Pre-Trained Models for Natural Language Processing: a Survey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Malware Classification with BERT
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 5-25-2021 Malware Classification with BERT Joel Lawrence Alvares Follow this and additional works at: https://scholarworks.sjsu.edu/etd_projects Part of the Artificial Intelligence and Robotics Commons, and the Information Security Commons Malware Classification with Word Embeddings Generated by BERT and Word2Vec Malware Classification with BERT Presented to Department of Computer Science San José State University In Partial Fulfillment of the Requirements for the Degree By Joel Alvares May 2021 Malware Classification with Word Embeddings Generated by BERT and Word2Vec The Designated Project Committee Approves the Project Titled Malware Classification with BERT by Joel Lawrence Alvares APPROVED FOR THE DEPARTMENT OF COMPUTER SCIENCE San Jose State University May 2021 Prof. Fabio Di Troia Department of Computer Science Prof. William Andreopoulos Department of Computer Science Prof. Katerina Potika Department of Computer Science 1 Malware Classification with Word Embeddings Generated by BERT and Word2Vec ABSTRACT Malware Classification is used to distinguish unique types of malware from each other. This project aims to carry out malware classification using word embeddings which are used in Natural Language Processing (NLP) to identify and evaluate the relationship between words of a sentence. Word embeddings generated by BERT and Word2Vec for malware samples to carry out multi-class classification. BERT is a transformer based pre- trained natural language processing (NLP) model which can be used for a wide range of tasks such as question answering, paraphrase generation and next sentence prediction. However, the attention mechanism of a pre-trained BERT model can also be used in malware classification by capturing information about relation between each opcode and every other opcode belonging to a malware family. -
Foundations of Computational Science August 29-30, 2019
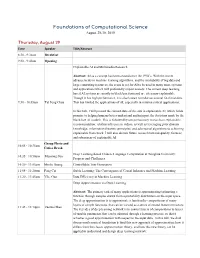
Foundations of Computational Science August 29-30, 2019 Thursday, August 29 Time Speaker Title/Abstract 8:30 - 9:30am Breakfast 9:30 - 9:40am Opening Explainable AI and Multimedia Research Abstract: AI as a concept has been around since the 1950’s. With the recent advancements in machine learning algorithms, and the availability of big data and large computing resources, the scene is set for AI to be used in many more systems and applications which will profoundly impact society. The current deep learning based AI systems are mostly in black box form and are often non-explainable. Though it has high performance, it is also known to make occasional fatal mistakes. 9:30 - 10:05am Tat Seng Chua This has limited the applications of AI, especially in mission critical applications. In this talk, I will present the current state-of-the arts in explainable AI, which holds promise to helping humans better understand and interpret the decisions made by the black-box AI models. This is followed by our preliminary research on explainable recommendation, relation inference in videos, as well as leveraging prior domain knowledge, information theoretic principles, and adversarial algorithms to achieving explainable framework. I will also discuss future research towards quality, fairness and robustness of explainable AI. Group Photo and 10:05 - 10:35am Coffee Break Deep Learning-based Chinese Language Computation at Tsinghua University: 10:35 - 10:50am Maosong Sun Progress and Challenges 10:50 - 11:05am Minlie Huang Controllable Text Generation 11:05 - 11:20am Peng Cui Stable Learning: The Convergence of Causal Inference and Machine Learning 11:20 - 11:45am Yike Guo Data Efficiency in Machine Learning Deep Approximation via Deep Learning Abstract: The primary task of many applications is approximating/estimating a function through samples drawn from a probability distribution on the input space. -

Bros:Apre-Trained Language Model for Understanding Textsin Document
Under review as a conference paper at ICLR 2021 BROS: A PRE-TRAINED LANGUAGE MODEL FOR UNDERSTANDING TEXTS IN DOCUMENT Anonymous authors Paper under double-blind review ABSTRACT Understanding document from their visual snapshots is an emerging and chal- lenging problem that requires both advanced computer vision and NLP methods. Although the recent advance in OCR enables the accurate extraction of text seg- ments, it is still challenging to extract key information from documents due to the diversity of layouts. To compensate for the difficulties, this paper introduces a pre-trained language model, BERT Relying On Spatiality (BROS), that represents and understands the semantics of spatially distributed texts. Different from pre- vious pre-training methods on 1D text, BROS is pre-trained on large-scale semi- structured documents with a novel area-masking strategy while efficiently includ- ing the spatial layout information of input documents. Also, to generate structured outputs in various document understanding tasks, BROS utilizes a powerful graph- based decoder that can capture the relation between text segments. BROS achieves state-of-the-art results on four benchmark tasks: FUNSD, SROIE*, CORD, and SciTSR. Our experimental settings and implementation codes will be publicly available. 1 INTRODUCTION Document intelligence (DI)1, which understands industrial documents from their visual appearance, is a critical application of AI in business. One of the important challenges of DI is a key information extraction task (KIE) (Huang et al., 2019; Jaume et al., 2019; Park et al., 2019) that extracts struc- tured information from documents such as financial reports, invoices, business emails, insurance quotes, and many others. -

