Generation of an Architecture View for Web Applications Using a Bayesian Network Classifier Juan-Carlos Castrejon-Castillo, Rafael Lozano, Genoveva Vargas-Solar
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spring Roo - Reference Documentation
Spring Roo - Reference Documentation DISID CORPORATION S.L. Table of Contents Getting started . 1 1. Overview . 2 2. What’s new in Spring Roo 2.0 . 3 Improved extensibility . 3 No backward compatibility . 3 Usability improvements . 3 Centered in Spring technologies . 3 Application architecture . 4 Domain model . 4 View layer . 4 3. Requirements . 6 4. Install Spring Roo . 7 Using Spring Roo . 9 5. The Roo shell . 10 6. Impatient beginners . 12 7. Create your Spring Boot application . 13 8. Configure the project settings . 14 9. Setup the persistence engine . 15 10. The domain model . 16 JPA entities . 16 DTOs . 20 11. The data access layer . 21 Spring Data repositories . 21 Default queries . 21 12. The service layer . 22 Service API and Impl . 22 13. The view layer . 23 Thymeleaf view engine . 23 Spring MVC Controllers . 23 Spring Webflow . 25 14. The integration layer . 26 REST API . 26 WS API . 26 Email . .. -

What's New in GWT?
What’s New in GWT? David Chandler Google Web Toolkit Team Atlanta, GA USA [email protected] 1 Agenda Why rich Web apps with GWT? GWT Quickstart Developer tools GWT performance for your users Building with GWT 2.12 2 GWT in 10 sec Asynchronous JavaScript And XML++ 3 GWT in 60 sec Open source Java to JavaScript compiler Lets you write rich Web apps in Java Cross-browser just works (FireFox, Chrome, Safari, IE 6+) Produces small, fast JavaScript Easy (and efficient) RPC Great for large projects / teams 4 Browser-Proof Your JS Code IE Firefox Safari Chrome Opera 5 5 No plugins required Silverlight VML Flash 6 6 Can you find the bug? Hint: JavaScript is a dynamic language 7 7 Catch errors at compile time Java is a static language 8 8 Completion, refactoring... 9 9 Eating our own dogfood += AdSense, Maps, Docs, Groups... 10 10 Demos Booked In Typing race 11 Rich ecosystem www.gwtmarketplace.com 12 More ecosystem Util: GIN, gwt-dnd, gwt-fx, gwt-comet, ... Widgets: EXT-GWT, Smart-GWT, ... Frameworks: Vaadin! 13 4+ years in review May 2006 GWT 1.0 Launch at JavaOne … … Aug 2008 GWT 1.5 Java 5 language support Apr 2009 GWT 1.7 Dedicated IE8 support Fall 2009 GWT 2.0 UIBinder (XML template), runAsync() Oct 2010 GWT 2.1 MVP, RequestFactory, Spring Roo 14 14 GWT delivers... Productivity for developers - Language, IDEs, tools, libraries - People, ecosystem Performance for users - 'Perfect' caching - Whole program optimization 15 15 Developing with GWT Develop - Google Plugin for Eclipse, GWT Designer, STS / Roo Debug - In Eclipse with dev mode -

Great Lakes Software Symposium Westin Chicago Northwest November 11 - 13, 2011
Great Lakes Software Symposium Westin Chicago Northwest November 11 - 13, 2011 Fri, Nov. 11, 2011 Ballroom 3-4 Ballroom 1-2 Gallery Chambers Stanford Trafalgar 12:00 - 1:00 PM REGISTRATION 1:00 - 1:15 PM WELCOME 1:15 - 2:45 PM What's new in Spring Resource-Oriented Programming HTML5 Concurrency without Busy Java Introduction to Lean-Agile Craig Walls Architectures : REST I Tim Berglund pain in pure Java Developer's Software Development Brian Sletten Venkat Subramaniam Guide to Java 7 Paul Rayner Ted Neward 2:45 - 3:15 PM BREAK 3:15 - 4:45 PM NoXML: Spring Resource-Oriented NoSQL Smackdown! Collections for Concurrency Busy Java Measure for Measure for XML-Haters Architectures : REST II Tim Berglund Venkat Subramaniam Developer's Guide – Lean Principles Craig Walls Brian Sletten to Multi-Paradigm Design for Effective Metrics Ted Neward and Motivation Paul Rayner 4:45 - 5:00 PM BREAK 5:00 - 6:30 PM Introducing Spring Strategic Design Cassandra: Radical Towards a Humane Busy Java Resource-Oriented Roo: From Zero Using DDD NoSQL Scalability Interface—Aesthetics Developer's Architectures : to Working Spring Paul Rayner Tim Berglund and Usability Guide to Guava RDF/SPARQL Application in Record Time Venkat Subramaniam Ted Neward Brian Sletten Craig Walls 6:30 - 7:15 PM DINNER 7:15 - 8:00 PM Keynote: by Venkat Subramaniam Great Lakes Software Symposium Westin Chicago Northwest November 11 - 13, 2011 Sat, Nov. 12, 2011 Ballroom 3-4 Ballroom 1-2 Gallery Chambers Stanford Trafalgar 8:00 - 9:00 AM BREAKFAST 9:00 - 10:30 -

