HP Flexfabric Reference Architecture Guide Version 3.0 Applying HP Converged Infrastructure to Data Center Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hp Storageworks Disk System 2405
user’s guide hp StorageWorks disk system 2405 Edition E0902 . Notice Trademark Information © Hewlett-Packard Company, 2002. All rights Red Hat is a registered trademark of Red Hat Co. reserved. C.A. UniCenter TNG is a registered trademark of A6250-96020 Computer Associates International, Inc. Hewlett-Packard Company makes no warranty of Microsoft, Windows NT, and Windows 2000 are any kind with regard to this material, including, but registered trademarks of Microsoft Corporation not limited to, the implied warranties of HP, HP-UX are registered trademarks of Hewlett- merchantability and fitness for a particular purpose. Packard Company. Command View, Secure Hewlett-Packard shall not be liable for errors Manager, Business Copy, Auto Path, Smart Plug- contained herein or for incidental or consequential Ins are trademarks of Hewlett-Packard Company damages in connection with the furnishing, performance, or use of this material. Adobe and Acrobat are trademarks of Adobe Systems Inc. This document contains proprietary information, which is protected by copyright. No part of this Java and Java Virtual Machine are trademarks of document may be photocopied, reproduced, or Sun Microsystems Inc. translated into another language without the prior NetWare is a trademark of Novell, Inc. written consent of Hewlett-Packard. The information contained in this document is subject to AIX is a registered trademark of International change without notice. Business Machines, Inc. Tru64 and OpenVMS are registered trademarks of Format Conventions Compaq Corporation. -

High Performance Computing, Converged Infrastructure | IT Case
HP solutions help find difficult-to-reach oil and gas faster MicroSeismic, Inc. processes seismic data eight times faster, using solutions based on HP Converged Infrastructure technologies “The HP ProLiant DL160se servers greatly improved performance, processing jobs in just a few minutes that once took 20—about eight times faster.” Brian Gibbons, IT Manager, MicroSeismic, Inc. Objective Decrease processing cycles by deploying a more powerful processing solution for oil and gas field data Approach Turn to HP Elite Partner TSA for advice on how to speed processing with HP Converged Infrastructure-based technologies HP customer case study: IT improvements high-performance • 8x faster server management with computing; HP BladeSystem converged infrastructure • 50% reduction in power consumption with Industry: oil and gas HP BladeSystem • Business continuity solution with replication of data across two sites The sweet sound of oil and gas Business benefits To find “unconventional” hydrocarbons in the ground, • 8x faster processing of data for optimizing well you have to be able to listen—with very sensitive stimulation instrumentation—to what’s going on in the subsurface. • 20% reduction in TCO for total server count “Unconventional” or “hard-to-get” oil and gas is often due to virtualization found in shales. When these shales are stimulated by a hydrofrac job, tiny noises that indicate how • Increase in revenue due to improved productivity the rock is breaking up occur. The patterns of these • Faster growth with enhanced ability to service sounds tell geoscientists about the stimulation job’s more customers effectiveness, which enables the subsurface to release • $100,000 USD in equipment savings with the hydrocarbons. -

