Application of DHT Protocol in IP Cloaking
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Windows 7 Operating Guide
Welcome to Windows 7 1 1 You told us what you wanted. We listened. This Windows® 7 Product Guide highlights the new and improved features that will help deliver the one thing you said you wanted the most: Your PC, simplified. 3 3 Contents INTRODUCTION TO WINDOWS 7 6 DESIGNING WINDOWS 7 8 Market Trends that Inspired Windows 7 9 WINDOWS 7 EDITIONS 10 Windows 7 Starter 11 Windows 7 Home Basic 11 Windows 7 Home Premium 12 Windows 7 Professional 12 Windows 7 Enterprise / Windows 7 Ultimate 13 Windows Anytime Upgrade 14 Microsoft Desktop Optimization Pack 14 Windows 7 Editions Comparison 15 GETTING STARTED WITH WINDOWS 7 16 Upgrading a PC to Windows 7 16 WHAT’S NEW IN WINDOWS 7 20 Top Features for You 20 Top Features for IT Professionals 22 Application and Device Compatibility 23 WINDOWS 7 FOR YOU 24 WINDOWS 7 FOR YOU: SIMPLIFIES EVERYDAY TASKS 28 Simple to Navigate 28 Easier to Find Things 35 Easy to Browse the Web 38 Easy to Connect PCs and Manage Devices 41 Easy to Communicate and Share 47 WINDOWS 7 FOR YOU: WORKS THE WAY YOU WANT 50 Speed, Reliability, and Responsiveness 50 More Secure 55 Compatible with You 62 Better Troubleshooting and Problem Solving 66 WINDOWS 7 FOR YOU: MAKES NEW THINGS POSSIBLE 70 Media the Way You Want It 70 Work Anywhere 81 New Ways to Engage 84 INTRODUCTION TO WINDOWS 7 6 WINDOWS 7 FOR IT PROFESSIONALS 88 DESIGNING WINDOWS 7 8 WINDOWS 7 FOR IT PROFESSIONALS: Market Trends that Inspired Windows 7 9 MAKE PEOPLE PRODUCTIVE ANYWHERE 92 WINDOWS 7 EDITIONS 10 Remove Barriers to Information 92 Windows 7 Starter 11 Access -

Malware and Social Engineering Attacks
chapter 2 Malware and Social Engineering Attacks After completing this chapter, you will be able to do the following: ● Describe the differences between a virus and a worm ● List the types of malware that conceals its appearance ● Identify different kinds of malware that is designed for profit ● Describe the types of social engineering psychological attacks ● Explain physical social engineering attacks 41 42 Chapter 2 Malware and Social Engineering Attacks Today’s Attacks and Defenses Successful software companies use a variety of strategies to outsell their competition and gain market share. These strategies may include selling their software at or below a com- petitor’s price, offering better technical support to customers, or providing customized software for clients. And if all else fails, a final strategy can be to buy out the competition through a merger or acquisition. These strategies are also being widely used by attackers who sell their attack software to others. Approximately two out of three malicious Web attacks have been developed using one of three popular attack toolkits. The toolkits are MPack (the most popular attack toolkit, which has almost half of the attacker toolkit mar- ket), NeoSploit, and ZeuS. These toolkits, which are bought and sold online through the underground attacker community, are used to create customized malware that can steal personal information, execute fraudulent financial transactions, and infect computers without the user’s knowledge. The toolkits range in price from only $40 to as much as $8,000. The developers behind these attack toolkits compete fiercely with each other. Some of their tactics include updating the toolkits to keep ahead of the latest security defenses, advertising their attack toolkits as cheaper than the competition, and provid- ing technical support to purchasers. -

Norton™ Utilities Premium: User Manual
Norton™ Utilities Premium User Manual Norton Utilities Premium User Guide The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Copyright © 2018 Symantec Corporation. All rights reserved. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be commercial computer software as defined in FAR 12.212 and subject to restricted rights as defined in FAR Section 52.227-19 "Commercial Computer Software - Restricted Rights" and DFARS 227.7202, et seq. "Commercial Computer Software and Commercial Computer Software Documentation," as applicable, and any successor regulations, whether delivered by Symantec as on premises or hosted services. Any use, modification, reproduction release, performance, display or disclosure of the Licensed Software and Documentation by the U.S. Government shall be solely in accordance with the terms of this Agreement. -

