Identification and Validation of a Gene Expression Signature That Predicts Outcome in Malignant Glioma Patients
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binding Specificities of Human RNA Binding Proteins Towards Structured
bioRxiv preprint doi: https://doi.org/10.1101/317909; this version posted March 1, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Binding specificities of human RNA binding proteins towards structured and linear 2 RNA sequences 3 4 Arttu Jolma1,#, Jilin Zhang1,#, Estefania Mondragón4,#, Teemu Kivioja2, Yimeng Yin1, 5 Fangjie Zhu1, Quaid Morris5,6,7,8, Timothy R. Hughes5,6, Louis James Maher III4 and Jussi 6 Taipale1,2,3,* 7 8 9 AUTHOR AFFILIATIONS 10 11 1Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Solna, Sweden 12 2Genome-Scale Biology Program, University of Helsinki, Helsinki, Finland 13 3Department of Biochemistry, University of Cambridge, Cambridge, United Kingdom 14 4Department of Biochemistry and Molecular Biology and Mayo Clinic Graduate School of 15 Biomedical Sciences, Mayo Clinic College of Medicine and Science, Rochester, USA 16 5Department of Molecular Genetics, University of Toronto, Toronto, Canada 17 6Donnelly Centre, University of Toronto, Toronto, Canada 18 7Edward S Rogers Sr Department of Electrical and Computer Engineering, University of 19 Toronto, Toronto, Canada 20 8Department of Computer Science, University of Toronto, Toronto, Canada 21 #Authors contributed equally 22 *Correspondence: [email protected] 23 24 25 SUMMARY 26 27 Sequence specific RNA-binding proteins (RBPs) control many important 28 processes affecting gene expression. They regulate RNA metabolism at multiple 29 levels, by affecting splicing of nascent transcripts, RNA folding, base modification, 30 transport, localization, translation and stability. Despite their central role in most 31 aspects of RNA metabolism and function, most RBP binding specificities remain 32 unknown or incompletely defined. -

Whole Exome Sequencing in Families at High Risk for Hodgkin Lymphoma: Identification of a Predisposing Mutation in the KDR Gene
Hodgkin Lymphoma SUPPLEMENTARY APPENDIX Whole exome sequencing in families at high risk for Hodgkin lymphoma: identification of a predisposing mutation in the KDR gene Melissa Rotunno, 1 Mary L. McMaster, 1 Joseph Boland, 2 Sara Bass, 2 Xijun Zhang, 2 Laurie Burdett, 2 Belynda Hicks, 2 Sarangan Ravichandran, 3 Brian T. Luke, 3 Meredith Yeager, 2 Laura Fontaine, 4 Paula L. Hyland, 1 Alisa M. Goldstein, 1 NCI DCEG Cancer Sequencing Working Group, NCI DCEG Cancer Genomics Research Laboratory, Stephen J. Chanock, 5 Neil E. Caporaso, 1 Margaret A. Tucker, 6 and Lynn R. Goldin 1 1Genetic Epidemiology Branch, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 2Cancer Genomics Research Laboratory, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 3Ad - vanced Biomedical Computing Center, Leidos Biomedical Research Inc.; Frederick National Laboratory for Cancer Research, Frederick, MD; 4Westat, Inc., Rockville MD; 5Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; and 6Human Genetics Program, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD, USA ©2016 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2015.135475 Received: August 19, 2015. Accepted: January 7, 2016. Pre-published: June 13, 2016. Correspondence: [email protected] Supplemental Author Information: NCI DCEG Cancer Sequencing Working Group: Mark H. Greene, Allan Hildesheim, Nan Hu, Maria Theresa Landi, Jennifer Loud, Phuong Mai, Lisa Mirabello, Lindsay Morton, Dilys Parry, Anand Pathak, Douglas R. Stewart, Philip R. Taylor, Geoffrey S. Tobias, Xiaohong R. Yang, Guoqin Yu NCI DCEG Cancer Genomics Research Laboratory: Salma Chowdhury, Michael Cullen, Casey Dagnall, Herbert Higson, Amy A. -

The Genetics of Bipolar Disorder
