Trusted Execution: Applications and Verification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Project Glossary Document # 17100-1.02
Multi-Modal Traveler Information System Project Glossary Document # 17100-1.02 Prepared by: De Leuw, Cather & Company Issue Date: November 4, 1997 GCM ITS Priority Corridor Multi-Modal Traveler Information System November 4, 1997 MULTI-MODAL TRAVELER INFORMATION SYSTEM SYSTEM GLOSSARY TABLE OF CONTENTS 1 INTRODUCTION ....................................................... 1-1 2 DEFINITIONS .......................................................... 2-1 3 ABBREVIATIONS AND ACRONYMS ...................................... 3-1 Document # 17100-1.02 i Project Glossary GCM ITS Priority Corridor Multi-Modal Traveler Information System November 4, 1997 MULTI-MODAL TRAVELER INFORMATION SYSTEM SYSTEM (MMTIS) GLOSSARY 1 INTRODUCTION This report provides definitions for words or acronyms that are used in the ITS, transportation and communication industries and throughout the MMTIS documentation (listed below): • Document #17150 - Gateway TIS System Definition Document • Document #17200 - GCM Corridor Architecture Functional Requirements • Document #17250 - Gateway Functional Requirements • Document #17300 - GCM Corridor Architecture Interface Control Requirements • Document #17350 - Gateway Interface Control Requirements • Working Paper #18250 - Cellular 911 - State of the Practice • Working Paper #18380 - GCM Corridor User Needs and Data Exchange Elements • Working Paper #18400 - Current and Proposed ITS Initiatives • Working Paper #18500 - GCM MMTIS Strategic Plan • Working Paper #18520 - Performance Criteria for Evaluating GCM Corridor Strategies -

AIX Commands Reference Vol.2 Dadmin to Hyphen
Bull AIX Commands Reference Vol.2 dadmin to hyphen AIX ORDER REFERENCE 86 A2 39JX 02 Bull AIX Commands Reference Vol.2 dadmin to hyphen AIX Software April 2000 BULL ELECTRONICS ANGERS CEDOC 34 Rue du Nid de Pie – BP 428 49004 ANGERS CEDEX 01 FRANCE ORDER REFERENCE 86 A2 39JX 02 The following copyright notice protects this book under the Copyright laws of the United States of America and other countries which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright Bull S.A. 1992, 2000 Printed in France Suggestions and criticisms concerning the form, content, and presentation of this book are invited. A form is provided at the end of this book for this purpose. To order additional copies of this book or other Bull Technical Publications, you are invited to use the Ordering Form also provided at the end of this book. Trademarks and Acknowledgements We acknowledge the right of proprietors of trademarks mentioned in this book. R AIX is a registered trademark of International Business Machines Corporation, and is being used under licence. UNIX is a registered trademark in the United States of America and other countries licensed exclusively through the Open Group. Year 2000 The product documented in this manual is Year 2000 Ready. The information in this document is subject to change without notice. Groupe Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. Commands Reference, Volume 2 Table -

PC Watch Monthly Newsletter
Perspectives PC Watch Monthly Newsletter PC Watch provides an invaluable source of information on European PC Production and related issues. This Neiusletter brings together the combined intelligence of the Worldwide Electronics Applications Group and the Worldwide Personal Computer Group. Packard Bell Acquires Zenith Data Systems Page 1 Intel Introduces Fourth Generation Pentium Chip Sets Page 2 Memory Developments in the PC Market Page 3 Intel's Motherboard Operation's Semiconductor TAM Page 5 Dell Computer Corporation—Channels and Manufacturing Page 7 Packard Bell Acquires Zenith Data Systems Packard Bell, Groupe Bull and NEC have reached an agreement that gives Packard Bell control of the Bull subsidiary. Zenith Data Systems (ZDS). Under the agreement, NEC will contribute $283 million in new investment alongside Bull's transfer of ZDS, which is valued at $367 milUon. Groupe Bull and NEC will receive convertible preference shares in the combined organization, giv ing each 19.9 percent of the new company, just below the 20 percent level at which they would have to consolidate the new company's results in their own figures. Dataquest estimates that Packard Bell was the world's fourth-largest PC maker in 1995 and the second-largest behind Compaq in the United States. ZDS was the thirteenth-largest PC vendor in the world and fourteenth in the United States. Combining their shipments would still leave Packard Bell fourth in the world. It would, however, become the largest PC vendor in the United States. In Europe Packard Bell was seventh and ZDS was thirteenth. Combining the two w^ould result in them rising to fourth position after Compaq, IBM and Apple. -

