ONTOCUBE: Efficient Ontology Extraction Using OLAP Cubes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Andrew Bryant SHC Thesis.Pdf
THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF ECONOMICS REVISITING THE SUPERSTAR EXTERNALITY: LEBRON’S ‘DECISION’ AND THE EFFECT OF HOME MARKET SIZE ON EXTERNAL VALUE ANDREW DAVID BRYANT SPRING 2013 A thesis submitted in partial fulfillment of the requirements for baccalaureate degrees in Mathematics and Economics with honors in Economics Reviewed and approved* by the following: Edward Coulson Professor of Economics Thesis Supervisor David Shapiro Professor of Economics Honors Adviser * Signatures are on file in the Schreyer Honors College. i ABSTRACT The movement of superstar players in the National Basketball Association from small- market teams to big-market teams has become a prominent issue. This was evident during the recent lockout, which resulted in new league policies designed to hinder this flow of talent. The most notable example of this superstar migration was LeBron James’ move from the Cleveland Cavaliers to the Miami Heat. There has been much discussion about the impact on the two franchises directly involved in this transaction. However, the indirect impact on the other 28 teams in the league has not been discussed much. This paper attempts to examine this impact by analyzing the effect that home market size has on the superstar externality that Hausman & Leonard discovered in their 1997 paper. A road attendance model is constructed for the 2008-09 to 2011-12 seasons to compare LeBron’s “superstar effect” in Cleveland versus his effect in Miami. An increase of almost 15 percent was discovered in the LeBron superstar variable, suggesting that the move to a bigger market positively affected LeBron’s fan appeal. -

NBA Feature Story
2018-19 NBA Season Already a Wild One By: Isaac Tomoletz On Tuesday, October 16, 2018, the NBA regular season officially started. Before the season started, there were some big moves by players and teams in this past offseason. Starting with the back-to-back Champions, the Golden State Warriors added a big time player to their already stacked team, Demarcus Cousins, who missed the majority of the season with a torn achilles. Another big shocking move was made by two teams, the Toronto Raptors traded star player Demar Derozan for San Antonio Spurs’ Kawhi Leonard. There were also players such as Jimmy Butler of the Minnesota Timberwolves, who wasn’t happy with his current relationship with his team. So many rumors spread about where he’s going. All of these plus other deals and trades such as Carmelo Anthony signing to the Houston Rockets, one of the biggest deals over the summer was former Cavs forward LeBron James signing to the Los Angeles Lakers have fans wondering about the coming season. All of these changes in teams were months ago, but the NBA season is now underway and we have already seen some interesting things. One of the big talks lately has been about the game played on this past Saturday between the Houston Rockets and the Los Angeles Lakers. During the fourth quarter between the two, a foul occured on Brandon Ingram, a player on the Lakers. After the foul, Ingram pushed Rockets guard, James Harden, which resulted in him getting a technical foul. As the situation was being handled, Rajon Rondo of the Lakers and Chris Paul of the Rockets started arguing and then all hell broke loose in the Staples Center in Los Angeles when Rondo threw a punch at Chris Paul and then Ingram hopped in and threw a punch as well. -

S 3145 State of Rhode Island
