Understanding the Effects of Hotspots in Wireless Cellular Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

QUESTION 20-1/2 Examination of Access Technologies for Broadband Communications
International Telecommunication Union QUESTION 20-1/2 Examination of access technologies for broadband communications ITU-D STUDY GROUP 2 3rd STUDY PERIOD (2002-2006) Report on broadband access technologies eport on broadband access technologies QUESTION 20-1/2 R International Telecommunication Union ITU-D THE STUDY GROUPS OF ITU-D The ITU-D Study Groups were set up in accordance with Resolutions 2 of the World Tele- communication Development Conference (WTDC) held in Buenos Aires, Argentina, in 1994. For the period 2002-2006, Study Group 1 is entrusted with the study of seven Questions in the field of telecommunication development strategies and policies. Study Group 2 is entrusted with the study of eleven Questions in the field of development and management of telecommunication services and networks. For this period, in order to respond as quickly as possible to the concerns of developing countries, instead of being approved during the WTDC, the output of each Question is published as and when it is ready. For further information: Please contact Ms Alessandra PILERI Telecommunication Development Bureau (BDT) ITU Place des Nations CH-1211 GENEVA 20 Switzerland Telephone: +41 22 730 6698 Fax: +41 22 730 5484 E-mail: [email protected] Free download: www.itu.int/ITU-D/study_groups/index.html Electronic Bookshop of ITU: www.itu.int/publications © ITU 2006 All rights reserved. No part of this publication may be reproduced, by any means whatsoever, without the prior written permission of ITU. International Telecommunication Union QUESTION 20-1/2 Examination of access technologies for broadband communications ITU-D STUDY GROUP 2 3rd STUDY PERIOD (2002-2006) Report on broadband access technologies DISCLAIMER This report has been prepared by many volunteers from different Administrations and companies. -

ITU Structure and Preparation on WRC-19 Agenda Items
ITU Structure and preparation on WRC-19 Agenda Items Pacific Radiocommunication Workshop 2018 (PRW-18) 04 – 06 Sep 2018 Honiara, Solomon Islands Aamir Riaz International Telecommunication Union – Regional Office for Asia and the Pacific [email protected] AGENDA ITU and its structure Recalling WRC-15 outcomes Preparatory work towards WRC-19 Going forward towards WRC-19 2 ITU at a Glance Specialized Agencies of the United Nations WHO ILO UPU ICAO WMO IMO IAEA WB UNWTO FAO IFAD UNIDO WIPO WFP IMF Specialized UN agency with focus on Telecommunication / ICTs ITU Presence JAKARTA ITU – Our strength Our numbers 193 >700 >100 MEMBER STATES ACADEMIA MEMBERS PRIVATE SECTOR ORGANIZATIONS ITU – Organization Each sector has separate mandate, but all work cohesively towards connecting the world ITU – Organization ITU – Organization Membership Inputs Treaty RPR WRC RPM Organiz. WTDC WTSA RA RR Action Advisory TDAG Plan TSAG Action RAG Plan Action Plan Study Groups Study Groups Technical Study Groups and CPMs Secretariat BDT TSB BR International Frequency Allocations The shaded part represents the Tropical Zones as defined in Nos. 5.16 to 5.20 and 5.21 The WRC Cycle Revisions to the Radio Regulations ITU Member States RA Final Acts Rep Rec R Members R CPM - Report WRC ITU & CPM-2 WRC Director RRB Resolution ITU-R Study Groups: Radiocommunication SG-1: Spectrum management Bureau SG-3: Radiowave propagation RoP Next WRC SG-4: Satellite services SG-5: Terrestrial services Agenda ITU Member States Member ITU SG-6: Broadcasting service SG-7: Science services CPM-1 RRB: Radio Regulations Board CPM: Conference Preparatory Meeting Adopted by SGs: Radiocommunication Study Groups Rec: ITU-R Recommendation ITU RA: Radiocommunication Assembly RoP: Rules of Procedure Council WRC: World Radiocommunication Conference RR: Radio Regulations (treaty status) Recalling WRC-15 outcomes WRC-15 (General Information) 2-27 November 2015 in Geneva 3275 participants attended WRC-15, including: . -

