Implementing Persistent Identifiers. Overview of Concepts, Guidelines
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Network Working Group T. Berners-Lee Request for Comments: 3986 W3C/MIT STD: 66 R
Network Working Group T. Berners-Lee Request for Comments: 3986 W3C/MIT STD: 66 R. Fielding Updates: 1738 Day Software Obsoletes: 2732, 2396, 1808 L. Masinter Category: Standards Track Adobe Systems January 2005 Uniform Resource Identifier (URI): Generic Syntax Status of This Memo This document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions for improvements. Please refer to the current edition of the "Internet Official Protocol Standards" (STD 1) for the standardization state and status of this protocol. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (2005). Abstract A Uniform Resource Identifier (URI) is a compact sequence of characters that identifies an abstract or physical resource. This specification defines the generic URI syntax and a process for resolving URI references that might be in relative form, along with guidelines and security considerations for the use of URIs on the Internet. The URI syntax defines a grammar that is a superset of all valid URIs, allowing an implementation to parse the common components of a URI reference without knowing the scheme-specific requirements of every possible identifier. This specification does not define a generative grammar for URIs; that task is performed by the individual specifications of each URI scheme. Berners-Lee, et al. Standards Track [Page 1] RFC 3986 URI Generic Syntax January 2005 Table of Contents 1. Introduction . 4 1.1. Overview of URIs . 4 1.1.1. Generic Syntax . 6 1.1.2. Examples . 7 1.1.3. URI, URL, and URN . 7 1.2. Design Considerations . -

A Framework for Auto-ID Enabled Business
A Framework for Auto-ID Enabled Business by Timothy Porter Milne M.S. Mechanical Engineering, 1995 Brigham Young University B.S. Mechanical Engineering, 1992 Brigham Young University Submitted to the Department of Mechanical Engineering in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY MASSACHUSETTS INSTITUTEINSTITUTE August 8, 2003 OF TECHNOL OGY OCT 0 6 ©2003 Massachusetts Institute of Technology All Rights Reserved. LIBRAR IES Signature of Author:................................ ....... .. ............. Departm of Mechanic Engineering (V August 8, 2003 C ertified by:............................................... Sanjay E. Sarma Associat e Professor of Mechanical Engineering Thesis Supervisor A ccepted by:......................................... Ain A. Sonin Chairman, Department Committee on Graduate Students BARKER A Framework for Auto-ID Enabled Business by Timothy Porter Milne Submitted to the Department of Mechanical Engineering August 8, 2003 In partial fulfillment of the requirements for the degree of Master of Science ABSTRACT Modern commerce is as much about trading information as it is about exchanging goods and money. With an Auto-ID enabled future, the expeditious exchange of information will be even more critical. The fundamental problem with e-commerce today is the soft connection between goods and their related information, which frequently results in breakdowns between the physical and information worlds. The Auto-ID Center at MIT has proposed a system using Radio Frequency Identification (RFID) tags on objects, coupled with a distributed information system using the Internet, that will allow the tracking of physical objects and the automatic association of relevant data about those objects. This thesis outlines a framework for a new method of using Auto-ID to connect the physical world to the information world using an example from commerce: Shipping and Receiving Verification. -

FAA-STD-075, Creating Service Identifiers
FAA-STD-075 June 29, 2021 SUPERSEDING FAA-STD-063 May 1, 2009 U.S. Department of Transportation Federal Aviation Administration U.S. Department of Transportation Federal Aviation Administration Standard Practice CREATING SERVICE IDENTIFIERS FAA-STD-075 June 29, 2021 FOREWORD This standard is approved for use by all Departments of the Federal Aviation Administration (FAA). This standard sets forth requirements for creating globally-unique identifiers for FAA service-oriented architecture (SOA)-based services. This standard has been prepared in accordance with FAA-STD-068, Department of Transportation Federal Aviation Administration, Preparation of Standards [STD068]. Comments, suggestions, or questions on this document shall be addressed to: Federal Aviation Administration System Wide Information Management (SWIM) Program Office, AJM-316 800 Independence Avenue, SW Washington, DC 20591 https://www.faa.gov/air_traffic/technology/swim/contacts/ i FAA-STD-075 June 29, 2021 Table of Contents 1 SCOPE ..................................................................................................................................................1 1.1 INTRODUCTION ...........................................................................................................................................1 1.2 INTENDED AUDIENCE ....................................................................................................................................1 1.3 BASIC CONCEPTS .........................................................................................................................................2 -