Molecular Psychiatry (2008) 13, 742–771 & 2008 Nature Publishing Group All rights reserved 1359-4184/08 $30.00 www.nature.com/mp FEATURE REVIEW The genetics of bipolar disorder: genome ‘hot regions,’ genes, new potential candidates and future directions A Serretti and L Mandelli Institute of Psychiatry, University of Bologna, Bologna, Italy Bipolar disorder (BP) is a complex disorder caused by a number of liability genes interacting with the environment. In recent years, a large number of linkage and association studies have been conducted producing an extremely large number of findings often not replicated or partially replicated. Further, results from linkage and association studies are not always easily comparable. Unfortunately, at present a comprehensive coverage of available evidence is still lacking. In the present paper, we summarized results obtained from both linkage and association studies in BP. Further, we indicated new potential interesting genes, located in genome ‘hot regions’ for BP and being expressed in the brain. We reviewed published studies on the subject till December 2007. We precisely localized regions where positive linkage has been found, by the NCBI Map viewer (http://www.ncbi.nlm.nih.gov/mapview/); further, we identified genes located in interesting areas and expressed in the brain, by the Entrez gene, Unigene databases (http://www.ncbi.nlm.nih.gov/entrez/) and Human Protein Reference Database (http://www.hprd.org); these genes could be of interest in future investigations. The review of association studies gave interesting results, as a number of genes seem to be definitively involved in BP, such as SLC6A4, TPH2, DRD4, SLC6A3, DAOA, DTNBP1, NRG1, DISC1 and BDNF. -
Drosophila and Human Transcriptomic Data Mining Provides Evidence for Therapeutic
Drosophila and human transcriptomic data mining provides evidence for therapeutic mechanism of pentylenetetrazole in Down syndrome Author Abhay Sharma Institute of Genomics and Integrative Biology Council of Scientific and Industrial Research Delhi University Campus, Mall Road Delhi 110007, India Tel: +91-11-27666156, Fax: +91-11-27662407 Email: [email protected] Nature Precedings : hdl:10101/npre.2010.4330.1 Posted 5 Apr 2010 Running head: Pentylenetetrazole mechanism in Down syndrome 1 Abstract Pentylenetetrazole (PTZ) has recently been found to ameliorate cognitive impairment in rodent models of Down syndrome (DS). The mechanism underlying PTZ’s therapeutic effect is however not clear. Microarray profiling has previously reported differential expression of genes in DS. No mammalian transcriptomic data on PTZ treatment however exists. Nevertheless, a Drosophila model inspired by rodent models of PTZ induced kindling plasticity has recently been described. Microarray profiling has shown PTZ’s downregulatory effect on gene expression in fly heads. In a comparative transcriptomics approach, I have analyzed the available microarray data in order to identify potential mechanism of PTZ action in DS. I find that transcriptomic correlates of chronic PTZ in Drosophila and DS counteract each other. A significant enrichment is observed between PTZ downregulated and DS upregulated genes, and a significant depletion between PTZ downregulated and DS dowwnregulated genes. Further, the common genes in PTZ Nature Precedings : hdl:10101/npre.2010.4330.1 Posted 5 Apr 2010 downregulated and DS upregulated sets show enrichment for MAP kinase pathway. My analysis suggests that downregulation of MAP kinase pathway may mediate therapeutic effect of PTZ in DS. Existing evidence implicating MAP kinase pathway in DS supports this observation. -

Peripheral Neuropathy Linked Mrna Export Factor GANP Reshapes Gene