HP Storageworks MSL5026SL Tape Library (Graphite)
HP StorageWorks MSL5026SL Tape Library QuickSpecs (Graphite) Overview HP StorageWorks MSL5026SL Tape Library (Graphite) HP StorageWorks MSL5026SL Tape Library At A Glance The HP StorageWorks MSL5026SL Tape Library starts HP's mid-range family of tape automation products for the mainstream automation segment. It is the first to offer high availability features in this segment with hot plug drives. It offers 5.72 TB (2:1 compression) of storage, providing the highest capacity in its class in a compact 5U form factor, in tabletop or rackmount configurations. It is scalable up to seven units in a rackmount configuration to provide a maximum of 40.04 TB (2:1 compression) of data backup capacity DA - 11440 Worldwide QuickSpecs — Version 9 — 11/21/2003 Page 1 HP StorageWorks MSL5026SL Tape Library QuickSpecs (Graphite) Product Highlights HP StorageWorks The HP StorageWorks MSL5026SL Tape Library comes with 26 media slots MSL5026SL Tape (including one mail slot) and one or two HP StorageWorks SDLT 110/220 Tape Library (graphite) Drives (number of drives determined by SKU chosen). Models MSL5026SL, 0 DRV, RM Graphite Library 293472-B21 MSL5026SL, 1 DRV, SDLT 110/220, TT Graphite Library 302511-B21 MSL5026SL, 2 DRV, SDLT 110/220, TT Graphite Library 302511-B22 MSL5026SL, 1 DRV, SDLT 110/220, RM Graphite Library 302512-B21 MSL5026SL, 2 DRV, SDLT 110/220, RM Graphite Library 302512-B22 MSL5000 Field Upgrade SDLT 110/220 Drive, LVD 231823-B22 Each library installation will require, (1) library system, (1) geographically specific power cord, (1) l SCSI cable for each SDLT drive pair, and up to 26 pieces of SDLT media with Bar Code Labels for each MSL5026SL. -

HP Proliant DL380 Gen7 to Arcsight Gen7 Appliances.Pdf
Hewlett-Packard Company 11445 Compaq Center Drive West Mail Stop 050807 Houston, TX 77070, USA www.hp.com To: Certification Body July 16, 2013 From: Hewlett-Packard Company 11445 Compaq Center Drive West Houston, TX 77070 USA Declaration of Similarity (DoS) for Product Families We, the undersigned manufacturer, confirm hereby that the following appliances are identical in all electrical safety and electromagnetic aspects from the regulatory point of view. REGULATORY MODEL NO. MARKETING NAME (DESCRIPTION) HSTNS-5141 HP Proliant DL380 G7 Server HP StorageWorks X1800 G2 Network Storage System HP StorageWorks X1800 G2 4.8TB SAS Network Storage System HP StorageWorks X1800 G2 4.8TB SAS Network Storage System/S- Buy HP StorageWorks X3800 G2 Network Storage Gateway HP MAS V4.3 Virtualization Server HP MAS V4.2 SAN Storage Node HP MAS V4.2 SAN Ctrl Storage Node HP SMS XL Appliance HP StoreVirtual 4130 600GB SAS Storage HP StoreVirtual 4130 CN 600GB SAS Storage HP StoreVirtual 4330 450GB SAS Storage HP StoreVirtual 4330 CN 450GB SAS Storage HP StoreVirtual 4330 900GB SAS Storage HP StoreVirtual 4330 CN 900GB SAS Storage HP StoreVirtual 4330 1TB MDL SAS Storage HP StoreVirtual 4330 CN 1TB MDL SAS Storage HP StoreVirtual 4330 FC 900GB SAS Storage HP StoreVirtual 4330 FC CN 900GB SAS Storage HP ArcSight AE-7405 Server HP ArcSight AE-7405-HA Server HP ArcSight AE-7405-NP Server HP ArcSight AE-7410 Server HP ArcSight AE-7410-HA Server HP ArcSight AE-7410-NP Server HP ArcSight AE-7425 Server HP ArcSight AE-7425-HA Server Page 1 of 4 Hewlett-Packard -

Annual Report 2008 CEO Letter
Annual Report 2008 CEO letter Dear Fellow Stockholders, Fiscal 2008 was a strong year with some notable HP gained share in key segments, while continuing accomplishments. We have prepared HP to perform to show discipline in our pricing and promotions. well and are building a company that can deliver Software, services, notebooks, blades and storage meaningful value to our customers and stockholders each posted doubledigit revenue growth, for the long term. Looking ahead, it is important to highlighting both our marketleading technology and separate 2008 from 2009, and acknowledge the improved execution. Technology Services showed difficult economic landscape. While we have made particular strength with doubledigit growth in much progress, there is still much work to do. revenue for the year and improved profitability. 2008—Solid Progress and Performance in a Tough The EDS Acquisition—Disciplined Execution of a Environment Multiyear Strategy With the acquisition of Electronic Data Systems In August, HP completed its acquisition of EDS, a Corporation (EDS), we continued implementing a global technology services, outsourcing and multiyear strategy to create the world’s leading consulting leader, for a purchase price of $13 technology company. Additionally, we made solid billion. The EDS integration is at or ahead of the progress on a number of core initiatives, including operational plans we announced in September, and the substantial completion of phase one of HP’s customer response to the acquisition remains very information technology transformation. positive. Fiscal 2008 was also a difficult year, during which The addition of EDS further expands HP’s economic conditions deteriorated. -

