Short Reference on Spin (From Computational-Physics Course)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kinematic Relativity of Quantum Mechanics: Free Particle with Different Boundary Conditions
Journal of Applied Mathematics and Physics, 2017, 5, 853-861 http://www.scirp.org/journal/jamp ISSN Online: 2327-4379 ISSN Print: 2327-4352 Kinematic Relativity of Quantum Mechanics: Free Particle with Different Boundary Conditions Gintautas P. Kamuntavičius 1, G. Kamuntavičius 2 1Department of Physics, Vytautas Magnus University, Kaunas, Lithuania 2Christ’s College, University of Cambridge, Cambridge, UK How to cite this paper: Kamuntavičius, Abstract G.P. and Kamuntavičius, G. (2017) Kinema- tic Relativity of Quantum Mechanics: Free An investigation of origins of the quantum mechanical momentum operator Particle with Different Boundary Condi- has shown that it corresponds to the nonrelativistic momentum of classical tions. Journal of Applied Mathematics and special relativity theory rather than the relativistic one, as has been uncondi- Physics, 5, 853-861. https://doi.org/10.4236/jamp.2017.54075 tionally believed in traditional relativistic quantum mechanics until now. Taking this correspondence into account, relativistic momentum and energy Received: March 16, 2017 operators are defined. Schrödinger equations with relativistic kinematics are Accepted: April 27, 2017 introduced and investigated for a free particle and a particle trapped in the Published: April 30, 2017 deep potential well. Copyright © 2017 by authors and Scientific Research Publishing Inc. Keywords This work is licensed under the Creative Commons Attribution International Special Relativity, Quantum Mechanics, Relativistic Wave Equations, License (CC BY 4.0). Solutions -

Relativistic Quantum Mechanics 1
Relativistic Quantum Mechanics 1 The aim of this chapter is to introduce a relativistic formalism which can be used to describe particles and their interactions. The emphasis 1.1 SpecialRelativity 1 is given to those elements of the formalism which can be carried on 1.2 One-particle states 7 to Relativistic Quantum Fields (RQF), which underpins the theoretical 1.3 The Klein–Gordon equation 9 framework of high energy particle physics. We begin with a brief summary of special relativity, concentrating on 1.4 The Diracequation 14 4-vectors and spinors. One-particle states and their Lorentz transforma- 1.5 Gaugesymmetry 30 tions follow, leading to the Klein–Gordon and the Dirac equations for Chaptersummary 36 probability amplitudes; i.e. Relativistic Quantum Mechanics (RQM). Readers who want to get to RQM quickly, without studying its foun- dation in special relativity can skip the first sections and start reading from the section 1.3. Intrinsic problems of RQM are discussed and a region of applicability of RQM is defined. Free particle wave functions are constructed and particle interactions are described using their probability currents. A gauge symmetry is introduced to derive a particle interaction with a classical gauge field. 1.1 Special Relativity Einstein’s special relativity is a necessary and fundamental part of any Albert Einstein 1879 - 1955 formalism of particle physics. We begin with its brief summary. For a full account, refer to specialized books, for example (1) or (2). The- ory oriented students with good mathematical background might want to consult books on groups and their representations, for example (3), followed by introductory books on RQM/RQF, for example (4). -