bioRxiv preprint doi: https://doi.org/10.1101/2021.05.18.444636; this version posted May 18, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Peripheral neuropathy linked mRNA export factor GANP 2 reshapes gene regulation in human motor neurons 3 4 Rosa Woldegebriel1,2, Jouni Kvist1, Matthew White2, Matilda Sinkko1, Satu Hänninen3,4, 5 Markus T Sainio1, Rubén Torregrosa-Munumer1, Sandra Harjuhaahto1, Nadine Huber5, Sanna- 6 Kaisa Herukka6,7, Annakaisa Haapasalo5, Olli Carpen3,4, Andrew Bassett8, Emil Ylikallio1,9, 7 Jemeen Sreedharan2*, Henna Tyynismaa1,10,11* 8 9 1 Stem Cells and Metabolism Research Program, Faculty of Medicine, University of Helsinki, 10 00290 Helsinki, Finland. 11 2 Maurice Wohl Clinical Neuroscience Institute, Institute of Psychiatry, Psychology and 12 Neuroscience, King's College London, London, UK. 13 3 Department of Pathology, University of Helsinki and Helsinki University Hospital, Helsinki, 14 Finland. 15 4 Research Program in Systems Oncology, University of Helsinki, Helsinki, Finland. 16 5 A.I. Virtanen Institute for Molecular Sciences, University of Eastern Finland, Kuopio, 17 Finland. 18 6 Department of Neurology, Kuopio University Hospital, Kuopio, Finland. 19 7 Neurology, Institute of Clinical Medicine, University of Eastern Finland, Kuopio, Finland. 20 8 Wellcome Sanger Institute, Wellcome Genome Campus, Hinxton, Cambridge, UK. 21 9 Clinical Neurosciences, Neurology, University of Helsinki and Helsinki University Hospital, 22 00290 Helsinki, Finland. 23 10 Department of Medical and Clinical Genetics, University of Helsinki, 00290 Helsinki, 24 Finland. 25 11 Neuroscience Center, Helsinki Institute of Life Science, University of Helsinki, Helsinki, 26 Finland. -

The Human Nucleoporin Tpr Protects Cells from RNA-Mediated Replication Stress
ARTICLE https://doi.org/10.1038/s41467-021-24224-3 OPEN The human nucleoporin Tpr protects cells from RNA-mediated replication stress Martin Kosar 1,2,9, Michele Giannattasio 1,3, Daniele Piccini 1, Apolinar Maya-Mendoza 4, Francisco García-Benítez5, Jirina Bartkova4,6, Sonia I. Barroso 5, Hélène Gaillard 5, Emanuele Martini 1, Umberto Restuccia1, Miguel Angel Ramirez-Otero 1, Massimiliano Garre1, Eleonora Verga1, Miguel Andújar-Sánchez 7, Scott Maynard 4, Zdenek Hodny2, Vincenzo Costanzo1,3, Amit Kumar 8, ✉ ✉ ✉ Angela Bachi 1, Andrés Aguilera 5 , Jiri Bartek 2,4,6 & Marco Foiani 1,3 1234567890():,; Although human nucleoporin Tpr is frequently deregulated in cancer, its roles are poorly understood. Here we show that Tpr depletion generates transcription-dependent replication stress, DNA breaks, and genomic instability. DNA fiber assays and electron microscopy visualization of replication intermediates show that Tpr deficient cells exhibit slow and asymmetric replication forks under replication stress. Tpr deficiency evokes enhanced levels of DNA-RNA hybrids. Additionally, complementary proteomic strategies identify a network of Tpr-interacting proteins mediating RNA processing, such as MATR3 and SUGP2, and functional experiments confirm that their depletion trigger cellular phenotypes shared with Tpr deficiency. Mechanistic studies reveal the interplay of Tpr with GANP, a component of the TREX-2 complex. The Tpr-GANP interaction is supported by their shared protein level alterations in a cohort of ovarian carcinomas. Our results reveal links between nucleoporins, DNA transcription and replication, and the existence of a network physically connecting replication forks with transcription, splicing, and mRNA export machinery. 1 IFOM, Fondazione Istituto FIRC di Oncologia Molecolare, Milano, Italy. -

Long Non-Coding RNA MCM3AP-AS1 Promotes Growth and Migration
Yang et al. Molecular Medicine (2019) 25:55 Molecular Medicine https://doi.org/10.1186/s10020-019-0121-2 RESEARCH ARTICLE Open Access Long non-coding RNA MCM3AP-AS1 promotes growth and migration through modulating FOXK1 by sponging miR-138- 5p in pancreatic cancer Ming Yang1, Shijuan Sun2, Yao Guo1, Junjie Qin2 and Guangming Liu2* Abstract Background: Pancreatic cancer (PC) is a type of malignant gastrointestinal tumor. Long non-coding RNA MCM3AP antisense RNA 1 (MCM3AP-AS1) has been reported to stimulate proliferation, migration and invasion in several types of tumors. However, the role of MCM3AP-AS1 in PC remains unclear. Methods: MCM3AP-AS1, microRNA miR-138-5p (miR-138-5p) and FOXK1 levels were detected using quantitative real time PCR. Cell proliferation, migration and invasion were analyzed. Dual luciferase reporter