Adapting Swarm Applications: a Systematic and Quantitative Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

English Rating System
User Guide This is a 「User Guide」 installed on the TV. The contents of this guide are subject to change without prior notice for quality improvement. ❐❐To❐view❐program❐information GP4 Displays information about the current program and/or current time, etc. enga 1 Move the pointer of the Magic remote control to the top of the TV screen. 2 Click the activated channel banner area. 3 The program details will be displayed at the bottom of the TV screen. ✎ Image shown may differ from your TV. Prev./Next Ch. Change Watch Thu. Current time PM❐4❐:❐28 PM❐4❐:❐43 UP DOWN Program name Detailed program information (for digital broadcast) ❐❐To❐set❐favorite❐channels GP4 enga SMART❐ ❐➾ Settings❐➙ CHANNEL❐➙ Channel❐Edit 1 Move to the desired channel on Wheel (OK) button. Channel is selected. 2 Press Set as Favorite. 3 Select the desired favorite channel group. 4 Select Enter. Favorite is set. ❐❐To❐use❐Favorite SMART❐ ❐➾❐Ch.❐List Channel list will appear. Select the desired preset favorite channel from Favorite List A to D. ❐❐To❐set❐Auto❐Tuning GP4 enga SMART❐ ❐➾❐Settings❐➙❐CHANNEL❐➙❐Auto❐Tuning Automatically tunes the channels. ✎ Channels are not registered properly unless the antenna/cable is connected correctly. ✎ Auto Tuning only sets channels that are currently broadcasting. ✎ If Lock System is turned on, a pop-up window will appear asking for password. ❐❐To❐set❐channels❐manually GP4 enga SMART❐ ❐➾❐Settings❐➙❐CHANNEL❐➙❐Manual❐Tuning Adjusts channels manually and saves the results. For digital broadcasting, signal strength, etc. can be checked. ❐❐To❐edit❐channels GP4 enga SMART❐ ❐➾❐Settings❐➙❐CHANNEL❐➙❐Channel❐Edit Edits the saved channels. -

Opentechnologies My Server 3DVBT User Guide
OpenTechnologies my server 3DVBT User guide 1 Quick start ....................................................................................................................................................................... 2 1.1 Features .................................................................................................................................................................. 2 1.2 Requirements .......................................................................................................................................................... 2 1.3 Package content ...................................................................................................................................................... 2 1.4 TV Server configuration .......................................................................................................................................... 3 1.5 Watching TV ............................................................................................................................................................ 6 1.6 Precautions ............................................................................................................................................................. 7 1.7 Device disposal ........................................................................................................................................................ 7 2 TV Server configuration ................................................................................................................................................. -

Homerun SOLD SEPARATELY
WORKS WITH ANTENNA HomeRun SOLD SEPARATELY YOUR CORD CUTTING SOLUTION FOR FREE OTA LIVE TV. The simple way to watch live HDTV on media devices throughout your home. 2 TUNERS HomeRun CONNECT DUO WORKS WITH OUR DVR APP $35/year DVR subscription, per entire household Available to download from hdhomerun.com HomeRun CONNECT DUO Have you thought about cutting the cord and forgetting about cable TV? Make HDHomeRun CONNECT DUO part of your home network. Receive Free to air TV via an antenna allowing you to send glorious high definition content to anywhere in your home over your existing home WiFi, or a wired Ethernet connection from your home router. No more expensive Cable TV subscriptions or cable boxes rental fees. You can now easily watch another program in a different room or enjoy football in the yard – whether on Android TV device, phone, tablet, computer or smart TV. You can watch LIVE TV through our HDHomeRun DVR app and you can record, pause, rewind and schedule your favorite shows using the HDHomeRun DVR OUR service*. DEVICES ARE 4K READY You can also watch and record Live TV with our Kodi/ XBMC Add-On or you can record, pause, rewind and schedule programs using popular compatible third party DVR software. *Requires Guide Subscription Cut the cable and save Pause on one device and on monthly rental fees. resume on another with multi- user, multi-device, multi-room Seamless Viewing™. Watch live HDTV on 2 devices Send live HDTV via your at the same time on your WiFi existing home WiFi or wired or wired network. -