Τα Passwords Στα Windows XP Και 2K Είναι Αποθηκεμένα Στο SAM File Το Οποίο Βρίσκεται Στο C:\Windows\System32\Config
Τεχνολογικό Εκπαιδευτικό Ίδρυμα Κρήτης Σχολή Τεχνολογικών Εφαρμογών Τμήμα Εφαρμοσμένης Πληροφορικής & Πολυμέσων Πτυχιακή εργασία Τίτλος: Μελέτη και δοκιμαστική λειτουργία των μηχανισμών ασφάλειας που παρέχει η πλατφόρμα Microsoft Windows XP ΚΟΥΡΟΣ ΚΩΝΣΤΑΝΤΙΝΟΣ (Α.Μ. 355) Ηράκλειο - Ημερομηνία Επόπτης Καθηγητής: Δρ. Μανιφάβας Χαράλαμπος 1 Περιεχόμενα Περιεχόμενα ..................................................................................................................2 Εισαγωγή.......................................................................................................................4 Σκοπός μελέτης...............................................................................................................................4 Λίγα λόγια για τα Windows XP......................................................................................................4 Προβλήματα ασφάλειας..................................................................................................................5 Τα passwords και η λειτουργία τους.............................................................................7 Windows Passwords............................................................................................................ 7 PASSWORDS.................................................................................................................................7 RECOVERY-CRACKING.............................................................................................................8 LC5 βήμα προς βήμα ....................................................................................................................16 -

Citrix Cloud Citrix Service Providers (Traditional)
TOMORROW ON WHEELS Microsoft Citrix Partnership Microsoft Strategic Alliance Driving Forward with Cloud and Mobility © 2016 Citrix. Confidential. Agenda Microsoft Strategic Relationship • Why Citrix • Current solutions Microsoft & Citrix together • Azure solutions • Office 365 • Windows 10 • New strategic agreement on Cloud and Mobility 5 © 2016 Citrix. Confidential. People Organizations Things “Power a world where people, organizations, and things are securely connected and accessible, so that you can make the extraordinary possible “ Citrix Strategy Build the world’s best integrated technology services for secure delivery of apps and data—anytime, anywhere. 7 © 2016 Citrix | Confidential XenApp and XenDesktop Technology Deployment Options On-Premises Citrix Cloud Citrix Service Providers (Traditional) Public Or Private Corporate Data Center Service Provider Cloud Cloud Subscription Offerings Perpetual Offerings Service Provider Offerings: • Desktops Service • XenApp Advanced edition • Subscription offers by individual • Apps & Desktop Service • XenApp Enterprise edition Service Providers • XenApp Platinum edition • XenDesktop VDI edition • XenDesktop Enterprise ed. • XenDesktop Platinum ed. 8 © 2016 Citrix | Confidential Citrix Cloud Citrix Solutions Today-Azure, Office 365 and Windows 10 Current Azure Solutions Enterprise Cloud Enterprise File Enterprise App Skype for Business Windows 10 App Delivery Networking Sync and Share Delivery Cloud Optimization Office 365 Delivery via IaaS • BYOL/IaaS Solution • Enhance load balancing • Mobilize employees • Unify administration • Virtual Skype for • Accelerate Win10 • Centralize control • Deliver network • Provide anywhere • Smooth on-ramp to the Business solution only delivery • Increase mobility optimization access cloud available from Citrix • Secure Office 365 • Enable cloud • Cross security and control • Aggregate enterprise • Cross-service • Uncompromised • Deliver Windows apps management data coordination quality of voice and video XenApp & XenDesktop Services Optimization Pack 10 © 2016 Citrix. -

X41 D-SEC Gmbh Dennewartstr
Browser Security White PAPER Final PAPER 2017-09-19 Markus VERVIER, Michele Orrù, Berend-Jan WEVER, Eric Sesterhenn X41 D-SEC GmbH Dennewartstr. 25-27 D-52068 Aachen Amtsgericht Aachen: HRB19989 Browser Security White PAPER Revision History Revision Date Change Editor 1 2017-04-18 Initial Document E. Sesterhenn 2 2017-04-28 Phase 1 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 3 2017-05-19 Phase 2 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 4 2017-05-25 Phase 3 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 5 2017-06-05 First DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 6 2017-06-26 Second DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 7 2017-07-24 Final DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 8 2017-08-25 Final PAPER M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 9 2017-09-19 Public Release M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER X41 D-SEC GmbH PAGE 1 OF 196 Contents 1 ExECUTIVE Summary 7 2 Methodology 10 3 Introduction 12 3.1 Google Chrome . 13 3.2 Microsoft Edge . 14 3.3 Microsoft Internet Explorer (IE) . 16 4 Attack Surface 18 4.1 Supported Standards . 18 4.1.1 WEB TECHNOLOGIES . 18 5 Organizational Security Aspects 21 5.1 Bug Bounties . 21 5.1.1 Google Chrome . 21 5.1.2 Microsoft Edge . 22 5.1.3 Internet Explorer . 22 5.2 Exploit Pricing . 22 5.2.1 ZERODIUM . 23 5.2.2 Pwn2Own . -