assay was used to confirm the relationship between MCM3AP-AS1 and miR-138-5p, between miR-138-5p and FOXK1. Protein levels were identified using western blot analysis. Results: MCM3AP-AS1 overexpression promoted proliferation, migration and invasion in PC cells. MCM3AP-AS1 silencing showed a suppressive effect on cell growth in PC cells. Moreover, MCM3AP-AS1 knockdown suppressed tumor growth in mice. Dual luciferase reporter assay demonstrated MCM3AP-AS1 could sponge microRNA-138-5p (miR-138-5p), and FOXK1 could bind with miR-138-5p. Positive correlation between MCM3AP-AS1 and FOXK1 was testified, as well as negative correlation between miR-138-5p and FOXK1. MCM3AP-AS1 promoted FOXK1 expression by targeting miR-138-5p, and MCM3AP-AS1 facilitated growth and invasion in PC cells by FOXK1. Conclusion: MCM3AP-AS1 promoted growth and migration through modulating miR-138-5p/FOXK1 axis in PC, providing insights into MCM3AP-AS1/miR-138-5p/FOXK1 axis as novel candidates for PC therapy from bench to clinic. -

Binding Specificities of Human RNA Binding Proteins Towards Structured and Linear RNA Sequences
bioRxiv preprint doi: https://doi.org/10.1101/317909; this version posted May 16, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Binding specificities of human RNA binding proteins towards structured and linear 2 RNA sequences 3 4 Arttu Jolma1,#, Jilin Zhang1,#, Estefania Mondragón4,#, Teemu Kivioja2, Yimeng Yin1, 5 Fangjie Zhu1, Quaid Morris5,6,7,8, Timothy R. Hughes5,6, Louis James Maher III4 and Jussi 6 Taipale1,2,3,* 7 8 9 AUTHOR AFFILIATIONS 10 11 1Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Solna, Sweden 12 2Genome-Scale Biology Program, University of Helsinki, Helsinki, Finland 13 3Department of Biochemistry, University of Cambridge, Cambridge, United Kingdom 14 4Department of Biochemistry and Molecular Biology and Mayo Clinic Graduate School of 15 Biomedical Sciences, Mayo Clinic College of Medicine and Science, Rochester, USA 16 5Department of Molecular Genetics, University of Toronto, Toronto, Canada 17 6Donnelly Centre, University of Toronto, Toronto, Canada 18 7Edward S Rogers Sr Department of Electrical and Computer Engineering, University of 19 Toronto, Toronto, Canada 20 8Department of Computer Science, University of Toronto, Toronto, Canada 21 22 #Authors contributed equally 23 *Correspondence: [email protected] 24 25 26 ABSTRACT 27 28 Sequence specific RNA-binding proteins (RBPs) control many important 29 processes affecting gene expression. They regulate RNA metabolism at multiple 30 levels, by affecting splicing of nascent transcripts, RNA folding, base modification, 31 transport, localization, translation and stability. Despite their central role in most 32 aspects of RNA metabolism and function, most RBP binding specificities remain 33 unknown or incompletely defined. -
![Downloaded from [22]](https://docslib.b-cdn.net/cover/0100/downloaded-from-22-2810100.webp)
Downloaded from [22]
BMC Genomics BioMed Central Research article Open Access Cell array-based intracellular localization screening reveals novel functional features of human chromosome 21 proteins Yu-Hui Hu1,2, Hans-Jörg Warnatz1, Dominique Vanhecke1, Florian Wagner3, Andrea Fiebitz1, Sabine Thamm1, Pascal Kahlem1,4, Hans Lehrach1, Marie- Laure Yaspo1 and Michal Janitz*1 Address: 1Department of Vertebrate Genomics, Max Planck Institute for Molecular Genetics, 14195 Berlin, Germany, 2FU Berlin, Department of Biology, Chemistry and Pharmacy, 14195 Berlin, Germany, 3RZPD German Resource Center for Genome Research, 14059 Berlin, Germany and 4Department of Hematology, Oncology, and Tumor Immunology, Humboldt University, Charite, Berlin, Germany Email: Yu-Hui Hu - [email protected]; Hans-Jörg Warnatz - [email protected]; Dominique Vanhecke - [email protected]; Florian Wagner - [email protected]; Andrea Fiebitz - [email protected]; Sabine Thamm - [email protected]; Pascal Kahlem - [email protected]; Hans Lehrach - [email protected]; Marie- Laure Yaspo - [email protected]; Michal Janitz* - [email protected] * Corresponding author Published: 16 June 2006 Received: 13 March 2006 Accepted: 16 June 2006 BMC Genomics 2006, 7:155 doi:10.1186/1471-2164-7-155 This article is available from: http://www.biomedcentral.com/1471-2164/7/155 © 2006 Hu et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Trisomy of human chromosome 21 (Chr21) results in Down's syndrome, a complex developmental and neurodegenerative disease. -