Purchasing a Hotspot Public WIFI
Virtual Tech Hub Internet Access Guide Virtual classes are starting next week and Foothill College understands that some students may be struggling with their Internet connection. In order to help those in need, the Virtual Hub Tech Ambassadors have decided to look into some of the different ways available to access the internet. Purchasing a Hotspot Those who do not have internet or reliable services have the option to purchase a hotspot. A hotspot is a device that allows people to obtain Internet access, typically using Wi-Fi, using a router connected to an Internet service provider. You can purchase hotspots at places like Best Buy, Target, Walmart or any place with a phone company stand. Public Wifi Another option is to use a public WIFI or an “Open Hotspot,” which are located in local or open spaces. Internet & Cellular Service Deals There is a possibility to look into the current deals that are happening with existing internet providers. Some of these deals ask that you enter into a contract while others offer their services no strings attached. We advise you to contact that service provider for more information. Additionally, it has come to our attention that some cellular phone companies are extending customer's GB for the month. This may allow you to access the internet longer if you're on a limited plan. You may also be able to use your phone as a hotspot. We encourage you to contact your cellular provider to find out if they are offering deals/freebies to help customers through the COVID-19 crisis. -

Bluetooth Hotspot
ISSN (Online) : 2278-1021 ISSN (Print) : 2319-5940 International Journal of Advanced Research in Computer and Communication Engineering Vol. 3, Issue 1, January 2014 Bluetooth Hotspot Pooja Abnave1, Priyanka Patil2, P.L.Himabindu3, Prashant Dukare4, S.S.Vanjire5 Student, Department Of Computer Engineering, University of Pune, Pune, India1 Student, Department Of Computer Engineering, University of Pune, Pune, India2 Student, Department Of Computer Engineering, University of Pune, Pune, India3 Student, Department Of Computer Engineering, University of Pune, Pune, India4 Assistant Professor, Department Of Computer Engineering, University of Pune, Pune, India5 Abstract: Bluetooth is a technology for short range wireless real-time data transfer between devices. It is becoming increasingly more prevalent in modern society, with technical gadgets now ranging from mobile phones and game controllers to PDAs and personal computers. Bluetooth hotspot is a technology which allows Bluetooth enabled mobiles (clients) to access the internet. With this technology mobile phones need not have a GPRS connection in it. Before accessing the internet Bluetooth mobiles (devices) need to be discoverable. The Bluetooth server discovers all devices in its range and sends a message for pairing. The connection link is established when an appropriate message is sent by the discovered device for pairing in response to the servers message. In this paper we will study how communication links are established, what are the security issues and how they are handled in Bluetooth and the data packet format. Keywords: Eavesdropping; Ad-hoc network; Bluetooth Network; Bluetooth Security; Media Access I. INTRODUCTION II. NEED Ad hoc networks today are based primarily on Bluetooth As the number of Bluetooth products increases each year, it technology. -

Car-Net Via Wi-Fi Hotspot Setting up an Internet Connection Via Wi-Fi In
Car-Net via Wi-Fi hotspot Setting up an Internet connection via Wi-Fi in order to use Car-Net Dear driver, Brief information about Volkswagen Car-Net With the optionally available Volkswagen Car-Net, you arrive at your destination more relaxed - and with greater reliability. The system is permanently updated via the Internet and therefore uses the most current data. Searching for a parking space and circumnavigating traffic jams is now becoming even easier. Here you find out how and under what requirements a Wi-Fi Internet connection to your infotainment system can be set up in order to be able to use Volkswagen Car-Net. However, this brochure does not describe all functions and therefore cannot replace the manual for the vehicle, which contains many important disclosures and warning notices. Frequently asked questions about Volkswagen Car-Net can be found on the Volkswagen Car- Net web page under the menu item „Help/FAQ“. The availability of Volkswagen Car-Net and its terms may vary depending on the vehicle and country. Further information about Volkswagen Car-Net is available at http://www.volkswagen.de/Car-Net and from your Volkswagen service partner and information about your mobile tariff conditions from your mobile phone system provider. Car-Net via Wi-Fi 2 Available connection technologies In order to use Car-Net, the infotainment system must be online. Here, you can see different connection technologies for Mobile phone interface “Business” * LTE Car Stick Discover Pro Discover Media creating an Internet connection. Go online via “Wi-Fi” In the described solution the Internet connection will not be created by the infotainment itself but by a different medium (e.g. -

