SPSS review 1 (for the Ed401A on Oct. 10, 2001) Yue (Melody)
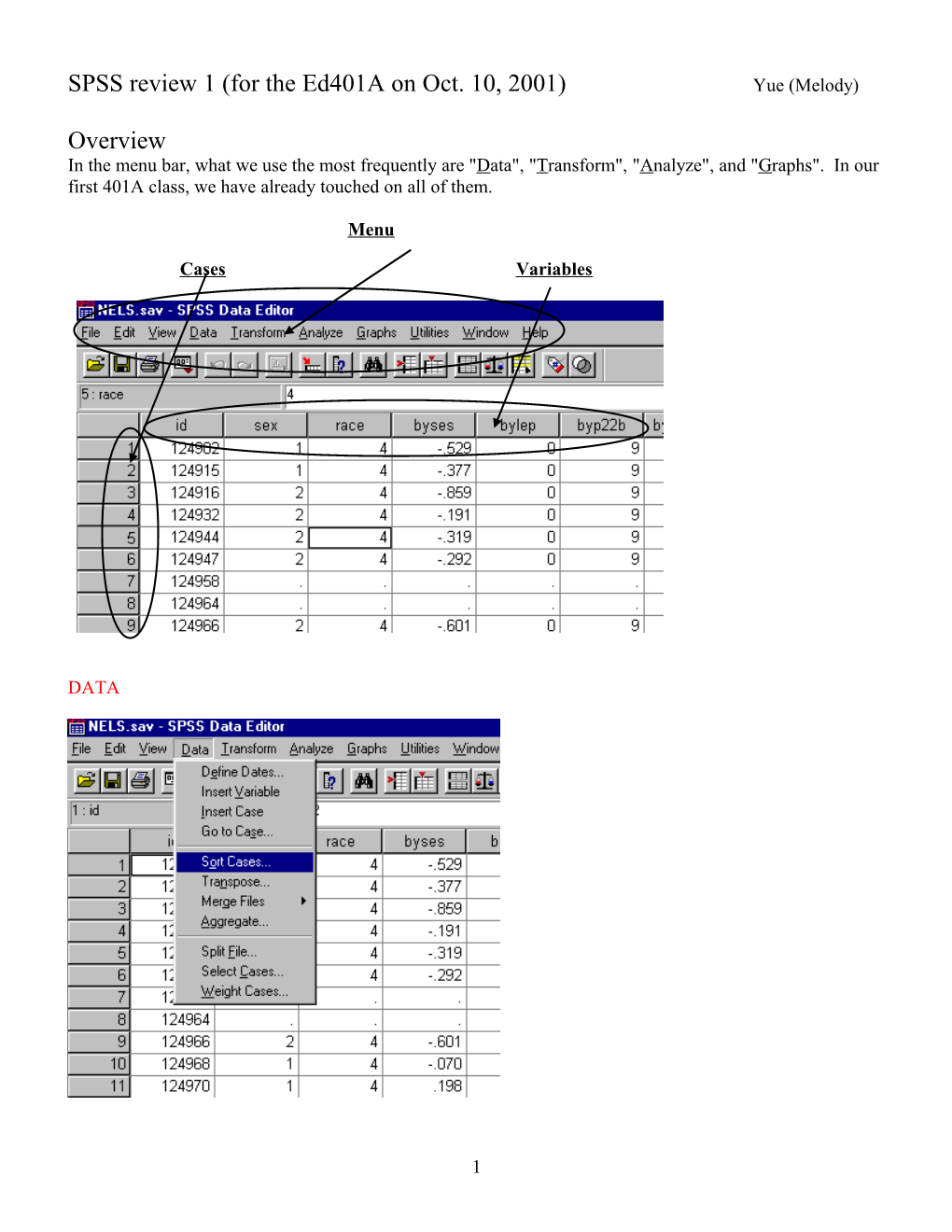
Overview In the menu bar, what we use the most frequently are "Data", "Transform", "Analyze", and "Graphs". In our first 401A class, we have already touched on all of them.
Menu
Cases Variables
DATA
1 "Data" can help organize the whole data we are working on. Here are several most frequently used commands and their functions. "Sort" can help present data based on one variable in either ascending or descending order. We have sorted our mock data by "id" and "grade" in class. "score" is a nice command for small data, since it can present a neat picture of it. For large data, "sort" is not that useful, no matter how the data is organized, you cannot see its "head" and "tail".:( "Merge Files" can help put two data together, either by adding more cases or variables. We might talk about it later. You can also try it yourself if you are interested. "Split File" can help separate data into groups. After you split a data, even though the separated data seem to be still in one data, all the following analysis will deal with different groups separately. We have experienced that in class after we split our NEL data into male and female. "Select cases" can help us select the data according to your need. Say, if you just need the cases without missing value or you just need the student above certain grade, "Select cases" can help you easily do that.
