Container Monitoring and Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Professional Heroku® Programming
ffirs.indd i 1/10/2013 1:46:29 PM PROFESSIONAL HEROKU® PROGRAMMING INTRODUCTION . xxv PART I AN OVERVIEW OF HEROKU CHAPTER 1 How Heroku Works . 3 CHAPTER 2 Architectural Considerations . .17 CHAPTER 3 Porting Your Applications to Heroku . 45 PART II CREATING AND MANAGING HEROKU APPLICATIONS CHAPTER 4 Deploying Your Applications to Heroku . 73 CHAPTER 5 Managing Releases with Heroku . 89 CHAPTER 6 Working with Add-Ons . 115 CHAPTER 7 Managing, Monitoring, and Scaling Your Heroku Applications . 133 PART III USING A DATA STORE WITH YOUR HEROKU APPLICATIONS CHAPTER 8 Using Heroku Postgres as a Data Store for Your Heroku Applications . 157 CHAPTER 9 Using Database.com as a Data Store for Your Heroku Applications . .181 CHAPTER 10 Using Third-Party Data Stores for Your Heroku Applications . .207 PART IV PROGRAMMING ON HEROKU’S POLYGLOT PLATFORM CHAPTER 11 Developing with Ruby . .233 CHAPTER 12 Developing with Java . 267 CHAPTER 13 Developing with Other Supported Languages . 301 CHAPTER 14 Understanding Buildpacks . 351 PART V CREATING A NEW GENERATION OF HEROKU APPLICATIONS CHAPTER 15 Building Mobile Applications with Heroku . 383 CHAPTER 16 Building Social Applications with Heroku . 411 APPENDIX Additional Resources . 445 INDEX . 469 ffirs.indd i 1/10/2013 1:46:29 PM ffirs.indd ii 1/10/2013 1:46:30 PM PROFESSIONAL Heroku® Programming ffirs.indd iii 1/10/2013 1:46:30 PM ffirs.indd iv 1/10/2013 1:46:30 PM PROFESSIONAL Heroku® Programming Chris Kemp Brad Gyger John Wiley & Sons, Ltd. ffirs.indd v 1/10/2013 1:46:30 PM © 2013 John Wiley & Sons, Ltd. -

Paas - Making the Most of Clouds
October 2012 ascent Thought leadership from Atos white paper PaaS - Making the most of Clouds Your business technologists. Powering progress Atos believes that a General Purpose PaaS would allow Cloud capabilities to be exploited to their full potential for applications. A General Purpose PaaS would be a comprehensive, open, flexible, and interoperable solution that simplifies the process of developing, deploying, integrating, and managing applications both in public and private Clouds. This whitepaper introduces the concept of the General Purpose PaaS and describes the desired capabilities and building blocks that need to be established, and proposes an architecture for such a platform. It also offers an analysis of market trends and existing solutions, in order to establish a future vision and direction for PaaS, as well as outlining the business potential of such a solution. © Atos, 2012, all rights reserved. The contents of this white paper is owned by Atos. You may not use or reproduce it in any type of media, unless you have been granted prior written consent thereto by a competent person authorized to represent Atos for such purpose. 2 Ascent / PaaS - Making the most of Clouds PaaS - Making the most of Clouds Contents 04 18 Introduction Business Opportunities An explanation of the need for PaaS and a definition of the A consideration of how PaaS could be used and by whom, concept. including the benefits it could bring. 05 19 Trends, market and technology Conclusion An overview of what PaaS providers need to consider in overview the near future. A look at the current PaaS market and forecasts for the future, including changes expected. -