Programming Technologies for the Development of Web-Based Platform for Digital Psychological Tools
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 9, No. 8, 2018 Programming Technologies for the Development of Web-Based Platform for Digital Psychological Tools Evgeny Nikulchev1, Dmitry Ilin2 Pavel Kolyasnikov3 Ilya Zakharov5, Sergey Malykh6 4 MIREA – Russian Technological Vladimir Belov Psychological Institute of Russian University & Russian Academy Russian Academy Science Academy of Education Science, Moscow, Russia Moscow, Russia Moscow, Russia Abstract—The choice of the tools and programming In addition, large accumulated data sets can become the technologies for information systems creation is relevant. For basis for machine learning mechanisms and other approaches every projected system, it is necessary to define a number of using artificial intelligence. Accumulation of data from criteria for development environment, used libraries and population studies into a single system can allow a technologies. The paper describes the choice of technological breakthrough in the development of systems for automated solutions using the example of the developed web-based platform intellectual analysis of behavior data. of the Russian Academy of Education. This platform is used to provide information support for the activities of psychologists in The issue of selecting methodological tools for online and their research (including population and longitudinal offline research includes several items. researches). There are following system features: large scale and significant amount of developing time that needs implementation First, any selection presupposes the existence of generally and ensuring the guaranteed computing reliability of a wide well-defined criteria, on the basis of which a decision can be range of digital tools used in psychological research; ensuring made to include or not to include techniques in the final functioning in different environments when conducting mass toolkit. -

Play Framework One Web Framework to Rule Them All
Play Framework One Web Framework to rule them all Felix Müller Agenda Yet another web framework? Introduction for Java devs Demo Summary Yet another web framework? Yet another web framework? Why do we need another web framework? Existing solutions: Servlets, Ruby on Rails, Grails, Django, node.js Yet another web framework? Threaded Evented 1 thread per 1 thread per cpu request core threads may block threads shall never during request block processing Yet another web framework? Threaded Evented Servlets Node.js Ruby on Rails Play Framework Grails Django Yet another web framework? Play is completely asynchronous horizontally scalable out of the box and a lot other goodies... Introduction for Java devs Play Framework MVC pattern Scala and Java API asset compiler for CoffeeScript and LESS + Google Closure Compiler + require.js Play Console play new <appName> play compile|test|run|debug play ~compile|test|run Application structure app directory contains source code, templates and assets standard packages based on MVC: app/controllers app/models app/views Application structure public directory is default for assets as css and javascript files public/stylesheets public/javascripts public/images served directly by web server Routes configuration contains url to controller mapping statically typed pattern: <HTTP method> <url> <controller> Controllers import play.mvc.*; public class Application extends Controller { public static Result index() { return ok("It works!"); } } Templates built-in Scala based template engine -