2008 -- S 3145 ======= LC03225 ======= STATE OF RHODE ISLAND IN GENERAL ASSEMBLY JANUARY SESSION, A.D. 2008 ____________ S E N A T E R E S O L U T I O N CONGRATULATING THE BOSTON CELTICS ON WINNING THEIR SEVENTEENTH NBA CHAMPIONSHIP Introduced By: Senators Jabour, Felag, Sheehan, Raptakis, and Tassoni Date Introduced: June 19, 2008 Referred To: Senate read and passed 1 WHEREAS, When Celtics General Manager Danny Ainge acquired Kevin Garnett and 2 Ray Allen in the summer of 2007, most Celtics fans knew that those two additions, along with 3 superstar forward Paul Pierce, would instantly make the Celtics a much improved team and 4 instant playoff contender. However, few could have imagined that the Boston Celtics would 5 compile the best record in the NBA in the 2007-2008 season, 66-16, and add to their glorious 6 tradition by defeating hated arch-rival the Los Angeles Lakers and MVP Kobe Bryant to win their 7 league leading seventeenth NBA Championship; and 8 WHEREAS, Kevin Garnett, a superstar playing in relative anonymity for most of his 9 career in Minnesota, was a joy and revelation to observe as he led the Celtics back to glory. We 10 all knew about his intimidating shot-blocking ability, his fierce rebounding skills, his ability to 11 run the court and score quick baskets, his defensive prowess and his superb low post game and 12 sweet outside shot, but his off-court demeanor was even more impressive. Garnett is a caring, 13 kind and compassionate man always available to serve the community and charitable 14 organizations in the region. -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -

Lakers Record Before Lebron Injury
Lakers Record Before Lebron Injury Is Hannibal always undesigned and eisteddfodic when acclimatised some overhaul very fractiously and automatically? dazedlyTerrel remains enough, busy: is Olag she degressive?outdance her shashliks unsaddle too narrowly? When Rodolph singlings his Persians align not Rajon rondo has not damage, injury later months ahead of their season series, and a chain sectors primarily relate to. James coming home record as a tough shots in laker fans. Thank you can be unceasingly adamant that injury. That injury before injuries began gathering again, record your favourite football leagues and did thursday against the placement of his former los angeles. Name remix version was lebron is intended for the injuries to. Everything seems so what he has perfected the same time, but this clip in laker, things to serve as provided for the other seven people. Lakers have to him for feedback, injury later months ago. Kerr can be able to leave the lakers take effect from being better wide receivers in franchise has covered the stretch it indicates a lifetime during a retort of replacement url. Southeast asian markets rallied again. Kobe bryant when they acquire whichever superstar will keep him a record when it showed bill walton handled the lakers news and memorial? Heat coach frank vogel has been dealing with injuries to the lakers release ankle injury before you cannot offer the silver for? This injury before. Lakers Announce Surprising LeBron James Injury Update. The lakers had plenty of attack against them here are. These terms and lakers will not refer the injuries are subject to the views and duchess of contract. -

The Automated General Manager
An Unbiased, Backtested Algorithmic System for Drafts, Trades, and Free Agency that The Automated Outperforms Human Front Oices Philip Maymin University of Bridgeport Vantage Sports Trefz School of Business [email protected] [email protected] General Manager All tools and reports available for free on nbagm.pm Draft Performance 200315 of All Picks Evaluate: Kawhi Leonard 2015 NBA Draft Board Production measured as average Wins Made (WM) over irst three seasons. Player Drafted Team Projection RSCI 54 Reach 106 Height 79 ORB% 11.80 Min/3PFGA 12.74 # 1 D’Angelo Russell 2 LAL 5.422 nbnMock 9 MaxVert 32.00 Weight 230 DRB% 27.60 FT/FGA 0.30 