Monitoring Container Environment with Prometheus and Grafana
Matti Holopainen Monitoring Container Environment with Prometheus and Grafana Metropolia University of Applied Sciences Bachelor of Engineering Information and Communication Technology Bachelor’s Thesis 3.5.2021 Abstract Tekijä Matti Holopainen Otsikko Monitoring Container Environment with Prometheus and Grafana Sivumäärä Aika 50 sivua 3.5.2021 Tutkinto Insinööri (AMK) Tutkinto-ohjelma Tieto- ja viestintätekniikka Ammatillinen pääaine Ohjelmistotuotanto Ohjaajat Nina Simola, Projektipäällikkö Auvo Häkkinen, Yliopettaja Insinöörityön tavoitteena oli oppia pystyttämään monitorointijärjestelmä konttiympäristön re- surssien käytön seuraamista, monitorointia ja analysoimista varten. Tavoitteena oli helpot- taa monitorointijärjestelmän käyttöönottoa. Työ tehtiin käytettävien ohjelmistojen dokumen- taation ja käytännön tekemisellä opittujen asioiden pohjalta. Insinöörityön alussa käytiin läpi työssä käytettyjä teknologioita. Tämän jälkeen käytiin läpi monitorointi järjestelmän konfiguraatio ja käyttöönotto. Seuraavaksi tutustuttiin PromQL-ha- kukieleen, jonka jälkeen näytettiin kuinka pystyttää valvontamonitori ja hälytykset sähköpos- timuistutuksella. Työn lopussa käydään läpi kuinka monitorointijärjestelmässä saatua dataa analysoidaan ja mietitään miten monitorointijärjestelmää voisi parantaa. Keywords Monitorointi, Kontti, Prometheus, Grafana, Docker Abstract Author Matti Holopainen Title Monitoring Container Environment with Prometheus and Grafana Number of Pages Date 50 pages 3.5.2021 Degree Bachelor of Engineering Degree Programme Information -

"SOLIZE India Technologies Private Limited" 56553102 .FABRIC 34354648 @Fentures B.V
Erkende referenten / Recognised sponsors Arbeid Regulier en Kennismigranten / Regular labour and Highly skilled migrants Naam bedrijf/organisatie Inschrijfnummer KvK Name company/organisation Registration number Chamber of Commerce "@1" special projects payroll B.V. 70880565 "SOLIZE India Technologies Private Limited" 56553102 .FABRIC 34354648 @Fentures B.V. 82701695 01-10 Architecten B.V. 24257403 100 Grams B.V. 69299544 10X Genomics B.V. 68933223 12Connect B.V. 20122308 180 Amsterdam BV 34117849 1908 Acquisition B.V. 60844868 2 Getthere Holding B.V. 30225996 20Face B.V. 69220085 21 Markets B.V. 59575417 247TailorSteel B.V. 9163645 24sessions.com B.V. 64312100 2525 Ventures B.V. 63661438 2-B Energy Holding 8156456 2M Engineering Limited 17172882 30MHz B.V. 61677817 360KAS B.V. 66831148 365Werk Contracting B.V. 67524524 3D Hubs B.V. 57883424 3DUniversum B.V. 60891831 3esi Netherlands B.V. 71974210 3M Nederland B.V. 28020725 3P Project Services B.V. 20132450 4DotNet B.V. 4079637 4People Zuid B.V. 50131907 4PS Development B.V. 55280404 4WEB EU B.V. 59251778 50five B.V. 66605938 5CA B.V. 30277579 5Hands Metaal B.V. 56889143 72andSunny NL B.V. 34257945 83Design Inc. Europe Representative Office 66864844 A. Hak Drillcon B.V. 30276754 A.A.B. International B.V. 30148836 A.C.E. Ingenieurs en Adviesbureau, Werktuigbouw en Electrotechniek B.V. 17071306 A.M. Best (EU) Rating Services B.V. 71592717 A.M.P.C. Associated Medical Project Consultants B.V. 11023272 A.N.T. International B.V. 6089432 A.S. Watson (Health & Beauty Continental Europe) B.V. 31035585 A.T. Kearney B.V. -

Quarterly Enterprise Software Market Review 1Q 2019
Quarterly Enterprise Software Market Review 1Q 2019 Boston San Francisco 200 Clarendon Street, Floor 45 601 Montgomery Street, Suite 2010 Boston, MA 02116 San Francisco, CA 94111 Peter M. Falvey Michael H.M. Shea Christopher J. Pingpank Michael S. Barker Managing Director Managing Director Managing Director Managing Director 617.896.2251 617.896.2255 617.896.2218 415.762.8101 [email protected] [email protected] [email protected] [email protected] Jeffrey G. Cook Brad E. McCarthy Misha Cvetkovic Principal Principal Vice President 617.896.2252 617.896.2245 415.762.8104 [email protected] [email protected] [email protected] www.shea-co.com Member FINRA & SIPC Copyright ©2019 Shea & Company Overview People ▪ Industry Expertise ▪ Process Excellence 1 2 24 15+ >70 Firm focused exclusively Offices in Boston and San Professionals focused on Years of experience Transactions completed on enterprise software Francisco the software industry amongst our senior representing billions of bankers dollars in value Mergers & Acquisitions Private Placements & Capital Raising Corporate Strategy ■ Sell-side and buy-side M&A advisory ■ Late-stage venture, growth equity and buyouts ■ Corporate development advisory ■ Divestitures ■ Recapitalizations ■ Balance sheet and capital structure review ■ Restructuring ■ IPO advisory ■ Fairness opinions has received an investment from has received an investment from Superior Outcomes has been acquired by has acquired Shea & Company has advised on important transactions representing billions of dollars in -