More Than a Smart TV — a Better TV
43 R6E Series 4K Roku TV inches MODEL 43R6E1 More than a smart TV — a better TV If you love movies, shows, sports and gaming, then the R6 4K UHD Smart Hisense Roku TV is perfect for presenting your favorite entertainment in a whole new way. Featuring 4K Ultra High Definition resolution, the R6 packs incredible detail into an HDR- compatible display that boosts contrast and color. With Motion Rate processing tech, you can enjoy the fastest action without lag or judder. The Hisense Roku TV serves up a massive library of premium content at the touch of a button. Simple to set-up and easy- to-use, connect to the internet, activate, and start streaming. 4K Resolution Motion Rate HDR WI-FI Dual Band Wireless DTS Studio Sound™ More Options on the Table Works with Alexa ROKU TV OS Works with Google Assistant 43 R6E Series 4K Roku TV inches MODEL 43R6E1 TECHNICAL SPECIFICATIONS DIMENSIONS/WEIGHT L/R Audio Input for Component No Digital Audio Output 1 Optical TV Dimension (Without the stand) 38.2” x 22.6” x 2.8” Earphone/Audio Output 1 (With the stand) 38.2” x 23.9” x 8.4” TV stand Width 30.7” x 8.4” OTHER FEATURES TV Weight (Without the stand) 17.4 lbs Noise Reduction Yes (With the stand) 17.6 lbs Parental Control Yes Carton Dimensions (WxHxD) 42.4” x 26.1” x 5.4” Closed Caption Yes Shipping Weight 20.9 lbs Sleep Timer Yes DISPLAY WALL MOUNT Actual screen size (diagonal) 42.5” VESA 200x200 Screen class 43” ACCESSORIES Screen type Flat Remote Yes TYPE OF TV Quick Start Guide and/or User Quick Start Guide is in the box/ Smart TV Yes, Roku Operating -

User Manual Sanyo Smart
LED TV (FULL HD) XT-43S8100FS XT-49S8100FS Thank you for purchasing this Sanyo product. Please read these instructions carefully before operating this Product and retain them for future reference. The images shown in this manual are for illustrative purposes only. To obtain a more detailed Electronic Copy of this Manual or much further contents,go to product page at our website www.sanyoappliance.in E-mail: [email protected] Need help? Please Call at Toll Free No. 1800 419 5088 Table of Contents Chapter 1: Introduction Safety Precautions ............................................................................................................................. 3 Use Environment ................................................................................................................................ 4 Cleaning ............................................................................................................................................. 4 Hanging the TV Set on the Wall .......................................................................................................... 4 Base Installation ................................................................................................................................ 4 Standard accessories ....................................................................................................................... 5 Optional accessories ........................................................................................................................... 5 -

The Smart Fourth Amendment, 102 Cornell L
Cornell Law Review Volume 102 Article 1 Issue 3 March 2017 The mS art Fourth Amendment Andrew G. Ferguson Follow this and additional works at: http://scholarship.law.cornell.edu/clr Part of the Law Commons Recommended Citation Andrew G. Ferguson, The Smart Fourth Amendment, 102 Cornell L. Rev. 547 (2017) Available at: http://scholarship.law.cornell.edu/clr/vol102/iss3/1 This Article is brought to you for free and open access by the Journals at Scholarship@Cornell Law: A Digital Repository. It has been accepted for inclusion in Cornell Law Review by an authorized editor of Scholarship@Cornell Law: A Digital Repository. For more information, please contact [email protected]. \\jciprod01\productn\C\CRN\102-3\CRN304.txt unknown Seq: 1 28-MAR-17 9:53 THE “SMART” FOURTH AMENDMENT Andrew Guthrie Ferguson† “Smart” devices radiate data, exposing a continuous, inti- mate, and revealing pattern of daily life. Billions of sensors collect data from smartphones, smart homes, smart cars, med- ical devices, and an evolving assortment of consumer and commercial products. But, what are these data trails to the Fourth Amendment? Does data emanating from devices on or about our bodies, houses, things, and digital devices fall within the Fourth Amendment’s protection of “persons, houses, papers, and effects”? Does interception of this infor- mation violate a “reasonable expectation of privacy”? This Article addresses the question of how the Fourth Amendment should protect “smart data.” It exposes the grow- ing danger of sensor surveillance and the weakness of current Fourth Amendment doctrine. The Article then suggests a new theory of “informational curtilage” to protect the data trails emerging from smart devices and reclaims the principle of “informational security” as the organizing framework for a digital Fourth Amendment. -
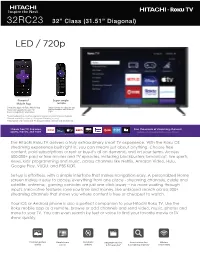
32RC23 32” Class (31.51” Diagonal)
32RC23 32” Class (31.51” Diagonal) LED / 720p Powerful Super simple Mobile App remote Limitations apply for Roku Mobile App. Actual remote includes pre-set Please see support.roku.com for channel buttons with channel logos. device compatibility information. *A paid subscription or other payments may be required for some channels. Channel availability subject to change and varies by country. †Roku search is for movies and TV shows and does not work with all channels. Stream free TV, live news, Plus thousands of streaming channels sports, movies, and more Visit roku.com/channelchecker to see more channels Payment required for some channels and content. 4K and HDR require 4K and HDR content, is not available on all channels and is subject to channel provider bandwidth requirements. Channels are subject to change and vary by region. The Hitachi Roku TV delivers a truly extraordinary smart TV experience. With the Roku OS streaming experience built right in, you can stream just about anything. Choose free content, paid subscriptions or rent or buy-it's all on demand, and on your terms. Access 500,000+ paid or free movies and TV episodes, including blockbusters, broadcast, live sports, news, kids' programming and music, across channels like Netflix, Amazon Video, Hulu, Google Play, VUDU, and PBS KIDS. Set-up is effortless, with a simple interface that makes navigation easy. A personalized Home screen makes it easy to access everything from one place - streaming channels, cable and satellite, antenna, gaming consoles are just one click away -- no more wading through inputs. Innovative features save you time and money, like unbiased search across 300+ streaming channels that shows you where content is free or cheapest to watch. -