Voice Over IP in the Wifi Network Business Models: Will Voice Be a Killer Application for Wifi Public Networks?”
“Voice over IP in the WiFi Network business models: Will voice be a killer application for WiFi Public Networks?” Jorge Infante, Boris Bellalta Research Group on Networking Technology and Strategies Universitat Pompeu Fabra Email: {jorge.infante, boris.bellalta}@upf.edu P. Circumval·lació 8, 08003 Barcelona (Spain) Phone/Fax: +34935422745 / +34935422517 Abstract The stunning growth of WiFi networks, together with the spreading of mobile telephony and the increasing use of Voice over IP (VoIP) on top of Internet, pose relevant questions on the application of WiFi networks to support VoIP services that could be used as a complement and/or competition to the 2G/3G cellular networks. Voice has been, is, and will surely be one of most important killer applications for many of the telecommunications networks. Till now, WiFi networks are centred on Internet access services, not covering a significant market for voice services. However, the succeeding VoIP services working on top of Internet as the ones provided by Skype or Vonage, and the irruption on the terminal market of intelligent dual WiFi/Cellular phones can enable different new scenarios for VoIP over WiFi. In these scenarios, private residential and corporate WiFi connections, WiFi hotspots and wide-area networks may act as complementary infrastructure support for supplying itinerant voice services combined with instant-messaging and multimedia services at advantageous prices, and enabling new competing business models in the voice market. The paper explores the state of the art on the capability of WiFi networks to support voice services in a user itinerant context, identifying actual and future strengths, weakness, opportunities and threats. -

Bluetooth Hotspot: Extending the Communication Range Between Bluetooth Devices
Pooja Sharma et al, / (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 2 (2) , 2011, 817-823 Bluetooth Hotspot: Extending the Communication Range between Bluetooth Devices Pooja Sharma B.S. Anangpuria Institute of Technology and Management Faridabad, Haryana Deepak Tyagi St. Anne Mary Education Society , Delhi Pawan Bhadana B.S. Anangpuria Institute of Technology and Management Faridabad, Haryana Abstract- Bluetooth is a wireless radio specification designed to over an extended distance. This relationship also allows for a replace the cables as the medium for data and voices signals dynamic topology that may change during any given session: between electronic devices. Bluetooth’s design sets a high as a device moves toward or away from the master device in priority on small size, low power consumption and low costs. The the network, the topology and therefore the relationships of Bluetooth specification seeks to simplify communication between electronic devices by automating the connection process. In this the devices in the immediate network change. paper we explain Bluetooth protocol stack and its different layers, then moving on to how Bluetooth networks are formed Mobile routers in a Bluetooth network control the changing and devices are located. The proposed idea in this paper is to network topologies of these networks. The routers also control develop Bluetooth hotspot and examine two different the flow of data between devices that are capable of implementation approaches. BlueSpot, the software components supporting a direct link to each other. As devices move about of the proposed Bluetooth hotspot are introduced, as well as the in a random fashion, these networks must be reconfigured on connection framework between these components and other the fly to handle the dynamic topology. -

How to Set up a Personal Hotspot on Your Iphone Or Ipad
How to set up a Personal Hotspot on your iPhone or iPad A Personal Hotspot lets you share the cellular data connection of your iPhone or iPad (Wi-Fi + Cellular) when you don't have access to a Wi-Fi network. Set up Personal Hotspot 1. Go to Settings > Cellular or Settings > Personal Hotspot. 2. Tap the slider next to Allow Others to Join. If you don't see the option for Personal Hotspot, contact your carrier to make sure that you can use Personal Hotspot with your plan. Carrier charges may apply. In order to maximize your download and upload speed, we recommend that you connect to only one device (computer or tablet) Connect to Personal Hotspot with Wi-Fi, Bluetooth, or USB Here are some tips for using each method. When you connect a device to your Personal Hotspot, the status bar turns blue and shows how many devices have joined. The number of devices that can join your Personal Hotspot at one time depends on your carrier and iPhone model. If other devices have joined your Personal Hotspot using Wi-Fi, you can use only cellular data to connect to the Internet from the host device. Use these steps to connect: Wi-Fi On the device that you want to connect to, go to Settings > Cellular > Personal Hotspot or Settings > Personal Hotspot and make sure that it's on. Then verify the Wi-Fi password and name of the phone. Stay on this screen until you’ve connected your other device to the Wi-Fi network. On the device that you want to connect, go to Settings > Wi-Fi and look for your iPhone or iPad in the list. -

