Using C++ Efficiently in Embedded Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Practical C/C++ Programming Part II
Practical C/C++ programming Part II Wei Feinstein HPC User Services Louisiana State University 7/11/18 Practical C/C++ programming II 1 Topics • Pointers in C • Use in functions • Use in arrays • Use in dynamic memory allocation • Introduction to C++ • Changes from C to C++ • C++ classes and objects • Polymorphism • Templates • Inheritance • Introduction to Standard Template Library (STL) 7/11/18 Practical C/C++ programming II 2 What is a pointer? • A pointer is essentially a variable whose value is the address of another variable. • Pointer “points” to a specific part of the memory. • Important concept in C programming language. Not recommended in C++, yet understanding of pointer is necessary in Object Oriented Programming • How to define pointers? int *i_ptr; /* pointer to an integer */ double *d_ptr; /* pointer to a double */ float *f_ptr; /* pointer to a float */ char *ch_ptr; /* pointer to a character */ int **p_ptr; /* pointer to an integer pointer */ 7/11/18 Practical C/C++ programming II 3 Pointer Operations (a) Define a pointer variable. (b) Assign the address of a variable to a pointer. & /* "address of" operator */ (c) Access the value pointed by the pointer by dereferencing * /* “dereferencing" operator */ Examples: int a = 6; int *ptr; ptr = &a; /* pointer p point to a */ *ptr = 10; /* dereference pointer p reassign a value*/ var_name var_address var_value ptr 0x22aac0 0xXXXX a 0xXXXX 6 7/11/18 Practical C/C++ programming II 4 Pointer Example int b = 17; int *p; /* initialize pointer p */ p = &b; /*pointed addr and value, -

Lab 1: Programming in C 1 Lab 1: Programming in C CS 273 Monday, 8-24-20 Revision 1.2
Lab 1: Programming in C 1 Lab 1: Programming in C CS 273 Monday, 8-24-20 Revision 1.2 Preliminary material • Using manual pages. For example, % man gcc % man read % man 2 read Viewing online manual pages on a browser. • Similarities between C++ and C. C++ language shares most of its same basic syntax with C. Thus, simple variable declarations, assignments, loops, array access, function defini- tions/declarations/calls, etc. are written the essentially the same way in both languages. Much of the basic semantics is shared, also. Thus, a for loop behaves as expected, as does an expression statement, a function definition, etc.; also, operators have the same precedence and associativity. The two languages both use predefined types int, long, float, char, etc. In both languages, ASCII characters are represented as (8-bit) integer values, and simple strings are represented as arrays of characters terminated by nullbytes. Preprocessor directives (such as #include, #define, etc.) are used in both C and C++. • Differences between C++ and C. { C has no classes. Instead, you must use functions and variables to perform operations. It is still useful to use \interface modules" and \implementation modules" and to organize your program into packages that can be linked separately. However, there are no classes to define per se. C does provide struct (and union) for data structures. Unlike C++, a struct is not a class, but instead is a container for variables of various types. There are no methods, no constructors, no destructors, etc. { No overloading of functions or operators in C. Many conventional meanings of operators in C++ (such as <<) are no longer relevant. -

Object Oriented Programming in Objective-C 2501ICT/7421ICT Nathan
Subclasses, Access Control, and Class Methods Advanced Topics Object Oriented Programming in Objective-C 2501ICT/7421ICT Nathan René Hexel School of Information and Communication Technology Griffith University Semester 1, 2012 René Hexel Object Oriented Programming in Objective-C Subclasses, Access Control, and Class Methods Advanced Topics Outline 1 Subclasses, Access Control, and Class Methods Subclasses and Access Control Class Methods 2 Advanced Topics Memory Management Strings René Hexel Object Oriented Programming in Objective-C Subclasses, Access Control, and Class Methods Subclasses and Access Control Advanced Topics Class Methods Objective-C Subclasses Objective-C Subclasses René Hexel Object Oriented Programming in Objective-C Subclasses, Access Control, and Class Methods Subclasses and Access Control Advanced Topics Class Methods Subclasses in Objective-C Classes can extend other classes @interface AClass: NSObject every class should extend at least NSObject, the root class to subclass a different class, replace NSObject with the class you want to extend self references the current object super references the parent class for method invocations René Hexel Object Oriented Programming in Objective-C Subclasses, Access Control, and Class Methods Subclasses and Access Control Advanced Topics Class Methods Creating Subclasses: Point3D Parent Class: Point.h Child Class: Point3D.h #import <Foundation/Foundation.h> #import "Point.h" @interface Point: NSObject @interface Point3D: Point { { int x; // member variables int z; // add z dimension -