Using Smart Tvs
Using smart TVs Do you have a smart TV? Let’s find out if you do, and what you can do with it to go beyond watching regular TV broadcasts. What is a smart TV? TVs are getting smarter all the time. Let’s see what’s special about smart TVs: • A smart TV includes a small computer with Wi-Fi for connecting to the internet. It has several apps loaded, like a smartphone, for playing all sorts of content from the internet. • You can control smart TVs with fancy remote controls, and many can also be controlled using your voice. Many smart TV can be • The most popular apps on smart TVs include ABC controlled using your voice iView, Netflix, YouTube and Amazon Prime Video. These are usually pre-installed on a new smart TV. Other apps can be installed from the TV’s app store. • While it’s usually most convenient to connect a smart TV to Wi-Fi, most smart TVs also include a wired network socket. • Smart TVs show special controls on their screen when you press the Home button. These might be a ribbon of options across the bottom or other icons or small panels from which you can choose programs or services. • If your TV does not connect to the internet, it is not a smart TV. If it is a smart TV and not connected to the internet, you’re not enjoying the benefits it has to offer. Try connecting it to make it smarter! For security, it’s important to get apps only from an official app store. -
How to Get a Jaolbroken Kodi Download on Pc How to Jailbreak Roku and Install Kodi (Workaround) Firstly, We Would Like to Say That It Is Not So Easy to Jailbreak Roku
how to get a jaolbroken kodi download on pc How to Jailbreak Roku and Install Kodi (Workaround) Firstly, we would like to say that it is not so easy to Jailbreak Roku. But there is some workaround available to watch Kodi on Roku TV. We are going to discuss those here. Roku is a digital media player that is used to stream content directly to your TV and thus transforming your TV into a smart device. It is one of the most popular streaming devices these days, which has the best variety that any digital media player can offer. It is extremely user-friendly and affordable like Fire TV Stick or a Chromecast. All you need to have is a Roku streaming stick and a TV with a stable internet connection. Related Articles. Kodi an open-source operating software for streaming videos free of cost. It is available on almost all platforms. It is also quite compatible with almost all OS like Windows, Linux, iOS, Android, and much more. Kodi also supports third-party add-ons, which means that users may use them for watching movies as well as tv shows for free. Now, users are finding ways to use Kodi or Roku for obvious reasons. Now, technically speaking, there is no legitimate way to use Kodi on Roku. Kodi is an Operating Software that has a C++ language backup that Roku is not yet compatible with. So you cannot directly link Kodi to Roku. But there are other ways with which you can use Kodi like an application on Roku, which is referred to as jailbreaking. -
Android Tv Box Lollipop Download How-To Install Libreelec Linux on Cheap Android TV Box
android tv box lollipop download How-to Install LibreELEC Linux on cheap Android TV Box. Today there are many cheap Android boxes, one of the most common processor is the Amlogic S905 or its more modern variants S905X and S905W. Those Quad-core Cortex-A53 CPUs can run 4K video on Android smoothly. But your Amlogic device is capable of some pretty cool things, one of those is running a full Linux operating system. In my case I have an X96 Mini, at a price o f $40 USD compares excellently against the $35 Raspberry Pi 3. Among others this small device has a fast Amlogic S905W quad-core 2GHz and Mali-450MP GPU, 2GB RAM and 16GB Flash, micro-sd reader, Ethernet & built-in WiFi, 2 USB ports and HDMI/AV output. BTW the X96 mini comes with everything you need as a power source, HDMI cable and IR remote control. As the purpose I had for this device was to use it for TV streaming I choose to install LibreELEC, but you could run a standard distribution Armbian versions from balbes150 if you like. LibreELEC (short for Libre Embedded Linux Entertainment Center) is a non-profit fork of OpenELEC Linux software appliance TV distro. LibreELEC is a complete media center software suite for embedded systems and computers, as it comes with a pre-configured version of Kodi and optional third-party PVR backend software. Kodi is one of the most popular media player and for good reason. The open-source program makes it easy to organize local files and watch streaming media on a wide variety of devices, all with the same highly customizable interface and user-friendly features. -