Cloud Native Go
Cloud Native Go Building Web Applications and Microservices for the Cloud with Go and React Kevin Hoffman Dan Nemeth AAddison-Wesley Boston • Columbus • Indianapolis • New York • San Francisco • Amsterdam • Cape Town Dubai • London • Madrid • Milan • Munich • Paris • Montreal • Toronto • Delhi Mexico City • Sao Paulo • Sidney • Hong Kong • Seoul • Singapore • Taipei • Tokyo Contents at a Glance 1 The Way of the Cloud 1 2 Getting Started ll 3 Go Primer 17 4 Delivering Continuously 35 5 Building Microservices in Go 53 6 Using Backing Services 71 7 Creating a Data Service 95 8 Event Sourcing and CQRS 113 9 Building a Web Application with Go 137 10 Security in the Cloud 151 11 Working with WebSockets 167 12 Building Web Views with React 177 13 Creating Ills that Scale with Flux 195 14 Creating a Full Application—World of FluxCraft 209 15 Conclusion 223 A Troubleshooting Cloud Applications 227 Index 231 NOTE: To register this product and gain access to bonus content, go to www.informit.com/register to sign in and enter the ISBN. After you register the product, a link to the additional content will be listed on your Account page, under Registered Products. Contents 1 The Way of the Cloud 1 The Virtues of the Way of the Cloud 2 Favor Simplicity 2 Test First, Test Everything 3 Release Early, Release Often 5 Automate Everything 6 Build Service Ecosystems 7 Why Use Go? 8 Simplicity 8 Open Source 8 Easy Automation and IDE Freedom 9 Summary 9 2 Getting Started 11 The Right Tools for the Job 11 Setting Up Git 12 Installing Homebrew 12 Installing the -

Syllabus for M.Sc. Part I (Semester I and II) Programme: M.Sc
Academic Council: 26/07/2019 Item No: 4.76 UNIVERSITY OF MUMBAI Syllabus for M.Sc. Part I (Semester I and II) Programme: M.Sc. Subject: Information Technology (Choice Based Credit System with effect from the academic year 2019 – 2020) Semester – I Course Code Course Title Credits PSIT101 Research in Computing 4 PSIT102 Data Science 4 PSIT103 Cloud Computing 4 PSIT104 Soft Computing Techniques 4 PSIT1P1 Research in Computing Practical 2 PSIT1P2 Data Science Practical 2 PSIT1P3 Cloud Computing Practical 2 PSIT1P4 Soft Computing Techniques Practical 2 Total Credits 24 Semester – II Course Code Course Title Credits PSIT201 Big Data Analytics 4 PSIT202 Modern Networking 4 PSIT203 Microservices Architecture 4 PSIT204 Image Processing 4 PSIT2P1 Big Data Analytics Practical 2 PSIT2P2 Modern Networking Practical 2 PSIT2P3 Microservices Architecture Practical 2 PSIT2P4 Image Processing Practical 2 Total Credits 24 2 Program Specific Outcomes PSO1: Ability to apply the knowledge of Information Technology with recent trends alignedwith research and industry. PSO2: Ability to apply IT in the field of Computational Research, Soft Computing, Big Data Analytics, Data Science, Image Processing, Artificial Intelligence, Networking and Cloud Computing. PSO3: Ability to provide socially acceptable technical solutions in the domains of Information Security, Machine Learning, Internet of Things and Embedded System, Infrastructure Services as specializations. PSO4: Ability to apply the knowledge of Intellectual Property Rights, Cyber Laws and Cyber Forensics and various standards in interest of National Security and Integrity along with IT Industry. PSO5: Ability to write effective project reports, research publications and content development and to work in multidisciplinary environment in the context of changing technologies. -