Class 2: Operators, Stationary States
Class 2: Operators, stationary states Operators In quantum mechanics much use is made of the concept of operators. The operator associated with position is the position vector r. As shown earlier the momentum operator is −iℏ ∇ . The operators operate on the wave function. The kinetic energy operator, T, is related to the momentum operator in the same way that kinetic energy and momentum are related in classical physics: p⋅ p (−iℏ ∇⋅−) ( i ℏ ∇ ) −ℏ2 ∇ 2 T = = = . (2.1) 2m 2 m 2 m The potential energy operator is V(r). In many classical systems, the Hamiltonian of the system is equal to the mechanical energy of the system. In the quantum analog of such systems, the mechanical energy operator is called the Hamiltonian operator, H, and for a single particle ℏ2 HTV= + =− ∇+2 V . (2.2) 2m The Schrödinger equation is then compactly written as ∂Ψ iℏ = H Ψ , (2.3) ∂t and has the formal solution iHt Ψ()r,t = exp − Ψ () r ,0. (2.4) ℏ Note that the order of performing operations is important. For example, consider the operators p⋅ r and r⋅ p . Applying the first to a wave function, we have (pr⋅) Ψ=−∇⋅iℏ( r Ψ=−) i ℏ( ∇⋅ rr) Ψ− i ℏ( ⋅∇Ψ=−) 3 i ℏ Ψ+( rp ⋅) Ψ (2.5) We see that the operators are not the same. Because the result depends on the order of performing the operations, the operator r and p are said to not commute. In general, the expectation value of an operator Q is Q=∫ Ψ∗ (r, tQ) Ψ ( r , td) 3 r . -

Question 1: Kinetic Energy Operator in 3D in This Exercise We Derive 2 2 ¯H ¯H 1 ∂2 Lˆ2 − ∇2 = − R +
ExercisesQuantumDynamics,week4 May22,2014 Question 1: Kinetic energy operator in 3D In this exercise we derive 2 2 ¯h ¯h 1 ∂2 lˆ2 − ∇2 = − r + . (1) 2µ 2µ r ∂r2 2µr2 The angular momentum operator is defined by ˆl = r × pˆ, (2) where the linear momentum operator is pˆ = −i¯h∇. (3) The first step is to work out the lˆ2 operator and to show that 2 2 ˆl2 = −¯h (r × ∇) · (r × ∇)=¯h [−r2∇2 + r · ∇ + (r · ∇)2]. (4) A convenient way to work with cross products, a = b × c, (5) is to write the components using the Levi-Civita tensor ǫijk, 3 3 ai = ǫijkbjck ≡ X X ǫijkbjck, (6) j=1 k=1 where we introduced the Einstein summation convention: whenever an index appears twice one assumes there is a sum over this index. 1a. Write the cross product in components and show that ǫ1,2,3 = ǫ2,3,1 = ǫ3,1,2 =1, (7) ǫ3,2,1 = ǫ2,1,3 = ǫ1,3,2 = −1, (8) and all other component of the tensor are zero. Note: the tensor is +1 for ǫ1,2,3, it changes sign whenever two indices are permuted, and as a result it is zero whenever two indices are equal. 1b. Check this relation ǫijkǫij′k′ = δjj′ δkk′ − δjk′ δj′k. (9) (Remember the implicit summation over index i). 1c. Use Eq. (9) to derive Eq. (4). 1d. Show that ∂ r = r · ∇ (10) ∂r 1e. Show that 1 ∂2 ∂2 2 ∂ r = + (11) r ∂r2 ∂r2 r ∂r 1f. Combine the results to derive Eq. -

Quantum Physics (UCSD Physics 130)
Quantum Physics (UCSD Physics 130) April 2, 2003 2 Contents 1 Course Summary 17 1.1 Problems with Classical Physics . .... 17 1.2 ThoughtExperimentsonDiffraction . ..... 17 1.3 Probability Amplitudes . 17 1.4 WavePacketsandUncertainty . ..... 18 1.5 Operators........................................ .. 19 1.6 ExpectationValues .................................. .. 19 1.7 Commutators ...................................... 20 1.8 TheSchr¨odingerEquation .. .. .. .. .. .. .. .. .. .. .. .. .... 20 1.9 Eigenfunctions, Eigenvalues and Vector Spaces . ......... 20 1.10 AParticleinaBox .................................... 22 1.11 Piecewise Constant Potentials in One Dimension . ...... 22 1.12 The Harmonic Oscillator in One Dimension . ... 24 1.13 Delta Function Potentials in One Dimension . .... 24 1.14 Harmonic Oscillator Solution with Operators . ...... 25 1.15 MoreFunwithOperators. .. .. .. .. .. .. .. .. .. .. .. .. .... 26 1.16 Two Particles in 3 Dimensions . .. 27 1.17 IdenticalParticles ................................. .... 28 1.18 Some 3D Problems Separable in Cartesian Coordinates . ........ 28 1.19 AngularMomentum.................................. .. 29 1.20 Solutions to the Radial Equation for Constant Potentials . .......... 30 1.21 Hydrogen........................................ .. 30 1.22 Solution of the 3D HO Problem in Spherical Coordinates . ....... 31 1.23 Matrix Representation of Operators and States . ........... 31 1.24 A Study of ℓ =1OperatorsandEigenfunctions . 32 1.25 Spin1/2andother2StateSystems . ...... 33 1.26 Quantum -

