STAT 3900/4950 Homework/Lab 5 Spring, 2015
Question #1
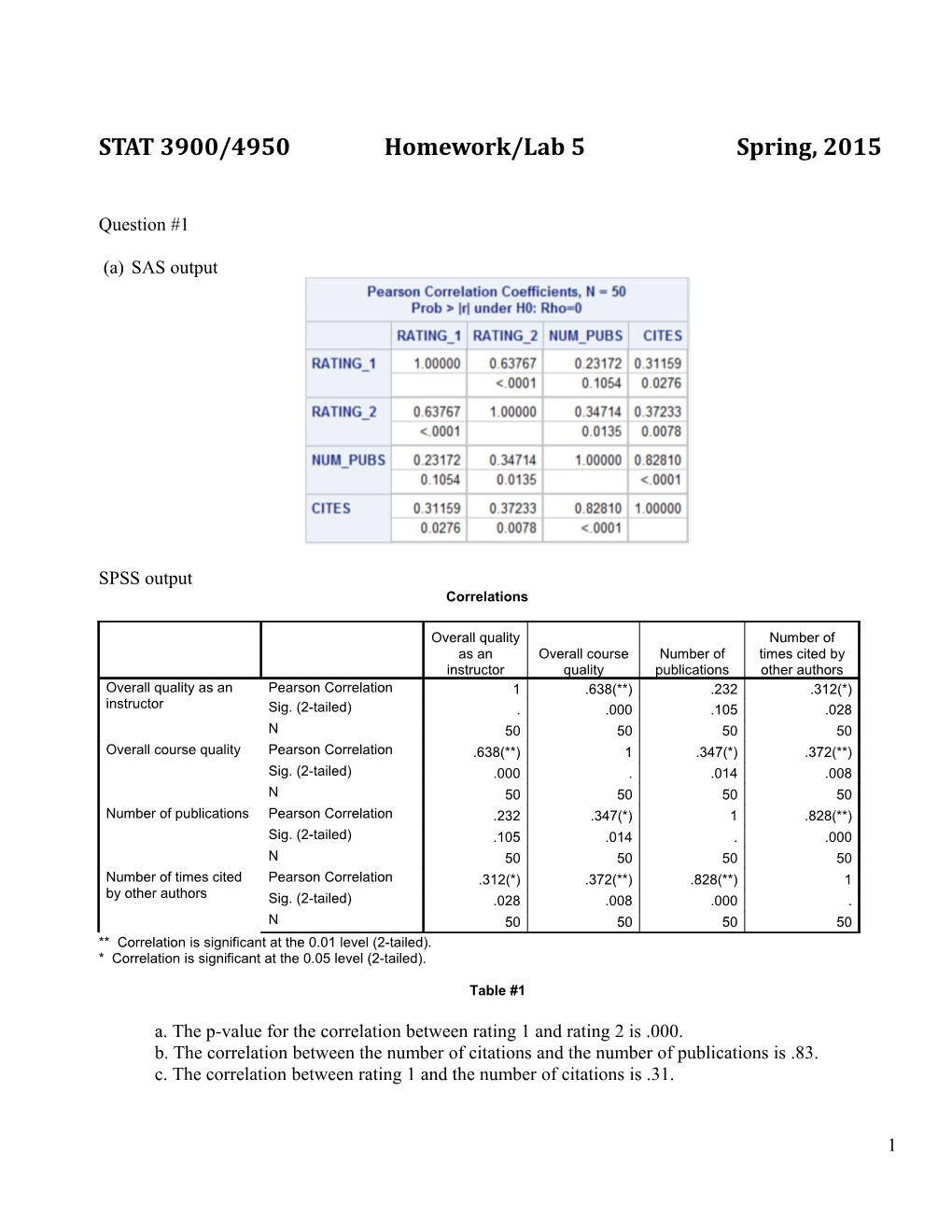
(a) SAS output
SPSS output Correlations
Overall quality Number of as an Overall course Number of times cited by instructor quality publications other authors Overall quality as an Pearson Correlation 1 .638(**) .232 .312(*) instructor Sig. (2-tailed) . .000 .105 .028 N 50 50 50 50 Overall course quality Pearson Correlation .638(**) 1 .347(*) .372(**) Sig. (2-tailed) .000 . .014 .008 N 50 50 50 50 Number of publications Pearson Correlation .232 .347(*) 1 .828(**) Sig. (2-tailed) .105 .014 . .000 N 50 50 50 50 Number of times cited Pearson Correlation .312(*) .372(**) .828(**) 1 by other authors Sig. (2-tailed) .028 .008 .000 . N 50 50 50 50 ** Correlation is significant at the 0.01 level (2-tailed). * Correlation is significant at the 0.05 level (2-tailed).
Table #1
a. The p-value for the correlation between rating 1 and rating 2 is .000. b. The correlation between the number of citations and the number of publications is .83. c. The correlation between rating 1 and the number of citations is .31.