Applicazioni Web in Groovy E Java
Università degli Studi di Padova Applicazioni web in Groovy e Java Laurea Magistrale Laureando: Davide Costa Relatore: Prof. Giorgio Clemente Dipartimento di Ingegneria dell’Informazione Anno Accademico 2011-2012 Indice INTRODUZIONE ........................................................................................... 1 1 GROOVY ............................................................................................... 5 1.1 Introduzione a Groovy ................................................................................. 5 1.2 Groovy Ver 1.8 (stable).............................................................................. 10 1.3 Installare Groovy ........................................................................................ 14 1.3.1 Installazione da codice sorgente......................................................... 15 1.4 L’interprete Groovy e groovyConsole ....................................................... 16 1.5 Esempi ........................................................................................................ 17 2 NETBEANS .......................................................................................... 20 2.1 Introduzione a Netbeans ............................................................................. 20 2.2 Installare Netbeans 7.1 ............................................................................... 22 2.3 “Hello World!” in Netbeans ....................................................................... 23 3 ARCHITETTURA MVC ....................................................................... -
Play Framework Documentation
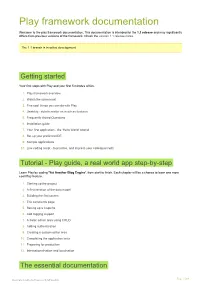
Play framework documentation Welcome to the play framework documentation. This documentation is intended for the 1.1 release and may significantly differs from previous versions of the framework. Check the version 1.1 release notes. The 1.1 branch is in active development. Getting started Your first steps with Play and your first 5 minutes of fun. 1. Play framework overview 2. Watch the screencast 3. Five cool things you can do with Play 4. Usability - details matter as much as features 5. Frequently Asked Questions 6. Installation guide 7. Your first application - the 'Hello World' tutorial 8. Set up your preferred IDE 9. Sample applications 10. Live coding script - to practice, and impress your colleagues with Tutorial - Play guide, a real world app step-by-step Learn Play by coding 'Yet Another Blog Engine', from start to finish. Each chapter will be a chance to learn one more cool Play feature. 1. Starting up the project 2. A first iteration of the data model 3. Building the first screen 4. The comments page 5. Setting up a Captcha 6. Add tagging support 7. A basic admin area using CRUD 8. Adding authentication 9. Creating a custom editor area 10. Completing the application tests 11. Preparing for production 12. Internationalisation and localisation The essential documentation Generated with playframework pdf module. Page 1/264 Everything you need to know about Play. 1. Main concepts i. The MVC application model ii. A request life cycle iii. Application layout & organization iv. Development lifecycle 2. HTTP routing i. The routes file syntax ii. Routes priority iii. -

Characters and Numbers A
Index ■Characters and Numbers by HTTP request type, 313–314 #{ SpEL statement } declaration, SpEL, 333 by method, 311–312 #{bean_name.order+1)} declaration, SpEL, overview, 310 327 @Required annotation, checking ${exception} variable, 330 properties with, 35 ${flowExecutionUrl} variable, 257 @Resource annotation, auto-wiring beans with ${newsfeed} placeholder, 381 all beans of compatible type, 45–46 ${resource(dir:'images',file:'grails_logo.pn g')} statement, 493 by name, 48–49 ${today} variable, 465 overview, 42 %s placeholder, 789 single bean of compatible type, 43–45 * notation, 373 by type with qualifiers, 46–48 * wildcard, Unix, 795 @Value annotation, assigning values in controller with, 331–333 ;%GRAILS_HOME%\bin value, PATH environment variable, 460 { } notation, 373 ? placeholder, 624 ~.domain.Customer package, 516 @Autowired annotation, auto-wiring 23505 error code, 629–631 beans with all beans of compatible type, 45–46 ■A by name, 48–49 a4j:outputPanel component, 294 overview, 42 AboutController class, 332 single bean of compatible type, 43–45 abstract attribute, 49, 51 by type with qualifiers, 46–48 AbstractAnnotationAwareTransactionalTe @PostConstruct annotation, 80–82 sts class, 566 @PreDestroy annotation, 80–82 AbstractAtomFeedView class, 385–386 @RequestMapping annotation, mapping AbstractController class, 298 requests with AbstractDependencyInjectionSpringConte by class, 312–313 xtTests class, 551–552, 555 985 ■ INDEX AbstractDom4jPayloadEndpoint class, AbstractTransactionalTestNGSpringConte 745, 747 xtTests class, 555, -

Marius Gligor Microservices Architect
Marius Gligor Microservices architect. Fluent in Scala, Java, Python, C, C++ , learning Haskell Working comfortable on Linux, Mac and Windows environments About me: Address: Sibiu, Romania, European Union LinkedIn: https://www.linkedin.com/in/marius-g-35a7165/ Nationality: Romanian GitHub: https://github.com/gmax-ws Mail: mailto :[email protected] Web: https://www.scalable-solutions.ro Mobile: +40 74 209 3069 References: https://www.scalable-solutions.ro/rec/mag_gcd_letter_of_recommendation_20141114.pdf Skype: marius.gligor Twitter: @GligorMarius I'm a Senior Software Engineer having more than 25 years great experience as programming language. For the beginning, I learned about Java programming Software Developer and Software Architect working in various projects. Immediately language then about the Microsoft .NET C# programming language. Finally, I decided after my graduation, as a Software System Engineer I designed a lot of products, that Java is the best choice for me. My first Java based projects were Desktop tools and OS patches for a wide range of machines, 8 bits microcomputers, Applications using the SWING framework and MySQL database. In the same time, minicomputers (PDP-11) and mainframes using mainly the assembly languages. In I've started to learn about the JEE and related technologies. From 2009 until today 1990 I have had for the first time an IBM PC on my hands. Using the x86 assembly I'm working mainly on JEE and Core Java applications. I'm specialized on the sever language, I designed small tools and viruses’ cleaners. Soon in 1992 the C and C++ side and Enterprise Information Systems (database) designing and implementing became my main programming languages for the next decays. -

