Postscript Language Reference Manual / Adobe Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Create a Word Document That Uses Different Page Numbering Formats
How to create a Word document that uses different page numbering formats You can use Microsoft Word to create complex documents. Books and other large documents occasionally require different page number formats in different sections of one document. For example, you can number the index pages with Roman numerals (for example, "i.", "ii.", "iii.") and the main document with Arabic numerals (for example, "1", "2", "3"). This article describes how to set up different page numbering formats. Format Page Numbering To format the page numbering for different sections, follow these steps: 1. Click between two parts of your document that you want to number differently. 2. On the Insert menu, click Break. 3. Click Next Page, Even Page, or Odd Page, and then click OK. For Help on an option, click the question mark, and then click the option. 4. Click in the first section. 5. On the View menu, click Header and Footer. 6. Click in the header or footer where you want the page number. 7. On the Header and Footer toolbar, click Insert Page Number. 8. On the Header and Footer toolbar, click Format Page Number. 9. In the Number format box, click the format that you want for the numbers in this section. 10. Do one of the following: o If you want the page numbering for the first page in this section to start at a particular number other than the first number in the format series, click Start at under Page numbering, and then enter the first number that you want to appear on the first page of the section. -

Copy — Copy file from Disk Or URL
Title stata.com copy — Copy file from disk or URL Syntax Description Options Remarks and examples Also see Syntax copy filename1 filename2 , options filename1 may be a filename or a URL. filename2 may be the name of a file or a directory. If filename2 is a directory name, filename1 will be copied to that directory. filename2 may not be a URL. Note: Double quotes may be used to enclose the filenames, and the quotes must be used if the filename contains embedded blanks. options Description public make filename2 readable by all text interpret filename1 as text file and translate to native text format replace may overwrite filename2 replace does not appear in the dialog box. Description copy copies filename1 to filename2. Options public specifies that filename2 be readable by everyone; otherwise, the file will be created according to the default permissions of your operating system. text specifies that filename1 be interpreted as a text file and be translated to the native form of text files on your computer. Computers differ on how end-of-line is recorded: Unix systems record one line-feed character, Windows computers record a carriage-return/line-feed combination, and Mac computers record just a carriage return. text specifies that filename1 be examined to determine how it has end-of-line recorded and that the line-end characters be switched to whatever is appropriate for your computer when the copy is made. There is no reason to specify text when copying a file already on your computer to a different location because the file would already be in your computer’s format. -
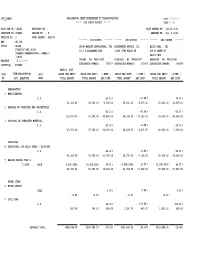
Bid Check Report * * * Time: 14:04
DOT_RGGB01 WASHINGTON STATE DEPARTMENT OF TRANSPORTATION DATE: 05/28/2013 * * * BID CHECK REPORT * * * TIME: 14:04 PS &E JOB NO : 11W101 REVISION NO : BIDS OPENED ON : Jun 26 2013 CONTRACT NO : 008498 REGION NO : 9 AWARDED ON : Jul 1 2013 VERSION NO : 2 WORK ORDER# : XL4078 ------- LOW BIDDER ------- ------- 2ND BIDDER ------- ------- 3RD BIDDER ------- HWY : SR 104 TITLE : SR104 ORION MARINE CONTRACTORS, INC. BLACKWATER MARINE, LLC QUIGG BROS., INC. KINGSTON TML SLIPS 1112 E ALEXANDER AVE 12019 76TH PLACE NE 819 W STATE ST DOLPHIN PRESERVATION - PHASE 4 98520-5934 11W101 PROJECT : NH-2013(079) TACOMA WA 984214102 KIRKLAND WA 980342437 ABERDEEN WA 985200281 COUNTY(S) : KITSAP CONTRACTOR NUMBER : 100767 CONTRACTOR NUMBER : 100874 CONTRACTOR NUMBER : 680000 ENGR'S. EST. ITEM ITEM DESCRIPTION UNIT PRICE PER UNIT/ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ NO. EST. QUANTITY MEAS TOTAL AMOUNT TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. PREPARATION 1 MOBILIZATION L.S. -25.20 % -25.48 % 40.00 % 25,000.00 18,700.00 -6,300.00 18,630.00 -6,370.00 35,000.00 10,000.00 2 REMOVAL OF STRUCTURE AND OBSTRUCTION L.S. -56.10 % -65.08 % -56.71 % 115,500.00 50,700.00 -64,800.00 40,338.00 -75,162.00 50,000.00 -65,500.00 3 DISPOSAL OF CREOSOTED MATERIAL L.S. -21.05 % -8.99 % -15.79 % 47,500.00 37,500.00 -10,000.00 43,228.35 -4,271.65 40,000.00 -7,500.00 STRUCTURE 4 STRUCTURAL LOW ALLOY STEEL - DOLPHINS L.S. -

