High Availability Framework for Mix-Cloud Secure Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Github Essentials.Pdf
[ 1 ] GitHub Essentials Unleash the power of collaborative workflow development using GitHub, one step at a time Achilleas Pipinellis BIRMINGHAM - MUMBAI GitHub Essentials Copyright © 2015 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: September 2015 Production reference: 1280915 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78355-371-6 www.packtpub.com Credits Author Copy Editor Achilleas Pipinellis Trishya Hajare Reviewer Project Coordinator Umesh Ram Sharma Shweta H Birwatkar Commissioning Editor Proofreader Dipika Gaonkar Safis Editng Acquisition Editor Indexer Nikhil Karkal Hemangini Bari Content Development Editor Production Coordinator Sumeet Sawant Nitesh Thakur Technical Editor Cover Work Saurabh Malhotra Nitesh Thakur About the Author Achilleas Pipinellis is an open source enthusiast and tries to get involved in as many projects as possible. -

Avaliação De Performance De Interpretadores Ruby
Universidade Federal de Santa Catarina Centro Tecnológico Curso de Sistemas de Informação Wilson de Almeida Avaliação de Performance de Interpretadores Ruby Florianópolis 2010 Wilson de Almeida Avaliação de Performance de Interpretadores Ruby Monograa apresentada ao Curso de Sistemas de Informação da UFSC, como requisito para a obten- ção parcial do grau de BACHAREL em Sistemas de Informação. Orientador: Lúcia Helena Martins Pacheco Doutora em Engenharia Florianópolis 2010 Almeida, Wilson Avaliação de Performance de Interpretadores Ruby / Wilson Al- meida - 2010 xx.p 1.Performance 2. Interpretadores.. I.Título. CDU 536.21 Wilson de Almeida Avaliação de Performance de Interpretadores Ruby Monograa apresentada ao Curso de Sistemas de Informação da UFSC, como requisito para a obten- ção parcial do grau de BACHAREL em Sistemas de Informação. Aprovado em 21 de junho de 2010 BANCA EXAMINADORA Lúcia Helena Martins Pacheco Doutora em Engenharia José Eduardo De Lucca Mestre em Ciências da Computação Eduardo Bellani Bacharel em Sistemas de Informação Aos meus pais e meu irmão. Aos familiares e amigos, em especial pra mi- nha eterna amiga Liliana, que está torcendo por mim de onde ela estiver. Agradecimentos Agradeço ao meu amigo, colega de curso, parceiro de trabalhos e orientador Eduardo Bellani, pelo encorajamento, apoio e seus ricos conselhos sobre o melhor direci- onamento deste trabalho. A professora Lúcia Helena Martins Pacheco pela orientação, amizade, e pela paciência, sem a qual este trabalho não se realizaria. Ao professor José Eduardo Delucca, por seus conselhos objetivos e pontuais. Todos os meus amigos que incentivaram e compreenderam a minha ausência nesse período de corrida atrás do objetivo de concluir o curso. -

Michael Johann Mjohann@RailsExperts.Com
Steinfurt, Germany Michael Johann mjohann@railsexperts.com http://www.railsexperts.com I am interested in new projects where various modern technologies are combined to build great innovative products. My view is from the full stack developer to architecture and engineering aspects. I am also passionate about being a CTO if the company is trusting my technical experience. I've supported the most known industry standards before thy became mainstream. I've founded JavaSPEKTRUM print magazine in 1996 and RailsWayMagazine (print) in 2009 and have been editor in chief for both magazines. In 2008 I wrote a german book about "JRuby on Rails for Java Enterprise Developers). As a regular speaker at conferences in Europe/USA, I always spread the news about new technologies and how they apply to projects. As a person with multiple interests I combine using technical aspects in development with writing and speaking at conferences. I've been an evangelist for Java and Rails. Technical Skills Like: ruby, on, rails, ios, android, java, jee, html5, css3, javascript, mongodb, torquebox, ansible, docker, rspec, cucumber Dislike: php, typo3, cobol Experience Chief Full Stack Developer – Smaps GmbH December 2013 Current rubyonrails4.1, objectivec, mongodb, android Responsible for product development of backend, frontend and mobile clients Backend consists of MongoDB Frontend is HTML5 with Bootstrap, JQuery, GoogleMaps API iOS Client native with RestKit API communication Android native (Java) Interims CTO – Eco Novum GmbH 2012 November 2013 ios, mongodb, jrubyonrails, html5, css3, javascript, chef, git, jira, json Responsible for all architectural and technological aspects of the products (several mobile payment solutions). -

