Opengl|D - an Alternative Approach to Multi-User Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half- duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full- duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number /etc/services, a service name range being unassigned. The Stream Control Transmission Protocol database file on Unix-like operating (SCTP) and the Datagram Congestion Control Protocol (DCCP) also systems.[1][2][3][4] use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[5] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[5] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[6] They are used by system processes that provide widely used types of network services. -

List of TCP and UDP Port Numbers 1 List of TCP and UDP Port Numbers
List of TCP and UDP port numbers 1 List of TCP and UDP port numbers This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of host-to-host communications. Originally, these ports number were used by the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), but are also used for the Stream Control Transmission Protocol (SCTP), and the Datagram Congestion Control Protocol (DCCP). SCTP and DCCP services usually use a port number that matches the service of the corresponding TCP or UDP implementation if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Table legend Use Description Color Official Port is registered with IANA for the application white Unofficial Port is not registered with IANA for the application blue Multiple use Multiple applications are known to use this port. yellow Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports. They are used by system processes that provide widely used types of network services. On Unix-like operating systems, a process must execute with superuser privileges to be able to bind a network socket to an IP address using one of the well-known ports. Port TCP UDP Description Status 0 UDP Reserved Official 1 TCP UDP TCP Port Service Multiplexer (TCPMUX) Official [2] [3] -

List of TCP and UDP Port Numbers - Wikipedia, the Free Encyclopedia 08/31/2007 04:24 PM
List of TCP and UDP port numbers - Wikipedia, the free encyclopedia 08/31/2007 04:24 PM List of TCP and UDP port numbers From Wikipedia, the free encyclopedia (Redirected from TCP and UDP port numbers) TCP and UDP are transport protocols used for communication between computers. The IANA is responsible for assigning port numbers to specific uses. Contents 1 Ranges 2 Port lists 2.1 Ports 0 to 1023 2.2 Ports 1024 to 49151 2.3 Ports 49152 to 65535 2.4 Multi cast Adresses 3 References 4 External links Ranges The port numbers are divided into three ranges. The Well Known Ports are those in the range 0–1023. On Unix-like operating systems, opening a port in this range to receive incoming connections requires administrative privileges or possessing of CAP_NET_BIND_SERVICE capability. The Registered Ports are those in the range 1024–49151. The Dynamic and/or Private Ports are those in the range 49152–65535. These ports are not used by any defined application. IANA does not enforce this; it is simply a set of recommended uses. Sometimes ports may be used for different applications or protocols than their official IANA designation. This misuse may, for example, be by a Trojan horse, or alternatively be by a commonly used program that didn't get an IANA registered port or port range. Port lists The tables below indicate a status with the following colors and tags: Official if the application and port combination is in the IANA list of port assignments (http://www.iana.org/assignments/port-numbers) ; Unofficial if the application and port combination is not in the IANA list of port assignments; and Conflict if the port is being used commonly for two applications or protocols. -

Zeszyty Naukowe Wsei Seria: Transport I Informatyka
ZESZYTY NAUKOWE WSEI SERIA: TRANSPORT I INFORMATYKA 7(1/2017) Zeszyty naukowe Wyższej Szkoły ekonomii i Innowacji w Lublinie SERIA: TRANSPORT I INFORMATYKA Rada naukowa: prof. zw. dr hab. inż. Andrzej Niewczas (ITS Warszawa) prof. dr hab. inż. Zdzisław Chłopek (Politechnika Warszawska) dr hab. inż. Tadeusz Dyr (Uniwersytet Technologiczno-Humanistyczny w Radomiu) prof. Tatiana Čorejova (University of Žilina, Słowacja) prof. dr hab. inż. Igor Kabashkin (Transport & Telecommunications Institute, Łotwa) dr hab. inż. Grzegorz Koralewski (WSOWL, Dęblin) prof. dr hab. Aleksander Medvedevs (Transport & Telecommunications Institute, Łotwa) prof. Inga O. Procenko (The Russian Academy of National Economy and Public Service at the President of the Russian Federation) prof. zw. dr hab. inż. Marek Stabrowski (WSEI w Lublinie) prof. George Utekhin (Transport and Telecommunuication Institute. Riga. Latvia) prof. dr hab. inż. David Valis (University of Defence Brno, Republika Czeska) Redakcja: dr inż. Józef Stokłosa (Redaktor Naczelny), mgr Joanna Sidor-Walczak (Sekretarz Redakcji), mgr Marek Szczodrak (Redaktor Techniczny) Redaktorzy tematyczni: prof. dr hab. inż. Jan Kukiełka (Infrastruktura transportu), dr hab. Grzegorz Wójcik (Informatyka), dr hab. inż. Andrzej Marciniak (Modelowanie systemów transportowych), dr inż. Mariusz Walczak (Mechanika, Inżynieria materiałowa) Recenzenci: dr hab. inż. Andrzej Adamkiewicz dr hab. inż. Tadeusz Cisowski, dr hab. inż. Paweł Droździel, prof. dr hab. inż. Henryk Komsta, dr hab. inż. Marianna Jacyna, dr hab. inż. Marek Jaśkiewicz, dr hab. inż. Zofia Jóźwiak, dr hab. inż. Grzegorz Koralewski, prof. dr hab. Anna Križanova, dr hab. inż. Andrzej Marciniak, prof. zw. dr hab. inż. Andrzej Niewczas, prof. dr hab. inż. Marek Opielak, dr hab. inż. Marek Pawełczyk, dr hab. inż. Artur Popko, dr hab. -

