Nosql Innovators – Part 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

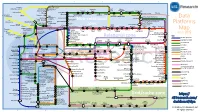
Data Platforms Map from 451 Research
1 2 3 4 5 6 Azure AgilData Cloudera Distribu2on HDInsight Metascale of Apache Kaa MapR Streams MapR Hortonworks Towards Teradata Listener Doopex Apache Spark Strao enterprise search Apache Solr Google Cloud Confluent/Apache Kaa Al2scale Qubole AWS IBM Azure DataTorrent/Apache Apex PipelineDB Dataproc BigInsights Apache Lucene Apache Samza EMR Data Lake IBM Analy2cs for Apache Spark Oracle Stream Explorer Teradata Cloud Databricks A Towards SRCH2 So\ware AG for Hadoop Oracle Big Data Cloud A E-discovery TIBCO StreamBase Cloudera Elas2csearch SQLStream Data Elas2c Found Apache S4 Apache Storm Rackspace Non-relaonal Oracle Big Data Appliance ObjectRocket for IBM InfoSphere Streams xPlenty Apache Hadoop HP IDOL Elas2csearch Google Azure Stream Analy2cs Data Ar2sans Apache Flink Azure Cloud EsgnDB/ zone Platforms Oracle Dataflow Endeca Server Search AWS Apache Apache IBM Ac2an Treasure Avio Kinesis LeanXcale Trafodion Splice Machine MammothDB Drill Presto Big SQL Vortex Data SciDB HPCC AsterixDB IBM InfoSphere Towards LucidWorks Starcounter SQLite Apache Teradata Map Data Explorer Firebird Apache Apache JethroData Pivotal HD/ Apache Cazena CitusDB SIEM Big Data Tajo Hive Impala Apache HAWQ Kudu Aster Loggly Ac2an Ingres Sumo Cloudera SAP Sybase ASE IBM PureData January 2016 Logic Search for Analy2cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO Splunk Maana Rela%onal zone B LogLogic EnterpriseDB SQream General purpose Postgres-XL Microso\ Ry\ X15 So\ware Oracle IBM SAP SQL Server Oracle Teradata Specialist analy2c PostgreSQL Exadata -
![LIST of NOSQL DATABASES [Currently 150]](https://docslib.b-cdn.net/cover/8918/list-of-nosql-databases-currently-150-418918.webp)
LIST of NOSQL DATABASES [Currently 150]
Your Ultimate Guide to the Non - Relational Universe! [the best selected nosql link Archive in the web] ...never miss a conceptual article again... News Feed covering all changes here! NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above. [based on 7 sources, 14 constructive feedback emails (thanks!) and 1 disliking comment . Agree / Disagree? Tell me so! By the way: this is a strong definition and it is out there here since 2009!] LIST OF NOSQL DATABASES [currently 150] Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3] Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

The Forrester Wave™: In-Memory Database Platforms, Q3 2015 by Noel Yuhanna August 3, 2015
FOR ENTERPRISE ARCHITECTURE PROFESSIONALS The Forrester Wave™: In-Memory Database Platforms, Q3 2015 by Noel Yuhanna August 3, 2015 Why Read This Report Key Takeaways The in-memory database platform represents a SAP, Oracle, IBM, Microsoft, And Teradata new space within the broader data management Lead The Pack market. Enterprise architecture (EA) professionals Forrester’s research uncovered a market in which invest in in-memory database platforms to SAP, Oracle, IBM, Microsoft, and Teradata lead support real-time analytics and extreme the pack. MemSQL, Kognitio, VoltDB, DataStax, transactions in the face of unpredictable mobile, Aerospike, and Starcounter offer competitive Internet of Things (IoT), and web workloads. options. Application developers use them to build new The In-Memory Database Platform Market Is applications that deliver performance and New But Growing Rapidly responsiveness at the fastest possible speed. The in-memory database market is new but Forrester identified the 11 most significant growing fast as more enterprise architecture software providers — Aerospike, DataStax, professionals see in-memory as a way to address IBM, Kognitio, MemSQL, Microsoft, Oracle, their top data management challenges, especially SAP, Starcounter, Teradata, and VoltDB — in the to support low-latency access to critical data for category and researched, analyzed, and scored transactional or analytical workloads. them against 19 criteria. This report details how well each vendor fulfills Forrester’s criteria and Scale, Performance, And Innovation where the vendors stand in relation to each Distinguish The In-Memory Database Leaders other to meet next-generation real-time data The Leaders we identified offer high-performance, requirements. scalable, secure, and flexible in-memory database solutions. -