Ruby on Rails™ Tutorial: Learn Web Developments with Rails
ptg8286261 www.it-ebooks.info Praise for Michael Hartl’s Books and Videos on Ruby on RailsTM ‘‘My former company (CD Baby) was one of the first to loudly switch to Ruby on ptg8286261 Rails, and then even more loudly switch back to PHP (Google me to read about the drama). This book by Michael Hartl came so highly recommended that I had to try it, and the Ruby on RailsTM Tutorial is what I used to switch back to Rails again.’’ —From the Foreword by Derek Sivers (sivers.org) Formerly: Founder, CD Baby Currently: Founder, Thoughts Ltd. ‘‘Michael Hartl’s Rails Tutorial book is the #1 (and only, in my opinion) place to start when it comes to books about learning Rails. It’s an amazing piece of work and, unusually, walks you through building a Rails app from start to finish with testing. If you want to read just one book and feel like a Rails master by the end of it, pick the Ruby on RailsTM Tutorial.’’ —Peter Cooper Editor, Ruby Inside www.it-ebooks.info ‘‘Grounded in the real world.’’ —I Programmer (www.i-programmer.info), by Ian Elliot ‘‘The book gives you the theory and practice, while the videos focus on showing you in person how its done. Highly recommended combo.’’ —Antonio Cangiano, Software Engineer, IBM ‘‘The author is clearly an expert at the Ruby language and the Rails framework, but more than that, he is a working software engineer who introduces best practices throughout the text.’’ —Greg Charles, Senior Software Developer, Fairway Technologies ‘‘Overall, these video tutorials should be a great resource for anyone new to Rails.’’ —Michael Morin, ruby.about.com ‘‘Hands-down, I would recommend this book to anyone wanting to get into Ruby on Rails development.’’ —Michael Crump, Microsoft MVP ptg8286261 www.it-ebooks.info RUBY ON RAILSTM TUTORIAL Second Edition ptg8286261 www.it-ebooks.info Visit informit.com/ruby for a complete list of available products. -

Deploying with Jruby Is the Definitive Text on Getting Jruby Applications up and Running
Early Praise for Deploying JRuby Deploying with JRuby is the definitive text on getting JRuby applications up and running. Joe has pulled together a great collection of deployment knowledge, and the JRuby story is much stronger as a result. ➤ Charles Oliver Nutter JRuby Core team member and coauthor, Using JRuby Deploying with JRuby answers all of the most frequently asked questions regarding real-world use of JRuby that I have seen, including many we were not able to answer in Using JRuby. Whether you’re coming to JRuby from Ruby or Java, Joe fills in all the gaps you’ll need to deploy JRuby with confidence. ➤ Nick Sieger JRuby Core team member and coauthor, Using JRuby This book is an excellent guide to navigating the various JRuby deployment op- tions. Joe is fair in his assessment of these technologies and describes a clear path for getting your Ruby application up and running on the JVM. ➤ Bob McWhirter TorqueBox team lead at Red Hat Essential reading to learn not only how to deploy web applications on JRuby but also why. ➤ David Calavera Creator of Trinidad Deploying with JRuby is a must-read for anyone interested in production JRuby deployments. The book walks through the major deployment strategies by providing easy-to-follow examples that help the reader take full advantage of the JRuby servers while avoiding the common pitfalls of migrating an application to JRuby. ➤ Ben Browning TorqueBox developer at Red Hat Deploying with JRuby is an invaluable resource for anyone planning on using JRuby for web-based development. For those who have never used JRuby, Joe clearly presents its many advantages and few disadvantages in comparison to MRI. -