Computational Science and Engineering
Computational Science and Engineering, PhD College of Engineering Graduate Coordinator: TBA Email: Phone: Department Chair: Marwan Bikdash Email: [email protected] Phone: 336-334-7437 The PhD in Computational Science and Engineering (CSE) is an interdisciplinary graduate program designed for students who seek to use advanced computational methods to solve large problems in diverse fields ranging from the basic sciences (physics, chemistry, mathematics, etc.) to sociology, biology, engineering, and economics. The mission of Computational Science and Engineering is to graduate professionals who (a) have expertise in developing novel computational methodologies and products, and/or (b) have extended their expertise in specific disciplines (in science, technology, engineering, and socioeconomics) with computational tools. The Ph.D. program is designed for students with graduate and undergraduate degrees in a variety of fields including engineering, chemistry, physics, mathematics, computer science, and economics who will be trained to develop problem-solving methodologies and computational tools for solving challenging problems. Research in Computational Science and Engineering includes: computational system theory, big data and computational statistics, high-performance computing and scientific visualization, multi-scale and multi-physics modeling, computational solid, fluid and nonlinear dynamics, computational geometry, fast and scalable algorithms, computational civil engineering, bioinformatics and computational biology, and computational physics. Additional Admission Requirements Master of Science or Engineering degree in Computational Science and Engineering (CSE) or in science, engineering, business, economics, technology or in a field allied to computational science or computational engineering field. GRE scores Program Outcomes: Students will demonstrate critical thinking and ability in conducting research in engineering, science and mathematics through computational modeling and simulations. -

Information Extraction Based on Named Entity for Tourism Corpus
Information Extraction based on Named Entity for Tourism Corpus Chantana Chantrapornchai Aphisit Tunsakul Dept. of Computer Engineering Dept. of Computer Engineering Faculty of Engineering Faculty of Engineering Kasetsart University Kasetsart University Bangkok, Thailand Bangkok, Thailand [email protected] [email protected] Abstract— Tourism information is scattered around nowa- The ontology is extracted based on HTML web structure, days. To search for the information, it is usually time consuming and the corpus is based on WordNet. For these approaches, to browse through the results from search engine, select and the time consuming process is the annotation which is to view the details of each accommodation. In this paper, we present a methodology to extract particular information from annotate the type of name entity. In this paper, we target at full text returned from the search engine to facilitate the users. the tourism domain, and aim to extract particular information Then, the users can specifically look to the desired relevant helping for ontology data acquisition. information. The approach can be used for the same task in We present the framework for the given named entity ex- other domains. The main steps are 1) building training data traction. Starting from the web information scraping process, and 2) building recognition model. First, the tourism data is gathered and the vocabularies are built. The raw corpus is used the data are selected based on the HTML tag for corpus to train for creating vocabulary embedding. Also, it is used building. The data is used for model creation for automatic for creating annotated data. -

Artificial Intelligence Research For
Charles Xie ([email protected]) is a senior scientist who works at the inter- section between computational science and learning science. Artificial Intelligence research for engineering design By Charles Xie Imagine a high school classroom in 2030. AI is one of the three most promising areas for which Bill Gates Students are challenged to design an said earlier this year he would drop out of college again if he were a young student today. The victory of Google’s AlphaGo against engineering system that meets the needs of a top human Go player in 2016 was a landmark in the history of their community. They work with advanced AI. The game of Go is considered a difficult challenge because computer-aided design (CAD) software that the number of legal positions on a 19×19 grid is estimated to be leverages the power of scientific simulation, 2×10170, far more than the total number of atoms in the observ- mixed reality, and cloud computing. Every able universe combined (1082). While AlphaGo may be only a cool tool needed to complete an engineering type of weak AI that plays Go at present, scientists believe that its development will engender technologies that eventually find design project is seamlessly integrated into applications in other fields. the CAD platform to streamline the learning process. But the most striking capability of Performance modeling the software is its ability to act like a mentor (e.g., simulation-based analysis) who has all the knowledge about the design project to answer questions, learns from all the successful or unsuccessful solutions ever Evaluator attempted by human designers or computer agents, adapts to the needs of each student based on experience interacting with all sorts of designers, inspires students to explore creative ideas, and, most importantly, remains User Ideator responsive all the time without ever running out of steam. -