Experimental Methods for the Evaluation of Big Data Systems Abdulqawi Saif
Experimental Methods for the Evaluation of Big Data Systems Abdulqawi Saif To cite this version: Abdulqawi Saif. Experimental Methods for the Evaluation of Big Data Systems. Computer Science [cs]. Université de Lorraine, 2020. English. NNT : 2020LORR0001. tel-02499941 HAL Id: tel-02499941 https://hal.univ-lorraine.fr/tel-02499941 Submitted on 5 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. AVERTISSEMENT Ce document est le fruit d'un long travail approuvé par le jury de soutenance et mis à disposition de l'ensemble de la communauté universitaire élargie. Il est soumis à la propriété intellectuelle de l'auteur. Ceci implique une obligation de citation et de référencement lors de l’utilisation de ce document. D'autre part, toute contrefaçon, plagiat, reproduction illicite encourt une poursuite pénale. Contact : [email protected] LIENS Code de la Propriété Intellectuelle. articles L 122. 4 Code de la Propriété Intellectuelle. articles L 335.2- L 335.10 http://www.cfcopies.com/V2/leg/leg_droi.php http://www.culture.gouv.fr/culture/infos-pratiques/droits/protection.htm -

Pentest-Report Prometheus 05.-06.2018 Cure53, Dr.-Ing
Dr.-Ing. Mario Heiderich, Cure53 Bielefelder Str. 14 D 10709 Berlin cure53.de · [email protected] Pentest-Report Prometheus 05.-06.2018 Cure53, Dr.-Ing. M. Heiderich, M. Wege, MSc. N. Krein, BSc. J. Hector, Dipl.-Ing. A. Inführ, J. Larsson Index Introduction Scope Test Methodology Part 1 (Manual Code Auditing) Part 2 (Code-Assisted Penetration Testing) Hardening Recommendations General Security Recommendations HTTP Security Headers Content Security Policy & Beyond Authentication / Authorization Non-Idempotent Request Protection Transport Security Clients/metrics endpoint API Endpoint Admin GUI Identified Vulnerabilities PRM-01-001 Web: Prometheus lifecycle killed with CSRF (Medium) PRM-01-003 Web: CORS header exposes API data to all origins (High) PRM-01-005 Server: Clients can cause Denial of Service via Gzip Bomb (Medium) Miscellaneous Issues PRM-01-002 Client: Clients leak Metrics data through unprotected endpoint (Low) PRM-01-004 Web: Parameters used insecurely in HTML templates (Low) Conclusions Cure53, Berlin · 06/11/18 1/18 Dr.-Ing. Mario Heiderich, Cure53 Bielefelder Str. 14 D 10709 Berlin cure53.de · [email protected] Introduction “An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.” From https://prometheus.io/ This report documents the findings of a security assessment targeting the Prometheus software compound and carried out by Cure53 in 2018. It should be noted that the project was sponsored by The Linux Foundation / Cloud Native Computing Foundation. In terms of the scope, the assignment entailed two main components as the Prometheus project was investigated through both a dedicated source code audit and comprehensive penetration testing. -

