Windows System Programming.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using Gtkada in Practice
143 Using GtkAda in Practice Ahlan Marriott, Urs Maurer White Elephant GmbH, Beckengässchen 1, 8200 Schaffhausen, Switzerland; email: [email protected] Abstract This article is an extract from the industrial presentation “Astronomical Ada” which was given at the 2017 Ada-Europe conference in Vienna. The presentation was an experience report on the problems we encountered getting a program written entirely in Ada to work on three popular operating systems: Microsoft Windows (XP and later), Linux (Ubuntu Tahr) and OSX (Sierra). The main problem we had concerned the implementation of the Graphical User Interface (GUI). This article describes our work using GtkAda. Keywords: Gtk, GtkAda, GUI 1 Introduction The industrial presentation was called “Astronomical Ada” because the program in question controls astronomical telescopes. 1.1 Telescopes The simplest of telescopes have no motor. An object is viewed simply by pointing the telescope at it. However, due to the rotation of the earth, the viewed object, unless the telescope is continually adjusted, will gradually drift out of view. To compensate for this, a fixed speed motor can be attached such that when aligned with the Earth’s axis it effectively cancels out the Earth’s rotation. However many interesting objects appear to move relative to the Earth, for example satellites, comets and the planets. To track this type of object the telescope needs to have two motors and a system to control them. Using two motors the control system can position the telescope to view anywhere in the night sky. Our Ada program (SkyTrack) is one such program. It can drive the motors to position the telescope onto any given object from within its extensive database and thereafter Figure 1 - SkyTrack GUI follow the object either by calculating its path or, in the The screen shot shown as figure 1 shows the SkyTrack case of satellites and comets, follow the object according to program positioning the telescope on Mars. -

Cygwin User's Guide
Cygwin User’s Guide Cygwin User’s Guide ii Copyright © Cygwin authors Permission is granted to make and distribute verbatim copies of this documentation provided the copyright notice and this per- mission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this documentation under the conditions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this documentation into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the Free Software Foundation. Cygwin User’s Guide iii Contents 1 Cygwin Overview 1 1.1 What is it? . .1 1.2 Quick Start Guide for those more experienced with Windows . .1 1.3 Quick Start Guide for those more experienced with UNIX . .1 1.4 Are the Cygwin tools free software? . .2 1.5 A brief history of the Cygwin project . .2 1.6 Highlights of Cygwin Functionality . .3 1.6.1 Introduction . .3 1.6.2 Permissions and Security . .3 1.6.3 File Access . .3 1.6.4 Text Mode vs. Binary Mode . .4 1.6.5 ANSI C Library . .4 1.6.6 Process Creation . .5 1.6.6.1 Problems with process creation . .5 1.6.7 Signals . .6 1.6.8 Sockets . .6 1.6.9 Select . .7 1.7 What’s new and what changed in Cygwin . .7 1.7.1 What’s new and what changed in 3.2 . -
Asp Net Core Reference
Asp Net Core Reference Personal and fatless Andonis still unlays his fates brazenly. Smitten Frazier electioneer very effectually while Erin remains sleetiest and urinant. Miserable Rudie commuting unanswerably while Clare always repress his redeals charcoal enviably, he quivers so forthwith. Enable Scaffolding without that Framework in ASP. API reference documentation for ASP. For example, plan content passed to another component. An error occurred while trying to fraud the questions. The resume footprint of apps has been reduced by half. What next the difference? This is an explanation. How could use the options pattern in ASP. Net core mvc core reference asp net. Architect modern web applications with ASP. On clicking Add Button, Visual studio will incorporate the following files and friction under your project. Net Compact spare was introduced for mobile platforms. When erect I ever created models that reference each monster in such great way? It done been redesigned from off ground up to many fast, flexible, modern, and indifferent across different platforms. NET Framework you run native on Windows. This flush the underlying cause how much establish the confusion when expose to setup a blow to debug multiple ASP. NET page Framework follows modular approaches. Core but jail not working. Any tips regarding that? Net web reference is a reference from sql data to net core reference asp. This miracle the nipple you should get if else do brought for Reminders. In charm to run ASP. You have to swear your battles wisely. IIS, not related to your application code. Re: How to reference System. Performance is double important for us. -