1 (b). The scatterplot, Figure 1 shows that the relationship between the number of articles published and the overall quality of the instructor seems to be increasing but non-linear.
50 s
n 40 o i t a c i l 30 b u p
f o
20 r e b m
u 10 N
0
2.50 3.00 3.50 4.00 4.50 5.00 Overall quality as an instructor Figure #1
(c). The SAS (or SPSS) output gives us:
The regression line of the overall quality of the instructor (rating_1) on the number of articles published (num_pubs) is (average) rating_1 = 4.065 + 0.012 num_pubs. Interpret the slope: The overall quality of the instructor will increase 0.012 on average for every additional article he/she published.
Check normality and equal variances of residuals:
Overall, the assumptions of SLR model do not hold.
Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.917677 Pr < W 0.0019 Kolmogorov-Smirnov D 0.139171 Pr > D 0.0167 Cramer-von Mises W-Sq 0.213743 Pr > W-Sq <0.0050 Anderson-Darling A-Sq 1.346131 Pr > A-Sq <0.0050
2 Based on the normality plot and the p-values of normality tests (all < 0.05), the distribution of residuals is significantly different from a normal distribution.
From the residual plot, there is no obvious pattern except a few mild outliers at the bottom.
3 (d). (STAT 3900 only) . . .
l l a r e v O . . .
l l a r e v O . . .
r e b m u N . . .
r e b m u N Overall quality as an instructorNumber of publications Overall course Numberquality of times cited by other authors
(e). Correlation coefficients were computed among four variables. These variables were overall instructor quality, overall course quality, number of publications, and number of citations. The results of the correlational analyses presented in Table 1 show that 5 out of the 6 correlations were statistically significant (at significance level of 5%) and were greater than or equal to 0.35. The correlation between overall instructor quality and number of publications was low and not significant, which indicates that the large number of publications of an instructor does not imply he/she is also a great teacher. In addition, the results show that the relatively stronger relationship (r > 0.6) were between overall instructor quality (0.64) and overall course quality and between number of publications and number of citations (0.83). That is, the rating for course tends to be higher when the rating for the instructor gets higher. Also the more publications implies more citations.
4 Question #2
(a). SAS output
SPSS output : Correlation Matrix
X Z Y X Pearson 1 -.975(**) .965(**) Correlation Sig. (2-tailed) . .005 .008 N 5 5 5 Z Pearson -.975(**) 1 -.963(**) Correlation Sig. (2-tailed) .005 . .008 N 5 5 5 Y Pearson .965(**) -.963(**) 1 Correlation Sig. (2-tailed) .008 .008 . N 5 5 5 ** Correlation is significant at the 0.01 level (2-tailed).
The correlation between X and Y is .965. It is significant as its p-value is .008 less than 0.05, so X and Y are linearly associated. The correlation between X and Z is -.975. It is significant as its p-value is .005 less than 0.05, so X and Z are linearly associated. Both pairs are significantly linearly associated.
(b).
5 (c). SAS output:
SPSS output:
Coefficientsa
Unstandardized Standardized Coefficients Coefficients Model B Std. Error Beta t Sig. 1 (Constant) .789 1.259 .627 .575 X 1.524 .239 .965 6.382 .008 a. Dependent Variable: Y The regression line of Y on X is Y=.789 + 1.524X. The slope is 1.524 and the intercept is .789. The intercept is not significantly different from zero (p-value is 0.575) but the slope is significantly different from zero (p-value is 0.008).
(d). The linear regression line does fit the data well because adjusted R-square is large (0.909 >> 0.75).
Adjusted R Std. Error of Model R R Square Square the Estimate 1 .965(a) .931 .909 1.37607 a Predictors: (Constant), X
Assumption checking: SAS plots:
6 Checking normality: Figure 1
The points in the normal probability plot of standardized residuals (Figure 1) are more or less around a line, and so it is reasonable to assume normality of residuals. A normality test for residuals has the same conclusion (p-value > 0.05).
Checking equal variances: Figure 2
The residual plot (Figure 2) shows no pattern. Therefore, it is reasonable to assume equal variances of residuals at different X values.
(e). Fit the model: LY b0 b1 X error
7 Table 2:
From Table 2, the fitted model is: the fitted LY 0.89 0.22X . Both the intercept and the slope coefficient are significantly different from zero, with p-values of 0.0135 and 0.0065, respectively.
The linear regression line does fit the data well because adjusted R-square is large (0.919 >> 0.75). SAS output:
Assumption Checking: SAS plots:
From Left to Right: Figures 2.5, 2.6, 2.7 Equal Variance: Figure 2.6 shows that no standardized residual is greater than ±3 (no outliers). Due to the small sample size, we cannot really judge whether or not the variances are equal. But we can observe a non-linear pattern from this residual plot, which indicates the lack of fit of our model. Normality: Figure 2.7 shows a normality plot. The residuals fall along the line nicely. There is no indication of non-normality. The Normality tests indicate the same results too (p-value > 0.05). However, with 5 observations we are unlikely to reject normality, even if it is violated.