Getting Started with Roo
Getting Started with Roo Getting Started with Roo Josh Long and Steve Mayzak Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Getting Started with Roo by Josh Long and Steve Mayzak Copyright © 2011 Josh Long and Steve Mayzak. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Editor: Mike Loukides Cover Designer: Karen Montgomery Production Editor: Jasmine Perez Interior Designer: David Futato Proofreader: O’Reilly Production Services Illustrator: Robert Romano Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Getting Started with Roo, the image of the common tree kangaroo, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. ISBN: 978-1-449-30790-5 [LSI] 1312551620 Table of Contents Preface ..................................................................... vii 1. Your First Intrepid Hops … err, Steps ..................................... -

Play for Java MEAP V2
MEAP Edition Manning Early Access Program Play for Java version 2 Copyright 2012 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. Please post comments or corrections to the Author Online forum: http://www.manning-sandbox.com/forum.jspa?forumID=811 Licensed to Yuri Delfino <[email protected]> brief contents PART I: INTRODUCTION AND FIRST STEPS 1. Introduction to Play 2 2. The parts of an application 3. A basic CRUD application PART II: CORE FUNCTIONALITY 4. An enterprise app, Play-style 5. Models and persistence 6. Controllers—handling HTTP requests 7. Handling user input 8. View templates—producing output 9. Security 10. Testing your applications 11. Deployment PART III: ADVANCE TOPICS 12. Client-side development and Play 13. SBT project management 14. Convenience libraries 15. Cloud integration ©Manning Publications Co. Please post comments or corrections to the Author Online forum: http://www.manning-sandbox.com/forum.jspa?forumID=811 Licensed to Yuri Delfino <[email protected]> 1 Introduction to1 Play 2 This chapter covers: What the Play framework is What high-productivity web frameworks are about Why Play supports both Java and Scala What a minimal Play application looks like Play isn’t really a Java web framework. Java’s involved, but that isn’t the whole story. The first version of Play may have been written in the Java language, but it also ignored the conventions of the Java platform, providing a fresh alternative to excessive enterprise architectures. Play was not based on Java Enterprise Edition APIs and made for Java developers. -

Play2sdg: Bridging the Gap Between Serving and Analytics in Scalable Web Applications
Play2SDG: Bridging the Gap between Serving and Analytics in Scalable Web Applications Panagiotis Garefalakis M.Res Thesis Presentation, 7 September 2015 Outline •Motivation •Challenges ➡Scalable web app design ➡Resource efficiency ➡Resource Isolation •In-memory Web Objects model ➡Play2SDG case study ➡Experimental Results •Conclusions •Future work 2 Motivation • Most modern web and mobile applications today offer highly personalised services generating large amounts of data • Tasks separated into offline (BE) and online (LC) based on the latency, computation and data freshness requirements • To train models and offer analytics, they use asynchronous offline computation, which leads to stale data being served to clients • To serve requests robustly and with low latency, applications cache data from the analytics layer • Applications deployed in large clusters, but with no collocation of tasks to avoid SLO violations • No data freshness guarantees and poor resource efficiency 3 Typical Web App • How does a typical scalable web application look like? • There is a strict decoupling of online and offline tasks • With the emerge of cloud computing, these applications are deployed on clusters with thousands of machines Cluster A Load Balancer Web Server Web Application Database Server HTTP Request HTTP Response Business Presentation Database Data Model Data Intensive Batch Processing Data Dashed Line: Offline Task Cluster B Trained Models 4 Challenges: Resource Efficiency • Most cloud facilities operate at very low utilisation, hurting both cost effectiveness and future scalability • Figure depicts a utilisation analysis for a production cluster at Twitter with thousands of servers, managed by Mesos over one month. The cluster mostly hosts user-centric services • The aggregate CPU utilisation is consistently below 20%, even though reservations reach up to 80% of total capacity Delimitrou, Christina, and Christos Kozyrakis.