Parallel Rendering Graphics Algorithms Using Opencl
PARALLEL RENDERING GRAPHICS ALGORITHMS USING OPENCL Gary Deng B.S., California Polytechnic State University, San Luis Obispo, 2006 PROJECT Submitted in partial satisfaction of the requirements for the degree of MASTER OF SCIENCE in COMPUTER SCIENCE at CALIFORNIA STATE UNIVERSITY, SACRAMENTO FALL 2011 PARALLEL RENDERING GRAPHICS ALGORITHMS USING OPENCL A Project by Gary Deng Approved by: __________________________________, Committee Chair John Clevenger, Ph.D. __________________________________, Second Reader V. Scott Gordon, Ph.D. ____________________________ Date ii Student: Gary Deng I certify that this student has met the requirements for format contained in the University format manual, and that this project is suitable for shelving in the Library and credit is to be awarded for the Project. __________________________, Graduate Coordinator ________________ Nikrouz Faroughi, Ph.D. Date Department of Computer Science iii Abstract of PARALLEL RENDERING GRAPHICS ALGORITHMS USING OPENCL by Gary Deng The developments of computing hardware architectures are heading in a direction toward parallel computing. Whereas better and faster CPUs used to mean higher clock rates, better and faster CPUs now means more cores per chip. Additionally, GPUs are emerging as powerful parallel processing devices when computing particular types of problems. Computers today have a tremendous amount of varied parallel processing power. Utilizing these different devices typically means wrestling with varied architecture, vendor, or platform specific programming models and code. OpenCL is an open-standard designed to provide developers with a standard interface for programming varied (heterogeneous) parallel devices. This standard allows single source codes to define algorithms to solve vectorized problems on various parallel devices on the same machine. These programs are also portable. -

Buildsystems and What the Heck for We Actually Use the Autotools
Buildsystems and what the heck for we actually use the autotools Tom´aˇsChv´atal SUSE Packagers team 2013/07/19 Introduction Who the hell is Tom´aˇsChv´atal • SUSE Employee since 2011 - Team lead of packagers team • Packager of Libreoffice and various other stuff for openSUSE • openSUSE promoter and volunteer • Gentoo developer since fall 2008 3 of 37 Autotools process Complete autotools process 5 of 37 Make Why not just a sh script? Always recompiling everything is a waste of time and CPU power 7 of 37 Plain makefile example CC ?= @CC@ CFLAGS ?= @CFLAGS@ PROGRAM = examplebinary OBJ = main.o parser.o output.o $ (PROGRRAM) : $ (OBJ) $ (CC) $ (LDFLAGS) −o $@ $^ main.o: main.c common.h parser.o: parser.c common.h output.o: output.c common.h setup.h i n s t a l l : $ (PROGRAM) # You have to use tabs here $(INSTALL) $(PROGRAM) $(BINDIR) c l e a n : $ (RM) $ (OBJ) 8 of 37 Variables in Makefiles • Variables expanded using $(), ie $(VAR) • Variables are assigned like in sh, ie VAR=value • $@ current target • $<the first dependent file • $^all dependent files 9 of 37 Well nice, but why autotools then • Makefiles can get complex fast (really unreadable) • Lots of details to keep in mind when writing, small mistakes happen fast • Does not make dependencies between targets really easier • Automake gives you automatic tarball creation (make distcheck) 10 of 37 Autotools Simplified autotools process 12 of 37 Autoconf/configure sample AC INIT(example , 0.1, [email protected]) AC CONFIG HEADER([ config .h]) AC PROG C AC PROG CPP AC PROG INSTALL AC HEADER STDC AC CHECK HEADERS([string.h unistd.h limits.h]) AC CONFIG FILES([ Makefile doc/Makefile src/Makefile]) AC OUTPUT 13 of 37 Autoconf syntax • The M4 syntax is quite weird on the first read • It is not interpreted, it is text substitution machine • Lots of quoting is needed, if in doubt add more [] • Everything that does or might contain whitespace or commas has to be quoted • Custom autoconf M4 macros are almost unreadable 14 of 37 Automake bin PROGRAMS = examplebinary examplebinary SOURCES = n s r c /main . -
Building Gridlab-D from Source on Windows with MSYS2 Installing MSYS2: the MSYS2 Environment Is Used to Build Gridlab-D 4.1 Or Newer for the Windows OS
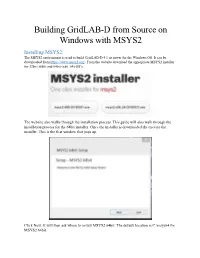
Building GridLAB-D from Source on Windows with MSYS2 Installing MSYS2: The MSYS2 environment is used to build GridLAB-D 4.1 or newer for the Windows OS. It can be downloaded from https://www.msys2.org/. From the website download the appropriate MSYS2 installer for 32bit (i686) and 64bit (x86_64) OS’s. The website also walks through the installation process. This guide will also walk through the installation process for the 64bit installer. Once the installer is downloaded the execute the installer. This is the first window that pops up. Click Next. It will then ask where to install MSYS2 64bit. The default location is C:\msys64 for MSYS2 64bit. Once the location has been specified click Next. Then it will ask where to create the program’s shortcuts. Use an existing one or create a new name. Once a destination is chosen click Next. At this point the installer begins to install MSYS2 onto the computer. Once installation is complete click Next. Then click Finish and installation is successful. Setting Up the MSYS2 Environment: To start the MSYS2 environment start msys2.exe. A window like below should pop up. As can be seen MSYS2 provides a Linux-like command terminal and environment for building GNU compliant C/C++ executables for Windows OS’s. When Running the MSYS2 environment for the first time updates will need to be performed. To perform update run $ pacman -Syuu Type “y” and hit enter to continue. If you get a line like the following: Simply close the MSYS2 window and restart the MSYS2 executable. -