VISUAL SUMMARY Communications and Networks
Rev.Confirming Pages VISUAL SUMMARY Communications and Networks COMMUNICATIONS COMMUNICATION CHANNELS Communications is the process of sharing data, pro- Communication channels carry data from one com- grams, and information between two or more com- puter to another. puters. Applications include e-mail, texting, Internet telephones, and electronic commerce. Physical Connections Physical connections use a solid medium to connect Connectivity sending and receiving devices. Connections include Connectivity is a concept related to using computer twisted pair (telephone lines and Ethernet cables), networks to link people and resources. You can link or coaxial cable, and fiber-optic cable. connect to large computers and the Internet, provid- Wireless Connections ing access to extensive information resources. Wireless connections do not use a solid substance to The Wireless Revolution connect devices. Most use radio waves. Mobile devices like smartphones and tablets have • Bluetooth— transmits data over short distances; brought dramatic changes in connectivity and com- widely used for wireless headsets, printers, and munications. These wireless devices are becoming handheld devices. widely used for computer communication. • Wi-Fi (wireless fidelity)— uses high-frequency radio signals; most home and business wireless Communication Systems networks use Wi-Fi. Communication systems transmit data from one loca- • Microwave— line-of-sight communication; used tion to another. Four basic elements are to send data between buildings; longer distances • Sending and receiving devices require microwave stations. • Communication channel (transmission medium) • WiMax (Worldwide Interoperability for Microwave Access)— extends the range of Wi-Fi • Connection (communication) devices networks using microwave connections. • Data transmission specifications • LTE (Long Term Evolution) —currently has similar performance to WiMax; promises to provide greater speed and quality transmissions in the near future. -
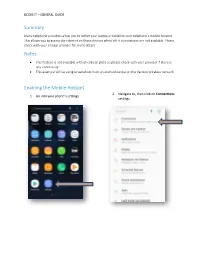
Summary Notes Enabling the Mobile Hotspot
BCOM IT – GENERAL GUIDE Summary Many cellphone providers allow you to tether your laptop or tablet to your cellphone’s mobile hotspot. This allows you to access the internet on those devices when Wi-Fi connections are not available. Please check with your cellular provider for more details. Notes • This feature is not available with all cellular plans so please check with your provider if there is any uncertainty • This example will be using screenshots from an android device on the Verizon Wireless network Enabling the Mobile Hotspot 2. Navigate to, then click on Connections 1. Go into your phone’s settings settings BCOM IT – GENERAL GUIDE 3. Select the Mobile Hotspot and 4. Switch the Mobile Hotspot to the ON Tethering option position • If this is the first time you are enabling the hotspot, you will be prompted with the dialog box below – the hotspot uses mobile data so Wi-Fi will need to be turned off (selecting OK will turn Wi-Fi off automatically) BCOM IT – GENERAL GUIDE 5. Once your mobile hotspot has been 6. Click on the network icon located on enabled, press the Mobile Hotspot the taskbar and let your computer scan button to view the network name, as for all available networks – within a few well as, the password required to seconds, you should see the mobile connect your laptop or tablet hotspot pop up in the list 7. Enter the password (see step 5) to connect to the internet* *After you are finished using your cellphones mobile hotspot, turn off the hotspot setting and reenable your phones Wi-Fi setting . -

Mobile Hotspot User Manual
Mobile Hotspot User Manual Contents Getting Started .................................................................................................................................................................... 1 Overview ................................................................................................................................................................................................ 2 System Requirements ................................................................................................................................................................ 2 Components .......................................................................................................................................................................................... 3 Device Display ..................................................................................................................................................................................... 5 Battery Management ........................................................................................................................................................................ 6 Using Your Mobile Hotspot ............................................................................................................................................ 7 Accessing the Network ..................................................................................................................................................................... 8 Using -
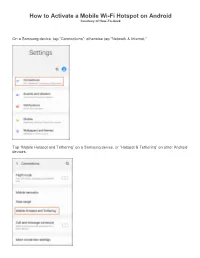
How to Activate a Mobile Wi-Fi Hotspot on Android Courtesy of How-To-Geek
How to Activate a Mobile Wi-Fi Hotspot on Android Courtesy of How-To-Geek On a Samsung device, tap “Connections”; otherwise tap “Network & Internet.” Tap “Mobile Hotspot and Tethering” on a Samsung device, or “Hotspot & Tethering” on other Android devices. On a Samsung, tap “Mobile Hotspot” to configure it—don’t tap the toggle unless you’ve already configured your hotspot. On other Android devices, tap “Set Up Wi-Fi Hotspot” under “Portable Wi-Fi Hotspot.” On most Android devices, you configure your Wi-Fi hotspot in this menu. Choose a suitable network name, a password, a Wi-Fi security option, and then tap “Save.” If you use a Samsung device, tap the hamburger menu at the top left, and then tap “Configure Mobile Hotspot” to access these settings. You can then customize your network name, password, and Wi-Fi settings in more detail. When you’re finished, tap “Save.” Enable Android’s Mobile Wi-Fi Hotspot After you configure your Wi-Fi hotspot, toggle-On the “Portable Wi-Fi Hotspot” (most Android devices) or “Mobile Hotspot” (Samsung). Android might warn you about increased data and battery usage; tap “OK” to confirm. Your Wi-Fi hotspot is now active and ready to connect. Once your mobile hotspot is active, it should appear the same as any other Wi-Fi network on your other devices. Use the password you selected during setup to connect. You can also quickly enable or disable the feature from quick actions in the notifications shade. Swipe down on your display to view your notifications shade and reveal your quick actions.