Second Stage Sampling for Conflict Areas: Methods and Implications Kristen Himelein, Stephanie Eckman, Siobhan Murray and Johannes Bauer 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lesson 3: Sampling Plan 1. Introduction to Quantitative Sampling Sampling: Definition
Quantitative approaches Quantitative approaches Plan Lesson 3: Sampling 1. Introduction to quantitative sampling 2. Sampling error and sampling bias 3. Response rate 4. Types of "probability samples" 5. The size of the sample 6. Types of "non-probability samples" 1 2 Quantitative approaches Quantitative approaches 1. Introduction to quantitative sampling Sampling: Definition Sampling = choosing the unities (e.g. individuals, famililies, countries, texts, activities) to be investigated 3 4 Quantitative approaches Quantitative approaches Sampling: quantitative and qualitative Population and Sample "First, the term "sampling" is problematic for qualitative research, because it implies the purpose of "representing" the population sampled. Population Quantitative methods texts typically recognize only two main types of sampling: probability sampling (such as random sampling) and Sample convenience sampling." (...) any nonprobability sampling strategy is seen as "convenience sampling" and is strongly discouraged." IIIIIIIIIIIIIIII Sampling This view ignores the fact that, in qualitative research, the typical way of IIIIIIIIIIIIIIII IIIII selecting settings and individuals is neither probability sampling nor IIIII convenience sampling." IIIIIIIIIIIIIIII IIIIIIIIIIIIIIII It falls into a third category, which I will call purposeful selection; other (= «!Miniature population!») terms are purposeful sampling and criterion-based selection." IIIIIIIIIIIIIIII This is a strategy in which particular settings, persons, or activieties are selected deliberately in order to provide information that can't be gotten as well from other choices." Maxwell , Joseph A. , Qualitative research design..., 2005 , 88 5 6 Quantitative approaches Quantitative approaches Population, Sample, Sampling frame Representative sample, probability sample Population = ensemble of unities from which the sample is Representative sample = Sample that reflects the population taken in a reliable way: the sample is a «!miniature population!» Sample = part of the population that is chosen for investigation. -

Chapter 3: Simple Random Sampling and Systematic Sampling
Chapter 3: Simple Random Sampling and Systematic Sampling Simple random sampling and systematic sampling provide the foundation for almost all of the more complex sampling designs that are based on probability sampling. They are also usually the easiest designs to implement. These two designs highlight a trade-off inherent in all sampling designs: do we select sample units at random to minimize the risk of introducing biases into the sample or do we select sample units systematically to ensure that sample units are well- distributed throughout the population? Both designs involve selecting n sample units from the N units in the population and can be implemented with or without replacement. Simple Random Sampling When the population of interest is relatively homogeneous then simple random sampling works well, which means it provides estimates that are unbiased and have high precision. When little is known about a population in advance, such as in a pilot study, simple random sampling is a common design choice. Advantages: • Easy to implement • Requires little advance knowledge about the target population Disadvantages: • Imprecise relative to other designs if the population is heterogeneous • More expensive to implement than other designs if entities are clumped and the cost to travel among units is appreciable How it is implemented: • Select n sample units at random from N available in the population All units within the population must have the same probability of being selected, therefore each and every sample of size n drawn from the population has an equal chance of being selected. There are many strategies available for selecting a random sample. -