Operating RISC: UNIX Standards in the 1990S
Operating RISC: UNIX Standards in the 1990s This case was written by Will Mitchell and Paul Kritikos at the University of Michigan. The case is based on public sources. Some figures are based on case-writers' estimates. We appreciate comments from David Girouard, Robert E. Thomas and Michael Wolff. The note "Product Standards and Competitive Advantage" (Mitchell 1992) supplements this case. The latest International Computerquest Corporation analysis of the market for UNIX- based computers landed on three desks on the same morning. Noel Sharp, founder, chief executive officer, chief engineer and chief bottle washer for the Superbly Quick Architecture Workstation Company (SQAWC) in Mountain View, California hoped to see strong growth predicted for the market for systems designed to help architects improve their designs. In New York, Bo Thomas, senior strategist for the UNIX systems division of A Big Computer Company (ABCC), hoped that general commercial markets for UNIX-based computer systems would show strong growth, but feared that the company's traditional mainframe and mini-computer sales would suffer as a result. Airborne in the middle of the Atlantic, Jean-Helmut Morini-Stokes, senior engineer for the UNIX division of European Electronic National Industry (EENI), immediately looked to see if European companies would finally have an impact on the American market for UNIX-based systems. After looking for analysis concerning their own companies, all three managers checked the outlook for the alliances competing to establish a UNIX operating system standard. Although their companies were alike only in being fictional, the three managers faced the same product standards issues. How could they hasten the adoption of a UNIX standard? The market simply would not grow until computer buyers and application software developers could count on operating system stability. -

IBM Highlights, 1996-1999
IBM HIGHLIGHTS, 1996 - 1999 Year Page(s) 1996 2 - 7 1997 7 - 13 1998 13- 21 1999 21 - 26 November 2004 1406HE05 2 1996 Business Performance IBM revenue reaches $75.94 billion, an increase of six percent over 1995, and earnings grow by nearly 30 percent to $5.42 billion. There are 240,615 employees and 622,594 stockholders at year end. Speaking in Atlanta to a group of shareholders, analysts and reporters at the corporation’s annual meeting, IBM chairman Louis V. Gerstner, Jr., discusses IBM’s condition, prospects for growth and the importance of network computing to the company’s future. IBM reaches agreement with the United States Department of Justice to terminate within five years all remaining provisions of the Consent Decree first entered into by IBM and the U.S. government in 1956. Organization IBM forms the Network Computer Division in November. The company says it will operate its worldwide services business under a single brand: IBM Global Services. IBM puts its industry-specific business units on a single global general manager. IBM and Tivoli Systems Inc. enter a merger agreement. Tivoli is a leading provider of systems management software and services for distributed client/server networks of personal computers and workstations. IBM’s acquisition of Tivoli extends the company’s strength in host-based systems management to multiplatform distributed systems. IBM and Edmark Corporation, a developer and publisher of consumer and education software, complete a merger in December. IBM acquires The Wilkerson Group, one of the world’s oldest and largest consulting firms dedicated to the pharmaceutical and medical products industry. -

Alerte Internet Sous Surveillance
Décembre 2011 Alerte : internet sous surveillance ! État des lieux, exportations et contrôle démocratique des outils de surveillance de l’Internet Le « Deep Packet Inspection », exportations d’un savoir-faire français Table ronde du mercredi 14 décembre 2011 à l’Assemblée Nationale à l’initiative et invitation de monsieur le député Christian Paul. Compte rendu textuel non officiel de l’enregistrement sonore agrémenté de liens référents et d’annexes pour comprendre des enjeux discutés. Document finalisé le 31 décembre 2011. Mis à disposition sous licence Creative Commons. Table ronde – Etat des lieux, exportations et contrôle démocratique des outils de surveillance de 2 l’Internet. Table ronde – Etat des lieux, exportations et contrôle démocratique des outils de surveillance de 3 l’Internet. Observations des rédacteurs Cette transcription réalisée -initialement par Lpenet, Patchidem et Seb, puis corrigée, sourcée et mise en forme par des lecteurs de Reflets.info comme Mi0 et d’autre volontaires- à partir du document sonore n’est en rien officielle et ne peut se prévaloir comme telle. Réalisée par des amateurs, dans un outil de traitement de texte grand public, elle peut ne pas observer les règles typographiques en vigueur. Les propos des différents intervenants ont été dans la mesure du possible le plus fidèlement rapportés aux dépens parfois de règles syntaxiques et orthographiques afin de ne pas perdre la spontanéité des échanges et débats. Seules, quand la compréhension des propos l’exigeait, des formules ont été arrangées (syntaxe, ponctuation, répétitions) afin de ne pas perdre en clarté. Certains propos n’ont pu être attribués à un intervenant particulier, faute de savoir qui parlait lors des échanges ; ces derniers sont identifiés comme « intervenant non reconnu ». -