NLP with BERT: Sentiment Analysis Using SAS® Deep Learning and Dlpy Doug Cairns and Xiangxiang Meng, SAS Institute Inc
Paper SAS4429-2020 NLP with BERT: Sentiment Analysis Using SAS® Deep Learning and DLPy Doug Cairns and Xiangxiang Meng, SAS Institute Inc. ABSTRACT A revolution is taking place in natural language processing (NLP) as a result of two ideas. The first idea is that pretraining a deep neural network as a language model is a good starting point for a range of NLP tasks. These networks can be augmented (layers can be added or dropped) and then fine-tuned with transfer learning for specific NLP tasks. The second idea involves a paradigm shift away from traditional recurrent neural networks (RNNs) and toward deep neural networks based on Transformer building blocks. One architecture that embodies these ideas is Bidirectional Encoder Representations from Transformers (BERT). BERT and its variants have been at or near the top of the leaderboard for many traditional NLP tasks, such as the general language understanding evaluation (GLUE) benchmarks. This paper provides an overview of BERT and shows how you can create your own BERT model by using SAS® Deep Learning and the SAS DLPy Python package. It illustrates the effectiveness of BERT by performing sentiment analysis on unstructured product reviews submitted to Amazon. INTRODUCTION Providing a computer-based analog for the conceptual and syntactic processing that occurs in the human brain for spoken or written communication has proven extremely challenging. As a simple example, consider the abstract for this (or any) technical paper. If well written, it should be a concise summary of what you will learn from reading the paper. As a reader, you expect to see some or all of the following: • Technical context and/or problem • Key contribution(s) • Salient result(s) If you were tasked to create a computer-based tool for summarizing papers, how would you translate your expectations as a reader into an implementable algorithm? This is the type of problem that the field of natural language processing (NLP) addresses. -

Knowledge-Powered Deep Learning for Word Embedding
Knowledge-Powered Deep Learning for Word Embedding Jiang Bian, Bin Gao, and Tie-Yan Liu Microsoft Research {jibian,bingao,tyliu}@microsoft.com Abstract. The basis of applying deep learning to solve natural language process- ing tasks is to obtain high-quality distributed representations of words, i.e., word embeddings, from large amounts of text data. However, text itself usually con- tains incomplete and ambiguous information, which makes necessity to leverage extra knowledge to understand it. Fortunately, text itself already contains well- defined morphological and syntactic knowledge; moreover, the large amount of texts on the Web enable the extraction of plenty of semantic knowledge. There- fore, it makes sense to design novel deep learning algorithms and systems in order to leverage the above knowledge to compute more effective word embed- dings. In this paper, we conduct an empirical study on the capacity of leveraging morphological, syntactic, and semantic knowledge to achieve high-quality word embeddings. Our study explores these types of knowledge to define new basis for word representation, provide additional input information, and serve as auxiliary supervision in deep learning, respectively. Experiments on an analogical reason- ing task, a word similarity task, and a word completion task have all demonstrated that knowledge-powered deep learning can enhance the effectiveness of word em- bedding. 1 Introduction With rapid development of deep learning techniques in recent years, it has drawn in- creasing attention to train complex and deep models on large amounts of data, in order to solve a wide range of text mining and natural language processing (NLP) tasks [4, 1, 8, 13, 19, 20]. -

Recurrent Neural Network Based Language Model
INTERSPEECH 2010 Recurrent neural network based language model Toma´sˇ Mikolov1;2, Martin Karafiat´ 1, Luka´sˇ Burget1, Jan “Honza” Cernockˇ y´1, Sanjeev Khudanpur2 1Speech@FIT, Brno University of Technology, Czech Republic 2 Department of Electrical and Computer Engineering, Johns Hopkins University, USA fimikolov,karafiat,burget,[email protected], [email protected] Abstract INPUT(t) OUTPUT(t) A new recurrent neural network based language model (RNN CONTEXT(t) LM) with applications to speech recognition is presented. Re- sults indicate that it is possible to obtain around 50% reduction of perplexity by using mixture of several RNN LMs, compared to a state of the art backoff language model. Speech recognition experiments show around 18% reduction of word error rate on the Wall Street Journal task when comparing models trained on the same amount of data, and around 5% on the much harder NIST RT05 task, even when the backoff model is trained on much more data than the RNN LM. We provide ample empiri- cal evidence to suggest that connectionist language models are superior to standard n-gram techniques, except their high com- putational (training) complexity. Index Terms: language modeling, recurrent neural networks, speech recognition CONTEXT(t-1) 1. Introduction Figure 1: Simple recurrent neural network. Sequential data prediction is considered by many as a key prob- lem in machine learning and artificial intelligence (see for ex- ample [1]). The goal of statistical language modeling is to plex and often work well only for systems based on very limited predict the next word in textual data given context; thus we amounts of training data. -