Attachment D to Adm. Memo No. 004 INSTRUCTIONS FOR
Attachment D to Adm. Memo No. 004 INSTRUCTIONS FOR FORMATTING A DISKETTE Formatting is the preparation of diskettes for storage of information. There are several different versions of the format command that can be used. The version that you use depends upon the type of diskette and the type of disk drive in which the diskette is being formatted. In order for us to be able to read the Tuition Grant diskettes you send, the diskettes should be properly formatted. Below is a table that identifies the more commonly used diskette types and disk drive specifications. The correct version of the format command will appear in the row for your diskette type and drive type. The format command uses the parameter “d:” to indicate the disk drive designation. For example, your 5 ¼ drive may be the “A:” drive. Instead of typing “FORMAT D:”, replace the drive designation with “A:” and type “FORMAT A:”. To verify that the disks were formatted correctly, perform the CHKDSK command on the newly formatted diskette. The format for the CHKDSK command is “CHKDSK d:”. When the command returns the disk information, compare it to the information in the fourth column of the table that corresponds to your diskette type and disk drive.. If the “total disk space” numbers are the same, the diskette is formatted correctly. DISK TYPE DRIVE TYPE FORMAT COMMAND SPACE INFO. 5 ¼” DSDD DSDD FORMAT d: 362,496 bytes total disk space 5 ¼” DSDD HD FORMAT d: /T:40 /N:9 362,496 bytes total disk space 5 ¼” HD DSDD Cannot be formatted 5 ¼” HD HD FORMAT d: 1,213,952 bytes total disk space 3 ½” DSDD DSDD FORMAT d: 730,112 bytes total disk space 3 ½” DSDD HD FORMAT d: /T:80 /N:9 730,112 bytes total disk space 3 ½” HD DSDD Cannot be formatted 3 ½” HD HD FORMAT d: 1,457,664 bytes total disk space 3 ½” DSHD FORMAT d: 1,457,664 bytes total disk space. -

Using a Next Workstation As a Development Platform for Version 5 Sas Applications
USING A NEXT WORKSTATION AS A DEVELOPMENT PLATFORM FOR VERSION 5 SAS APPLICATIONS Joseph E St Sauver, Office of University Computing, University of Oregon ABSTRACT Similarly. there is liUle sense in tieing up a PC for hours (or days) running a large statistical analysis when a sha.red SAS Institute has yet to announce any firm plans to port the mainframe will often have abundant horsepower to handle just SAS System* to NeXT* workstations. Nonetheless, a NeXT those sorts of CPU-intensive jobs. workstation can serve as an excellent platform for developing VAXNMS· (or other mainframe) SAS System code for remote The PC version of SAS atte~s to explott this philosophy by execution. giving the user the option of either processing SAS code locally using the SUBMIT command, or processing SAS code on a The combination of a strong windowing environment, display remote mainframe SAS host using the RSUBMIT command. In a PostScript support. a built-in athemet interlace and copious perfect world. this approach would allow the user to elect the slorage eapacny bundled on lOP of more-or-Iess BSD 4.3 UNIX" best mix of local and remote resources to achieve his or her make development of SAS System code on the NeXT for objectives in a timely and cost effective manner. remote execution on another mainframe quite easy. Unfortunately, in my experience, the happy symbiosis The author's experience with use of a NeXT as a remote code envisioned between the PC version of the SAS System and the development plaHorm for SAS and SAS/Graph" on a VAXNMS mainframe version of the SAS system often breaks down. -