Globally Unique Flight Identifier (GUFI) Format and Content
Globally Unique Flight Identifier (GUFI) Format and Content A collaborative effort to establish the Flight Information Exchange Model (FIXM) has been underway for several years. A key component of the flight model is a Globally Unique Flight Identifier (GUFI) that is included on every Air Traffic Management (ATM) flight data transaction to unambiguously identify the flight to which the data applies. The June 23, purpose of the GUFI is to eliminate problems that have occurred in the past when 2014 systems try to accurately correlate data that is received from many other systems. This paper discusses the format and content of the GUFI. Version: 2.1 GUFI Format Version 2.1 Table of Contents Document History ........................................................................................................................................ 3 1 Introduction .......................................................................................................................................... 4 2 Background/Discussion ......................................................................................................................... 4 2.1 Purpose ..................................................................................................................................... 4 2.2 General Concept ....................................................................................................................... 4 2.3 General Approaches ................................................................................................................. -

Persistent Identifiers (Pids): Recommendations for Institutions Persistent Identifiers (Pids): Recommendations for Institutions
persistent identifiers (pids): recommendations for institutions persistent identifiers (pids): recommendations for institutions edited by ATHENA ATHENA WP3 general co-ordinator Working Group Rossella Caffo “Identifying standards and developing design recommendations” mt milani, geo graphic sdf texts by Gordon McKenna, Athena logo Collections Trust (UK) Susan Hazan Roxanne Wyms, Royal Museums of Art web version and History (Belgium) http://www.athenaeurope. org/index.php?en/110/ The text of this booklet promotional-material is included in deliverables 3.4 and 3.5, This work by ATHENA of the ATHENA project project is licensed under and is based on a survey a Creative Commons of the content that Attribution ATHENA partners Non-Commercial contracted to provide Share Alike Licence to Europeana through (CC-BY-NC-SA) the ATHENA project. http://creativecommons. org/licenses/by-nc-sa/3.0/ Foreword Introduction 1. Persistent identifiers A briefing note 2. Persistent identifier policy in context 3. Standards landscape 3.1 Physical objects in museums 3.2 Digital objects 3.3 Services 3.4 Collections in museums 3.5 Institutions 4. Managing organisations 5. Persistent identifier systems table of contents Foreword It is the aim of the ATHENA project to support especially museums in providing object data for publication in Europeana. Thus ATHENA is about access to digitised or digital cultural heritage held in museums and other institutions. In order to ensure that information about an object and the object itself, its digital copies can be related to each other and can be retrieved easily at different points in time and from different places it is necessary to use “persistent identifiers” (PIDs). -

Digital Object Identifier (DOI) System for Research Data
Digital Object Identifier (DOI) System for Research Data A guide explaining what the Digital Object Identifier system does, the advantages of using a DOI Name to cite and link research data and the ARDC DOI minting service. Who is this for? This guide is intended for researchers and eResearch infrastructure support providers. Last updated: May 2019 This work is licenced under a Creative Commons Attribution 4.0 Australia Licence Contents Anatomy of a DOI ....................................................................................................................................................................1 What is the DOI System? ..............................................................................................................................................................1 What are the advantages of DOIs for datasets? ...................................................................................................................2 Digital Object Identifiers (DOIs) .................................................................................................................................................3 DOIs and other persistent identifiers ................................................................................................................................4 DOIs for versioned data .......................................................................................................................................................4 ARDC DOI Minting service...................................................................................................................................................4 -

Identifiers and Use Case in Scientific Research
Submitted on: 19.07.2016 Identifiers and Use Case in Scientific Research Thomas Gillespie Neurosciences, University of California, San Diego, San Diego, CA, USA E-mail address: [email protected] Qian Zhang School of Information Sciences, University of Illinois at Urbana-Champaign, USA E-mail address: [email protected] Chelakara S. Subramanian Department of Mech and Aerospace Engineering, Florida Institute of Technology, Melbourne, FL, USA, E-mail address: [email protected] Yan Han University Libraries, The University of Arizona, Tucson, AZ, USA. E-mail address: [email protected] Copyright © 2016 by Thomas Gillespie, Qian Zhang, Chelakara S. Subramanian, Yan Han. This work is made available under the terms of the Creative Commons Attribution 4.0 International License: http://creativecommons.org/licenses/by/4.0 Abstract: The authors have broad representations across of a variety of domains including Oceanography, Aerospace Engineering, Astronomy, Neurosciences, and Libraries. The article is intended to: a) discuss the key concepts related to identifiers and define identifiers; b) explore characteristics of good and bad identifiers in general, along with an overview of popular identifiers; c) demonstrate a use case in a scientific domain of using identifiers via the data lifecycle; c) raise awareness of data collection, data analysis and data sharing for raw and post-processing data for data producers and data users. It is inevitable for multiple identifiers to co-exist in the data lifecycle, as the case study shows different needs of data producers and data users. Keywords: identifier, use case, data lifecycle 1. Identifiers: Introduction and Definition A lab’s notebook number and page are sufficient for local access in no time. -

