Setting CPU Affinity in Windows Based SMP Systems Using Java Bala Dhandayuthapani Veerasamy, Dr
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kernel-Scheduled Entities for Freebsd
Kernel-Scheduled Entities for FreeBSD Jason Evans [email protected] November 7, 2000 Abstract FreeBSD has historically had less than ideal support for multi-threaded application programming. At present, there are two threading libraries available. libc r is entirely invisible to the kernel, and multiplexes threads within a single process. The linuxthreads port, which creates a separate process for each thread via rfork(), plus one thread to handle thread synchronization, relies on the kernel scheduler to multiplex ”threads” onto the available processors. Both approaches have scaling problems. libc r does not take advantage of multiple processors and cannot avoid blocking when doing I/O on ”fast” devices. The linuxthreads port requires one process per thread, and thus puts strain on the kernel scheduler, as well as requiring significant kernel resources. In addition, thread switching can only be as fast as the kernel's process switching. This paper summarizes various methods of implementing threads for application programming, then goes on to describe a new threading architecture for FreeBSD, based on what are called kernel- scheduled entities, or scheduler activations. 1 Background FreeBSD has been slow to implement application threading facilities, perhaps because threading is difficult to implement correctly, and the FreeBSD's general reluctance to build substandard solutions to problems. Instead, two technologies originally developed by others have been integrated. libc r is based on Chris Provenzano's userland pthreads implementation, and was significantly re- worked by John Birrell and integrated into the FreeBSD source tree. Since then, numerous other people have improved and expanded libc r's capabilities. At this time, libc r is a high-quality userland implementation of POSIX threads. -

Multiplatformní Knihovna Pro Interakci S Grafickým Uživatelským Prostředím
Masarykova univerzita Fakulta}w¡¢£¤¥¦§¨ informatiky !"#$%&'()+,-./012345<yA| Multiplatformní knihovna pro interakci s grafickým uživatelským prostředím Bakalářská práce Jaromír Kala Brno, 2014 Prohlášení Prohlašuji, že tato bakalářská práce je mým původním autorským dílem, které jsem vypracoval samostatně. Všechny zdroje, prameny a literaturu, které jsem při vypracování používal nebo z nich čerpal, v práci řádně cituji s uvedením úplného odkazu na příslušný zdroj. Jaromír Kala Vedoucí práce: RNDr. Pavel Troubil ii Poděkování Rád bych poděkoval RNDr. Pavlu Troubilovi za cenné rady, věcné připomínky a ochotu při konzultacích a vypracování bakalářské práce. iii Shrnutí Cílem bakalářské práce bylo vytvořit multiplatformní knihovnu pro manipulaci s grafickým uživatelským rozhraním. Vzniklá knihovna WDDMan podporuje detekci připojených monitorů a jejich rozlišení, zjištění otevřených oken a manipulaci s nimi (zavření, změny velikostí a přesuny) a detekci virtuálních ploch. Knihovna WDDMan funguje na operačních systémech skupiny Windows, Linux a Mac OS. Kni- hovna s podobnou funkcionalitou doposud nebyla k dispozici a bude použita v middleware CoUniverse pro manipulaci s objekty videokon- ferenčních nástrojů. Prostředí CoUniverse se využije pro vzdálené tlu- močení přednášek pro Středisko pro pomoc studentům se specifickými nároky Masarykovy univerzity. Knihovna WDDMan bude zveřejněna pod otevřenou licencí k volnému užití. Součástí knihovny je i anglická dokumentace a ukázkový a testovací příklad. iv Klíčová slova CoUniverse, Windows API, XLib, JNA, AppleScript, GUI v Obsah 1 Úvod ...............................2 2 Popis použitých technologií .................4 2.1 Java Native Access .....................4 2.1.1 Popis knihovny Java Native Access . .4 2.1.2 Použití JNA v knihovně WDDMan . .7 2.2 Windows API ........................8 2.3 X Window System a Xlib .................9 2.4 AppleScript ........................ -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