Microsoft Smartscreen
Microsoft SmartScreen SmartScreen is a cloud-based anti-phishing and anti-malware component included in several Microsoft products, including Windows 10, Microsoft Edge and Outlook.com. It is designed to help protect users against attacks that utilize social engineering and drive-by downloads to infect a system by scanning URLs accessed by a user against a blacklist of websites containing known threats. Microsoft placed the SmartScreen settings into the Windows Defender Security Center. Microsoft Defender SmartScreen helps you identify reported phishing and malware websites and also helps you make informed decisions about downloads. SmartScreen helps protect you in three ways: • As you browse the web, it analyzes pages and determines if they might be suspicious. If it finds suspicious pages, SmartScreen will display a warning page, giving you an opportunity to provide feedback and advising you to continue with caution. • SmartScreen checks the sites you visit against a dynamic list of reported phishing sites and malicious software sites. If it finds a match, SmartScreen will show you a warning, letting you know that the site has been blocked for your safety. • SmartScreen checks files that you download from the web against a list of reported malicious software sites and programs known to be unsafe. If it finds a match, SmartScreen will warn you that the download has been blocked for your safety. SmartScreen also checks the files that you download against a list of files that are well known and downloaded by many people who use Edge. If the file that you are downloading isn't on that list, SmartScreen will warn you. -
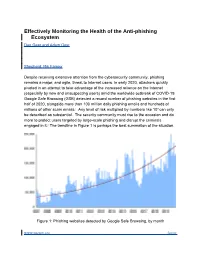
Despite Receiving Extensive Attention from the Cybersecurity Community, Phishing Remains a Major, and Agile, Threat to Internet Users
Effectively Monitoring the Health of the Anti-phishing Ecosystem Dan Geer and Adam Oest Shepherd: Rik Farrow Despite receiving extensive attention from the cybersecurity community, phishing remains a major, and agile, threat to Internet users. In early 2020, attackers quickly pivoted in an attempt to take advantage of the increased reliance on the Internet (especially by new and unsuspecting users) amid the worldwide outbreak of COVID-19. Google Safe Browsing (GSB) detected a record number of phishing websites in the first half of 2020, alongside more than 100 million daily phishing emails and hundreds of millions of other scam emails.i Any level of risk multiplied by numbers like 108 can only be described as substantial. The security community must rise to the occasion and do more to protect users targeted by large-scale phishing and disrupt the criminals engaged in it.ii The trendline in Figure 1 is perhaps the best summation of the situation. Figure 1: Phishing websites detected by Google Safe Browsing, by month www.usenix.org ;login: Most cyberattacks exploit technical vulnerabilities in computer systems; however, phishing attacks instead target the users of those systems with deceit, tricking the human user sitting in front of the screen into taking actions they would not normally take, such as sharing sensitive personal information. In turn, these actions put the victim users and others at risk. Even though phishing may appear trivial on the surface, it is not – modern attacks are marked by a high degree of sophistication, especially measures to evade timely detection by anti-phishing systems. That growing sophistication makes phishing particularly dangerous. -

Handbook on Identity-Related Crime Cover Image © Dreamstime UNITED NATIONS OFFICE on DRUGS and CRIME Vienna
Handbook on Identity-related Crime Cover image © Dreamstime UNITED NATIONS OFFICE ON DRUGS AND CRIME Vienna Handbook on Identity-related Crime United Nations New York, 2011 10-58702_inner_FINAL.indd 1 29/03/2011 00:01 © United Nations, April 2011. All rights reserved. The designations employed and the presentation of material in this publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area, or of its authori- ties, or concerning the delimitation of its frontiers or boundaries. This publication has not been formally edited. Publishing production: English, Publishing and Library Section, United Nations Office at Vienna. 10-58702_inner_FINAL.indd 2 29/03/2011 00:01 Foreword The present Handbook follows the release in 2007 of the United Nations study on “fraud and the criminal misuse and falsification of identity”, commissioned by UNODC and submitted to the United Nations Commission on Crime Prevention and Criminal Justice at its sixteenth session (E/CN.15/2007/8 and Add. 1-3), in line with Economic and Social Council resolution 2004/26. The main contribution and achievement of that study was two-fold: first, it adopted a broad approach on the concept of “identity-related crime” and considered it in an inclusive manner to cover all forms of illicit conduct involving identity, including offences described, often not consistently, as “identity fraud” and “identity theft”. Second, it dealt with the problems posed by identity-related crime from a new criminal justice perspective and the treatment of identity abuses as distinct criminal offences, as opposed to the traditional approach of criminalizing other activities commit- ted using false identities. -