An Evaluation of Tensorflow As a Programming Framework for HPC Applications
DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2018 An Evaluation of TensorFlow as a Programming Framework for HPC Applications WEI DER CHIEN KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE An Evaluation of TensorFlow as a Programming Framework for HPC Applications WEI DER CHIEN Master in Computer Science Date: August 28, 2018 Supervisor: Stefano Markidis Examiner: Erwin Laure Swedish title: En undersökning av TensorFlow som ett utvecklingsramverk för högpresterande datorsystem School of Electrical Engineering and Computer Science iii Abstract In recent years, deep-learning, a branch of machine learning gained increasing popularity due to their extensive applications and perfor- mance. At the core of these application is dense matrix-matrix multipli- cation. Graphics Processing Units (GPUs) are commonly used in the training process due to their massively parallel computation capabili- ties. In addition, specialized low-precision accelerators have emerged to specifically address Tensor operations. Software frameworks, such as TensorFlow have also emerged to increase the expressiveness of neural network model development. In TensorFlow computation problems are expressed as Computation Graphs where nodes of a graph denote operation and edges denote data movement between operations. With increasing number of heterogeneous accelerators which might co-exist on the same cluster system, it became increasingly difficult for users to program efficient and scalable applications. TensorFlow provides a high level of abstraction and it is possible to place operations of a computation graph on a device easily through a high level API. In this work, the usability of TensorFlow as a programming framework for HPC application is reviewed. -

A Brief Introduction to Mathematical Optimization in Julia (Part 1) What Is Julia? and Why Should I Care?
A Brief Introduction to Mathematical Optimization in Julia (Part 1) What is Julia? And why should I care? Carleton Coffrin Advanced Network Science Initiative https://lanl-ansi.github.io/ Managed by Triad National Security, LLC for the U.S. Department of Energy’s NNSA LA-UR-21-20278 Warning: This is not a technical talk! 9/25/2019 Julia_prog_language.svg What is Julia? • A “new” programming language developed at MIT • nearly 10 years old (appeared around 2012) • Julia is a high-level, high-performance, dynamic programming language • free and open source • The Creator’s Motivation • build the next-generation of programming language for numerical analysis and computational science • Solve the “two-language problem” (you havefile:///Users/carleton/Downloads/Julia_prog_language.svg to choose between 1/1 performance and implementation simplicity) Who is using Julia? Julia is much more than an academic curiosity! See https://juliacomputing.com/ Why Julia? Application9/25/2019 Julia_prog_language.svg Needs Data Scince Numerical Scripting Computing Automation 9/25/2019 Thin-Border-Logo-Text Julia Data Differential Equations file:///Users/carleton/Downloads/Julia_prog_language.svg 1/1 Deep Learning Mathematical Optimization High Performance https://camo.githubusercontent.com/31d60f762b44d0c3ea47cc16b785e042104a6e03/68747470733a2f2f7777772e6a756c69616f70742e6f72672f696d616765732f6a7… 1/1 -

Unified Language Model Pre-Training for Natural
Unified Language Model Pre-training for Natural Language Understanding and Generation Li Dong∗ Nan Yang∗ Wenhui Wang∗ Furu Wei∗† Xiaodong Liu Yu Wang Jianfeng Gao Ming Zhou Hsiao-Wuen Hon Microsoft Research {lidong1,nanya,wenwan,fuwei}@microsoft.com {xiaodl,yuwan,jfgao,mingzhou,hon}@microsoft.com Abstract This paper presents a new UNIfied pre-trained Language Model (UNILM) that can be fine-tuned for both natural language understanding and generation tasks. The model is pre-trained using three types of language modeling tasks: unidirec- tional, bidirectional, and sequence-to-sequence prediction. The unified modeling is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction conditions on. UNILM compares favorably with BERT on the GLUE benchmark, and the SQuAD 2.0 and CoQA question answering tasks. Moreover, UNILM achieves new state-of- the-art results on five natural language generation datasets, including improving the CNN/DailyMail abstractive summarization ROUGE-L to 40.51 (2.04 absolute improvement), the Gigaword abstractive summarization ROUGE-L to 35.75 (0.86 absolute improvement), the CoQA generative question answering F1 score to 82.5 (37.1 absolute improvement), the SQuAD question generation BLEU-4 to 22.12 (3.75 absolute improvement), and the DSTC7 document-grounded dialog response generation NIST-4 to 2.67 (human performance is 2.65). The code and pre-trained models are available at https://github.com/microsoft/unilm. 1 Introduction Language model (LM) pre-training has substantially advanced the state of the art across a variety of natural language processing tasks [8, 29, 19, 31, 9, 1].