HP Disaster Recovery Solutions with Vmware Vsphere 4 Rethink Your Approach to Disaster Recovery Solution Brief
HP Disaster Recovery Solutions with VMware vSphere 4 Rethink your approach to disaster recovery Solution brief Minimize risk as you keep your mind that comes from knowing your business will keep business running running in the event of a disaster. This comprehensive solution has three main components: Enterprises such as yours depend on rapidly evolving • HP StorageWorks SAN solutions with data technology to keep business operations connected, replication software drive revenue, and support customer demands. Yet • VMware vSphere from HP many organizations’ business continuity and disaster recovery plans are outdated and rigid. As your • VMware vCenter Site Recovery Manager from HP organization deals with constant changes—such HP StorageWorks SAN solutions as operational growth, expansion from mergers or HP offers a range of efficient HP StorageWorks acquisitions, new business processes, and shifting SAN storage solutions that properly support the personnel—your IT infrastructure might not be in a advanced requirements of virtualized environments. position to recover from a disaster. If that’s the case, The comprehensive suite of replication software the entire enterprise may be at risk—and it’s probably from HP lets you protect your valuable data by time to focus on this issue. replicating between HP StorageWorks SAN systems. The trouble is that traditional disaster recovery It also provides ease of management, and efficient solutions are often costly and complex. Even if storage and network resource utilization. HP array- you double your server and storage (and cost) for based replication software is fully integrated and protected applications, the expansion still might not certified with VMware through HP Storage Replication meet your recovery objectives. -

Quickspecs Kits Overview
RETIRED: Retired products sold prior to the November 1, 2015 separation of Hewlett-Packard Company into Hewlett Packard Enterprise Company and HP Inc. may have older product names and model numbers that differ from current models. HP StorageWorks 4400 Enterprise Virtual Array Starter QuickSpecs Kits Overview NOTE: The information in this QuickSpec can now be found in 12893, HP StorageWorks 4400 Enterprise Virtual Array. The HP StorageWorks 4400 Enterprise Virtual Array Starter Kits offer midsize customers with limited storage administration resources, an affordable single part number package with enterprise-class array functionality that's simple to order, simple to deploy, and simple to manage. Designed to reduce the complexity and total cost of ownership of traditional arrays, the EVA4400 is ideal for customers who are looking for a reliable, available, and cost effective storage solution. EVA4400 Starter Kits include disk drives and all necessary accessories as part of the package. The EVA4400 delivers all the business benefits of virtualization such as ease of management, superior capacity utilization, and self- tuning performance that have made the EVA product family one of best selling arrays in its class. The EVA4400 provides broad operating system support and is built on the EVA4100/6100/8100 architecture with dual-redundant design and offering 99.999% availability. Plus, it supports the robust local and remote replication capabilities of Business Copy and Continuous Access EVA allowing customers to configure for disaster tolerance and the ability to easily keep applications on-line during backup and restore. The EVA4400 delivers real value to customers with cost savings that include easy set up, installation and configuration, and self- repair capabilities. -

Solutions to Meet Your PCI Compliance Needs
Solutions to Meet Your PCI Compliance Needs A whitepaper prepared by Coalfire Systems and HP 1 | P a g e Table of Contents Executive Summary..................................................................................................................................... 3 The Payment Card Industry Data Security Standard ................................................................................... 3 PCI SSC Virtualization and Cloud Guidance ................................................................................................. 4 HP – Providing Software to Meet PCI Compliance Needs ........................................................................... 5 Identified HP Solutions ............................................................................................................................... 6 HP Solutions Mapped to PCI Controls ......................................................................................................... 6 Conclusion ................................................................................................................................................ 10 Appendices ............................................................................................................................................... 11 Secure Card Information Storage .............................................................................................................. 11 Secure Card Information Storage ............................................................................................................. -