Hu8700 Smart Uhd Tv Spec Sheet
HU8700 SMART UHD TV SPEC SHEET PRODUCT HIGHLIGHTS • Ultra High Definition 4K (3840 x 2160) • UHD Upscaling • UHD 4K Standard Future Proof • UHD Dimming • Precision Black (Local Dimming) • Smart TV SIZES 55" 65" experience real world resolution with the Samsung Smart HU8700 UHD tV. the HU8700 includes exclusive technology that delivers incredi- bly lifelike UHD 4K picture quality. Watch any movie, sport, disc or streaming app at 4 times the resolution of full HD with UHD Upscaling. this ultra high definition is paired with UHD Dimming and Precision Black, which create outstanding contrast levels and provide greater detail with deep, rich color. explore the future of picture quality with the new HU8700. key features PICTURE QUALITY UHD 4K STANDARD FUTURE PROOF • Clear Motion Rate 1320 CONNECTIONS • Ultra High Definition 4K (3840 x 2160) ® • UHD Upscaling • 4 HDMI Connections • UHD Dimming • 3 USB Connections: • Precision Black (Local Dimming) • Wi-Fi Built in • 1 Component in SMART TV • 2 Composite in (AV) • Quad Core Processor • 1 Shared with Component • Smart Hub AUDIO • Full Web Browser ® • Quad Screen • Dolby Digital Plus ® ® • Instant On • Dolby Pulse with Dolby MS11 MultiStream Decoder • DTS Premium Sound | 5.1 Decoding with DTS Studio Sound™ SMART INTERACTION INCLUDES • Motion Control with Camera Accessory • Voice Interaction • Smart Remote Control • 4 Pairs of 3D Active Glasses (SSG-5150GB) SMART CONNECTIVITY • Screen Mirroring • Smart View 2.0 • S Recommendation • MHL Adapter See Back For DetAILS HU8700 SMART UHD TV SPEC SHEET KEY FEATURES PICTURE QUALITY SMART CONNECTIVITY UHD UPSCALING SCREEN Mirroring UHD Upscaling delivers the complete UHD picture experience with the screen mirroring feature allows you to mirror your phone or other a proprietary process including signal analysis, noise reduction and compatible mobile devices' screen onto the tVs screen wirelessly. -

SMART TV – the Basics
SMART TV – The Basics To use the TV as a Computer Monitor Connect through the HDMI Port using an HDMI cable. Once the connection has been made, press the SOURCE button to select the connected external device. Connect through the HDMI (DVI) port using a DVI to HDMI cable. Once the connection has been made, press the SOURCE button to select the connected external device. • To connect a Mac with Thuderbolt connector to the TV, Mini DisplayPort to HDMI Video Adapters are available for check-out at the AMLF Help Desk. Mirror a mobile device’s screen on the TV • Run Screen Mirroring on the mobile device and select the TV from the list of available devices to connect to (device must support Screen Mirroring). • In the pop-up displayed on the TV, select Allow to connect the mobile device. Connect a mobile device without a wireless router (Wi-Fi Direct) • Enable Wi-Fi Direct on the mobile device (device must support Wi-Fi Direct). • Navigate to Network and select Wi-Fi Direct on the TV. • Select the device from the list to initiate the connection, then select Allow. Smart Hub (surf the Web and launch Apps) • Installing an App from the SAMSUNG APPS screen: select Most Popular, What's new, or Categories, move the focus to an app, and then press and hold the button. A pop-up menu appears. Select Download. • To launch an App: select an app on the SAMSUNG APPS screen, and then press the button. • Deleting an App: move focus to the app you want to remove, then press and hold the button.