Quantization of the Free Electromagnetic Field: Photons and Operators G
Quantization of the Free Electromagnetic Field: Photons and Operators G. M. Wysin [email protected], http://www.phys.ksu.edu/personal/wysin Department of Physics, Kansas State University, Manhattan, KS 66506-2601 August, 2011, Vi¸cosa, Brazil Summary The main ideas and equations for quantized free electromagnetic fields are developed and summarized here, based on the quantization procedure for coordinates (components of the vector potential A) and their canonically conjugate momenta (components of the electric field E). Expressions for A, E and magnetic field B are given in terms of the creation and annihilation operators for the fields. Some ideas are proposed for the inter- pretation of photons at different polarizations: linear and circular. Absorption, emission and stimulated emission are also discussed. 1 Electromagnetic Fields and Quantum Mechanics Here electromagnetic fields are considered to be quantum objects. It’s an interesting subject, and the basis for consideration of interactions of particles with EM fields (light). Quantum theory for light is especially important at low light levels, where the number of light quanta (or photons) is small, and the fields cannot be considered to be continuous (opposite of the classical limit, of course!). Here I follow the traditinal approach of quantization, which is to identify the coordinates and their conjugate momenta. Once that is done, the task is straightforward. Starting from the classical mechanics for Maxwell’s equations, the fundamental coordinates and their momenta in the QM sys- tem must have a commutator defined analogous to [x, px] = i¯h as in any simple QM system. This gives the correct scale to the quantum fluctuations in the fields and any other dervied quantities. -

Simple Quantum Systems in the Momentum Representation
Simple quantum systems in the momentum rep- resentation H. N. N´u˜nez-Y´epez † Departamento de F´ısica, Universidad Aut´onoma Metropolitana-Iztapalapa, Apar- tado Postal 55-534, Iztapalapa 09340 D.F. M´exico, E. Guillaum´ın-Espa˜na, R. P. Mart´ınez-y-Romero, A. L. Salas-Brito ‡ ¶ Laboratorio de Sistemas Din´amicos, Departamento de Ciencias B´asicas, Univer- sidad Aut´onoma Metropolitana-Azcapotzalco, Apartado Postal 21-726, Coyoacan 04000 D. F. M´exico Abstract The momentum representation is seldom used in quantum mechanics courses. Some students are thence surprised by the change in viewpoint when, in doing advanced work, they have to use the momentum rather than the coordinate repre- sentation. In this work, we give an introduction to quantum mechanics in momen- tum space, where the Schr¨odinger equation becomes an integral equation. To this end we discuss standard problems, namely, the free particle, the quantum motion under a constant potential, a particle interacting with a potential step, and the motion of a particle under a harmonic potential. What is not so standard is that they are all conceived from momentum space and hence they, with the exception of the free particle, are not equivalent to the coordinate space ones with the same arXiv:physics/0001030v2 [physics.ed-ph] 18 Jan 2000 names. All the problems are solved within the momentum representation making no reference to the systems they correspond to in the coordinate representation. E-mail: [email protected] † On leave from Fac. de Ciencias, UNAM. E-mail: [email protected] ‡ E-mail: [email protected] or [email protected] ¶ 1 1. -