Humidity Definitions
ROTRONIC TECHNICAL NOTE Humidity Definitions 1 Relative humidity Table of Contents Relative humidity is the ratio of two pressures: %RH = 100 x p/ps where p is 1 Relative humidity the actual partial pressure of the water vapor present in the ambient and ps 2 Dew point / Frost the saturation pressure of water at the temperature of the ambient. point temperature Relative humidity sensors are usually calibrated at normal room temper - 3 Wet bulb ature (above freezing). Consequently, it generally accepted that this type of sensor indicates relative humidity with respect to water at all temperatures temperature (including below freezing). 4 Vapor concentration Ice produces a lower vapor pressure than liquid water. Therefore, when 5 Specific humidity ice is present, saturation occurs at a relative humidity of less than 100 %. 6 Enthalpy For instance, a humidity reading of 75 %RH at a temperature of -30°C corre - 7 Mixing ratio sponds to saturation above ice. by weight 2 Dew point / Frost point temperature The dew point temperature of moist air at the temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to water (liquid). The frost point temperature of moist air at temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to ice. Magnus Formula for dew point (over water): Td = (243.12 x ln (pw/611.2)) / (17.62 - ln (pw/611.2)) Frost point (over ice): Tf = (272.62 x ln (pi/611.2)) / (22.46 - -

Sun Ultratm 5 Workstation Just the Facts
Sun UltraTM 5 Workstation Just the Facts Copyrights 1999 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun logo, Ultra, PGX, PGX24, Solaris, Sun Enterprise, SunClient, UltraComputing, Catalyst, SunPCi, OpenWindows, PGX32, VIS, Java, JDK, XGL, XIL, Java 3D, SunVTS, ShowMe, ShowMe TV, SunForum, Java WorkShop, Java Studio, AnswerBook, AnswerBook2, Sun Enterprise SyMON, Solstice, Solstice AutoClient, ShowMe How, SunCD, SunCD 2Plus, Sun StorEdge, SunButtons, SunDials, SunMicrophone, SunFDDI, SunLink, SunHSI, SunATM, SLC, ELC, IPC, IPX, SunSpectrum, JavaStation, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunVIP, SunSolve, and SunSolve EarlyNotifier are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. OpenGL is a registered trademark of Silicon Graphics, Inc. Display PostScript and PostScript are trademarks of Adobe Systems, Incorporated, which may be registered in certain jurisdictions. Netscape is a trademark of Netscape Communications Corporation. DLT is claimed as a trademark of Quantum Corporation in the United States and other countries. Just the Facts May 1999 Positioning The Sun UltraTM 5 Workstation Figure 1. The Ultra 5 workstation The Sun UltraTM 5 workstation is an entry-level workstation based upon the 333- and 360-MHz UltraSPARCTM-IIi processors. The Ultra 5 is Sun’s lowest-priced workstation, designed to meet the needs of price-sensitive and volume-purchase customers in the personal workstation market without sacrificing performance. -