Ruby on Railsâ—¢ Tutorial
www.it-ebooks.info Praise for Michael Hartl’s Books and Videos on Ruby on RailsTM ‘‘My former company (CD Baby) was one of the first to loudly switch to Ruby on Rails, and then even more loudly switch back to PHP (Google me to read about the drama). This book by Michael Hartl came so highly recommended that I had to try it, and the Ruby on RailsTM Tutorial is what I used to switch back to Rails again.’’ —From the Foreword by Derek Sivers (sivers.org) Formerly: Founder, CD Baby Currently: Founder, Thoughts Ltd. ‘‘Michael Hartl’s Rails Tutorial book is the #1 (and only, in my opinion) place to start when it comes to books about learning Rails. ... It’s an amazing piece of work and, unusually, walks you through building a Rails app from start to finish with testing. If you want to read just one book and feel like a Rails master by the end of it, pick the Ruby on RailsTM Tutorial.’’ —Peter Cooper Editor, Ruby Inside www.it-ebooks.info ‘‘Grounded in the real world.’’ —I Programmer (www.i-programmer.info), by Ian Elliot ‘‘The book gives you the theory and practice, while the videos focus on showing you in person how its done. Highly recommended combo.’’ —Antonio Cangiano, Software Engineer, IBM ‘‘The author is clearly an expert at the Ruby language and the Rails framework, but more than that, he is a working software engineer who introduces best practices throughout the text.’’ —Greg Charles, Senior Software Developer, Fairway Technologies ‘‘Overall, these video tutorials should be a great resource for anyone new to Rails.’’ —Michael Morin, ruby.about.com ‘‘Hands-down, I would recommend this book to anyone wanting to get into Ruby on Rails development.’’ —Michael Crump, Microsoft MVP www.it-ebooks.info RUBY ON RAILSTM TUTORIAL Second Edition www.it-ebooks.info Visit informit.com/ruby for a complete list of available products. -

CSE341: Programming Languages Installing and Using Ruby and Irb Autumn 2018
CSE341: Programming Languages Installing and Using Ruby and irb Autumn 2018 Contents 1 Overview ................................................. 1 2 Windows .................................................. 2 2.1 Using Windows in the Department's Undergraduate Labs . 2 2.2 Using the Department's Windows Machines Remotely . 2 2.3 Using Your Own Windows Machine . 2 3 Linux .................................................... 4 3.1 Using Linux in the Department's Undergraduate Labs . 4 3.2 Using Your Own Linux machine . 5 3.3 Using the Department's Remote Linux Server attu ....................... 5 3.4 Using the Department's Linux Virtual Machine on Your Machine . 5 4 Mac ..................................................... 6 4.1 Installation: Mac OS X Mojave, High Sierra, Sierra, and El Capitan . 6 4.2 Installation: Mac OS X Yosemite and Mavericks . 6 4.3 Installation: Mac OS X Mountain Lion and Older . 7 4.4 Editing and Running Code . 7 5 General Information on Using (or Not Using) the REPL ................... 7 6 Main Links for Ruby Documentation, etc. ............................ 7 1 Overview The last two homeworks will be using the Ruby language. We recommend editing your files in Emacs and using irb, which is Ruby's REPL. (If you prefer a different editor that has support for Ruby, that is fine.) This document describes basic installation and usage steps sufficient for doing your homework. Unlike when we used SML, we recommend running the REPL from a terminal (shell) window, not from within Emacs. This is described below. For installation purposes related to Homework 6, there are some key facts: • You need to have some version of Ruby 2, but in order to most easily use the Tk graphics library, which is necessary for Homework 6, we recommend Ruby 2.2.X for some X. -