An Approach to Quantum Mechanics
An Approach to Quantum Mechanics Frank Rioux Department of Chemistry St. John=s University | College of St. Benedict The purpose of this tutorial is to introduce the basics of quantum mechanics using Dirac bracket notation while working in one dimension. Dirac notation is a succinct and powerful language for expressing quantum mechanical principles; restricting attention to one-dimensional examples reduces the possibility that mathematical complexity will stand in the way of understanding. A number of texts make extensive use of Dirac notation (1-5). In addition a summary of its main elements is provided at: http://www.users.csbsju.edu/~frioux/dirac/dirac.htm. Wave-particle duality is the essential concept of quantum mechanics. DeBroglie expressed this idea mathematically as λ = h/mv = h/p. On the left is the wave property λ, and on the right the particle property mv, momentum. The most general coordinate space wave function for a free particle with wavelength λ is the complex Euler function shown below. ⎛⎞⎛⎞⎛⎞x xx xiλπ==+exp⎜⎟⎜⎟⎜⎟ 2 cos 2 π i sin 2 π ⎝⎠⎝⎠⎝⎠λ λλ Equation 1 Feynman called this equation “the most remarkable formula in mathematics.” He referred to it as “our jewel.” And indeed it is, because when it is enriched with de Broglie’s relation it serves as the foundation of quantum mechanics. According to de Broglie=s hypothesis, a particle with a well-defined wavelength also has a well-defined momentum. Therefore, we can obtain the momentum wave function (unnormalized) of the particle in coordinate space by substituting the deBroglie relation into equation (1). -

Lecture 4: the Schrödinger Wave Equation
4 THE SCHRODINGER¨ WAVE EQUATION 1 4 The Schr¨odinger wave equation We have noted in previous lectures that all particles, both light and matter, can be described as a localised wave packet. • De Broglie suggested a relationship between the effective wavelength of the wave function associated with a given matter or light particle its the momentum. This relationship was subsequently confirmed experimentally for electrons. • Consideration of the two slit experiment has provided an understanding of what we can and cannot achieve with the wave function representing the particle: The wave function Ψ is not observable. According to the statistical interpretation of Born, the quantity Ψ∗Ψ = |Ψ2| is observable and represents the probability density of locating the particle in a given elemental volume. To understand the wave function further, we require a wave equation from which we can study the evolution of wave functions as a function of position and time, in general within a potential field (e.g. the potential fields associated with the Coulomb or strong nuclear force). As we shall see, manipulation of the wave equation will permit us to calculate “most probable” values of a particle’s position, momentum, energy, etc. These quantities form the study of me- chanics within classical physics. Our quantum theory has now become quantum mechanics – the description of mechanical physics on the quantum scale. The particular sub-branch of quantum mechanics accessible via wave theory is sometimes referred to as wave mechanics. The time–dependent Schr¨odinger wave equation is the quantum wave equation ∂Ψ(x, t) h¯2 ∂2Ψ(x, t) ih¯ = − + V (x, t) Ψ(x, t), (1) ∂t 2m ∂x2 √ where i = −1, m is the mass of the particle,h ¯ = h/2π, Ψ(x, t) is the wave function representing the particle and V (x, t) is a potential energy function. -

