350 Victoria Street, Toronto, ON M5B 2K3, Canada; [email protected] * Correspondence: [email protected]; Tel.: +618-9266-7701 Received: 28 July 2017; Accepted: 16 October 2017; Published: 21 October 2017 Abstract: Web mapping and the use of geospatial information online have evolved rapidly over the past few decades. Almost everyone in the world uses mapping information, whether or not one realizes it. Almost every mobile phone now has location services and every event and object on the earth has a location. The use of this geospatial location data has expanded rapidly, thanks to the development of the Internet. Huge volumes of geospatial data are available and daily being captured online, and are used in web applications and maps for viewing, analysis, modeling and simulation. This paper reviews the developments of web mapping from the first static online map images to the current highly interactive, multi-sourced web mapping services that have been increasingly moved to cloud computing platforms. The whole environment of web mapping captures the integration and interaction between three components found online, namely, geospatial information, people and functionality. In this paper, the trends and interactions among these components are identified and reviewed in relation to the technology developments. -

Consumer Heterogeneity and Paid Search Effectiveness
Consumer Heterogeneity and Paid Search E↵ectiveness: A Large Scale Field Experiment⇤ Thomas Blake† Chris Nosko‡ Steven Tadelis§ October 30, 2013 Abstract Internet advertising has been the fastest growing advertising channel in recent years with paid search ads comprising the bulk of this revenue. We present results from a series of large-scale field experiments done at eBay that were designed to measure the causal e↵ectiveness of paid search ads. Because search clicks and purchase behavior are correlated, we show that returns from paid search are a fraction of conventional non-experimental estimates. As an extreme case, we show that brand-keyword ads have no short-term benefits. For non-brand keywords we find that new and infrequent users are positively influenced by ads but that more frequent users whose purchasing behavior is not influenced by ads account for most of the advertising expenses, resulting in average returns that are negative. ⇤We are grateful to many ebay employees and executives who made this work possible. We thank Susan Athey, Randall Lewis, David Reiley, Justin Rao and Florian Zettelmeyer for comments on earlier drafts. †eBay Research Labs. Email: [email protected] ‡University of Chicago and eBay Research Labs. Email: [email protected] §UC Berkeley and eBay Research Labs. Email: [email protected] 1 Introduction Advertising expenses account for a sizable portion of costs for many companies across the globe. In recent years the internet advertising industry has grown disproportionately, with revenues in the -

Microsoft Lumia
Microsoft Lumia 640 Prepared for Anything Key Features Operating System: Windows Phone 8.1 with Lumia • Latest version of Windows Phone 8.1 along with Denim seamlessly integrated Microso Office experiences Lumia 640 • Built-in Skype integraon and a 1MP front-facing Networks: camera for switching seamlessly between voice and • GSM/EDGE: 850/900/1800/1900 MHz, WCDMA: video calls 850/900/1900/2100 MHz 3G Dual SIM • 8MP camera with LED flash and Lumia Camera right out of the box Processor: CPU Qualcomm Snapdragon 400 Prepared for Anything • 1GB of memory and powerful quad core processor (MSM8926), 1.2 GHz quad core processor • Smart Dual SIM to ensure you never miss a call Memory: 1GB RAM, 8 GB internal mass memory + up Accessories to 128 GB Micro SD & 30GB* free OneDrive cloud • Cover for Lumia 640 – with card holder storage • Microso Screen Sharing for Lumia Phones • Comfort Headset Display: 5” HD (1280x720, 16:9) IPS LCD, 294 PPI, Glance screen, Corning Gorilla Glass 3, Sunlight Size: 141.3 x 72.2 x 8.85 (volumetric) mm readability enhancements Weight: 145g Primary Camera: 8 MP AF (3280x2464), f/2.2, 28 mm, 1080p @ 30 fps video (connuous autofocus), Colors: Flash: LED, Lumia Camera Talk time and Standby time (Estimates) Secondary Camera: HD 1 MP wide angle, f/2.4, • Standby time: up to 35 days (840 hours) 720p video • Talk time: up to 27.3 hours (2G) • Talk time: up to 20.3 hours (3G) Connectivity: BT 4.0, microUSB 2.0, Micro SIM, A-GPS +GLONASS, BeiDou, DLNA, Screen cloning with Sales Package Miracast, WLAN 802.11 b/g/n/ • Lumia 640 3G Dual SIM • Charger: AC-20 Sensors: Accelerometer, Magnetometer, Proximity, • WH-108 headset (In select markets only) Ambient Light Sensor • Battery: BV-T5C (removable) • User guide Audio: 3.5 mm AV connector (AHJ), FM Radio, • Note: there may be differences in country / Internet Radio customer variants Battery: 2500 mAh (BV-T5C) removable baery * available when camera roll back up is activated.