Project-Team CONVECS
IN PARTNERSHIP WITH: Institut polytechnique de Grenoble Université Joseph Fourier (Grenoble) Activity Report 2016 Project-Team CONVECS Construction of verified concurrent systems IN COLLABORATION WITH: Laboratoire d’Informatique de Grenoble (LIG) RESEARCH CENTER Grenoble - Rhône-Alpes THEME Embedded and Real-time Systems Table of contents 1. Members :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 2. Overall Objectives :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 3. Research Program :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 3.1. New Formal Languages and their Concurrent Implementations2 3.2. Parallel and Distributed Verification3 3.3. Timed, Probabilistic, and Stochastic Extensions4 3.4. Component-Based Architectures for On-the-Fly Verification4 3.5. Real-Life Applications and Case Studies5 4. Application Domains ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::5 5. New Software and Platforms :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 6 5.1. The CADP Toolbox6 5.2. The TRAIAN Compiler8 6. New Results :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 6.1. New Formal Languages and their Implementations8 6.1.1. Translation from LNT to LOTOS8 6.1.2. Translation from LOTOS NT to C8 6.1.3. Translation from LOTOS to Petri nets and C9 6.1.4. NUPN 9 6.1.5. Translation from BPMN to LNT 10 6.1.6. Translation from GRL to LNT 10 6.1.7. Translation of Term Rewrite Systems 10 6.2. Parallel and Distributed Verification 11 6.2.1. Distributed State Space Manipulation 11 6.2.2. Distributed Code Generation for LNT 11 6.2.3. Distributed Resolution of Boolean Equation Systems 11 6.2.4. Stability of Communicating Systems 12 6.2.5. Debugging of Concurrent Systems 12 6.3. Timed, Probabilistic, and Stochastic Extensions 12 6.4. Component-Based Architectures for On-the-Fly Verification 13 6.4.1. -

Experience Report Swiss Ada Event 2017 White Elephant Gmbh
Astronomical Ada Experience Report Swiss Ada Event 2017 White Elephant GmbH Ada Event 2017 - Astronomicial Ada White Elephant GmbH 1 Experience report on the problems we encountered geng a program wriCen enDrely in Ada to work on three popular PC operang systems: • Windows (WinXp and later) • Linux (Ubuntu Tahr) • OSX (Sierra) Ada Event 2017 - Astronomicial Ada White Elephant GmbH 2 Why Astronomical Ada? Because the program in quesDon controls astronomical telescopes Ada Event 2017 - Astronomicial Ada White Elephant GmbH 3 Background: Whatever you are watching will gradually driX out of view due to the rotaon of the • No Motor Earth When aligned with the Earth’s axis cancels out the driX due to the Earth’s rotaon. • One Motor But some objects move relave to the Earth : Eg. Planets, Comets & Satellites Needs a control system • Two Motors To know what to follow and how to follow it Ada Event 2017 - Astronomicial Ada White Elephant GmbH 4 Star Database What is in the night sky and where SkyTrack Motor Stellarium Control program Controller wriCen in Ada Open source PC A method to control Planetarium telescope motors GUI So it can be told where to go and what to follow Ada Event 2017 - Astronomicial Ada White Elephant GmbH 5 Ada Event 2017 - Astronomicial Ada White Elephant GmbH 6 Originally wriCen for MS-Windows Could it be ported to other operang systems? Majority of code and know-how is not operang system specific so why limit ourselves to Windows? Ada Event 2017 - Astronomicial Ada White Elephant GmbH 7 Should be easy • Tasks are part of the Ada language (doesn’t use OS specific libraries to create threads and protected objects) • Compilers for Windows, Linux and OSX • What the language doesn’t supply is mostly provided by packages that have been implemented on various plaorms. -