Tachyonic Dirac Equation Revisited
Tachyonic Dirac Equation Revisited Luca Nanni Faculty of Natural Science, University of Ferrara, 44122 Ferrara, Italy [email protected] Abstract In this paper, we revisit the two theoretical approaches for the formulation of the tachyonic Dirac equation. The first approach works within the theory of restricted relativity, starting from a Lorentz invariant Lagrangian consistent with a spacelike four-momentum. The second approach uses the theory of relativity extended to superluminal motions and works directly on the ordinary Dirac equation through superluminal Lorentz transformations. The equations resulting from the two approaches show mostly different, if not opposite, properties. In particular, the first equation violates the invariance under the action of the parity and charge conjugation operations. Although it is a good mathematical tool to describe the dynamics of a space-like particle, it also shows that the mean particle velocity is subluminal. In contrast, the second equation is invariant under the action of parity and charge conjugation symmetries, but the particle it describes is consistent with the classical dynamics of a tachyon. This study shows that it is not possible with the currently available theories to formulate a covariant equation that coherently describes the neutrino in the framework of the physics of tachyons, and depending on the experiment, one equation rather than the other should be used. Keywords: Dirac equation, tachyon, non-Hermitian operator, superluminal Lorentz transformations, CPT symmetry. 1. Introduction The Dirac equation is one of the most widely used mathematical tools in modern theoretical physics [1-4]. It was formulated in 1928 and has since been mentioned in the literature of most scientific areas. -
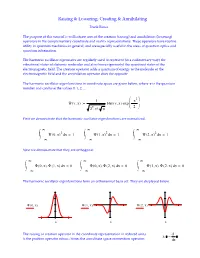
The Creation and Annihilation Operators Are 5X5 Matrices
Raising & Lowering; Creating & Annihilating Frank Rioux The purpose of this tutorial is to illustrate uses of the creation (raising) and annihilation (lowering) operators in the complementary coordinate and matrix representations. These operators have routine utility in quantum mechanics in general, and are especially useful in the areas of quantum optics and quantum information. The harmonic oscillator eigenstates are regularly used to represent (in a rudimentary way) the vibrational states of diatomic molecules and also (more rigorously) the quantized states of the electromagnetic field. The creation operator adds a quantum of energy to the molecule or the electromagnetic field and the annihilation operator does the opposite. The harmonic oscillator eigenfunctions in coordinate space are given below, where v is the quantum number and can have the values 0, 1, 2, ... 2 1 x Ψ()vx Her() v x exp v 2 2 v π First we demonstrate that the harmonic oscillator eigenfunctions are normalized. ∞ ∞ ∞ 2 2 2 Ψ()0x d1x Ψ()1x d1x Ψ()2x d1x ∞ ∞ ∞ Next we demonstrate that they are orthogonal: ∞ ∞ ∞ Ψ()0x Ψ()1x d0x Ψ()0x Ψ()2x d0x Ψ()1x Ψ()2x d0x ∞ ∞ ∞ The harmonic oscillator eigenfunctions form an orthonormal basis set. They are displayed below. Ψ()0x Ψ()1x Ψ()2x x x x d The raising or creation operator in the coordinate representation in reduced units x is the position operator minus i times the coordinate space momentum operator: dx Operating on the v = 0 eigenfunction d xΨ()0x Ψ()0x yields the v = 1 eigenfunction: dx x d The lowering or annihilation operator in the coordinate representation in reduced x units is the position operator plus i times the coordinate space momentum operator: dx d Operating on the v = 2 eigenfunction xΨ()2x Ψ()2x yields the v = 1 eigenfunction: dx x The energy operator in coordinate space and the energy expectation value for the v = 2 state are given below. -

Quantum Theory I, Lecture 6 Notes
Lecture 6 8.321 Quantum Theory I, Fall 2017 33 Lecture 6 (Sep. 25, 2017) 6.1 Solving Problems in Convenient Bases Last time we talked about the momentum and position bases. From a practical point of view, it often pays off to not solve a particular problem in the position basis, and instead choose a more convenient basis, such as the momentum basis. Suppose we have a Hamiltonian 1 d2 H = − + ax : (6.1) 2m dx2 We could solve this in the position basis; it is a second-order differential equation, with solutions called Airy functions. However, this is easy to solve in the momentum basis. In the momentum basis, the Hamiltonian becomes p2 d H = + ia ; (6.2) 2m ~dp which is only a first-order differential equation. For other problems, the most convenient basis may not be the position or the momentum basis, but rather some mixed basis. It is worth becoming comfortable with change of basis in order to simplify problems. 6.2 Quantum Dynamics Recall the fourth postulate: time evolution is a map 0 0 j (t)i 7! t = U t ; t j (t)i ; (6.3) where U(t0; t) is the time-evolution operator, which is unitary. In the case where t0 and t differ by an infinitesimal amount, we can rewrite time evolution as a differential equation, d i j (t)i = H(t)j (t)i ; (6.4) ~dt where H(t) is the Hamiltonian, which is a Hermitian operator. In general, we can always write 0 0 t = U t ; t j (t)i (6.5) for some operator U(t0; t).