Virtualization/Containerization of the PNNL High Energy Physics Computing Infrastructure
Virtualization/Containerization of the PNNL High Energy Physics Computing Infrastructure Kevin Fox, David Cowley, Malachi Schram, Evan Felix, James Czebotar, Smith Gary Grid Services Deployed DIRAC Belle2DB Distributed Data Management REST Service System UI Service Gatekeeper Services Payload Service Many development and testing Squid Cache services Postgresql Relational Database Condor CE's FTS3 DIRAC SiteDirector CVMFS Stratum HTCondor cluster Zero Squid Cache One Leadership Class Facility CE's Authorization DIRAC SiteDirector Gums HPC Cluster VOMS Server with multiple VO's SE's BestMan2 Gridftp Backed by Lustre Note to the Sysadmins New methodology for system administration. Cloud Native focuses around what the user cares about most, not what we Sysadmins are used to caring about. Users care about services. Users do not care about machines providing service. Pets vs Cattle analogy. We must unlearn what we have learned. Try and separate pets and cattle to different pools of resource. Our Infrastructure Journey Individual machines Automated provisioning Virtual machines OpenStack Cloud Repo Mirrors Containers Kubernetes Infrastructure Deployed Kubernetes + Docker Engine Prometheus OpenStack + KVM Grafana Ceph CheckMK GitLab ElasticSearch Lustre 389-DS LoadBalancing/HA Cobbler PerfSonar NFS Metric/Log gathering is very important for system problem analysis Current tool stack includes CheckMK Grafana/Prometheus Kibana/ElasticSearch/LogShippers Kubernetes Load Balancers Give users a load balancer to talk to. Back it with multiple instances of the software making up of the service whenever possible. When not possible, make it very quick to redeploy. Deployment Flow Separate Build and Deploy steps. Kubernetes/Docker example: #Build > docker build . -t pnnlhep/condor-compute:2017-09-01 … > docker push pnnlhep/condor-compute:2017-09-01 … #Deploy > helm install --name ce0-compute condor-compute \ –set version=2017-09-01 .. -
Lumada Edge Version
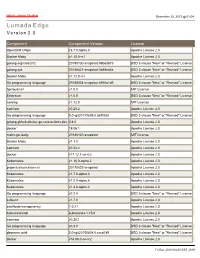
Hitachi - Inspire The Next December 20, 2019 @ 01:04 Lumada Edge V e r s i o n 3 . 0 Component Component Version License OpenShift Origin v3.7.0-alpha.0 Apache License 2.0 Docker Moby v1.10.0-rc1 Apache License 2.0 golang.org/x/oauth2 20190130-snapshot-99b60b75 BSD 3-clause "New" or "Revised" License golang sys 20180821-snapshot-3b58ed4a BSD 3-clause "New" or "Revised" License Docker Moby v1.12.0-rc1 Apache License 2.0 Go programming language 20180824-snapshot-4910a1d5 BSD 3-clause "New" or "Revised" License hpcloud-tail v1.0.0 MIT License Ethereum v1.5.0 BSD 3-clause "New" or "Revised" License zerolog v1.12.0 MIT License cadvisor v0.28.2 Apache License 2.0 Go programming language 0.0~git20170629.0.5ef0053 BSD 3-clause "New" or "Revised" License golang-github-docker-go-connections-dev 0.4.0 Apache License 2.0 docker 18.06.1 Apache License 2.0 mattn-go-isatty 20180120-snapshot MIT License Docker Moby v1.1.0 Apache License 2.0 cadvisor v0.23.4 Apache License 2.0 docker v17.12.1-ce-rc2 Apache License 2.0 Kubernetes v1.15.0-alpha.2 Apache License 2.0 projectcalico/calico-cni 20170522-snapshot Apache License 2.0 Kubernetes v1.7.0-alpha.3 Apache License 2.0 Kubernetes v1.2.0-alpha.6 Apache License 2.0 Kubernetes v1.4.0-alpha.2 Apache License 2.0 Go programming language v0.2.0 BSD 3-clause "New" or "Revised" License kubevirt v1.7.0 Apache License 2.0 certificate-transparency 1.0.21 Apache License 2.0 kubernetes/api kubernetes-1.15.0 Apache License 2.0 cadvisor v0.28.1 Apache License 2.0 Go programming language v0.3.0 BSD 3-clause "New" or "Revised" -

Choosing the Right Vendor for Application Development
Choosing the Right Vendor for Application Development Customer Experiences with Amazon, Oracle, and Pivotal Cloud Services August 2018 THE DEVELOPMENT OF THIS WHITE PAPER WAS SPONSORED BY ORACLE. THE UNDERLYING RESEARCH AND ANALYSIS WERE EXECUTED INDEPENDENTLY BY PIQUE SOLUTIONS. 795 Folsom Street, 1st Floor | San Francisco, CA 94107 | Tel.: 415.685.3392 | www.piquesolutions.com Application Development in the Cloud Contents Executive Summary ........................................................................................................................ 1 Introduction .................................................................................................................................... 3 Cloud Providers Take Different Approaches ............................................................................... 4 Amazon ................................................................................................................................... 4 Oracle ...................................................................................................................................... 4 Pivotal ..................................................................................................................................... 4 Study Approach ............................................................................................................................... 5 Methodology ............................................................................................................................... 5 AppDev