TRANSFORM
Compared with "Data", "Transform" zooms in focus to variables instead of whole data. In our class, we have talked about two most frequently used commands, "Compute" and "Recode". "Compute" can help do calculation and create new variables. In class, we got the mean of pretest and post score, "MEANSCR". Similarly, we can do other calculations, with the operators or functions supplied by SPSS. "Recode" is another common way to change variables. We can put changed variables in the original variable or create a new variable to hold the new values. Shortcoming for the first one is that, once you recode it into the same variable and save data, you will lose that variable's original values forever, because they are overwritten by the new ones. So the safe way to do it is to create a new variable for the recoded value.
ANALYZE
2 It is the most important part, the core, of SPSS, that is also the most complex and challenging part of SPSS. If you grasp all the commands here, you will be not only a very cool SPSS expert but a statistics expert,:) because the application of the commands here and the interpretation of the output obtained from those commands are based on understanding of statistics. In our first class, we talked about "Descriptive Statistics". It can help address the issues related to descriptive statistics. Later on, we will use more commands with the progress of class.
Some commands we used in class
Logging data: Create variables, label them, label the value of the variables. I think most of you have already got it.
Sort (cases):
In Sort Case window, choose the variable you want to base on and transfer it to the sort by window. You can also choose sort it in either ascending or descending order of a variable you want, say "grade". Click OK.
Recode (variable):
3 As what we mentioned in the overview part, we don't want to overwrite the original variable. Therefore, generally, we will recode variable into different variables. (Personally, I like to insert the new variable behind the original one to get a clear picture of them, which can be realized by step 1 and step 2 as follows. If you don't care where the new variable is, you can skip the first two steps and go to step 3 directly. SPSS will automatically put the new variable behind the last one, eg. "post" in our data.)
Step 1: Insert new variable behind the old one. Choose the column behind the original one, click the variable, right click to insert a new column (variable).
Step 2: Name the new variable inserted.
Change to "Variable View", give the inserted variable with a proper name. Here we name new variable "mature", according to the requirement in hunter's handout.
Step 3: Recode the original variable After the new variable is created. We can put new values in it. Follow the next several procedures:
4 Fill in the output variable and its label. Then click button.
5 Fill in the old value and new value, then click button. Repeat it until you put in all the values that you want to recode. In our example, we recode grade 9 (freshman) and grade 10 (sophomores) as "0" -- "not mature"; grade 11 (juniors) and grade 12 (seniors) as "1" -- "mature".
Then click . You will go back the last interface we met. After you make sure that you do want recode the original variable into the new one, click . Friendly and careful SPSS will warn you by the picture as below. If you are sure that you did not make mistake, click on the warning board. Then another on the recode board. See what happened in your data. Got it? :)
Compute
Function
Just fill in the window as above and click "OK". Easily, you will get the mean score ("meanscr" in data) of pre-test and post-test. Similarly, you can also use other operators and functions when you need.
Frequency
6 Generally, we only do frequency analysis on nominal and ordinal variables. If we do it on continuous variables of a large size data, we usually group them (use "recode") first, then do frequency on those groups. Otherwise, we will get endless but meaningless data. :( In our class, we analyzed frequency of race. Put "race" into the variable window of frequency. If you also want to get some charts for it, say "pie" or "bar", click "chart". By clicking statistics, you can get all the choices for statistics. I believe you can figure out what to do next. :)
7
Split (data)
In the split interface, check "Compare groups", then choose the variable based on which you want to group the data, transfer it into "Groups Based on" window. Click OK. As we said in the overview, after you splitted the data, all the analysis will be done in the two groups separately, output will also be organized separately. If you want to recover your data into a whole one, just come back to the split command and check back "Analyze all cases, do not create groups". Who is the troublemaker, who will be the trouble solver. Does it make sense?
Graph:
8 Even though some pictures can be drawn in "Analyze", "Graph" is an experts of pictures. "Graph" is not hard to handle. The challenge for it is: "what kind of graph should we use for different type of variables?" and "how should we interpret the output according to our knowledge and experience?" Later on, we will deal with more of them.
9