AIX 4.3 Quick Beginnings
Bull AIX 4.3 Quick Beginnings AIX ORDER REFERENCE 86 A2 75HX 04 Bull AIX 4.3 Quick Beginnings AIX Software September 1999 BULL ELECTRONICS ANGERS CEDOC 34 Rue du Nid de Pie – BP 428 49004 ANGERS CEDEX 01 FRANCE ORDER REFERENCE 86 A2 75HX 04 The following copyright notice protects this book under the Copyright laws of the United States of America and other countries which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright Bull S.A. 1992, 1999 Printed in France Suggestions and criticisms concerning the form, content, and presentation of this book are invited. A form is provided at the end of this book for this purpose. To order additional copies of this book or other Bull Technical Publications, you are invited to use the Ordering Form also provided at the end of this book. Trademarks and Acknowledgements We acknowledge the right of proprietors of trademarks mentioned in this book. AIXR is a registered trademark of International Business Machines Corporation, and is being used under licence. UNIX is a registered trademark in the United States of America and other countries licensed exclusively through the Open Group. Year 2000 The product documented in this manual is Year 2000 Ready. The information in this document is subject to change without notice. Groupe Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. About This Book: AIX 4.3 Quick Beginnings This book contains information for first–time users who have little or no experience with the AIX operating system. -

AIX 4.3 System Management Guide Communications and Networks
Bull AIX 4.3 System Management Guide Communications and Networks AIX ORDER REFERENCE 86 A2 31JX 02 Bull AIX 4.3 System Management Guide Communications and Networks AIX Software October 1999 BULL ELECTRONICS ANGERS CEDOC 34 Rue du Nid de Pie – BP 428 49004 ANGERS CEDEX 01 FRANCE ORDER REFERENCE 86 A2 31JX 02 The following copyright notice protects this book under the Copyright laws of the United States of America and other countries which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright Bull S.A. 1992, 1999 Printed in France Suggestions and criticisms concerning the form, content, and presentation of this book are invited. A form is provided at the end of this book for this purpose. To order additional copies of this book or other Bull Technical Publications, you are invited to use the Ordering Form also provided at the end of this book. Trademarks and Acknowledgements We acknowledge the right of proprietors of trademarks mentioned in this book. AIXR is a registered trademark of International Business Machines Corporation, and is being used under licence. UNIX is a registered trademark in the United States of America and other countries licensed exclusively through the Open Group. Year 2000 The product documented in this manual is Year 2000 Ready. The information in this document is subject to change without notice. Groupe Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. About This Book This book is for AIX system administrators who maintain the system’s network connections. -

System Management Guide Communications and Networks
Bull System Management Guide Communications and Networks AIX ORDER REFERENCE 86 A2 27EF 03 Bull System Management Guide Communications and Networks AIX Software June 2003 BULL CEDOC 357 AVENUE PATTON B.P.20845 49008 ANGERS CEDEX 01 FRANCE ORDER REFERENCE 86 A2 27EF 03 The following copyright notice protects this book under the Copyright laws of the United States of America and other countries which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright Bull S.A. 1992, 2003 Printed in France Suggestions and criticisms concerning the form, content, and presentation of this book are invited. A form is provided at the end of this book for this purpose. To order additional copies of this book or other Bull Technical Publications, you are invited to use the Ordering Form also provided at the end of this book. Trademarks and Acknowledgements We acknowledge the right of proprietors of trademarks mentioned in this book. AIXR is a registered trademark of International Business Machines Corporation, and is being used under licence. UNIX is a registered trademark in the United States of America and other countries licensed exclusively through the Open Group. Linux is a registered trademark of Linus Torvalds. The information in this document is subject to change without notice. Groupe Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. About This Book This book is for system administrators who maintain the operating system’s network connections. Familiarity with the Base Operating System and the material covered in AIX 5L Version 5.2 System Management Guide: Operating System and Devices and AIX 5L Version 5.2 System User’s Guide: Communications and Networks is necessary. -