R(Y NONRESPONSE in SURVEY RESEARCH Proceedings of the Eighth International Workshop on Household Survey Nonresponse 24-26 September 1997
ZUMA Zentrum für Umfragen, Melhoden und Analysen No. 4 r(y NONRESPONSE IN SURVEY RESEARCH Proceedings of the Eighth International Workshop on Household Survey Nonresponse 24-26 September 1997 Edited by Achim Koch and Rolf Porst Copyright O 1998 by ZUMA, Mannheini, Gerinany All rights reserved. No part of tliis book rnay be reproduced or utilized in any form or by aiiy means, electronic or mechanical, including photocopying, recording, or by any inforniation Storage and retrieval System, without permission in writing froni the publisher. Editors: Achim Koch and Rolf Porst Publisher: Zentrum für Umfragen, Methoden und Analysen (ZUMA) ZUMA is a member of the Gesellschaft Sozialwissenschaftlicher Infrastruktureinrichtungen e.V. (GESIS) ZUMA Board Chair: Prof. Dr. Max Kaase Dii-ector: Prof. Dr. Peter Ph. Mohlcr P.O. Box 12 21 55 D - 68072.-Mannheim Germany Phone: +49-62 1- 1246-0 Fax: +49-62 1- 1246- 100 Internet: http://www.social-science-gesis.de/ Printed by Druck & Kopie hanel, Mannheim ISBN 3-924220-15-8 Contents Preface and Acknowledgements Current Issues in Household Survey Nonresponse at Statistics Canada Larry Swin und David Dolson Assessment of Efforts to Reduce Nonresponse Bias: 1996 Survey of Income and Program Participation (SIPP) Preston. Jay Waite, Vicki J. Huggi~isund Stephen 1'. Mnck Tlie Impact of Nonresponse on the Unemployment Rate in the Current Population Survey (CPS) Ciyde Tucker arzd Brian A. Harris-Kojetin An Evaluation of Unit Nonresponse Bias in the Italian Households Budget Survey Claudio Ceccarelli, Giuliana Coccia and Fahio Crescetzzi Nonresponse in the 1996 Income Survey (Supplement to the Microcensus) Eva Huvasi anci Acfhnz Marron The Stability ol' Nonresponse Rates According to Socio-Dernographic Categories Metku Znletel anci Vasju Vehovar Understanding Household Survey Nonresponse Through Geo-demographic Coding Schemes Jolin King Response Distributions when TDE is lntroduced Hikan L. -

Lecture 8: Sampling Methods
Lecture 8: Sampling Methods Donglei Du ([email protected]) Faculty of Business Administration, University of New Brunswick, NB Canada Fredericton E3B 9Y2 Donglei Du (UNB) ADM 2623: Business Statistics 1 / 30 Table of contents 1 Sampling Methods Why Sampling Probability vs non-probability sampling methods Sampling with replacement vs without replacement Random Sampling Methods 2 Simple random sampling with and without replacement Simple random sampling without replacement Simple random sampling with replacement 3 Sampling error vs non-sampling error 4 Sampling distribution of sample statistic Histogram of the sample mean under SRR 5 Distribution of the sample mean under SRR: The central limit theorem Donglei Du (UNB) ADM 2623: Business Statistics 2 / 30 Layout 1 Sampling Methods Why Sampling Probability vs non-probability sampling methods Sampling with replacement vs without replacement Random Sampling Methods 2 Simple random sampling with and without replacement Simple random sampling without replacement Simple random sampling with replacement 3 Sampling error vs non-sampling error 4 Sampling distribution of sample statistic Histogram of the sample mean under SRR 5 Distribution of the sample mean under SRR: The central limit theorem Donglei Du (UNB) ADM 2623: Business Statistics 3 / 30 Why sampling? The physical impossibility of checking all items in the population, and, also, it would be too time-consuming The studying of all the items in a population would not be cost effective The sample results are usually adequate The destructive nature of certain tests Donglei Du (UNB) ADM 2623: Business Statistics 4 / 30 Sampling Methods Probability Sampling: Each data unit in the population has a known likelihood of being included in the sample. -

Survey Design
1 Survey Design Target population: The scope of ACES is to capture investment by all domestic, private, non-farm businesses, including agricultural non-farm business and businesses without employees. Investment made after applying for an Employer Identification Number (EIN) from the Internal Revenue Service (IRS) but before having any payroll or receipts is also included. Major exclusions are foreign operations of U.S. businesses, businesses in the U.S. territories, government operations (including the U.S. Postal Service), agricultural production companies and private households. Sampling frame: ACES collects information at the company level. The records of how the company invests are maintained at the headquarters level, and not at the location of each physical operating location. Companies may elect to have divisions within the company report, but the sampling unit and tabulation unit will be the company. A company’s importance to the survey depends on their employment, payroll, and their business activity. The greater the number of employees or the larger the payroll, the more likely, in general, a company is to be selected in the sample. The influence that the amount of payroll has on the likelihood of selection is adjusted by the business activity such that two companies with similar payroll but in different business activities will not have the same likelihood of selection. This is done to improve the quality of the estimates from any particular ACES specific industry code for business activities. Estimates are from two distinct samples from distinct frames. The first frame collects in-scope companies with employees. Companies sampled from this frame will receive an ACE-1 form, and the frame and sample are the ACE-1 frame and sample, respectively. -