Pushing Enterprise Software to the Next Level Self-Contained Web Applications on In-Memory Platforms
Pushing Enterprise Software to the Next Level Self-contained Web Applications on In-Memory Platforms Michał Nosek Starcounter AB Who am I? ▪ Michał Nosek Software Engineer, Technical Sales Engineer – Starcounter http://starcounter.com ▪ Github: mmnosek LinkedIn: https://www.linkedin.com/in/mmnosek E-mail: [email protected] Twitter: @mmnosek On Today’s Agenda 01 Setting the Stage RAM Memory Modern WEB SCS Architecture 02 In-Memory Application Platform Architecture Single App Integration Demo Future Enterprise Software of Today Monolith Micro-Services ▪ Bad maintainability ▪ Orchestration ▪ Long builds ▪ Eventual consistency ▪ Technology lock-in ▪ Communication problems ▪ Long TTM ▪ Complexity ▪ Poor scalability Wirth’s law “What Intel giveth, Microsoft taketh away.” “What Andy giveth, Bill taketh away” On Today’s Agenda 01 Setting the Stage RAM Memory Modern WEB SCS Architecture 02 In-Memory Application Platform Architecture Single App Integration Demo Future RAM Prices Price of 1MB in USD over time 1000,00000 100,00000 10,00000 1,00000 0,10000 USD 0,01000 0,00100 0,00010 0,00001 1980 1990 2000 2010 2020 Year https://jcmit.net/memoryprice.htm Conventional In-Memory Conventional In-Memory Pros and Cons Pros Cons ▪ Getting faster ▪ Communication isn’t faster ▪ Better utilised by modern CPUs ▪ It’s not durable ▪ Not getting cheaper anymore? On Today’s Agenda 01 Setting the Stage RAM Memory Modern WEB SCS Architecture 02 In-Memory Application Platform Architecture Single App Integration Demo Future Pros and Cons Pros Cons ▪ Ubiquitous -

In-Memory Databases, Q1 2017 In-Memory Databases Are Driving Next-Generation Workloads and Use Cases by Noel Yuhanna February 28, 2017
FOR ENTERPRISE ARCHITECTURE PROFESSIONALS The Forrester Wave™: In-Memory Databases, Q1 2017 In-Memory Databases Are Driving Next-Generation Workloads And Use Cases by Noel Yuhanna February 28, 2017 Why Read This Report Key Takeaways In-memory database initiatives are fast on the Thirteen In-Memory Databases Compete In rise as organizations focus on rolling out real-time This Hot Market analytics and extreme transactions to support Among the commercial and open source in- growing business demands. In-memory offers memory database vendors Forrester evaluated, enterprise architects a platform that supports we found fve Leaders, six Strong Performers, low-latency access with optimized storage and two Contenders. and retrieval by leveraging memory, SSD, and In-Memory Has Become Critical For All fash. Forrester identifed the 13 most signifcant Enterprises companies in the category — Aerospike, The in-memory database market is growing Couchbase, DataStax, IBM, MemSQL, Microsoft, rapidly, largely because enterprises see Oracle, Red Hat, Redis Labs, SAP, Starcounter, in-memory as a way to support their next- Teradata, and VoltDB —and researched, generation real-time workloads, such as extreme analyzed, and scored them against 24 criteria. transactions and operational analytics. Scale, Performance, And Stack Distinguish The In-Memory Database Leaders The Leaders we identifed offer high-performance, scalable, secure, and fexible in-memory databases. The Strong Performers have turned up the heat as high as it will go on the incumbent Leaders, with -
Data Platforms
1 2 3 4 5 6 Towards Apache Storm SQLStream enterprise search Treasure AWS Azure Apache S4 HDInsight DataTorrent Qubole Data EMR Hortonworks Metascale Lucene/Solr Feedzai Infochimps Strao Doopex Teradata Cloud T-Systems MapR Apache Spark A Towards So`ware AG ZeUaset IBM Azure Databricks A SRCH2 IBM for Hadoop E-discovery Al/scale BigInsights Data Lake Oracle Big Data Cloud Guavus InfoSphere CenturyLink Data Streams Cloudera Elas/c Lokad Rackspace HP Found Non-relaonal Oracle Big Data Appliance Autonomy Elas/csearch TIBCO IBM So`layer Google Cloud StreamBase Joyent Apache Hadoop Platforms Oracle Azure Dataflow Data Ar/sans Apache Flink Endeca Server Search AWS xPlenty zone IBM Avio Kinesis Trafodion Splice Machine MammothDB Presto Big SQL CitusDB Hadapt SciDB HPCC AsterixDB IBM InfoSphere Starcounter Towards NGDATA SQLite Apache Teradata Map Data Explorer Firebird Apache Apache Crate Cloudera JethroData Pivotal SIEM Tajo Hive Drill Impala HD/HAWQ Aster Loggly Sumo LucidWorks Ac/an Ingres Big Data SAP Sybase ASE IBM PureData June 2015 Logic for Analy/cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO EnterpriseDB B LogLogic Rela%onal zone SQream General purpose Postgres-XL Microso` vFabric Postgres Oracle IBM SAP SQL Server Oracle Teradata Specialist analy/c Splunk PostgreSQL Exadata PureData HANA PDW Exaly/cs -as-a-Service Percona Server MySQL MarkLogic CortexDB ArangoDB Ac/an PSQL XtremeData BigTables OrientDB MariaDB Enterprise MariaDB Oracle IBM Informix SQL HP NonStop SQL Metamarkets Druid Orchestrate Sqrrl Database DB2 Server -