T U M a Digital Wallet Implementation for Anonymous Cash
Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Oliver R. Broome Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Implementierung eines digitalen Wallets for anonyme Währungen Author Oliver R. Broome Supervisor Prof. Dr.-Ing. Georg Carle Advisor Sree Harsha Totakura, M. Sc. Date October 15, 2015 Informatik VIII Chair for Network Architectures and Services I conrm that this thesis is my own work and I have documented all sources and material used. Garching b. München, October 15, 2015 Signature Abstract GNU Taler is a novel approach to digital payments with which payments are performed with cryptographically generated representations of actual currencies. The main goal of GNU Taler is to allow taxable anonymous payments to non-anonymous merchants. This thesis documents the implementation of the Android version of the GNU Taler wallet, which allows users to create new Taler-based funds and perform payments with them. Zusammenfassung GNU Taler ist ein neuartiger Ansatz für digitales Bezahlen, bei dem Zahlungen mit kryptographischen Repräsentationen von echten Währungen getätigt werden. Das Hauptziel von GNU Taler ist es, versteuerbare, anonyme Zahlungen an nicht-anonyme Händler zu ermöglichen. Diese Arbeit dokumentiert die Implementation der Android-Version des Taler-Portemonnaies, der es Benutzern erlaubt, neues Taler-Guthaben zu erzeugen und mit ihnen Zahlungen zu tätigen. I Contents 1 Introduction 1 1.1 GNU Taler . .2 1.2 Goals of the thesis . .2 1.3 Outline . .3 2 Implementation prerequisites 5 2.1 Native libraries . .5 2.1.1 Libgcrypt . -

Developers Guide
jjPPrroodduuccttiivviittyy LLLLCC Protection User Guide Developers Guide Licensing Toolkit Protect your investments Protect your with Protection! http://www.jproductivity.com v 5 . 2 ! tm Revision 397 - 1/7/20 Notice of Copyright Published by jProductivity, LLC Copyright ©2003-2019 All rights reserved. Registered Trademarks and Proprietary Names Product names mentioned in this document may be trademarks or registered trademarks of jProductivity, LLC or other hardware, software, or service providers and are used herein for identification purposes only. Applicability This document applies to Protection! v5.2 software. 2 Protection! Developers Guide v5.2 Copyright © 2003-2019 jProductivity L.L.C. http://www. jproductivity.com Contents Contents ....................................................................................................................... 3 1. Protection! Licensing Toolkit Concepts ........................................................................... 6 1.1 Key Concepts ................................................................................................. 6 1.1.1 License File .............................................................................................. 6 1.1.2 Protection! Control Center ......................................................................... 6 1.1.3 Secret Storage ......................................................................................... 6 1.2 Protection! Process ......................................................................................... -

2. Virtualizing CPU(2)
Operating Systems 2. Virtualizing CPU Pablo Prieto Torralbo DEPARTMENT OF COMPUTER ENGINEERING AND ELECTRONICS This material is published under: Creative Commons BY-NC-SA 4.0 2.1 Virtualizing the CPU -Process What is a process? } A running program. ◦ Program: Static code and static data sitting on the disk. ◦ Process: Dynamic instance of a program. ◦ You can have multiple instances (processes) of the same program (or none). ◦ Users usually run more than one program at a time. Web browser, mail program, music player, a game… } The process is the OS’s abstraction for execution ◦ often called a job, task... ◦ Is the unit of scheduling Program } A program consists of: ◦ Code: machine instructions. ◦ Data: variables stored and manipulated in memory. Initialized variables (global) Dynamically allocated (malloc, new) Stack variables (function arguments, C automatic variables) } What is added to a program to become a process? ◦ DLLs: Libraries not compiled or linked with the program (probably shared with other programs). ◦ OS resources: open files… Program } Preparing a program: Task Editor Source Code Source Code A B Compiler/Assembler Object Code Object Code Other A B Objects Linker Executable Dynamic Program File Libraries Loader Executable Process in Memory Process Creation Process Address space Code Static Data OS res/DLLs Heap CPU Memory Stack Loading: Code OS Reads on disk program Static Data and places it into the address space of the process Program Disk Eagerly/Lazily Process State } Each process has an execution state, which indicates what it is currently doing ps -l, top ◦ Running (R): executing on the CPU Is the process that currently controls the CPU How many processes can be running simultaneously? ◦ Ready/Runnable (R): Ready to run and waiting to be assigned by the OS Could run, but another process has the CPU Same state (TASK_RUNNING) in Linux. -