A Yeast-Based Model for Hereditary Motor and Sensory Neuropathies: a Simple System for Complex, Heterogeneous Diseases
International Journal of Molecular Sciences Review A Yeast-Based Model for Hereditary Motor and Sensory Neuropathies: A Simple System for Complex, Heterogeneous Diseases Weronika Rzepnikowska 1, Joanna Kaminska 2 , Dagmara Kabzi ´nska 1 , Katarzyna Bini˛eda 1 and Andrzej Kocha ´nski 1,* 1 Neuromuscular Unit, Mossakowski Medical Research Centre Polish Academy of Sciences, 02-106 Warsaw, Poland; [email protected] (W.R.); [email protected] (D.K.); [email protected] (K.B.) 2 Institute of Biochemistry and Biophysics Polish Academy of Sciences, 02-106 Warsaw, Poland; [email protected] * Correspondence: [email protected] Received: 19 May 2020; Accepted: 15 June 2020; Published: 16 June 2020 Abstract: Charcot–Marie–Tooth (CMT) disease encompasses a group of rare disorders that are characterized by similar clinical manifestations and a high genetic heterogeneity. Such excessive diversity presents many problems. Firstly, it makes a proper genetic diagnosis much more difficult and, even when using the most advanced tools, does not guarantee that the cause of the disease will be revealed. Secondly, the molecular mechanisms underlying the observed symptoms are extremely diverse and are probably different for most of the disease subtypes. Finally, there is no possibility of finding one efficient cure for all, or even the majority of CMT diseases. Every subtype of CMT needs an individual approach backed up by its own research field. Thus, it is little surprise that our knowledge of CMT disease as a whole is selective and therapeutic approaches are limited. There is an urgent need to develop new CMT models to fill the gaps. -
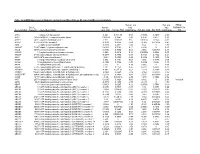
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

T-, B-And NK-Lymphoid, but Not Myeloid Cells Arise from Human
Leukemia (2007) 21, 311–319 & 2007 Nature Publishing Group All rights reserved 0887-6924/07 $30.00 www.nature.com/leu ORIGINAL ARTICLE T-, B- and NK-lymphoid, but not myeloid cells arise from human CD34 þ CD38ÀCD7 þ common lymphoid progenitors expressing lymphoid-specific genes I Hoebeke1,3, M De Smedt1, F Stolz1,4, K Pike-Overzet2, FJT Staal2, J Plum1 and G Leclercq1 1Department of Clinical Chemistry, Microbiology and Immunology, Ghent University Hospital, Ghent, Belgium and 2Department of Immunology, Erasmus University Medical Center, Rotterdam, The Netherlands Hematopoietic stem cells in the bone marrow (BM) give rise to share a direct common progenitor either, as CLPs were not all blood cells. According to the classic model of hematopoi- found in the fetal liver.5 Instead, fetal B and T cells would esis, the differentiation paths leading to the myeloid and develop through B/myeloid and T/myeloid intermediates. lymphoid lineages segregate early. A candidate ‘common 6 lymphoid progenitor’ (CLP) has been isolated from The first report of a human CLP came from Galy et al. who À þ CD34 þ CD38À human cord blood cells based on CD7 expres- showed that a subpopulation of adult and fetal BM Lin CD34 sion. Here, we confirm the B- and NK-differentiation potential of cells expressing the early B- and T-cell marker CD10 is not þ À þ CD34 CD38 CD7 cells and show in addition that this capable of generating monocytic, granulocytic, erythroid or population has strong capacity to differentiate into T cells. As megakaryocytic cells, but can differentiate into dendritic cells, CD34 þ CD38ÀCD7 þ cells are virtually devoid of myeloid B, T and NK cells.