Quake III Arena This Page Intentionally Left Blank Focus on Mod Programming for Quake III Arena
Focus on Mod Programming for Quake III Arena This page intentionally left blank Focus on Mod Programming for Quake III Arena Shawn Holmes © 2002 by Premier Press, a division of Course Technology. All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, elec- tronic or mechanical, including photocopying, recording, or by any information stor- age or retrieval system without written permission from Premier Press, except for the inclusion of brief quotations in a review. The Premier Press logo, top edge printing, and related trade dress are trade- marks of Premier Press, Inc. and may not be used without written permis- sion. All other trademarks are the property of their respective owners. Publisher: Stacy L. Hiquet Marketing Manager: Heather Hurley Managing Editor: Sandy Doell Acquisitions Editor: Emi Smith Series Editor: André LaMothe Project Editor: Estelle Manticas Editorial Assistant: Margaret Bauer Technical Reviewer: Robi Sen Technical Consultant: Jared Larson Copy Editor: Kate Welsh Interior Layout: Marian Hartsough Cover Design: Mike Tanamachi Indexer: Katherine Stimson Proofreader: Jennifer Davidson All trademarks are the property of their respective owners. Important: Premier Press cannot provide software support. Please contact the appro- priate software manufacturer’s technical support line or Web site for assistance. Premier Press and the author have attempted throughout this book to distinguish proprietary trademarks from descriptive terms by following the capitalization style used by the manufacturer. Information contained in this book has been obtained by Premier Press from sources believed to be reliable. However, because of the possibility of human or mechanical error by our sources, Premier Press, or others, the Publisher does not guarantee the accuracy, adequacy, or completeness of any information and is not responsible for any errors or omissions or the results obtained from use of such information. -

Optimization and Visualization of Strategies for Platforms
Optimization and Visualization of Strategies for Platforms, Complements, and Services. by Richard B. LeVine BA, Psychology, State University of New York at Albany, 1980 MS, Computer Science, Union College, Schenectady New York, 1986 SUBMITTED TO THE ALFRED P. SLOAN SCHOOL OF MANAGEMENT IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTERS OF SCIENCE at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY June 2003 ©2003 Richard B. LeVine. All rights reserved. The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of Author: Alfred P. Sloan School of Management May 8, 2003 Certified by: Professor James Utterback, Chair, Management of Technology Program Reader Certified by: Professor Michael Cusumano, Sloan Management Review Distinguished Professor of Management Thesis Supervisor Accepted by: David Weber Director, Management of Technology Program 1 of 160 Optimization and Visualization of Strategies for Platforms, Complements, and Services by Richard B. LeVine Submitted to the Alfred P. Sloan School of Management on May 8, 2003, in Partial Fulfillment of the Requirement for the Degree of Masters of Science. Abstract This thesis probes the causal elements of product platform strategies and the effects of platform strategy on a firm. Platform strategies may be driven by internal or external forces, and the lifecycle of a firm and of a platform strategy evolve over time in response to both the needs of the firm and the changes in the external environment. This external environment may consist of a “platform ecology,” in which the platform strategies of firms affect one another. -
Quake Shareware Windows 10 Download Quake on Windows 10 in High Resolution
quake shareware windows 10 download Quake on Windows 10 in High Resolution. Quake: another all time classic, although this DOS game looks like it was never really finished properly (which is true). Poorly designed weaponry. No gun-changing animation. Cartoonish characters. But it was an instant classic FPS anyway, with true 3D level design and polygonal characters, as well as TCP/IP network support. With the DarkPlaces quake engine you still can play Quake on a computer with a modern operating system! The DarkPlaces Quake engine is the best source port we've encountered so far. Other Quake source ports we've tested: ezQuake. So, what do you need to get Quake running with DarkPlaces on Windows 10, Windows 8 and Windows 7? Installation of Quake. If you have an original Quake CD with a DOS version, install the game with DOSBox. Instructions on how to install a game from CD in DOSBox are here. The game files are in the ID1 folder of the Quake installation. If you have an original Quake CD with a Windows version, you don't have to install the game. The game files are in the ID1 folder on the CD. You don't have the original Quake game? Download Quake (including Mission Pack 1 and 2)! Installation of the DarkPlaces Quake engine. the latest stable/official release of the DarkPlaces Quake engine files: Windows 32 bits: DarkPlaces engine Windows OpenGL build 20140513 Windows 64 bits: DarkPlaces engine Windows 64 OpenGL build 20140513. Quake CD soundtrack. The music of Quake on the original installation CD consists of CD audio tracks (starting with track 2), which are not copied to your hard disk when you install the game. -
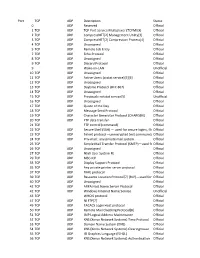
Official 2 TCP UDP Compr
Port TCP UDP Description Status 0 UDP Reserved Official 1 TCP UDP TCP Port Service Multiplexer (TCPMUX) Official 2 TCP UDP CompressNET[2] Management Utility[3] Official 3 TCP UDP CompressNET[2] Compression Process[4] Official 4 TCP UDP Unassigned Official 5 TCP UDP Remote Job Entry Official 7 TCP UDP Echo Protocol Official 8 TCP UDP Unassigned Official 9 TCP UDP Discard Protocol Official 9 UDP Wake-on-LAN Unofficial 10 TCP UDP Unassigned Official 11 TCP UDP Active Users (systat service)[5][6] Official 12 TCP UDP Unassigned Official 13 TCP UDP Daytime Protocol (RFC 867) Official 14 TCP UDP Unassigned Official 15 TCP UDP Previously netstat service[5] Unofficial 16 TCP UDP Unassigned Official 17 TCP UDP Quote of the Day Official 18 TCP UDP Message Send Protocol Official 19 TCP UDP Character Generator Protocol (CHARGEN) Official 20 TCP UDP FTP data transfer Official 21 TCP FTP control (command) Official 22 TCP UDP Secure Shell (SSH) — used for secure logins, file Officialtransfers (scp, sftp) and port forwarding 23 TCP UDP Telnet protocol—unencrypted text communicationsOfficial 24 TCP UDP Priv-mail : any private mail system. Official 25 TCP Simple Mail Transfer Protocol (SMTP)—used forOfficial e-mail routing between mail servers 26 TCP UDP Unassigned Official 27 TCP UDP NSW User System FE Official 29 TCP UDP MSG ICP Official 33 TCP UDP Display Support Protocol Official 35 TCP UDP Any private printer server protocol Official 37 TCP UDP TIME protocol Official 39 TCP UDP Resource Location Protocol*7+ (RLP)—used for determiningOfficial the location -

