Big Data As the Future of Information Technology A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Big Data Enables Economic Harm to Consumers, Especially to Low-Income and Other Vulnerable Sectors of the Population
How Big Data Enables Economic Harm to Consumers, Especially to Low-Income and Other Vulnerable Sectors of the Population The author of these comments, Nathan Newman, has been writing for twenty years about the impact of technology on society, including his 2002 book Net Loss: Internet Profits, Private Profits and the Costs to Community, based on doctoral research on rising regional economic inequality in Silicon Valley and the nation and the role of Internet policy in shaping economic opportunity. He has been writing extensively about big data as a research fellow at the New York University Information Law Institute for the last two years, including authoring two law reviews this year on the subject. These comments are adapted with some additional research from one of those law reviews, "The Costs of Lost Privacy: Consumer Harm and Rising Economic Inequality in the Age of Google” published in the William Mitchell Law Review. He has a J.D. from Yale Law School and a Ph.D. from UC-Berkeley’s Sociology Department; Executive Summary: ϋBͤ͢ Dͯ͜͜ό ͫͧͯͪͭͨͮ͜͡ ͮͰͣ͞ ͮ͜ Gͪͪͧ͢͠ ͩ͜͟ Fͪͪͦ͜͞͠͝ ͭ͜͠ ͪͨͤͩ͢͝͠͞ ͪͨͤͩͩͯ͟͜ institutions organizing information not just about the world but about consumers themselves, thereby reshaping a range of markets based on empowering a narrow set of corporate advertisers and others to prey on consumers based on behavioral profiling. While big data can benefit consumers in certain instances, there are a range of new consumer harms to users from its unregulated use by increasingly centralized data platforms. A. These harms start with the individual surveillance of users by employers, financial institutions, the government and other players that these platforms allow, but also extend to ͪͭͨͮ͡ ͪ͡ Ͳͣͯ͜ ͣͮ͜ ͩ͝͠͠ ͧͧ͜͟͞͠ ϋͧͪͭͤͯͣͨͤ͜͢͞ ͫͭͪͤͧͤͩ͢͡ό ͯͣͯ͜ ͧͧͪ͜Ͳ ͪͭͫͪͭͯ͜͞͠ ͤͩͮͯͤͯͰͯͤͪͩͮ to discriminate and exploit consumers as categorical groups. -

Issues, Challenges, and Solutions: Big Data Mining
ISSUES , CHALLENGES , AND SOLUTIONS : BIG DATA MINING Jaseena K.U. 1 and Julie M. David 2 1,2 Department of Computer Applications, M.E.S College, Marampally, Aluva, Cochin, India [email protected],[email protected] ABSTRACT Data has become an indispensable part of every economy, industry, organization, business function and individual. Big Data is a term used to identify the datasets that whose size is beyond the ability of typical database software tools to store, manage and analyze. The Big Data introduce unique computational and statistical challenges, including scalability and storage bottleneck, noise accumulation, spurious correlation and measurement errors. These challenges are distinguished and require new computational and statistical paradigm. This paper presents the literature review about the Big data Mining and the issues and challenges with emphasis on the distinguished features of Big Data. It also discusses some methods to deal with big data. KEYWORDS Big data mining, Security, Hadoop, MapReduce 1. INTRODUCTION Data is the collection of values and variables related in some sense and differing in some other sense. In recent years the sizes of databases have increased rapidly. This has lead to a growing interest in the development of tools capable in the automatic extraction of knowledge from data [1]. Data are collected and analyzed to create information suitable for making decisions. Hence data provide a rich resource for knowledge discovery and decision support. A database is an organized collection of data so that it can easily be accessed, managed, and updated. Data mining is the process discovering interesting knowledge such as associations, patterns, changes, anomalies and significant structures from large amounts of data stored in databases, data warehouses or other information repositories. -