STANDARDS and GUIDELINES for STATISTICAL SURVEYS September 2006
OFFICE OF MANAGEMENT AND BUDGET STANDARDS AND GUIDELINES FOR STATISTICAL SURVEYS September 2006 Table of Contents LIST OF STANDARDS FOR STATISTICAL SURVEYS ....................................................... i INTRODUCTION......................................................................................................................... 1 SECTION 1 DEVELOPMENT OF CONCEPTS, METHODS, AND DESIGN .................. 5 Section 1.1 Survey Planning..................................................................................................... 5 Section 1.2 Survey Design........................................................................................................ 7 Section 1.3 Survey Response Rates.......................................................................................... 8 Section 1.4 Pretesting Survey Systems..................................................................................... 9 SECTION 2 COLLECTION OF DATA................................................................................... 9 Section 2.1 Developing Sampling Frames................................................................................ 9 Section 2.2 Required Notifications to Potential Survey Respondents.................................... 10 Section 2.3 Data Collection Methodology.............................................................................. 11 SECTION 3 PROCESSING AND EDITING OF DATA...................................................... 13 Section 3.1 Data Editing ........................................................................................................ -

Unit 16: Census and Sampling
Unit 16: Census and Sampling Summary of Video There are some questions for which an experiment can’t help us find the answer. For example, suppose we wanted to know what percentage of Americans smoke cigarettes, or what per- centage of supermarket chicken is contaminated with salmonella bacteria. There is no experi- ment that can be done to answer these types of questions. We could test every chicken on the market, or ask every person if they smoke. This is a census, a count of each and every item in a population. It seems like a census would be a straightforward way to get the most accurate, thorough information. But taking an accurate census is more difficult than you might think. The U.S. Constitution requires a census of the U.S population every ten years. In 2010, more than 308 million Americans were counted. However, the Census Bureau knows that some people are not included in this count. Undercounting certain segments of the population is a problem that can affect the representation given to a certain region as well as the federal funds it receives. What is particularly problematic is that not all groups are undercounted at the same rate. For example, the 2010 census had a hard time trying to reach renters. The first step in the U.S. Census is mailing a questionnaire to every household in the country. In 2010 about three quarters of the questionnaires were returned before the deadline. A census taker visits those households that do not respond by mail, but still not everyone is reached. -

Ch7 Sampling Techniques
7 - 1 Chapter 7. Sampling Techniques Introduction to Sampling Distinguishing Between a Sample and a Population Simple Random Sampling Step 1. Defining the Population Step 2. Constructing a List Step 3. Drawing the Sample Step 4. Contacting Members of the Sample Stratified Random Sampling Convenience Sampling Quota Sampling Thinking Critically About Everyday Information Sample Size Sampling Error Evaluating Information From Samples Case Analysis General Summary Detailed Summary Key Terms Review Questions/Exercises 7 - 2 Introduction to Sampling The way in which we select a sample of individuals to be research participants is critical. How we select participants (random sampling) will determine the population to which we may generalize our research findings. The procedure that we use for assigning participants to different treatment conditions (random assignment) will determine whether bias exists in our treatment groups (Are the groups equal on all known and unknown factors?). We address random sampling in this chapter; we will address random assignment later in the book. If we do a poor job at the sampling stage of the research process, the integrity of the entire project is at risk. If we are interested in the effect of TV violence on children, which children are we going to observe? Where do they come from? How many? How will they be selected? These are important questions. Each of the sampling techniques described in this chapter has advantages and disadvantages. Distinguishing Between a Sample and a Population Before describing sampling procedures, we need to define a few key terms. The term population means all members that meet a set of specifications or a specified criterion. -

METHOD GUIDE 3 Survey Sampling and Administration
METHOD GUIDE 3 Survey sampling and administration Alexandre Barbosa, Marcelo Pitta, Fabio Senne and Maria Eugênia Sózio Regional Center for Studies on the Development of the Information Society (Cetic.br), Brazil November 2016 1 Table of Contents Global Kids Online ......................................................................................................................... 3 Abstract .......................................................................................................................................... 4 Key issues ...................................................................................................................................... 5 Main approaches and identifying good practice ......................................................................... 7 Survey frame and sources of information .................................................................................................................... 8 Methods of data collection ................................................................................................................................................ 8 Choosing an appropriate method of data collection.......................................................................................................... 9 Sampling plan.................................................................................................................................................................. 11 Target population ....................................................................................................................................................... -