C++ for C Programmers BT120
C++ for C Programmers BT120 40 Academic Hours C++ for C Programmers Outline C++ is undoubtedly one of the most popular programming languages for software development. It brings language enhancements and object-oriented programming support to C. However, C++ is a large and sometimes difficult language, and even with a C background, a programmer needs to understand C++ programming style as well as C++ constructs to get the best out of itl. For experienced C programmers, the course will illustrate how to get the benefits of good software engineering and code reuse by using standard C++ and object-oriented programming techniques in real-world programming situations. This is a hand on course with a mix of tuition and practical sessions for each technical chapter which reinforce the C++ syntax and object-oriented programming techniques covered in the course. Target Audience C Programmers wishing to learn or improve in C++ Prerequisites Delegates should have a working knowledge of C, and some knowledge of ו Embedded/Real Time programming. Delegates must have solid experience of C including structures (i.e. struct and/or ו class); declaration and use of pointers; function declaration, definition and use with call by value or call by pointer; dynamic memory allocation (i.e. malloc and free, or new and delete); multiple source file projects (requiring project files or makes files) Objectives On completion, Delegates will be able to: .The core C++ syntax and semantics ו Object Oriented Advantages, and Principles ו How to write safe, efficient C++ -
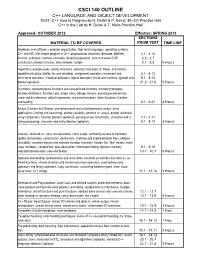
CSCI 140 OUTLINE C++ LANGUAGE and OBJECT DEVELOPMENT TEXT: C++ How to Program by H
CSCI 140 OUTLINE C++ LANGUAGE AND OBJECT DEVELOPMENT TEXT: C++ How to Program by H. Deitel & P. Deitel, 8th ED Prentice Hall C++ in the Lab by H. Deitel & T. Nieto Prentice Hall Approved: OCTOBER 2012 Effective: SPRING 2013 SECTIONS MATERIAL TO BE COVERED FROM TEXT TIME LINE Hardware and software, computer organization, high level languages, operating systems, C++ and IDE, first simple program in C++, preprocessor directives (#include, #define), 1.1 - 1.14 macros, arithmetic, memory concepts, relational operators, intro to classes OOP, 2.2 - 2.7 constructor, member function, data member, set/get 3.1 - 3.8 5 Hours Algorithms, pseudo-code, control structures, selection structures (if, if/else, and switch), repetition structure (whilte, for, and do/while), assignment operators, increment and 4.1 - 4.12 decrement operators, relational operators, logical operators, break and continue, typedef and 5.1 - 5.10 bitwise operators 21.2 - 21.6 5 Hours Functions: standard library functions and user-defined functions, function prototypes, function definitions, function calls, scope rules, storage classes, passing parameters by value and by reference, default arguments, recursive functions, inline functions, function overloading 6.1 - 6.21 4 Hours Arrays, Pointers and Strings: one-dimensional and multidimensional arrays, array applications (sorting and searching), pointer variables, pointers vs. arrays, pointer arithmetic, arrays of pointers, function pointers (optional), passing arrays to functions, character and C- 7.1 - 7.11 string processing, character -

The Rule of the Big Five
C++11: The Rule of the Big Five Resource Management The dynamic creation and destruction of objects was always one of the bugbears of C. It required the programmer to (manually) control the allocation of memory for the object, handle the object’s initialisation, then ensure that the object was safely cleaned-up after use and its memory returned to the heap. Because many C programmers weren’t educated in the potential problems (or were just plain lazy or delinquent in their programming) C got a reputation in some quarters for being an unsafe, memory-leaking language. C++ improved matters significantly by introducing an idiom known (snappily) as RAII/RRID – Resource Acquisition Is Initialisation / Resource Release Is Destruction*. The idiom makes use of the fact that every time an object is created a constructor is called; and when that object goes out of scope a destructor is called. The constructor/destructor pair can be used to create an object that automatically allocates and initialises another object (known as the managed object) and cleans up the managed object when it (the manager) goes out of scope. This mechanism is generically referred to as resource management. A resource could be any object that required dynamic creation/deletion – memory, files, sockets, mutexes, etc. Resource management frees the client from having to worry about the lifetime of the managed object, potentially eliminating memory leaks and other problems in C++ code. However, RAII/RRID doesn’t come without cost (to be fair, what does?) Introducing a ‘manager’ object can lead to potential problems – particularly if the ‘manager’ class is passed around the system (it is just another object, after all). -