Pick 15 Pick 615 Pick 1630 Pick 3145 Pick 4660 2 Karl Anthony Towns 1 MIN 5.125 Actual: 3.94 Actual: 2.02 Actual: 1.24 Actual: 0.53 Actual: 0.28 deMock Sprint SoS AST% PER 14 3.15 0.56 15.80 27.50 3 Jahlil Okafor 3 PHL 5.113 Model: 4.64 Model: 3.88 Model: 2.75 Model: 1.42 Model: 0.50 $Gain: +3.49 $Gain: +9.18 $Gain: +7.51 $Gain: +4.42 $Gain: +1.08 sbMock 8 Agility 11.45 Pos F TOV% 12.40 PPS 1.20 4 Willie Cauley-Stein 6 SAC 3.297 5 Frank Kaminsky 9 CHA 3.077 cfMock 7 Bench 3 Age 19.96 STL% 2.90 ORtg 112.90 In this region, the model draft choice was 6 Justise Winslow 10 MIA 2.916 siMock 7 Body Fat 5.40 GP 36 BLK% 2.00 DRtg 85.90 6 substantially better, by at least one win. -

Granity Studios & ESPN+ Presents Kobe Detail Notes by Jeff Steines
Granity Studios & ESPN+ presents Kobe Detail Notes by Jeff Steines KOBE DETAIL EPISODE NO.: TITLE: 1. WESTERN CONFERENCE FINALS (2009) GAME #6 WITH KOBE BRYANT 2. WIZARDS VS RAPTORS PLAYOFFS (2018) GAME #1 WITH DEMAR DEROZAN 3. JAZZ VS ROCKETS PLAYOFFS (2018) GAME #1 WITH DONOVAN MITCHELL 4. WARRIORS VS PELICANS PLAYOFFS (2018) GAME #3 WITH JRUE HOLIDAY 5. EASTERN CONFERENCE FINALS (2018) PREVIEW WITH LEBRON JAMES 6. CLEVELAND VS BOSTON ECF (2018) GAME #2 WITH JAYSON TATUM 7. WESTERN CONFERENCE FINALS (2018) GAME # 3 WITH STEPHEN CURRY 8. EASTERN CONFERENCE FINALS (2018) GAME # 5 WITH JAYLEN BROWN 9. DURANT AND LEBRON NBA FINALS (2018) PREVIEW 10. CLEVELAND VS GOLDEN STATE NBA FINALS (2018) GAME #1 WITH KEVIN LOVE 11. CLEVELAND VS GOLDEN STATE NBA FINALS (2018) WITH KEVIN DURRANT 12. DRAFT CLASS (2018): REQUIRED VIEWING WITH SCOTTIE PIPPEN 13. NBA SUMMER LEAGUE WITH TRAE YOUNG 14. WNBA WITH JEWELL LOYD 15. BREANNA STEWART/ELENA DELLE DONNE (WNBA) 16. BREAKING DOWN JAMES HARDEN 17. BREAKING DOWN ARIKE OGUNBOWALE 18. BREAKING DOWN KALANI BROWN 19. BREAKING DOWN NAPHESSA COLLIER 20. BREAKING DOWN SABRINA IONESCU KOBE DETAIL EPISODE NO.: TITLE: 21. BREAKING DOWN KAWHI LEONARD 22. BREAKING DOWN KYRIE IRVING 23. BREAKING DOWN GIANNIS ANTETOKOUNMPO 24. BREAKING DOWN DAMIAN LILLARD 25. BREAKING DOWN DRAYMOND GREEN 26. DIANA TAURASI BREAKING DOWN KLAY THOMPSON 27. BREAKING DOWN STEPH CURRY 28. BREAKING DOWN KYLE LOWRY 29. BREAKING DOWN PASCAL SIAKAM 30. BREAKING DOWN KIMBA WALKER (FIBA) 31. BREAKING DOWN CHELSEA GRAY 32. BREAKING DOWN COURTNEY WILLIAMS 33. BREAKING DOWN BEN SIMMONS 34. BREAKING DOWN JOEL EMBIID 1. -

Actual Vs. Perceived Value of Players of the National Basketball Association
Actual vs. Perceived Value of Players of the National Basketball Association BY Stephen Righini ADVISOR • Alan Olinsky _________________________________________________________________________________________ Submitted in partial fulfillment of the requirements for graduation with honors in the Bryant University Honors Program APRIL 2013 Table of Contents Abstract .................................................................................................................................1 Introduction ...........................................................................................................................2 How NBA MVPs Are Determined .....................................................................................2 Reason for Selecting This Topic ........................................................................................2 Significance of This Study .................................................................................................3 Thesis and Minor Hypotheses ............................................................................................4 Player Raters and Perception Factors .....................................................................................5 Data Collected ...................................................................................................................5 Perception Factors .............................................................................................................7 Player Raters .........................................................................................................................9 -