Improve Your Browser's Security Settings for Greater Protection While
S491.qxp_September 2018 02/08/2018 14:11 Page 35 Secure Browsing with the Correct Configuration S 491/1 Improve Your Browser’s Security Settings for Greater Protection while Browsing the Internet Using the information given in this article you will be able to: Configure Edge, IE, Firefox and Chrome for perfect security, Remove the insecure add-ons that leave your browser vulnerable to attack, Boost your browser protection with registry tweaks. Your web browser is the application you probably use most on your PC, but it is also the one that is most at risk. That is why it is so important to take steps to configure your browser’s security settings to protect your PC from coming to harm. The vast majority of malware infections arrive via hijacked or fake websites, since Windows Firewall has blocked most of the other routes hackers used to take to infect PCs. This means that it has never been more important to secure your web browser against attacks. All the latest web browsers come with a raft of security features to help you do that but it is important to take the time to configure the features correctly. This will result in the highest level of protection possible from your browser. Follow the steps in this article for a perfectly configured web browser and enhanced online security. • Configure Edge for Best Security .......... .......... ............... S 491/2 • Set Up Internet Explorer for Optimised Security .. ....... S 491/3 • Boost the Security of Google’s Chrome Browser .......... S 491/4 • Protect Firefox with Optimal Security Settings .. -

Phishprint: Evading Phishing Detection Crawlers by Prior Profiling
PhishPrint: Evading Phishing Detection Crawlers by Prior Profiling Bhupendra Acharya and Phani Vadrevu, UNO Cyber Center, University of New Orleans https://www.usenix.org/conference/usenixsecurity21/presentation/acharya This paper is included in the Proceedings of the 30th USENIX Security Symposium. August 11–13, 2021 978-1-939133-24-3 Open access to the Proceedings of the 30th USENIX Security Symposium is sponsored by USENIX. PhishPrint: Evading Phishing Detection Crawlers by Prior Profiling Bhupendra Acharya Phani Vadrevu UNO Cyber Center UNO Cyber Center University of New Orleans University of New Orleans [email protected] [email protected] Abstract Firefox, Safari, and Samsung Internet web browsers which Security companies often use web crawlers to detect together account for about 90% of the market share use the phishing and other social engineering attack websites. We GSB blocklist [3]. GSB is deployed in about four billion built a novel, scalable, low-cost framework named PhishPrint devices worldwide and shows millions of browser warnings to enable the evaluation of such web security crawlers against every day protecting users from web attacks. Such blocklists multiple cloaking attacks. PhishPrint is unique in that it are populated with the help of web security crawlers that completely avoids the use of any simulated phishing sites and regularly scout web-pages to evaluate them. However, in blocklisting measurements. Instead, it uses web pages with order to evade these crawlers, miscreants employ many benign content to profile security crawlers. cloaking techniques [23, 38, 39, 49, 52]. We used PhishPrint to evaluate 23 security crawlers Despite such great importance, security crawlers have including highly ubiquitous services such as Google Safe been left understudied for a long time. -
Free Download Chrome Web Browser How to Install Chromium in Windows 10
free download chrome web browser How to install Chromium in Windows 10. You may not realize it, but Chromium is the basis for many of today’s most popular browsers, including Google Chrome, Opera and the latest iteration of Microsoft Edge. Chromium itself is an open-source browser that can freely be used by other developers wishing to make their own browsers over the top of it, and you can use the base version of Chromium yourself, too. Chromium used to be a bit fiddly to install on Windows but is now a whole lot simpler than it used to be. Here we show you how to install Chromium on Windows 10. You can always find the latest version of Chromium here on the Chromium website. You’ll see a warning saying that this is a “raw” version of Chromium and may therefore be buggy, but this is what you came for, so no point questioning it now! Across the bottom of this page you’ll see links to different versions of Chromium, including a 32-bit version “for Windows x86.” Once you’ve downloaded the ZIP file, extract it to the directory where you want Chromium installed. Go to the directory once it’s extracted, then double-click the “chrome” executable. You may get a notification saying that Microsoft Defender has “prevented an unrecognized app from starting.” If this pops up, click “More info” then “Run anyway.” If you want, you can also pin Chromium to your taskbar or create a desktop shortcut. Just right-click the “chrome” executable, then click “Pin to taskbar” or “Create shortcut.” And that’s it! You now have the latest build of Chromium running on your PC.