List of TCP and UDP Port Numbers - Wikipedia, the Free Encyclopedia List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
8/21/2014 List of TCP and UDP port numbers - Wikipedia, the free encyclopedia List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) which needed two ports for half duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for bidirectional traffic. The even numbered ports were not used, and this resulted in some even numbers in the well-known port number range being unassigned. The Stream Control Transmission Protocol (SCTP) and the Datagram Congestion Control Protocol (DCCP) also use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Use Description Color Official Port is registered with IANA for the application[1] White Unofficial Port is not registered with IANA for the application Blue Multiple use Multiple applications are known to use this port. Yellow Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[2] They are used by system processes that provide widely used types of network services. -
Game Server HOWTO
Game Server HOWTO Anders Jensen−Urstad <[email protected]> $Id: Game−Server−HOWTO.sgml,v 1.5 2003/04/08 20:49:11 andersju Exp $ This document explains how to install, configure and maintain servers for various popular multiplayer games. Game Server HOWTO Table of Contents 1. Introduction.....................................................................................................................................................1 1.1. Copyright and License......................................................................................................................1 1.2. History..............................................................................................................................................1 1.3. New versions.....................................................................................................................................1 1.4. Credits...............................................................................................................................................2 1.5. Feedback...........................................................................................................................................2 2. Basics................................................................................................................................................................3 2.1. Security and permissions..................................................................................................................3 2.2. Keeping the server running...............................................................................................................3 -
Linux Quake HOWTO Linux Quake HOWTO
Linux Quake HOWTO Linux Quake HOWTO Table of Contents Linux Quake HOWTO.......................................................................................................................................1 Bob Zimbinski bobz@mr.net...................................................................................................................1 1.Introduction ..........................................................................................................................................1 2.Quake/Quakeworld...............................................................................................................................1 3.Quake II................................................................................................................................................1 4.Related Software...................................................................................................................................2 5.Troubleshooting/FAQs.........................................................................................................................2 6.Tips & Tricks........................................................................................................................................2 7.Administrivia........................................................................................................................................2 1. Introduction .........................................................................................................................................3 -

List of TCP and UDP Port Numbers - Wikipedia, Th
List of TCP and UDP port numbers - Wikipedia, th... https://en.wikipedia.org/wiki/List_of_TCP_and_U... List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half-duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full-duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number range being unassigned. The Stream Control Transmission Protocol (SCTP) and the Datagram Congestion Control Protocol (DCCP) also use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[1] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[2] They are used by system processes that provide widely used types of network services.