Introduction to Ruby on Rails
Introduction to Ruby on Rails Thomas Kowark Software Engineering II Prof. Plattner, Dr. Uflacker WS 2015/16 Enterprise Platform and Integration Concepts group Introduction to Ruby on Rails 1. Ruby & Ruby on Rails ■ What is Ruby on Rails? ■ A few words about Ruby ■ Rails' core components ■ RESTful architecture 2. Your first Rails applicaon 3. Your introductory Rails exercise 4. AddiAonal Literature Introduction to Ruby on Rails — Software Engineering II — WS 2015/16 October 16, 2015 2 What is Ruby on Rails? Web applicaon development framework wriHen in Ruby ■ hHp://rubyonrails.org/ Philosophy ■ "Don't repeat yourself" – DRY ■ ConvenAon over Configuraon – there is "the Rails way" ■ RESTful architecture ■ Everything in its place Rails 1 Rails2 Rails 3 Rails 4 Rails 5 2003 2006 2009 2013 est. 2015 ■ Used by Github, Groupon, TwiHer (parAally) Introduction to Ruby on Rails — Software Engineering II — WS 2015/16 October 16, 2015 3 A few words about Ruby hHp://www.ruby-lang.org/ ■ Dynamic, reflecAve, general-purpose, object-oriented ■ Influenced by Perl, Smalltalk, Eiffel, and Lisp ■ Open-source, mature soaware ■ Matz’s Ruby Interpreter (MRI) versions: Yukihiro "Matz" Matsumoto with R. Stallman Ruby 1.0 Ruby 1.8.7 Ruby 1.9.3 Ruby 2.0.0 Ruby 2.2.2 1996 2010 2011 2013 2015 □ AddiAonally different VMs available (JRuby, Rubinius, IronRuby, Maglev) Introduction to Ruby on Rails — Software Engineering II — WS 2015/16 Image by Rubén Rodríguez (CC BY 3.0) - hHp://commons.wikimedia.org/wiki/File:Matz.jpgOctober 16, 2015 4 Rails Core Components Ac1on Pack Raili1es Ac1on View (core code, e.G. -

Client-Server Web Apps with Javascript and Java
Client-Server Web Apps with JavaScript and Java Casimir Saternos Client-Server Web Apps with JavaScript and Java by Casimir Saternos Copyright © 2014 EzGraphs, LLC. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/ institutional sales department: 800-998-9938 or [email protected]. Editors: Simon St. Laurent and Allyson MacDonald Indexer: Judith McConville Production Editor: Kristen Brown Cover Designer: Karen Montgomery Copyeditor: Gillian McGarvey Interior Designer: David Futato Proofreader: Amanda Kersey Illustrator: Rebecca Demarest April 2014: First Edition Revision History for the First Edition: 2014-03-27: First release See http://oreilly.com/catalog/errata.csp?isbn=9781449369330 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Client-Server Web Apps with JavaScript and Java, the image of a large Indian civet, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. -
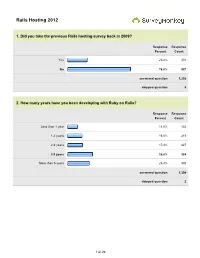
Rails Hosting 2012
Rails Hosting 2012 1. Did you take the previous Rails hosting survey back in 2009? Response Response Percent Count Yes 23.2% 301 No 76.8% 997 answered question 1,298 skipped question 8 2. How many years have you been developing with Ruby on Rails? Response Response Percent Count Less than 1 year 11.0% 144 1-2 years 16.5% 215 2-3 years 17.4% 227 3-5 years 29.8% 388 More than 5 years 25.3% 330 answered question 1,304 skipped question 2 1 of 24 3. How many Ruby on Rails applications have you deployed? Response Response Percent Count None (yet) 1.6% 21 1 5.7% 74 2-5 41.1% 534 6-15 33.1% 429 15+ 18.5% 240 answered question 1,298 skipped question 8 4. How many Ruby (non-Rails, e.g., Sinatra) application have you deployed? Response Response Percent Count None (yet) 37.0% 480 1 13.9% 180 2-5 35.6% 462 6-15 8.2% 106 15+ 5.5% 71 answered question 1,299 skipped question 7 2 of 24 5. What versions of Ruby are you using in your applications? Response Response Percent Count Ruby 1.8.6 5.8% 75 Ruby 1.8.7 (REE or MRI) 52.9% 690 Ruby 1.9.2 47.9% 625 Ruby 1.9.3 78.4% 1,022 Rubinius 1.4% 18 JRuby 9.8% 128 answered question 1,304 skipped question 2 6. Are you using a Ruby version manager in production? Response Response Percent Count Yes 63.0% 818 No 37.0% 481 answered question 1,299 skipped question 7 3 of 24 7. -