Oracle Big Data SQL Release 4.1
ORACLE DATA SHEET Oracle Big Data SQL Release 4.1 The unprecedented explosion in data that can be made useful to enterprises – from the Internet of Things, to the social streams of global customer bases – has created a tremendous opportunity for businesses. However, with the enormous possibilities of Big Data, there can also be enormous complexity. Integrating Big Data systems to leverage these vast new data resources with existing information estates can be challenging. Valuable data may be stored in a system separate from where the majority of business-critical operations take place. Moreover, accessing this data may require significant investment in re-developing code for analysis and reporting - delaying access to data as well as reducing the ultimate value of the data to the business. Oracle Big Data SQL enables organizations to immediately analyze data across Apache Hadoop, Apache Kafka, NoSQL, object stores and Oracle Database leveraging their existing SQL skills, security policies and applications with extreme performance. From simplifying data science efforts to unlocking data lakes, Big Data SQL makes the benefits of Big Data available to the largest group of end users possible. KEY FEATURES Rich SQL Processing on All Data • Seamlessly query data across Oracle Oracle Big Data SQL is a data virtualization innovation from Oracle. It is a new Database, Hadoop, object stores, architecture and solution for SQL and other data APIs (such as REST and Node.js) on Kafka and NoSQL sources disparate data sets, seamlessly integrating data in Apache Hadoop, Apache Kafka, • Runs all Oracle SQL queries without modification – preserving application object stores and a number of NoSQL databases with data stored in Oracle Database. -

Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners
Additional praise for Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners “Jared’s book is a great introduction to the area of High Powered Analytics. It will be useful for those who have experience in predictive analytics but who need to become more versed in how technology is changing the capabilities of existing methods and creating new pos- sibilities. It will also be helpful for business executives and IT profes- sionals who’ll need to make the case for building the environments for, and reaping the benefi ts of, the next generation of advanced analytics.” —Jonathan Levine, Senior Director, Consumer Insight Analysis at Marriott International “The ideas that Jared describes are the same ideas that being used by our Kaggle contest winners. This book is a great overview for those who want to learn more and gain a complete understanding of the many facets of data mining, knowledge discovery and extracting value from data.” —Anthony Goldbloom Founder and CEO of Kaggle “The concepts that Jared presents in this book are extremely valuable for the students that I teach and will help them to more fully under- stand the power that can be unlocked when an organization begins to take advantage of its data. The examples and case studies are particu- larly useful for helping students to get a vision for what is possible. Jared’s passion for analytics comes through in his writing, and he has done a great job of making complicated ideas approachable to multiple audiences.” —Tonya Etchison Balan, Ph.D., Professor of Practice, Statistics, Poole College of Management, North Carolina State University Big Data, Data Mining, and Machine Learning Wiley & SAS Business Series The Wiley & SAS Business Series presents books that help senior-level managers with their critical management decisions. -

Internet of Things Big Data Artificial Intelligence
IGF 2019 Best Practices Forum on Internet of Things Big Data Artificial Intelligence Draft BPF Output Report - November 2019 - Acknowledgements The Best Practice Forum on Internet of Things, Big Data, Artificial Intelligence (BPF IoT, Big Data, AI) is an open multistakeholder group conducted as an intersessional activity of the Internet Governance Forum (IGF). This report is the draft output of the IGF2019 BPF IoT, Big Data, AI and is the product of the collaborative work of many. Facilitators of the BPF IoT, Big Data, AI: Ms. Concettina CASSA, MAG BPF Co-coordinator Mr. Alex Comninos, BPF Co-coordinator Mr. Michael Nelson, BPF Co-coordinator Mr. Wim Degezelle, BPF Consultant (editor) The BPF draft document was developed through open discussions on the BPF mailing list and virtual meetings. We would like to acknowledge participants to these discussions for their input. The BPF would also like to thank all who submitted input through the BPF’s Call for contributions. Disclaimer: The IGF Secretariat has the honour to transmit this paper prepared by the 2019 Best Practice Forum on IoT, Big Data, AI. The content of the paper and the views expressed therein reflect the BPF discussions and are based on the various contributions received and do not imply any expression of opinion on the part of the United Nations. IGF2019 BPF IoT, Big Data, AI - Draft output report - November 2019 2 / 37 DOCUMENT REVIEW & FEEDBACK (editorial note 12 November 2019) The BPF IoT, Big Data, AI is inviting Community feedback on this draft report! How ? Please send your feedback to [email protected] Format? Feedback can be sent in an email or as a word or pdf document attached to an email. -