Copyrighted Material 23 Chapter 2: Data, Variables, and Calculations 25
CONTENTS INTRODUCTION xxxv CHAPTER 1: PROGRAMMING WITH VISUAL C++ 1 Learning with Visual C++ 1 Writing C++ Applications 2 Learning Desktop Applications Programming 3 Learning C++ 3 Console Applications 4 Windows Programming Concepts 4 What Is the Integrated Development Environment? 5 The Editor 6 The Compiler 6 The Linker 6 The Libraries 6 Using the IDE 7 Toolbar Options 8 Dockable Toolbars 9 Documentation 10 Projects and Solutions 10 Defi ning a Project 10 Debug and Release Versions of Your Program 15 Executing the Program 16 Dealing with Errors 18 Setting Options in Visual C++ 19 Creating and Executing Windows Applications 20 Creating an MFC Application 20 Building and Executing the MFC Application 22 Summary COPYRIGHTED MATERIAL 23 CHAPTER 2: DATA, VARIABLES, AND CALCULATIONS 25 The Structure of a C++ Program 26 Program Comments 31 The #include Directive — Header Files 32 Namespaces and the Using Declaration 33 The main() Function 34 Program Statements 34 fftoc.inddtoc.indd xxviivii 224/08/124/08/12 88:01:01 AAMM CONTENTS Whitespace 37 Statement Blocks 37 Automatically Generated Console Programs 37 Precompiled Header Files 38 Main Function Names 39 Defi ning Variables 39 Naming Variables 39 Keywords in C++ 40 Declaring Variables 41 Initial Values for Variables 41 Fundamental Data Types 42 Integer Variables 42 Character Data Types 44 Integer Type Modifi ers 45 The Boolean Type 46 Floating-Point Types 47 Fundamental Types in C++ 47 Literals 48 Defi ning Synonyms for Data Types 49 Basic Input/Output Operations 50 Input from the Keyboard 50 -

C++ in Embedded Systems: Myth and Reality
C++ C++ in embedded systems: Myth and reality By Dominic Herity superior to C for embedded sys- Listing 1 Listing 2 Senior Software Engineer tems programming. Function name Silicon and Software Systems It aims to provide detailed Function name overloading. overloading in C. understanding of what C++ I was surprised a while ago by code does at the machine level, // C++ function name /* C substitute for */ overload example /* function name over- what I heard in a coffee break so that readers can evaluate for void foo(int i) load */ conversation during a C++ themselves the speed and size { void foo_int(int i) course. The attendees were spec- of C++ code as naturally as they //... { ulating on the relevance of C++ do for C code. } /*... */ void foo(char* s) } to embedded systems, and the To examine the nuts and { void foo_charstar(char* misconceptions that surfaced bolts of C++ code generation, //... s) drove me ultimately to write this I will discuss the major features } { article. of the language and how they void main() /*... */ { } Some perceive that C++ has are implemented in practice. foo(1); void main() overheads and costs that render Implementations will be illus- foo(“Hello world”); { it somehow unsuited to embed- trated by showing pieces of C++ } foo_int(1); ded systems programming, that code followed by the equivalent foo_charstar(“Hello world”); it lacks the control and brevity of (or near equivalent) C code. a C compiler and the machine } C, or that, while it may be suited I will then discuss some pitfalls code generated will be exactly to some niche applications, it specific to embedded systems what you would expect from a C Listing 3 will never displace C as the lan- and how to avoid them. -

C++ Overview (1)
C++ Overview (1) COS320 Heejin Ahn ([email protected]) Introduc@on • Created By Bjarne Stroustrup • Standards – C++98, C++03, C++07, C++11, and C++14 • Features – Classes and oBjects – Operator overloading – Templates – STL (Standard Template LiBrary) – … • S@ll widely used in performance-cri@cal programs • This overview assumes that you know C and Java from [3] C++ is a Federaon of Languages • C – Mostly Backward compaBle with C – Blocks, statements, preprocessor, Built-in data types, arrays, pointers, … • OBject-Oriented C++ – Classes, encapsulaon, inheritance, polymorphism, virtual func@ons, … • Template C++ – Paradigm for generic programming • STL (Standard Template LiBrary) – Generic liBrary using templates – Containers, iterators, algorithms, func@on oBjects … Topics • Today – Heap memory allocaon – References – Classes – Inheritance • Next @me – Operator overloading – I/O streams – Templates – STL – C++11 from [1] Heap allocaon: new and delete • new/delete is a type-safe alternave to malloc/free • new T allocates an oBject of type T on heap, returns pointer to it – Stack *sp = new Stack(); • new T[n] allocates array of T's on heap, returns pointer to first – int *stk = new int[100]; – By default, throws excep@on if no memory • delete p frees the single item pointed to By p – delete sp; • delete[] p frees the array Beginning at p – delete[] stk; • new uses T's constructor for oBjects of type T – need a default constructor for array allocaon • delete uses T's destructor ~T() • use new/delete instead of malloc/free and never -