Processor Affinity Or Bound Multiprocessing?
Processor Affinity or Bound Multiprocessing? Easing the Migration to Embedded Multicore Processing Shiv Nagarajan, Ph.D. QNX Software Systems [email protected] Processor Affinity or Bound Multiprocessing? QNX Software Systems Abstract Thanks to higher computing power and system density at lower clock speeds, multicore processing has gained widespread acceptance in embedded systems. Designing systems that make full use of multicore processors remains a challenge, however, as does migrating systems designed for single-core processors. Bound multiprocessing (BMP) can help with these designs and these migrations. It adds a subtle but critical improvement to symmetric multiprocessing (SMP) processor affinity: it implements runmask inheritance, a feature that allows developers to bind all threads in a process or even a subsystem to a specific processor without code changes. QNX Neutrino RTOS Introduction The QNX® Neutrino® RTOS has been Effective use of multicore processors can multiprocessor capable since 1997, and profoundly improve the performance of embedded is deployed in hundreds of systems and applications ranging from industrial control systems thousands of multicore processors in to multimedia platforms. Designing systems that embedded environments. It supports make effective use of multiprocessors remains a AMP, SMP — and BMP. challenge, however. The problem is not just one of making full use of the new multicore environments to optimize performance. Developers must not only guarantee that the systems they themselves write will run correctly on multicore processors, but they must also ensure that applications written for single-core processors will not fail or cause other applications to fail when they are migrated to a multicore environment. To complicate matters further, these new and legacy applications can contain third-party code, which developers may not be able to change. -

CPU Scheduling
CPU Scheduling CS 416: Operating Systems Design Department of Computer Science Rutgers University http://www.cs.rutgers.edu/~vinodg/teaching/416 What and Why? What is processor scheduling? Why? At first to share an expensive resource ± multiprogramming Now to perform concurrent tasks because processor is so powerful Future looks like past + now Computing utility – large data/processing centers use multiprogramming to maximize resource utilization Systems still powerful enough for each user to run multiple concurrent tasks Rutgers University 2 CS 416: Operating Systems Assumptions Pool of jobs contending for the CPU Jobs are independent and compete for resources (this assumption is not true for all systems/scenarios) Scheduler mediates between jobs to optimize some performance criterion In this lecture, we will talk about processes and threads interchangeably. We will assume a single-threaded CPU. Rutgers University 3 CS 416: Operating Systems Multiprogramming Example Process A 1 sec start idle; input idle; input stop Process B start idle; input idle; input stop Time = 10 seconds Rutgers University 4 CS 416: Operating Systems Multiprogramming Example (cont) Process A Process B start B start idle; input idle; input stop A idle; input idle; input stop B Total Time = 20 seconds Throughput = 2 jobs in 20 seconds = 0.1 jobs/second Avg. Waiting Time = (0+10)/2 = 5 seconds Rutgers University 5 CS 416: Operating Systems Multiprogramming Example (cont) Process A start idle; input idle; input stop A context switch context switch to B to A Process B idle; input idle; input stop B Throughput = 2 jobs in 11 seconds = 0.18 jobs/second Avg. -
CPU Scheduling
Chapter 5: CPU Scheduling Operating System Concepts – 10th Edition Silberschatz, Galvin and Gagne ©2018 Chapter 5: CPU Scheduling Basic Concepts Scheduling Criteria Scheduling Algorithms Thread Scheduling Multi-Processor Scheduling Real-Time CPU Scheduling Operating Systems Examples Algorithm Evaluation Operating System Concepts – 10th Edition 5.2 Silberschatz, Galvin and Gagne ©2018 Objectives Describe various CPU scheduling algorithms Assess CPU scheduling algorithms based on scheduling criteria Explain the issues related to multiprocessor and multicore scheduling Describe various real-time scheduling algorithms Describe the scheduling algorithms used in the Windows, Linux, and Solaris operating systems Apply modeling and simulations to evaluate CPU scheduling algorithms Operating System Concepts – 10th Edition 5.3 Silberschatz, Galvin and Gagne ©2018 Basic Concepts Maximum CPU utilization obtained with multiprogramming CPU–I/O Burst Cycle – Process execution consists of a cycle of CPU execution and I/O wait CPU burst followed by I/O burst CPU burst distribution is of main concern Operating System Concepts – 10th Edition 5.4 Silberschatz, Galvin and Gagne ©2018 Histogram of CPU-burst Times Large number of short bursts Small number of longer bursts Operating System Concepts – 10th Edition 5.5 Silberschatz, Galvin and Gagne ©2018 CPU Scheduler The CPU scheduler selects from among the processes in ready queue, and allocates the a CPU core to one of them Queue may be ordered in various ways CPU scheduling decisions may take place when a -
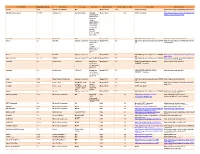
Third Party Version
Third Party Name Third Party Version Manufacturer License Type Comments Merge Product Merge Product Versions License details Software source autofac 3.5.2 Autofac Contributors MIT Merge Cardio 10.2 SOUP repository https://www.nuget.org/packages/Autofac/3.5 .2 Gibraltar Loupe Agent 2.5.2.815 eSymmetrix Gibraltor EULA Gibraltar Merge Cardio 10.2 SOUP repository https://my.gibraltarsoftware.com/Support/Gi Loupe Agent braltar_2_5_2_815_Download will be used within the Cardio Application to view events and metrics so you can resolve support issues quickly and easily. Modernizr 2.8.3 Modernizr MIT Merge Cadio 6.0 http://modernizr.com/license/ http://modernizr.com/download/ drools 2.1 Red Hat Apache License 2.0 it is a very old Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/drools/dro version of 2.0 ols-spring/2.1 drools. Current version is 6.2 and license type is changed too drools 6.3 Red Hat Apache License 2.0 Merge PACS 7.1 http://www.apache.org/licenses/LICENSE- https://github.com/droolsjbpm/drools/releases/ta 2.0 g/6.3.0.Final HornetQ 2.2.13 v2.2..13 JBOSS Apache License 2.0 part of JBOSS Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/org.hornet 2.0 q/hornetq-core/2.2.13.Final jcalendar 1.0 toedter.com LGPL v2.1 MergePacs Merge PACS 7.0 GNU LESSER GENERAL PUBLIC http://toedter.com/jcalendar/ server uses LICENSE Version 2. v1, and viewer uses v1.3. -