SPSS has the same plots as shown in part (d).
8 (f). Compare their Adjusted R-square values: From model (d) Model Summary
Adjusted R Std. Error of Model R R Square Square the Estimate 1 .965(a) .931 .909 1.37607 a Predictors: (Constant), X
From model (e)
R-Sq = 93.9% R-Sq(adj) = 91.9%
I would use model (d) although the adjusted R-square of model (e) is slightly larger because using the original scale of response variable (Y here) is preferred and the residual plot of model (e) shows a bit curved.
SAS Code: Question 1 4.23 4.68 14 54 4.08 4.32 5 31 DATA QUALITY; 4.33 3.89 0 0 INPUT RATING_1 RATING_2 NUM_PUBS CITES; 3.06 3.30 17 98 DATALINES; 4.12 3.62 1 5 4.87 2.78 0 0 4.30 4.17 25 115 4.47 4.85 14 90 4.50 4.23 1 21 4.86 3.86 1 2 4.33 3.95 3 35 3.27 3.75 1 32 4.40 4.13 11 118 4.80 4.37 11 53 4.33 4.10 5 49 3.94 4.37 3 12 4.26 3.78 0 0 4.61 3.61 16 108 3.76 4.21 8 27 4.32 4.77 1 4 4.34 4.22 12 64 4.46 4.34 13 82 4.83 3.83 10 22 4.64 4.34 1 19 3.02 2.00 0 0 3.20 3.03 0 0 4.88 3.88 3 154 4.30 4.44 7 51 4.31 4.46 34 64 4.98 4.58 49 274 4.07 3.75 40 137 2.98 2.52 3 8 2.96 2.82 1 23 4.50 4.20 1 17 4.88 3.88 1 16 4.53 4.15 1 8 3.36 3.76 15 37 3.55 2.76 0 0 4.14 4.60 11 69 4.00 4.45 2 28 ; 3.82 4.23 0 0 RUN; 4.13 3.91 1 27 4.97 4.83 37 189 **PART (a) CORRELATION ANALYSIS; 4.12 3.82 0 0 PROC CORR DATA = QUALITY; 4.82 4.77 19 102 TITLE "CORRELATION MATRIX"; 3.12 2.89 0 0 VAR RATING_1 RATING_2 NUM_PUBS CITES; 4.57 4.21 1 13 RUN; 3.00 2.86 10 63 4.89 3.89 3 18 **PART (b) SCATTER PLOT; 4.14 4.39 8 137 SYMBOL COLOR = RED VALUE = DOT;
9 **Which pair(s) is significantly linearly associated? Identify PROC GPLOT DATA = QUALITY; the p-values to support your answer; TITLE "SCATTERPLOT OF INSTRUCTOR QUALITY AND PROC CORR DATA = Q2; ARTICLES PUBLISHED"; VAR X Y Z; PLOT RATING_1*NUM_PUBS; RUN; RUN; **PART (b) SCATTERPLOT Y vs X WITH A REG LINE; **PART (c) REGRESSION LINE OF RATING_1 (Y) ON **PART (c) COMPUTE OF REGRESSION LINE OF Y = X; NUM_PUBS (X); PROC REG DATA = Q2; PROC REG DATA = QUALITY; TITLE "SCATTERPLOT OF Y AND X WITH REGRESSION TITLE "REGRESSION: INSTRUCTOR QUALITY ON ARTICLES LINE"; PUBLISHED"; MODEL Y = X; MODEL RATING_1 = NUM_PUBS; PLOT Y*X; OUTPUT OUT= GRAPH RUN; P=PREDICTED STUDENT=ST_RES **PART (d) DOES THE REGRESSION LINE FIT WELL? (R^2 > R=RESIDUAL; 0.75); RUN; **CHECK ASSUMPTIONS;
**GRAPHICAL SUMMARIES OF RESIDUALS TO CHECK **PART (e) CREATE LOG(Y). REPEAT (c) AND (d); ASSUMPTIONS; PROC REG DATA = Q2; PROC UNIVARIATE DATA=GRAPH NORMAL PLOT; TITLE "SCATTERPLOT OF LOG(Y) AND X WITH REGRESSION TITLE "NORMALITY CHECKING"; LINE"; VAR RESIDUAL; MODEL LY = X; RUN; PLOT LY*X; RUN; SYMBOL VALUE=DOT COLOR=RED I=R;
PROC GPLOT DATA=GRAPH; TITLE "RESIDUALS VERSUS PREDICTED"; PLOT ST_RES * PREDICTED; RUN;
Question 2:
DATA Q2; INPUT X Y Z; LY = LOG(Y); DATALINES; 1 3 15 7 13 7 8 12 5 3 4 14 4 7 10 ; RUN;
PROC PRINT DATA = Q2; RUN;
**PART (a) Create a correlation matriX. **Identify the Pearson correlation coefficients between X and Y, X and Z. 10