Modern C++ Tutorial: C++11/14/17/20 on the Fly
Modern C++ Tutorial: C++11/14/17/20 On the Fly Changkun Ou (hi[at]changkun.de) Last update: August 28, 2021 Notice The content in this PDF file may outdated, please check our website or GitHub repository for the latest book updates. License This work was written by Ou Changkun and licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. http://creativecommons.org/licenses/by-nc-nd/4.0/ 1 2 CONTENTS CONTENTS Contents Preface 8 Introduction ............................................... 8 Targets ................................................. 8 Purpose ................................................. 9 Code ................................................... 9 Exercises ................................................ 9 Chapter 01: Towards Modern C++ 9 1.1 Deprecated Features ........................................ 10 1.2 Compatibilities with C ....................................... 11 Further Readings ............................................ 13 Chapter 02: Language Usability Enhancements 13 2.1 Constants .............................................. 13 nullptr ............................................... 13 constexpr ............................................. 15 2.2 Variables and initialization .................................... 17 if-switch .............................................. 17 Initializer list ........................................... 18 Structured binding ........................................ 20 2.3 Type inference .......................................... -

CS11 – Introduction to C++
CS11 – Introduction to C++ Fall 2012-2013 Lecture 2 Our Point Class – Point.hh // A 2D point class! class Point { double x_coord, y_coord; // Data-members public: Point(); // Constructors Point(double x, double y); ~Point(); // Destructor double getX(); // Accessors double getY(); void setX(double x); // Mutators void setY(double y); }; Copying Classes n Now you want to make a copy of a Point Point p1(3.5, 2.1); Point p2(p1); // Copy p1. n This works, because of the copy-constructor n Copy-constructors make a copy of another instance q Any time an object needs to be copied, this guy does it. n Copy-constructor signature is: MyClass(MyClass &other); //Copy-constructor n Note that the argument is a reference. q Why doesn’t MyClass(MyClass other) make sense? n Hint: default C++ argument-passing is pass-by-value q Because other would need to be copied with the copy ctor Required Class Operations n No copy-constructor in our Point declaration! n C++ requires that all classes must provide certain operations q If you don’t provide them, the compiler will make them up (following some simple rules) q This can lead to problems n Required operations: q At least one non-copy constructor q A copy constructor q An assignment operator (covered next week) q A destructor More C++ Weirdness n This calls the copy-constructor: Point p1(19.6, -3.5); Point p2(p1); // Copy p1 n So does this: Point p1(19.6, -3.5); Point p2 = p1; // Identical to p2(p1). q Syntactic sugar for calling the copy-constructor. -

Image Processing – the Programming Fundamentals
Image Processing – The Programming Fundamentals First Edition Revision 1.0 A text to accompany Image Apprentice The C/C++ based Image Processing Learner’s Toolkit. Copyright © 2005-2007, Advanced Digital Imaging Solutions Laboratory (ADISL). http://www.adislindia.com 2 This document is available at http://adislindia.com/documents/DIP_Programming_Fundamentals.pdf The author can be reached at: http://www.adislindia.com/people/~divya/index.htm Image Processing – The Programming Fundamentals Prerequisites: A brief knowledge of C/C++ language(s). This text describes the basic computer programming (C/C++) techniques required to begin practical implementations in Digital Image Processing. After reading the text, the reader would be in a position to understand and identify: • How uncompressed images are stored digitally • Typical data structures needed to handle digital image data • How to implement a generic image processing algorithm as function Mathematically, an image can be considered as a function of 2 variables, f(x, y), where x and y are spatial coordinates and the value of the function at given pair of coordinates (x, y) is called the intensity value. The programming counterpart of such a function could be a one or two dimensional array. Code Snippet 1 and Code Snippet 2 show how to traverse and use 1-D and 2-D arrays programmatically. Both of them essentially can represent an image as shown in Figure 1. width = 256 width = 256 pixels 0 1 2 3 4 5 . 253 254 255 0 1 2 3 4 5 . 253 254 255 0 1 2 3 4 5 . 253 254 255 0 1 2 3 4 5 .