Introduction to the Course
Introduction to the course 1 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Prerequirements § OOP + Java: essential! (Must have passed Linguaggi di Programmazione!) § Network fundamentals § Database § No need to already know HTML/HTTP etc. 2 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Topics § HTTP + HTML + CSS § Server side programming: PHP – Java, parameter passing, state problem… § Data access (DB) § Javascript – EcmaScript – Typescript § Patterns: MV* + … § AJAX/XML/JSON § JS frameworks/libraries: JQuery, (brief remarks on React, Angular…) § General considerations (accessibility, security…) 3 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento We’ll use Piazza As soon as the dept Buys the licence For now we go with moodle (sigh) 4 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Exam § Similar to “Linguaggi di Programmazione – mod.1” § 1st part: output prediction of 8 brief code fragments + 8 true/fase questions (40 minutes) § 2nd part: small project development (4 hours) If possiBle, in presence. Else, Responsus+Moodle+VDI 5 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento 6 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento What is the difference between the Web and the Internet? 7 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento What is the difference between the Web and the Internet? § "The -

Referencing Source Code Artifacts: a Separate Concern in Software Citation Roberto Di Cosmo, Morane Gruenpeter, Stefano Zacchiroli
Referencing Source Code Artifacts: a Separate Concern in Software Citation Roberto Di Cosmo, Morane Gruenpeter, Stefano Zacchiroli To cite this version: Roberto Di Cosmo, Morane Gruenpeter, Stefano Zacchiroli. Referencing Source Code Artifacts: a Separate Concern in Software Citation. Computing in Science and Engineering, Institute of Electrical and Electronics Engineers, In press, pp.1-9. 10.1109/MCSE.2019.2963148. hal-02446202 HAL Id: hal-02446202 https://hal.archives-ouvertes.fr/hal-02446202 Submitted on 22 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. 1 Referencing Source Code Artifacts: a Separate Concern in Software Citation Roberto Di Cosmo, Inria and University Paris Diderot, France [email protected] Morane Gruenpeter, University of L’Aquila and Inria, France [email protected] Stefano Zacchiroli, University Paris Diderot and Inria, France [email protected] Abstract—Among the entities involved in software citation, II. REFERENCING SOURCE CODE FOR REPRODUCIBILITY software source code requires special attention, due to the role Software and software-based methods are now widely used it plays in ensuring scientific reproducibility. To reference source code we need identifiers that are not only unique and persistent, in research fields other than just computer science and en- but also support integrity checking intrinsically. -
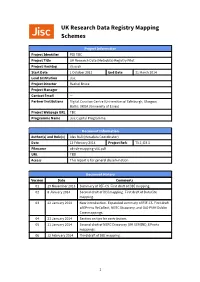
UK Research Data Registry Mapping Schemes
UK Research Data Registry Mapping Schemes Project Information Project Identifier PID TBC Project Title UK Research Data (Metadata) Registry Pilot Project Hashtag #jiscrdr Start Date 1 October 2013 End Date 31 March 2014 Lead Institution Jisc Project Director Rachel Bruce Project Manager — Contact Email — Partner Institutions Digital Curation Centre (Universities of Edinburgh, Glasgow, Bath); UKDA (University of Essex) Project Webpage URL TBC Programme Name Jisc Capital Programme Document Information Author(s) and Role(s) Alex Ball (Metadata Coordinator) Date 12 February 2014 Project Refs T3.1; D3.1 Filename uk-rdr-mapping-v06.pdf URL TBD Access This report is for general dissemination Document History Version Date Comments 01 29 November 2013 Summary of RIF-CS. First draft of DDI mapping. 02 8 January 2014 Second draft of DDI mapping. First draft of DataCite mapping. 03 22 January 2014 New introduction. Expanded summary of RIF-CS. First draft of EPrints ReCollect, NERC Discovery, and OAI-PMH Dublin Core mappings. 04 23 January 2014 Section on tips for contributors. 05 31 January 2014 Second draft of NERC Discovery (UK GEMINI), EPrints mappings. 06 12 February 2014 Third draft of DDI mapping. 1 Contents 1 Introduction 3 1.1 Typographical conventions . 3 2 RIF-CS 4 2.1 Elements . 4 2.2 Controlled vocabularies . 8 3 Internally managed RIF-CS elements 20 4 Mapping from DDI to RIF-CS 21 4.1 Related Objects . 22 5 Mapping from UK GEMINI 2 to RIF-CS 24 5.1 Related Objects . 26 6 Mapping from DataCite to RIF-CS 27 6.1 Related Objects . -