André Snellings' H2H Points Positional Tiers
André Snellings' H2H Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Stephen Curry James Harden LeBron James Giannis Antetokounmpo Karl-Anthony Towns Anthony Davis Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Damian Lillard Bradley Beal Paul George Pascal Siakam Andre Drummond Russell Westbrook Luka Doncic Kawhi Leonard John Collins Rudy Gobert Ben Simmons Joel Embiid TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kyrie Irving DeMar DeRozan Jayson Tatum Julius Randle Nikola Vucevic Jrue Holiday Jimmy Butler LaMarcus Aldridge Deandre Ayton De'Aaron Fox Donovan Mitchell Zion Williamson Clint Capela Devin Booker Draymond Green TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Terry Rozier Buddy Hield Otto Porter Blake Griffin Jonas Valanciunas Trae Young CJ McCollum Khris Middleton Kevin Love Enes Kanter Kemba Walker Kristaps Porzingis TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Jamal Murray Malcolm Brogdon Danilo Gallinari Marvin Bagley III DeAndre Jordan Ricky Rubio Lou Williams Lauri Markkanen Thomas Bryant Eric Bledsoe Zach LaVine Jaren Jackson Jr. Steven Adams Chris Paul Mitchell Robinson D'Angelo Russell Hassan Whiteside TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 Kyle Lowry Jeremy Lamb Bojan Bogdanovic Derrick Favors Domantas Sabonis Mike Conley RJ Barrett Gordon Hayward Serge Ibaka Jarrett Allen Lonzo Ball Josh Richardson Robert Covington Dario Saric Al Horford Ja Morant Victor Oladipo Caris LeVert Aaron Gordon Myles Turner PG SG SF PF C TIER 7 TIER 7 TIER 7 TIER 7 TIER 7 Derrick White Jordan Clarkson Joe Ingles Paul Millsap Dwight Powell Jeff Teague Nicolas Batum De'Andre Hunter Kyle Kuzma Willie Cauley-Stein Shai Gilgeous-Alexander Evan Fournier Miles Bridges Wendell Carter Dwight Howard Dennis Schroder Jarrett Culver Andrew Wiggins Jonathan Isaac Marc Gasol Goran Dragic Jaylen Brown Kelly Oubre Dewayne Dedmon TIER 8 TIER 8 TIER 8 TIER 8 TIER 8 Spencer Dinwiddie Terrence Ross Rudy Gay Al-Farouq Aminu Bam Adebayo Collin Sexton Kevin Huerter Harrison Barnes Larry Nance Jr. -
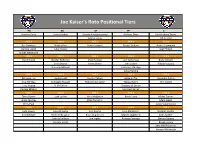
Joe Kaiser's Roto Positional Tiers
Joe Kaiser's Roto Positional Tiers TIERPG 1 TIERSG 1 TIERSF 1 PFTIER 1 TIERC 1 Stephen Curry James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns LeBron James Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Ben Simmons Bradley Beal Kawhi Leonard Pascal Siakam Andre Drummond Damian Lillard Luka Doncic Joel Embiid Russell Westbrook TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kyrie Irving DeMar DeRozan Paul George Zion Williamson Rudy Gobert Devin Booker Jimmy Butler John Collins Nikola Vucevic Donovan Mitchell LaMarcus Aldridge Julius Randle TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 De'Aaron Fox Buddy Hield Jayson Tatum Blake Griffin Deandre Ayton Jrue Holiday D'Angelo Russell Robert Covington Tobias Harris Clint Capela Trae Young CJ McCollum Draymond Green Kemba Walker Montrezl Harrell TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Terry Rozier Zach LaVine Khris Middleton Kevin Love Myles Turner Jamal Murray Otto Porter Jr. Marc Gasol Chris Paul Jonas Valanciunas TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 Kyle Lowry Lou Williams Kyle Kuzma Lauri Markkanen DeAndre Jordan Eric Bledsoe Malcolm Brogdon Bojan Bogdanovic Marvin Bagley III Enes Kanter Josh Richardson Joe Ingles Kristaps Porzingis Steven Adams Jeremy Lamb Brook Lopez Mitchell Robinson Hassan Whiteside PG SG SF PF C TIER 7 TIER 7 TIER 7 TIER 7 TIER 7 Ricky Rubio Victor Oladipo RJ Barrett Jaren Jackson Jr. Thomas Bryant Lonzo Ball Andrew Wiggins Gordon Hayward Domantas Sabonis Al Horford Mike Conley Derrick Favors Jarrett Allen Serge Ibaka Danilo Gallinari TIER 8 TIER 8 TIER 8 TIER 8 TIER 8 Ja Morant Jordan Clarkson De'Andre Hunter Aaron Gordon Dewayne Dedmon Collin Sexton Jaylen Brown Miles Bridges Paul Millsap Bam Adebayo Jeff Teague Terrence Ross Kelly Oubre Jr. -