MILLIONS of TRANSACTIONS PER SECOND on a SINGLE MACHINE CASE for a VIRTUALIZED DATABASE and SCALE-IN ROGER JOHANSSON Who Am I?
MILLIONS OF TRANSACTIONS PER SECOND ON A SINGLE MACHINE CASE FOR A VIRTUALIZED DATABASE AND SCALE-IN ROGER JOHANSSON Who am I? Roger Johansson Actor Model, Scalability, Senior Solution Architect – Starcounter Distributed Systems, C#, Go, Kotlin http://StarCounter.io Proto.Actor Founder – Ultra Fast Distributed Actors (Go, .NET, JVM) http://Proto.Actor https://github.com/AsynkronIT Twitter: @rogeralsing Github: rogeralsing Mail: [email protected] http://Github.com/rogeralsing/presentations Agenda Setting the stage - Why we need in memory computing: • Application Platform • Micro-Apps The Starcounter information operating system: • Our approach to in memory computing • The future of hardware • The Mars project Front-end Framework React, Polymer Communication Palindrom - REST, Web Sockets Application View Models, Entities, App Logic In Memory App Platform Mapping, Persistence, Queries Starcounter Front-end Framework Front-end Framework Client Side Code Network Network Services + Contracts View Models Application Code Application O/R Mapper Network Database In Memory App Platform Traditional Stack Starcounter UI A UI B UI C App A App B App C Model A Model B Model C Starcounter Client Side Blending UI B UI A UI C UI A UI B UI C App A App B App C Model A Model B Model C Starcounter Profile ObjectId 789 FirstName Stefan LastName Edqvist User ObjectId 123 FirstName Stefan LastName Edqvist Client Side Blending UI B UI A UI C UI A UI B UI C App A App B App C Model A Model B Model C ACID, Snapshot Mapper Isolation Starcounter UI A UI B UI C App -