BUGS Code for Item Response Theory
JSS Journal of Statistical Software August 2010, Volume 36, Code Snippet 1. http://www.jstatsoft.org/ BUGS Code for Item Response Theory S. McKay Curtis University of Washington Abstract I present BUGS code to fit common models from item response theory (IRT), such as the two parameter logistic model, three parameter logisitic model, graded response model, generalized partial credit model, testlet model, and generalized testlet models. I demonstrate how the code in this article can easily be extended to fit more complicated IRT models, when the data at hand require a more sophisticated approach. Specifically, I describe modifications to the BUGS code that accommodate longitudinal item response data. Keywords: education, psychometrics, latent variable model, measurement model, Bayesian inference, Markov chain Monte Carlo, longitudinal data. 1. Introduction In this paper, I present BUGS (Gilks, Thomas, and Spiegelhalter 1994) code to fit several models from item response theory (IRT). Several different software packages are available for fitting IRT models. These programs include packages from Scientific Software International (du Toit 2003), such as PARSCALE (Muraki and Bock 2005), BILOG-MG (Zimowski, Mu- raki, Mislevy, and Bock 2005), MULTILOG (Thissen, Chen, and Bock 2003), and TESTFACT (Wood, Wilson, Gibbons, Schilling, Muraki, and Bock 2003). The Comprehensive R Archive Network (CRAN) task view \Psychometric Models and Methods" (Mair and Hatzinger 2010) contains a description of many different R packages that can be used to fit IRT models in the R computing environment (R Development Core Team 2010). Among these R packages are ltm (Rizopoulos 2006) and gpcm (Johnson 2007), which contain several functions to fit IRT models using marginal maximum likelihood methods, and eRm (Mair and Hatzinger 2007), which contains functions to fit several variations of the Rasch model (Fischer and Molenaar 1995). -

XMP SPECIFICATION PART 3 STORAGE in FILES Copyright © 2016 Adobe Systems Incorporated
XMP SPECIFICATION PART 3 STORAGE IN FILES Copyright © 2016 Adobe Systems Incorporated. All rights reserved. Adobe XMP Specification Part 3: Storage in Files NOTICE: All information contained herein is the property of Adobe Systems Incorporated. No part of this publication (whether in hardcopy or electronic form) may be reproduced or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of Adobe Systems Incorporated. Adobe, the Adobe logo, Acrobat, Acrobat Distiller, Flash, FrameMaker, InDesign, Illustrator, Photoshop, PostScript, and the XMP logo are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. MS-DOS, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Apple, Macintosh, Mac OS and QuickTime are trademarks of Apple Computer, Inc., registered in the United States and other countries. UNIX is a trademark in the United States and other countries, licensed exclusively through X/Open Company, Ltd. All other trademarks are the property of their respective owners. This publication and the information herein is furnished AS IS, is subject to change without notice, and should not be construed as a commitment by Adobe Systems Incorporated. Adobe Systems Incorporated assumes no responsibility or liability for any errors or inaccuracies, makes no warranty of any kind (express, implied, or statutory) with respect to this publication, and expressly disclaims any and all warranties of merchantability, fitness for particular purposes, and noninfringement of third party rights. Contents 1 Embedding XMP metadata in application files . -

Encapsulated Postscript File Format Specification
® Encapsulated PostScript File Format Specification ®® Adobe Developer Support Version 3.0 1 May 1992 Adobe Systems Incorporated Adobe Developer Technologies 345 Park Avenue San Jose, CA 95110 http://partners.adobe.com/ PN LPS5002 Copyright 1985–1988, 1990, 1992 by Adobe Systems Incorporated. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of the publisher. Any software referred to herein is furnished under license and may only be used or copied in accordance with the terms of such license. PostScript is a registered trademark of Adobe Systems Incorporated. All instances of the name PostScript in the text are references to the PostScript language as defined by Adobe Systems Incorpo- rated unless otherwise stated. The name PostScript also is used as a product trademark for Adobe Sys- tems’ implementation of the PostScript language interpreter. Any references to a “PostScript printer,” a “PostScript file,” or a “PostScript driver” refer to printers, files, and driver programs (respectively) which are written in or support the PostScript language. The sentences in this book that use “PostScript language” as an adjective phrase are so constructed to rein- force that the name refers to the standard language definition as set forth by Adobe Systems Incorpo- rated. PostScript, the PostScript logo, Display PostScript, Adobe, the Adobe logo, Adobe Illustrator, Tran- Script, Carta, and Sonata are trademarks of Adobe Systems Incorporated registered in the U.S.A. and other countries. Adobe Garamond and Lithos are trademarks of Adobe Systems Incorporated. -