Smartzone 7.1 Device Catalog
Number of Rack Description Vendor Name Model Number Part Number Units 3com 8C 3com 8C 1 Alcatel 3600 Mainstreet 23 Alcatel 3600 Mainstreet 23_ 11 Alcatel Omnistack-24 Alcatel Sistemas de Informacion 1 APC ACF002 APC ACF002 2 APC AP7900 Horizontal PDU APC AP7900 1 APC AP7901 Horizontal PDU APC AP7901 1 APC AP7902 Horizontal PDU APC AP7902 2 APC AP7911A Horizontal PDU APC AP7911A 2 APC AP7920 Horizontal PDU APC AP7920 1 APC AP7921 Horizontal PDU APC AP8921 1 APC AP7930 Vertical PDU APC AP7930 36 APC AP7931 Vertical PDU APC AP7931 28 APC AP7932 Vertical PDU APC AP7932 40 APC AP7940 Vertical PDU APC AP7940 36 APC AP7960 Vertical PDU APC AP7960 37 APC AP7968 Vertical PDU APC AP7968 40 APC AP7990 Vertical PDU APC AP7990 37 APC AP7998 Vertical PDU APC AP7998 40 APC AP8941 Vertical PDU APC AP8941 42 APC AP8958 Vertical PDU APC AP8958 23 APC AP8958NA3 Vertical PDU APC AP8958NA3 23 APC AP8959 Vertical PDU APC AP8959 40 APC AP8959NA3 Vertical PDU APC AP8959NA3 40 APC AP8961 Vertical PDU APC AP8961 40 APC AP8965 Vertical PDU APC AP8965 40 APC AP8981 Vertical PDU APC AP8981 41 APC PDU APC 1 APC PDU Environmentals APC 1 Apex El 40DT Apex El_40DT 1 Apple iPad Apple 0 Apple Xserve Raid array Apple Xserve Raid array 3 Avaya G350 Avaya G350 3 Avaya IP Office 406 Avaya 2 Avaya IP Office 412 Avaya 2 Avaya IP Office 500 Avaya 2 Avaya IP Office 500 V2 Avaya 2 Avaya P133G2 Avaya P133G2 2 Avaya S3210R Avaya S3210R 4 Number of Rack Description Vendor Name Model Number Part Number Units Avaya S8500C Avaya S8500C 1 Avaya S8720 Avaya S8720 2 Nortel 8610 Avaya (Rapid -

HP Innovation for the Financial Sector
The HP Financial Advisor HP innovation for the financial sector What’s Inside In the News . 2 Letter from the Editor . 2 EDS Merger . 4 HP CEO View ot IT . 6 Reduce Costs . 7 Greening the Data Center . 7 Transformation and Virtualization . 14 Mitigate Risk . 26 Security, Operations and Governance . 26 Revenue Growth . 34 Business Intelligence . 41 Payments . 43 Drew Caola Editor in Chief David Keith Contributing Editor Betsy Walton Contributing Editor Letter from the Editor Drew Caola, VP of Sales and General Manager, Financial Services Industry Strategic Accounts, is responsible for HP’s strategic accounts in financial services. Drew has been with HP since 1984, in a variety of services and sales manage - ment positions. Before joining HP, he worked for Arthur Andersen & Company. Dear Reader, We’ve certainly witnessed some interesting events recently. Congressional rescue plans and market volatality are adding to the unrest in our country. On top of all the upheaval, chief information officers (CIOs) at financial services firms still need to focus on improving return on investment (ROI), mitigating risk, improving performance, increasing agility, and facilitating regulatory compli - ance—all of which will involve the effective use of information technology. HP is a leading provider of Many financial services companies are undergoing significant shifts in revenue sources, particularly in the capital infrastructure products, solu - markets and consumer banking areas. They need the right information to better understand the needs of customers and markets so they can cross-sell products and services. And of course everyone is trying to figure out how to drive higher tions and services for the quality and greater profits by more effectively automating processes. -