Sample Surveys Test Review SOLUTIONS/EXPLANATIONS – Multiple Choice Questions
Sample Surveys Test Review SOLUTIONS/EXPLANATIONS – Multiple Choice questions Correct answers are bolded. Explanations are in red. 1. Ann Landers, who wrote a daily advice column appearing in newspapers across the country, once asked her readers, “If you had to do it all over again, would you have children?” Of the more than 10,000 readers who responded, 70% said no. What does this show? (A) The survey is meaningless because of voluntary response bias. Explanation: Voluntary response bias is powerful – it means only people with strong opinions about the topic will respond. It will always give meaningless information for that reason, no matter what the “characteristics of her readers” include. (B) No meaningful conclusion is possible without knowing something more about the characteristics of her readers. (See above) (C) The survey would have been more meaningful if she had picked a random sample of the 10,000 readers who responded. This is nonsense. If she picks a random sample of the 10,000 people, these are the people who voluntarily responded. It then becomes a biased random sample and is still meaningless. (D) The survey would have been more meaningful if she had used a control group. Also nonsense. How do you have a control group with a voluntary survey? “Hey, you, please DON’T take this survey.” (E) This was a legitimate sample, randomly drawn from her readers and of sufficient size to allow the conclusion that most of her readers who are parents would have second thoughts about having children. NOT random, hello. 2. Which of the following are true statements? I. -

Interactive Lecture Notes 03-Sampling, Surveys and Gathering Useful Data
Author: Brenda Gunderson, Ph.D., 2015 License: Unless otherwise noted, this material is made available under the terms of the Creative Commons Attribution- NonCommercial-Share Alike 3.0 Unported License: http://creativecommons.org/licenses/by-nc-sa/3.0/ The University of Michigan Open.Michigan initiative has reviewed this material in accordance with U.S. Copyright Law and have tried to maximize your ability to use, share, and adapt it. The attribution key provides information about how you may share and adapt this material. Copyright holders of content included in this material should contact [email protected] with any questions, corrections, or clarification regarding the use of content. For more information about how to attribute these materials visit: http://open.umich.edu/education/about/terms-of-use. Some materials are used with permission from the copyright holders. You may need to obtain new permission to use those materials for other uses. This includes all content from: Attribution Key For more information see: http:://open.umich.edu/wiki/AttributionPolicy Content the copyright holder, author, or law permits you to use, share and adapt: Creative Commons Attribution-NonCommercial-Share Alike License Public Domain – Self Dedicated: Works that a copyright holder has dedicated to the public domain. Make Your Own Assessment Content Open.Michigan believes can be used, shared, and adapted because it is ineligible for copyright. Public Domain – Ineligible. Works that are ineligible for copyright protection in the U.S. (17 USC §102(b)) *laws in your jurisdiction may differ. Content Open.Michigan has used under a Fair Use determination Fair Use: Use of works that is determined to be Fair consistent with the U.S. -
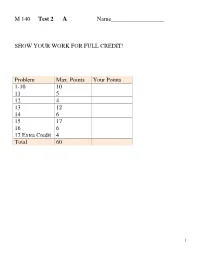
M 140 Test 2 a Name___SHOW YOUR WORK for FULL CREDIT! Problem Max. Points Your Points 1-10 10 11 5 12 4 13 1
M 140 Test 2 A Name__________________ SHOW YOUR WORK FOR FULL CREDIT! Problem Max. Points Your Points 1-10 10 11 5 12 4 13 12 14 6 15 17 16 6 17 Extra Credit 4 Total 60 1 Multiple Choice Questions (1 point each) 1. A new headache remedy was given to a group of 25 subjects who had headaches. Four hours after taking the new remedy, 20 of the subjects reported that their headaches had disappeared. From this information you conclude: a. that the remedy is effective for the treatment of headaches. b. nothing, because the sample size is too small. c. nothing, because there is no control group for comparison. d. that the new treatment is better than aspirin. e. that the remedy is not effective for the treatment of headaches. 2. In the Faculty of Science of a university there are ten departments. Two faculty members are selected at random from each department. The sample of twenty faculty members selected in this way is called a: a. Simple random sample. b. Systematic sample. c. Stratified random sample. d. Voluntary response sample. e. Multistage sample. 3. A simple random sample of 1200 adult Americans is selected and each person is asked the following question. "In light of the huge national deficit, should the government at this time spend additional money to establish a national system of health insurance?" Only 39% of those responding answered yes. This survey a. is reasonably accurate since it used a large, simple random sample. b. probably overstates the percentage of people that favor a system of national health insurance.