Semantic Web Queries Over Scientific Data
ACTA UNIVERSITATIS UPSALIENSIS Uppsala Dissertations from the Faculty of Science and Technology 121 Andrej Andrejev Semantic Web Queries over Scientific Data Dissertation presented at Uppsala University to be publicly examined in Lecture hall 2446, Polacksbacken, Uppsala, Wednesday, 23 March 2016 at 14:00 for the degree of Doctor of Philosophy. The examination will be conducted in English. Faculty examiner: Professor Gerhard Weikum (Max Planck Institute for Informatics). Abstract Andrejev, A. 2016. Semantic Web Queries over Scientific Data. Uppsala Dissertations from the Faculty of Science and Technology 121. 214 pp. Uppsala: Acta Universitatis Upsaliensis. ISBN 978-91-554-9465-0. Semantic Web and Linked Open Data provide a potential platform for interoperability of scientific data, offering a flexible model for providing machine-readable and queryable metadata. However, RDF and SPARQL gained limited adoption within the scientific community, mainly due to the lack of support for managing massive numeric data, along with certain other important features – such as extensibility with user-defined functions, query modularity, and integration with existing environments and workflows. We present the design, implementation and evaluation of Scientific SPARQL – a language for querying data and metadata combined, represented using the RDF graph model extended with numeric multidimensional arrays as node values – RDF with Arrays. The techniques used to store RDF with Arrays in a scalable way and process Scientific SPARQL queries and updates are implemented in our prototype software – Scientific SPARQL Database Manager, SSDM, and its integrations with data storage systems and computational frameworks. This includes scalable storage solutions for numeric multidimensional arrays and an efficient implementation of array operations. -

The Steadily Growing Database Market Is Increasing Enterprises
For: Application The Steadily Growing Database Market Is Development & Delivery Increasing Enterprises’ Choices Professionals by Noel Yuhanna, June 7, 2013 KEY TAKEAWAYS Information Management Challenges Create New Database Market Opportunities Data volume, data velocity, mobility, cloud, globalization, and increased compliance requirements demand new features, functionality, and innovation. A recent Forrester survey found that performance, integration, security, unpredictable workloads, and high availability are companies’ top data management challenges. Look Beyond Traditional Database Solutions And Architectures The database market is transforming. Relational DBs are OK for established OLTP and decision support apps, but new business requirements, dynamic workloads, globalization, and cost-cutting mean that firms need a new database strategy. Devs facing issues with existing DB implementations or designing new web-scale apps should look beyond relational. Invest In New Database Technologies To Succeed Business data comprises an increasing share of the value of your systems. Past investments in relational DBs are a solid basis, but you need more to stay competitive amid the many innovative new ways to use information. Next-gen DB strategies require you to invest anew so you can deliver the speed, agility, and insights critical to business growth. Forrester Research, Inc., 60 Acorn Park Drive, Cambridge, MA 02140 USA Tel: +1 617.613.6000 | Fax: +1 617.613.5000 | www.forrester.com FOR APPLICATION DEVELOPMENT & DELIVERY PROFESSIONALS JUNE 7, 2013 The Steadily Growing Database Market Is Increasing Enterprises’ Choices An Overview Of The Enterprise Database Management System Market In 2013 by Noel Yuhanna with Mike Gilpin and Vivian Brown WHY READ THIS REPort Business demand for more applications, larger databases, and new analytics initiatives is driving innovation and growth in the database market, with new options for cloud, in-memory, mobility, predictive analytics, and real-time data management. -

How to Get Extreme Database Performance and Development Speed
How to get extreme database performance and development speed Niklas Bjorkman VP Technology, Starcounter Could it be magic? “Any sufficiently advanced technology is indistinguishable from magic.” Arthur C. Clarke Today’s topics Utilize server side performance of today Persistent server controlled app How it is possible Performance on all levels Performance – where? The enabler Raw database performance Hundreds of thousands of TPS per CPU core Easy to scale up performance The hub Web server performance Millions of http RPS DB transaction time included We like less lines of code Development performance Shorter time to market Less maintenance costs Super fast What to do with it? “Todo” sample Rewrite to server side controlled Todo MVC (Web Components) Web component implementation using Polymer www.todomvc.com/architecture-examples/polymer/index.html Todo MVC file setup master.html td-todos.html td-item.html polymer-localstorage.html + td-model.html flatiron-director.html Server side “todo” All the same features - fully server controlled Nothing created, stored or updated in local client storage Persistent Tamper proof Less lines of code Simplified client implementation Use JSON Patch (RFC 6902) Todo MVC server version setup master.html td-todos.html td-item.html DB Server Internet JSON Patch Web Server “Todo” polymer client Remove and modify code Change 1: master.html <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <title>Polymer • TodoMVC</title> <link rel="stylesheet" href="/app/app.css"> <link