HP Annual Report 2007
Annual Report 2007 Forward-looking Statements This document contains forward-looking statements that involve risks, uncertainties and assumptions. If such risks or uncertainties materialize or such assumptions prove incorrect, the results of HP and its consolidated subsidiaries could differ materially from those expressed or implied by such forward-looking statements and assumptions. All statements other than statements of historical fact are statements that could be deemed forward-looking statements, including but not limited to any statements of the plans, strategies and objectives of management for future operations; any statements concerning expected development, performance, market share or demand relating to HP’s products and services; any statements regarding anticipated operational and financial results, including the execution of cost reduction programs; any statements including estimates regarding market size or growth; any statements regarding future economic conditions or performance; any statements of expectation or belief; and any statements of assumptions underlying any of the foregoing. Risks, uncertainties and assumptions include the execution and performance of contracts by HP and its customers, suppliers and partners; the achievement of expected results; expectations and assumptions relating to the execution and timing of cost reduction programs; and other risks that are described in HP’s filings with the Securities and Exchange Commission, including but not limited to HP’s Annual Report on Form 10 K for the fiscal year ended October 31, 2007, which is included as part of this document. HP assumes no obligation and does not intend to update these forward-looking statements. CEO Letter Dear Fellow Stockholders: If one word can best describe HP’s performance in fiscal 2007, it is growth. -
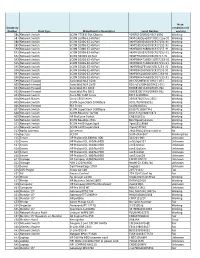
586 Network Switch 3COM 7758 8-Slot Chassis YCWF610000002
Note: Inventory condition or if Number Item Type Make/Brand or Description Serial Number working 586 Network Switch 3COM 7758 8-Slot Chassis YCWF610000002/3C16896 Working 587 Network Switch 3COM 5500G-EI 48 Port 9KMF5XD9E4300/ 3CR17255-91 Working 588 Network Switch 3COM 5500G-EI 24 Port 9KMF5XD9E4300/3CR17254-91 Working 589 Network Switch 3COM 5500G-EI 48 Port 9KMF5XD9E4200/3CR17255-91 Working 590 Network Switch 3COM 5500G-EI 48 Port 9KMF86K396B00/3CR17255-91 Working 591 Network Switch 3COM 5500G-EI 48 Port 9KMF63DAE9200/3CR17253-91 Working 592 Network Switch 3COM 5500EI 28 Port 9KWF9TLD0C1C0/3CR1717-91 Working 593 Network Switch 3COM 5500G-EI 48 Port 9KMF8KK473680/ 3CR17253-91 Working 594 Network Switch 3COM 5500G-EI 48 Port 9KMF8KK474D00/3CR17253-91 Working 595 Network Switch 3COM 5500G-EI 48 Port 9KMF85K2FE400/3CR17253-91 Working 596 Network Switch 3COM 5500G-EI 48 Port 9KMF89K3KFD00/3CR17253-91 Working 597 Network Switch 3COM 5500G-EI 48 Port 9KMF8FK400500/3CR17253-91 Working 598 Network Switch 3COM 5500G-EI 48 Port 9KMF8KK474A80/3CR17253-91 Working 599 Network Firewall SonicWall NSA 3500 0017C598F81C/ 1RK21-071 Working 600 Network Firewall SonicWall NSA 3500 0017cC599B438/1RK21-071 Working 601 Network Firewall SonicWall Pro 3060 0006B10D16A0/1RK09-032 Working 602 Network Firewall SonicWall Pro 3061 0006B10D1698/1RK09-032 Working 603 Network Switch Cisco ME 3400 Series F0C13220V0G6 Working 604 Network Router Cisco 2500 Series 25998784/Cisco 2501 Working 605 Network Switch 3COM SuperStack 1000Base 0101/7LNV055332 Working 606 Network