Persistent Identifiers: Consolidated Assertions Status of November, 2017
Persistent identifiers: Consolidated assertions Status of November, 2017 Editors: Peter Wittenburg (RDA Europe), Margareta Hellström (ICOS), and Carlo-Maria Zwölf (VAMDC) Co-authors: Hossein Abroshan (CESSDA), Ari Asmi (ENVRIplus), Giuseppe Di Bernardo (MPA), Danielle Couvreur (MYRRHA), Tamas Gaizer (ELI), Petr Holub (BBMRI), Rob Hooft (ELIXIR), Ingemar Häggström (EISCAT), Manfred Kohler (EU- OPENSCREEN), Dimitris Koureas (NHM), Wolfgang Kuchinke (ECRIN), Luciano Milanesi (CNR), Joseph Padfield (NG), Antonio Rosato (INSTRUCT), Christine Staiger (SurfSARA), Dieter van Uytvanck (CLARIN) and Tobias Weigel (IS-ENES) The Research Data Alliance is supported by the European Commission, the National Science Foundation and other U.S. agencies, and the Australian Government. Document revision history 2016-11-01 v 1.0 (extracted from RDA Data Fabric IG wiki) 2016-12-15 v 2.0, after comments & feedback from Bratislava 2016-11-14 2017-03-29 v 3.0, partially discussed at RDA P9 in Barcelona 2017-04-07 2017-05-10 v 4.0, discussed during GEDE telco on 2017-05-29 2017-06-21 v 5.0 for GEDE PID group review on 2017-06-28 2017-08-29 v 5.1 for GEDE PID group review on 2017-08-30 2017-11-13 v 6.0, for GEDE review on 2017-11-20 2017-12-13 V 6.1, circulated for RDA (Data Fabric IG) review ii Abstract Experts from 47 European research infrastructure initiatives and ERICs have agreed on a set of assertions about the nature, the creation and the usage of Persistent Identifiers (PIDs). This work was done in close synchronisation with the RDA Data Fabric Interest Group (DFIG) ensuring a global validation of the assertions. -

ARK Identifier Scheme
UC Office of the President CDL Staff Publications Title The ARK Identifier Scheme Permalink https://escholarship.org/uc/item/9p9863nc Authors Kunze, John Rodgers, Richard Publication Date 2008-05-22 eScholarship.org Powered by the California Digital Library University of California Network Preservation Group J. Kunze California Digital Library R. Rodgers US National Library of Medicine May 22, 2008 The ARK Identifier Scheme Abstract The ARK (Archival Resource Key) naming scheme is designed to facilitate the high-quality and persistent identification of information objects. A founding principle of the ARK is that persistence is purely a matter of service and is neither inherent in an object nor conferred on it by a particular naming syntax. The best that an identifier can do is to lead users to the services that support robust reference. The term ARK itself refers both to the scheme and to any single identifier that conforms to it. An ARK has five components: [http://NMAH/]ark:/NAAN/Name[Qualifier] an optional and mutable Name Mapping Authority Hostport (usually a hostname), the "ark:" label, the Name Assigning Authority Number (NAAN), the assigned Name, and an optional and possibly mutable Qualifier supported by the NMA. The NAAN and Name together form the immutable persistent identifier for the object independent of the URL hostname. An ARK is a special kind of URL that connects users to three things: the named object, its metadata, and the provider's promise about its persistence. When entered into the location field of a Web browser, the ARK leads the user to the named object.