SQL Server 2005 on the IBM Eserver Xseries 460 Enterprise Server
IBM Front cover SQL Server 2005 on the IBM Eserver xSeries 460 Enterprise Server Describes how “scale-up” solutions suit enterprise databases Explains the XpandOnDemand features of the xSeries 460 Introduces the features of the new SQL Server 2005 Michael Lawson Yuichiro Tanimoto David Watts ibm.com/redbooks Redpaper International Technical Support Organization SQL Server 2005 on the IBM Eserver xSeries 460 Enterprise Server December 2005 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. First Edition (December 2005) This edition applies to Microsoft SQL Server 2005 running on the IBM Eserver xSeries 460. © Copyright International Business Machines Corporation 2005. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix The team that wrote this Redpaper . ix Become a published author . .x Comments welcome. xi Chapter 1. The x460 enterprise server . 1 1.1 Scale up versus scale out . 2 1.2 X3 Architecture . 2 1.2.1 The X3 Architecture servers . 2 1.2.2 Key features . 3 1.2.3 IBM XA-64e third-generation chipset . 4 1.2.4 XceL4v cache . 6 1.3 XpandOnDemand . 6 1.4 Memory subsystem . 7 1.5 Multi-node configurations . 9 1.5.1 Positioning the x460 and the MXE-460. 11 1.5.2 Node connectivity . 12 1.5.3 Partitioning . 13 1.6 64-bit with EM64T . 14 1.6.1 What makes a 64-bit processor . 14 1.6.2 Intel Xeon with EM64T . -

Support for NUMA Hardware in Helenos
Charles University in Prague Faculty of Mathematics and Physics MASTER THESIS Vojtˇech Hork´y Support for NUMA hardware in HelenOS Department of Distributed and Dependable Systems Supervisor: Mgr. Martin Dˇeck´y Study Program: Software Systems 2011 I would like to thank my supervisor, Martin Dˇeck´y,for the countless advices and the time spent on guiding me on the thesis. I am grateful that he introduced HelenOS to me and encouraged me to add basic NUMA support to it. I would also like to thank other developers of HelenOS, namely Jakub Jerm´aˇrand Jiˇr´ı Svoboda, for their assistance on the mailing list and for creating HelenOS. I would like to thank my family and my closest friends too { for their patience and continuous support. I declare that I carried out this master thesis independently, and only with the cited sources, literature and other professional sources. I understand that my work relates to the rights and obligations under the Act No. 121/2000 Coll., the Copyright Act, as amended, in particular the fact that the Charles University in Prague has the right to conclude a license agreement on the use of this work as a school work pursuant to Section 60 paragraph 1 of the Copyright Act. Prague, August 2011 Vojtˇech Hork´y 2 N´azevpr´ace:Podpora NUMA hardwaru pro HelenOS Autor: Vojtˇech Hork´y Katedra (´ustav): Matematicko-fyzik´aln´ıfakulta univerzity Karlovy Vedouc´ıpr´ace:Mgr. Martin Dˇeck´y e-mail vedouc´ıho:[email protected]ff.cuni.cz Abstrakt: C´ılemt´etodiplomov´epr´aceje rozˇs´ıˇritoperaˇcn´ısyst´emHelenOS o podporu ccNUMA hardwaru.