Ruby Version Manager for Windows « Ruby on Rails Outsourcing 6/7/2014
Ruby version manager for Windows « Ruby on Rails Outsourcing 6/7/2014 Ruby version manager for Windows 28 Jul 2010 William Notowidagdo Knowledge Kiranatama Staff ruby, windows Tweet 1 Ruby version manager is a great tool that allows you to easily have multiple versions of Ruby. For Unix-based environment, there is RVM and for Windows we have Pik. This post will take you to have a quick look on Pik. Installation When writing this post I am using ruby 1.9.1p429 (2010-07-02 revision 28523) [i386-mingw32] on Windows 7. You can use Pik from the Windows command line, Windows PowerShell, or Git Bash. Here I am using the command line. You can install pik via rubygems, or the Windows installer, or you can update pik with pik. Let us install pik using rubygems gem install pik If the installation gone smooth, you should see Successfully installed pik-0.2.8 1 gem installed After pik is installed now you want to use pik_install script to install the pik executable. You must install pik to a location in your path, but not in your Ruby bin directory. I add C:\bin to my path, so I run pik_install C:\bin then you should see pik is installed if you want to use pik with git bash, add the following line to your ~/.bashrc: [[ -s $USERPROFILE/.pik/.pikrc ]] && source $USERPROFILE/.pik/.pikrc Update: the command prompt from which you run pik has to be started using run as Administrator (if it’s Windows 7). Pik is modifying %PATH% environment variable and Windows 7 would silently not let it do so if not enough user privileges. -

The Ruby Way: Solutions and Techniques in Ruby Programming
Praise for The Ruby Way, Third Edition “Sticking to its tried and tested formula of cutting right to the techniques the modern day Rubyist needs to know, the latest edition of The Ruby Way keeps its strong reputation going for the latest generation of the Ruby language.” Peter Cooper Editor of Ruby Weekly “The authors’ excellent work and meticulous attention to detail continues in this lat- est update; this book remains an outstanding reference for the beginning Ruby pro- grammer—as well as the seasoned developer who needs a quick refresh on Ruby. Highly recommended for anyone interested in Ruby programming.” Kelvin Meeks Enterprise Architect Praise for Previous Editions of The Ruby Way “Among other things, this book excels at explaining metaprogramming, one of the most interesting aspects of Ruby. Many of the early ideas for Rails were inspired by the first edition, especially what is now Chapter 11. It puts you on a rollercoaster ride between ‘How could I use this?’ and ‘This is so cool!’ Once you get on that roller- coaster, there’s no turning back.” David Heinemeier Hansson Creator of Ruby on Rails, Founder at Basecamp “The appearance of the second edition of this classic book is an exciting event for Rubyists—and for lovers of superb technical writing in general. Hal Fulton brings a lively erudition and an engaging, lucid style to bear on a thorough and meticulously exact exposition of Ruby. You palpably feel the presence of a teacher who knows a tremendous amount and really wants to help you know it too.” David Alan Black Author of The Well-Grounded Rubyist “This is an excellent resource for gaining insight into how and why Ruby works.