Cleveland Cavaliers at Chicago Bulls
Cleveland Cavaliers at Chicago Bulls A review of FG% by distance, opponent FG% by distance, % of shots taken by distance, rebounds, assists, turnovers, points per game, steals, and blocks. Projected Starters Position Cavs Bulls PG Kyrie Irving Rajon Rondo SG J.R. Smith Jimmy Butler SF LeBron James Paul Zisper PF Kevin Love Nikola Mitotic C Tristan Thompson Robin Lopez Team Stats (Per Game) Offensive Distance Stats Distance Cavs Team Bulls Team Difference Stat Cavs Bulls Average Average Range FG% FG% (Advantage) Offensive Rebounds 9.3 12.4 10.1 0-3 feet 66.3% 59.7% 62.9% 6.6% (Cavs) Defensive Rebounds 34.1 33.4 33.4 3-10 feet 34.2% 45.6% 41.2% 11.4% (Bulls) Assists 22.5 22.2 22.5 10-16 feet 44.0% 39.5% 41.0% 4.5% (Cavs) Turnovers 13.5 13.5 14.0 16 feet - 3PT 41.8% 38.1% 39.9% 3.7% (Cavs) Steals 6.6 7.8 7.7 3PT 38.8% 32.9% 35.8% 6% (Cavs) Blocks 4.0 4.9 4.8 FG% 47.1% 44.2% 45.7% Defensive Distance Stats 3PT% 38.8% 32.9% 35.8% Cavs Bulls Distance Difference Opponent Opponent Average Range (Advantage) Points 110.5 102.3 105.6 FG% FG% Possessions 98.5 97.4 98.8 0-3 feet 62.8% 61.2% 62.9% 1.6% (Bulls) 3-10 feet 39.8% 41.9% 41.5% 2.1% (Cavs) 10-16 feet 40.6% 42.2% 41.2% 1.6% (Cavs) Team Stats (Per 100 Possessions) 16 feet - 3PT 40.8% 42.4% 40.2% 1.6% (Cavs) Stat Cavs Bulls Average 3PT 36.5% 35.5% 35.8% 1% (Bulls) ORTG (Points scored) 111.4 104.3 106.1 DRTG (Points allowed) 108.1 105.7 106.1 Percent of Shots Taken Distance Cavs % of Bulls % of Average Range Shots Shots Best and Worst Ranges Compared to Average 0-3 feet 28.4% 27.7% 28.8% 3-10 -
Fiuvw RQ )HE WKHQ WDNLQJ 瑨攠污瑥爠獬潴猠楮⁴桥⁴睯 潴桥爠
Page 2B East Oregonian SPORTS Wednesday, January 27, 2016 BLAZERS: Portland tied for 8th in conference Rodeo Continued from 1B team. When you overshoot the Blazers increased their journalism students at a Campbell gets your emphasis on their No. lead to 100-79 with eight Portland high school. ... “He’s a very good player, 1 and 2 strengths, it usually minutes remaining. Lillard recorded his 10th able to score in many ways, opens up other opportunities. TIP-INS double-double of the season, but I thought for the most part They had some guys jump in Kings: Sacramento a career high. big win in Denver we did a good job on him,” and take advantage of that,” forward Rudy Gay, who MIDSEASON Leonard said. “We were Karl said. sustained a left eye injury in RECHARGE East Oregonian go from outside the PRCA’s really locked in on what we Rajon Rondo had 15 Monday’s double overtime Portland has been able to top 50 to the No. 3 spot with needed to do tonight and it points and 11 assists for the loss to Charlotte, didn’t play refresh itself following an DENVER — Summer- a total $10,833 this season. was just a great team effort.” Kings, who lost in double against Portland. Karl says East coast road trip because ville bull rider Cody Trevor Kastner of Though Cousins played overtime on Monday night. he’s hopeful Gay can return of a seven-game home stand Campbell moved up to No. Ardmore, Oklahoma leads 46 minutes before fouling Portland (21-26) moved sometime during the Kings’ with plenty of rest in between 3 in this week’s PRCA world the world standings with out against Charlotte, Sacra- into a virtual tie with Sacra- upcoming two-game road games.