AIX 5L System User's Guide Communications and Network
Bull AIX 5L System User’s Guide Communications and Network AIX ORDER REFERENCE 86 A2 25EF 02 Bull AIX 5L System User’s Guide Communications and Network AIX Software October 2002 BULL CEDOC 357 AVENUE PATTON B.P.20845 49008 ANGERS CEDEX 01 FRANCE ORDER REFERENCE 86 A2 25EF 02 The following copyright notice protects this book under the Copyright laws of the United States of America and other countries which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright Bull S.A. 1992, 2002 Printed in France Suggestions and criticisms concerning the form, content, and presentation of this book are invited. A form is provided at the end of this book for this purpose. To order additional copies of this book or other Bull Technical Publications, you are invited to use the Ordering Form also provided at the end of this book. Trademarks and Acknowledgements We acknowledge the right of proprietors of trademarks mentioned in this book. AIXR is a registered trademark of International Business Machines Corporation, and is being used under licence. UNIX is a registered trademark in the United States of America and other countries licensed exclusively through the Open Group. The information in this document is subject to change without notice. Groupe Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. About This Book This book describes the following communications applications: Mail, Message Handler (MH), Transmission Control Protocol/Internet Protocol (TCP/IP), Basic Networking Utilities (BNU), and Asynchronous Terminal Emulation (ATE). -
The Organizational and Geographic Configuration of the Personal Computer Value Chain
Kenney text.qxd 8/1/03 8:55 AM Page 111 part two Kenney text.qxd 8/1/03 8:55 AM Page 112 Kenney text.qxd 8/1/03 8:55 AM Page 113 chapter five The Organizational and Geographic Configuration of the Personal Computer Value Chain james curry martin kenney Frederick Jameson (1991), in one of his ruminations on postmodernism, re- marks that the personal computer (PC) comes up short as a visual emblem in an era that is, at least, in part defined by digital technology.1 Notwithstanding the potent symbolism of the beige (or black) box, the PC falls short as an art object. And yet, the installed base of 500 million PCs worldwide not only pro- vides desktop computing to hundreds of millions but also makes the PC the de- vice that enabled the Internet to become more than just a curiosity for research scientists affiliated with universities and government laboratories. Even if it is not iconic, the PC has in some way touched every other industry discussed in this book, as it has become the ubiquitous information appliance, and the Dell business model has become universally admired. The production and distribu- tion of the PC illustrates, nearly perfectly, the dynamics discussed in the Intro- duction. The tension between the global and the local suffuses the PC industries and is derived from the modular design of the personal computer system. The phys- ical components of the greatest value and technical virtuosity are the semicon- ductors and the hard disk drive. We omit the monitor in this statement, though as Murtha, Lenway, and Hart show in Chapter 7, the flat panel display (FPD) is certainly worthy of placement in this group of components. -
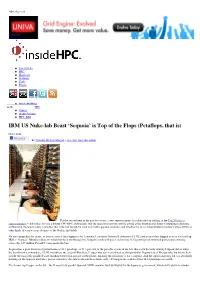
IBM US Nuke-Lab Beast 'Sequoia' Is Top of the Flops (Petaflops, That Is) | Insidehpc.Com
Advertisement insideHPC Skip to content Latest News HPC Hardware Software Tools Events inside-BigData Search Rock Stars of HPC Videos inside-Startups HPC Jobs IBM US Nuke-lab Beast ‘Sequoia’ is Top of the Flops (Petaflops, that is) 06.18.2012 Mi piace By Timothy Prickett Morgan • Get more from this author For the second time in the past two years, a new supercomputer has taken the top ranking in the Top 500 list of supercomputers – and it does not use a hybrid CPU-GPU architecture. But the question everyone will be asking at the International Super Computing conference in Hamburg, Germany today is whether this is the last hurrah for such monolithic parallel machines and whether the move toward hybrid machines where GPUs or other kinds of coprocessors do most of the work is inevitable. No one can predict the future, of course, even if they happen to be Lawrence Livermore National Laboratory (LLNL) and even if they happen to have just fired up IBM’s “Sequoia” BlueGene/Q beast, which has been put through the Linpack benchmark paces, delivering 16.32 petaflops of sustained performance running across the 1.57 million PowerPC cores inside the box. Sequoia has a peak theoretical performance of 20.1 petaflops, so 81.1 per cent of the possible clocks in the box that could do work running Linpack did so when the benchmark test was done. LLNL was where the original BlueGene/L super was commercialized, so that particular Department of Energy nuke lab knows how to tune the massively parallel Power machine better than anyone on the planet, meaning the efficiency is not a surprise.