Artificial Intelligence and Big Data – Innovation Landscape Brief
ARTIFICIAL INTELLIGENCE AND BIG DATA INNOVATION LANDSCAPE BRIEF © IRENA 2019 Unless otherwise stated, material in this publication may be freely used, shared, copied, reproduced, printed and/or stored, provided that appropriate acknowledgement is given of IRENA as the source and copyright holder. Material in this publication that is attributed to third parties may be subject to separate terms of use and restrictions, and appropriate permissions from these third parties may need to be secured before any use of such material. ISBN 978-92-9260-143-0 Citation: IRENA (2019), Innovation landscape brief: Artificial intelligence and big data, International Renewable Energy Agency, Abu Dhabi. ACKNOWLEDGEMENTS This report was prepared by the Innovation team at IRENA’s Innovation and Technology Centre (IITC) with text authored by Sean Ratka, Arina Anisie, Francisco Boshell and Elena Ocenic. This report benefited from the input and review of experts: Marc Peters (IBM), Neil Hughes (EPRI), Stephen Marland (National Grid), Stephen Woodhouse (Pöyry), Luiz Barroso (PSR) and Dongxia Zhang (SGCC), along with Emanuele Taibi, Nadeem Goussous, Javier Sesma and Paul Komor (IRENA). Report available online: www.irena.org/publications For questions or to provide feedback: [email protected] DISCLAIMER This publication and the material herein are provided “as is”. All reasonable precautions have been taken by IRENA to verify the reliability of the material in this publication. However, neither IRENA nor any of its officials, agents, data or other third- party content providers provides a warranty of any kind, either expressed or implied, and they accept no responsibility or liability for any consequence of use of the publication or material herein. -
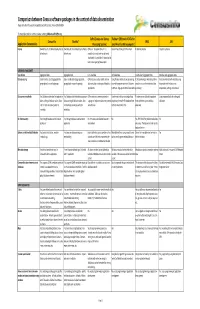
Comparison Between Census Software Packages in the Context of Data Dissemination Prepared by Devinfo Support Group (DSG) and UN Statistics Division (DESA/UNSD)
Comparison between Census software packages in the context of data dissemination Prepared by DevInfo Support Group (DSG) and UN Statistics Division (DESA/UNSD) For more information or comments please contact: [email protected] CsPro (Census and Survey Redatam (REtrieval of DATa for CensusInfo DevInfo* SPSS SAS Application Characteristics Processing System) small Areas by Microcomputer) License Owned by UN, distributed royalty-free to Owned by UN, distributed royalty-free to CSPro is in the public domain. It is Version free of charge for Download Properitery license Properitery license all end-users all end-users available at no cost and may be freely distributed. It is available for download at www.census.gov/ipc/www/cspro DATABASE MANAGEMENT Type of data Aggregated data. Aggregated data. Individual data. Individual data. Individual and aggregated data. Individual and aggregated data. Data processing Easily handles data disaggregated by Easily handles data disaggregated by CSPro lets you create, modify, and run Using Process module allows processing It allows entering primary data, define It lets you interact with your data using geographical area and subgroups. geographical area and subgroups. data entry, batch editing, and tabulation data with programs written in Redatam variables and perform statistical data integrated tools for data entry, applications command language or limited Assisstants processing computation, editing, and retrieval. Data consistency checks Yes, Database administration application Yes, Database administration -