No. 25 a Secret Index—
a secret index— division leap no. 25 a secret index— Booksellers, publishers and researchers of the history of print culture. Collections purchased. Books found. Appraisals performed. Libraries built. divisionleap.com no. 25 83. 35. 59. 39. 39. 27. 30. 25. 21. 65. 48. 72. 6. contents a. Walter Benjamin—German Expressionism—Raubdrucke 17 b. Reproduction—Computing—Classification—Architecture 23 c. The Body—Tattooing—Incarceration—Crime—Sexuality 33 d. Social Movements—1968—Feminism—The SI & After 47 e. Music 57 f. Literature—Poetry—Periodicals 63 g. Film—Chris Marker 77 h. Art 85 i. Punk Zines 91 Additional images of all items available at divisionleap.com or by request. a. Walter Benjamin—German Expressionism—Raubdrucke 17 2. 1. 18 a. The Birth of Walter Benjamin’s Theory Heuber so messianically feels is near … ” of the Messianic McCole, analyzing this same letter, notes that this appears to be Benjamin’s first use of the term 1. [Victor Hueber] Die Organisierung der “Messianic” in his writings [McCole, p. 61]. The Intelligenz. Ein Aufruf. Zweite, erweiterte Auflage. idea would haunt Benjamin’s subsequent works Als Manuskript gedruckt. on history, and reach its conclusion in the second [Prague]: Druck H. Mercy, [1910]. 8vo, thesis in On the Concept of History, written just 107 pp, stab-stapled and glue bound into violet before his march into the mountains. “The past printed wraps. Front and back panels of wraps carries with it a secret index, by which it is referred detached but present, with the paper covering to its resurrection. There is an agreement and an the spine mostly perished. -

Pdflib Text and Image Extraction Toolkit (TET) Manual
ABC Text and Image Extraction Toolkit (TET) Version 5.2 Toolkit for extracting Text, Images, and other items from PDF Copyright © 2002–2019 PDFlib GmbH. All rights reserved. Protected by European and U.S. patents. PDFlib GmbH Franziska-Bilek-Weg 9, 80339 München, Germany www.pdflib.com phone +49 • 89 • 452 33 84-0 If you have questions check the PDFlib mailing list and archive at groups.yahoo.com/neo/groups/pdflib/info Licensing contact: [email protected] Support for commercial PDFlib licensees: [email protected] (please include your license number) This publication and the information herein is furnished as is, is subject to change without notice, and should not be construed as a commitment by PDFlib GmbH. PDFlib GmbH assumes no responsibility or lia- bility for any errors or inaccuracies, makes no warranty of any kind (express, implied or statutory) with re- spect to this publication, and expressly disclaims any and all warranties of merchantability, fitness for par- ticular purposes and noninfringement of third party rights. TET contains modified parts of the following third-party software: CMap resources. Copyright © 1990-2019 Adobe Zlib compression library, Copyright © 1995-2017 Jean-loup Gailly and Mark Adler TIFFlib image library, Copyright © 1988-1997 Sam Leffler, Copyright © 1991-1997 Silicon Graphics, Inc. Cryptographic software written by Eric Young, Copyright © 1995-1998 Eric Young ([email protected]) Independent JPEG Group’s JPEG software, Copyright © Copyright © 1991-2017, Thomas G. Lane, Guido Vollbeding Cryptographic software, Copyright © 1998-2002 The OpenSSL Project (www.openssl.org) Expat XML parser, Copyright © 2001-2017 Expat maintainers ICU International Components for Unicode, Copyright © 1995-2012 International Business Machines Corpo- ration and others OpenJPEG library, Copyright © 2002-2014, Université catholique de Louvain (UCL), Belgium TET contains the RSA Security, Inc.