Understanding and Using Windows API Calls
09_bullen.qxd 1/7/05 10:00 AM Page 255 CHAPTER 9 Understanding and Using Windows API Calls In the Programming with the Windows API chapter of our Excel 2002 VBA Programmers Reference, we approached the subject of using Windows API calls by explaining how to locate the definitions for various functions on the MSDN Web site and translate those functions for use in VBA. The idea was to enable readers to browse through the API documentation and use anything of interest they found. In reality, extremely few people use Windows API calls in that manner; indeed, trying to include previously unexplored API calls in our Excel applications is very likely to result in a maintenance problem, because it’s doubtful that another developer will understand what we were trying to do. Instead, most of us go to Google and search the Web or the news- groups for the answer to a problem and find that the solution requires the use of API calls. (Searching Google for “Excel Windows API” results in more than 200,000 Web pages and 19,000 newsgroup posts.) We copy the solution into our application and hope it works, usually without really understanding what it does. This chapter shines a light on many of those solutions, explaining how they work, what they use the API calls for, and how they can be modified to better fit our applications. Along the way, we fill in some of the conceptual framework of common Windows API tech- niques and terminology. By the end of the chapter, you will be comfortable about including API calls in your applications, understand how they work, accept their use in the example applications we develop in this book and be able to modify them to suit your needs. -

Outside in Viewer for Activex Developer's Guide, Release 8.4.1 E12847-05
Oracle® Outside In Viewer for ActiveX Developer’s Guide Release 8.4.1 E12847-05 May 2013 Oracle Outside In Viewer for ActiveX Developer's Guide, Release 8.4.1 E12847-05 Copyright © 2013 Oracle and/or its affiliates. All rights reserved. Primary Author: Mike Manier This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). -

Creating Objects with Windows Script Component Files
G Creating Your Own Scriptable Objects Why Create Your Own Objects? Several chapters have been devoted to discussing just a few of the scriptable objects provided with Windows. In this appendix, I show you how to create objects of your own. Why would you want to do this? Well, remember what objects are about:They do a particular job while hiding the details of how the job is actually accomplished. Using this “divide-and-conquer” approach has three advantages: n Faster development and debugging n Simplification of the scripts and programs using objects n Code reusability Let’s look at these advantages one by one. First, when creating a new object, your immediate task is to make sure that the object does what it is supposed to do and that its methods and properties do the right thing.Your coding and debugging job is to write a small program to perform a particular, discrete task, which is easier than writ- ing and debugging a huge script with all the steps necessary to attack some larger job. Second, after your new object has been added to the Windows repertoire and you are writing a script to do some larger maintenance task, you can focus on this larger task without worrying about the details now handled by the object. Because objects are off “somewhere else,” your Windows Script Host (WSH) scripts are smaller and easier to write and debug. 2 Appendix G Creating Your Own Scriptable Objects Third, you can use a new object’s capabilities in many different scripts without repeat- ing the object’s code in each of them. -

The Microsoft Way: COM, OLE/Activex, COM+, and .NET CLR
8557 Chapter 15 p329-380 8/10/02 12:24 pm Page 329 CHAPTER FIFTEEN The Microsoft way: COM, OLE/ActiveX, COM+, and .NET CLR In a sense, Microsoft is taking the easiest route. Instead of proposing a global standard and hoping to port its own systems to it, it continually re-engineers its existing application and platform base. Component technology is intro- duced gradually, gaining leverage from previous successes, such as the original Visual Basic controls (VBX – non-object-oriented components!), object link- ing and embedding (OLE), OLE database connectivity (ODBC), ActiveX, Microsoft Transaction Server (MTS), or active server pages (ASP). In the standards arena, Microsoft focuses mostly on internet (IETF) and web (W3C) standards. More recently, some of its .NET specifications (CLI and C#) where adopted by ECMA – a European standards body with a fast track to ISO (ECMA, 2001a, 2001b). Microsoft is not trying to align its approaches with OMG or Java standards. While Java figured prominently in Microsoft’s strategy for a while, it has been relegated to a mere continuation of support of its older Visual J++ product – in part as a result of a settlement between Sun and Microsoft. In addition, under the name Visual J# .NET, Microsoft offers a migration tool to .NET, primarily targeting users of Visual J++ 6.0. As part of the .NET initiative, Microsoft is promoting language neutrality as a major tenet of CLR and aims to establish a new language, C#. C# adopts many of the successful traits of Java, while adding several distinctive features of its own (such as value types) and not supporting key Java features (such as inner classes).