Research; *Electronic Data Processing; Information Processing; Information Systems; *Manpower Utilization; *Personnel Data; Personnel Management; Questionnaires
DOCUMENT RESUME ED 084 382 CE 000 533 AUTHOR Bayhylle, J. E., Ed.; Hersleb, A., Ed. TITLE The Development of Electronic Data Processing in Manpower Areas; A Comparative Study of Personnel Information Systems and their Implications in Six European Countries. INSTITUTION Organisation for Economic Cooperation and Development, Paris (France) . PUB DATE 73 NOTE 366p. AVAILABLE FROMOECD Publications Center, Suite 1207, 1750 Pennsylvania Ave., N.W., Washington, DC 20006 ($8.50) EDRS PRICE MF-$0.65 HC- $13.16 DESCRIPTORS Case Studies; Data Bases; Data Processing; *Ecqnomic .Research; *Electronic Data Processing; Information Processing; Information Systems; *Manpower Utilization; *Personnel Data; Personnel Management; Questionnaires ABSTRACT Usable data about human resources in the ecqnqmy are fundamentally important, but present methods of obtaining, organizing, and using such information are increasingly unsatisfactory. The application of electronic data processing to manpower and social concerns should be improved and increased. This could stimulate closer exchange between government, institutions, and business enterprises in the collection and dissemination of manpower data. The first phase of the study was a broad-scope questionnaire of 38 companies in Austria, France, Germany, Great Britain, Sweden, and Switzerland which have developed, or are planning to develop, computer-based personnel information, systems. The second phase consisted of depth study of eight of the companies. Case study investigations were concerned with the content and function of the system and with the administrative and personnel consequences of the introduction of such systems. A set of key.points which emerged from the study is developed. A model demonstrates the need for coordination to increase communication vertically and horizontally. -

Big Data Platforms, Tools, and Research at IBM
IBM Research Big Data Platforms, Tools, and Research at IBM Ed Pednault CTO, Scalable Analytics Business Analytics and Mathematical Sciences, IBM Research © 2011 IBM Corporation Please Note: IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal without notice at IBM’s sole discretion. Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision. The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract. The development, release, and timing of any future features or functionality described for our products remains at our sole discretion. Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user's job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here. IBM Big Data Strategy: Move the Analytics Closer to the Data New analytic applications drive the Analytic Applications BI / Exploration / Functional Industry Predictive Content BI / requirements -

Artificial Intelligence, Big Data and Cloud Taxonomy
DEPARTMENT OF DEFENSE ARTIFICIAL INTELLIGENCE, BIG DATA AND CLOUD TAXONOMY Foreword by Hon. Robert O. Work, 32nd Deputy Secretary of Defense COMPANIES INCLUDED GOVINI CLIENT MARKET VIEWS Altamira Technologies Corp. University of Southern California Artificial Intelligence - Computer Vision Aptima Inc. United Technologies Corp. AT&T Inc. (T) Vector Planning & Services Inc. Artificial Intelligence - Data Mining BAE Systems PLC (BAESY) Vision Systems Inc. Artificial Intelligence - Deep Learning Boeing Co. (BA) Vykin Corp. Booz Allen Hamilton Inc. (BAH) World Wide Technology Inc. Artificial Intelligence - Machine Learning CACI International Inc. (CACI) Artificial Intelligence - Modeling & Simulation Carahsoft Technology Corp. Combined Technical Services LLC Artificial Intelligence - Natural Language Processing Concurrent Technologies Corp. Cray Inc. Artificial Intelligence - Neuromorphic Engineering CSRA Inc. (CSRA) Artificial Intelligence - Quantum Computing deciBel Research Inc. Dell Inc. Artificial Intelligence - Supercomputing Deloitte Consulting LLP DLT Solutions Inc. Artificial Intelligence - Virtual Agents DSD Laboratories Artificial Intelligence - Virtual Reality DXC Technologies Corp. (DXC) General Dynamics Corp. (GD) Big Data - Business Analytics Georgia Tech. Harris Corp. Big Data - Data Analytics Johns Hopkins APL Big Data - Data Architecture & Modeling HRL Laboratories International Business Machines Inc. (IBM) Big Data - Data Collection Inforeliance Corp. Big Data - Data Hygiene Insight Public Sector Inc. Intelligent Automation Inc. Big Data - Data Hygiene Software Intelligent Software Solutions Inc. JF Taylor Inc. Big Data - Data Visualization Software L3 Technologies Inc. (LLL) Big Data - Data Warehouse Leidos Inc. (LDOS) Lockheed Martin Co. (LMT) Big Data - Distributed Processing Software Logos Technologies LLC ManTech International Corp. (MANT) Big Data - ETL & Data Processing Microsoft Corp. (MSFT) Big Data - Intelligence Exploitation Mythics Inc. NANA Regional Corp. Cloud - IaaS Northrop Grumman Corp. -

Big Data, Data Mining and Machine Learning
Contents Forward xiii Preface xv Acknowledgments xix Introduction 1 Big Data Timeline 5 Why This Topic Is Relevant Now 8 Is Big Data a Fad? 9 Where Using Big Data Makes a Big Difference 12 Part One The Computing Environment ..............................23 Chapter 1 Hardware 27 Storage (Disk) 27 Central Processing Unit 29 Memory 31 Network 33 Chapter 2 Distributed Systems 35 Database Computing 36 File System Computing 37 Considerations 39 Chapter 3 Analytical Tools 43 Weka 43 Java and JVM Languages 44 R 47 Python 49 SAS 50 ix ftoc ix April 17, 2014 10:05 PM Excerpt from Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners by Jared Dean. Copyright © 2014 SAS Institute Inc., Cary, North Carolina, USA. ALL RIGHTS RESERVED. x ▸ CONTENTS Part Two Turning Data into Business Value .......................53 Chapter 4 Predictive Modeling 55 A Methodology for Building Models 58 sEMMA 61 Binary Classifi cation 64 Multilevel Classifi cation 66 Interval Prediction 66 Assessment of Predictive Models 67 Chapter 5 Common Predictive Modeling Techniques 71 RFM 72 Regression 75 Generalized Linear Models 84 Neural Networks 90 Decision and Regression Trees 101 Support Vector Machines 107 Bayesian Methods Network Classifi cation 113 Ensemble Methods 124 Chapter 6 Segmentation 127 Cluster Analysis 132 Distance Measures (Metrics) 133 Evaluating Clustering 134 Number of Clusters 135 K‐means Algorithm 137 Hierarchical Clustering 138 Profi ling Clusters 138 Chapter 7 Incremental Response Modeling 141 Building the Response -

Applied Accounting and Automatic Data-Processing Systems." (1962)
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1962 Applied Accounting and Automatic Data- Processing Systems. William Elwood Swyers Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Recommended Citation Swyers, William Elwood, "Applied Accounting and Automatic Data-Processing Systems." (1962). LSU Historical Dissertations and Theses. 745. https://digitalcommons.lsu.edu/gradschool_disstheses/745 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. This dissertation has been 62—3671 microfilmed exactly as received SWYERS, William Elwood, 1922- APPLIED ACCOUNTING AND AUTOMATIC DATA-PRO CESSING SYSTEMS. Louisiana State University, Ph.D., 1962 Economics, commerce—business University Microfilms, Inc., Ann Arbor, Michigan APPLIED ACCOUNTING AND AUTOMATIC DATA-PROCESSING SYSTEMS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Accounting by William Eiu<Swyers B.S., Centenary College, 1942 M.B.A. t Louisiana State University, 1948 January, 1962 ACKNOWLEDGMENTS The writer wishes to express appreciation to Dr. Robert H. Van Voorhis, Professor of Accounting, Louisiana State University, for his valuable assistance and guidance in the preparation of this dissertation. The writer wishes to acknowledge, also, the helpful suggestions made by Dr. W. D. Ross, Dean of the College of Business Administration, Dr.