Shifted Gradient Similarity: a Perceptual Video Quality Assessment Index for Adaptive Streaming Encoding”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Network Working Group A
Network Working Group A. Filippov Internet Draft Huawei Technologies Intended status: Informational A. Norkin Netflix J.R. Alvarez Huawei Technologies Expires: May 17, 2017 November 17, 2016 <Video Codec Requirements and Evaluation Methodology> draft-ietf-netvc-requirements-04.txt Status of this Memo This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF), its areas, and its working groups. Note that other groups may also distribute working documents as Internet- Drafts. The list of current Internet-Drafts can be accessed at http://datatracker.ietf.org/drafts/current/ Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress." The list of current Internet-Drafts can be accessed at http://www.ietf.org/1id-abstracts.html The list of Internet-Draft Shadow Directories can be accessed at http://www.ietf.org/shadow.html This Internet-Draft will expire on May 17, 2017. Copyright Notice Copyright (c) 2016 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with <Filippov> Expires May 17, 2017 [Page 1] Internet-Draft Video Codec Requirements and Evaluation November 2016 respect to this document. -

Edge Detection of Noisy Images Using 2-D Discrete Wavelet Transform Venkata Ravikiran Chaganti
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2005 Edge Detection of Noisy Images Using 2-D Discrete Wavelet Transform Venkata Ravikiran Chaganti Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY FAMU-FSU COLLEGE OF ENGINEERING EDGE DETECTION OF NOISY IMAGES USING 2-D DISCRETE WAVELET TRANSFORM BY VENKATA RAVIKIRAN CHAGANTI A thesis submitted to the Department of Electrical Engineering in partial fulfillment of the requirements for the degree of Master of Science Degree Awarded: Spring Semester, 2005 The members of the committee approve the thesis of Venkata R. Chaganti th defended on April 11 , 2005. __________________________________________ Simon Y. Foo Professor Directing Thesis __________________________________________ Anke Meyer-Baese Committee Member __________________________________________ Rodney Roberts Committee Member Approved: ________________________________________________________________________ Leonard J. Tung, Chair, Department of Electrical and Computer Engineering Ching-Jen Chen, Dean, FAMU-FSU College of Engineering The office of Graduate Studies has verified and approved the above named committee members. ii Dedicate to My Father late Dr.Rama Rao, Mother, Brother and Sister-in-law without whom this would never have been possible iii ACKNOWLEDGEMENTS I thank my thesis advisor, Dr.Simon Foo, for his help, advice and guidance during my M.S and my thesis. I also thank Dr.Anke Meyer-Baese and Dr. Rodney Roberts for serving on my thesis committee. I would like to thank my family for their constant support and encouragement during the course of my studies. I would like to acknowledge support from the Department of Electrical Engineering, FAMU-FSU College of Engineering. -

DVP Tutorial
IP Video Conferencing: A Tutorial Roman Sorokin, Jean-Louis Rougier Abstract Video conferencing is a well-established area of communications, which have been studied for decades. Recently this area has received a new impulse due to significantly increased bandwidth of Local and Wide area networks, appearance of low-priced video equipment and development of web based media technologies. This paper presents the main techniques behind the modern IP-based videoconferencing services, with a particular focus on codecs, network protocols, architectures and standardization efforts. Questions of security and topologies are also tackled. A description of a typical video conference scenario is provided, demonstrating how the technologies, responsible for different conference aspects, are working together. Traditional industrial disposition as well as modern innovative approaches are both addressed. Current industry trends are highlighted in respect to the topics, described in the tutorial. Legacy analog/digital technologies, together with the gateways between the traditional and the IP videoconferencing systems, are not considered. Keywords Video Conferencing, codec, SVC, MCU, SIP, RTP Roman Sorokin ALE International, Colombes, France e-mail: [email protected] Jean-Louis Rougier Télécom ParisTech, Paris, France e-mail: [email protected] 1 1 Introduction Video conferencing is a two-way interactive communication, delivered over networks of different nature, which allows people from several locations to participate in a meeting. Conference participants use video conferencing endpoints of different types. Generally a video conference endpoint has a camera and a microphone. The video stream, generated by the camera, and the audio stream, coming from the microphone, are both compressed and sent to the network interface. -

High Efficiency, Moderate Complexity Video Codec Using Only RF IPR
Thor High Efficiency, Moderate Complexity Video Codec using only RF IPR draft-fuldseth-netvc-thor-00 Arild Fuldseth, Gisle Bjontegaard (Cisco) IETF 93 – Prague, CZ – July 2015 1 Design principles • Moderate complexity to allow real-time implementation in SW on common HW, as well as new HW designs • Basic building blocks from well-known hybrid approach (motion compensated prediction and transform coding) • Common design elements in modern codecs – Larger block sizes and transforms, up to 64x64 – Quarter pixel interpolation, motion vector prediction, etc. • Cisco RF IPR (note well: declaration filed on draft) – Deblocking, transforms, etc. (some also essential in H.265/4) • Avoid non-RF IPR – If/when others offer RF IPR, design/performance will improve 2 Encoder Architecture Input Transform Quantizer Entropy Output video Coding bitstream - Inverse Transform Intra Frame Prediction Loop filters Inter Frame Prediction Reconstructed Motion Frame Estimation Memory 3 Decoder Architecture Input Entropy Inverse Bitstream Decoding Transform Intra Frame Prediction Loop filters Inter Frame Prediction Output video Reconstructed Frame Memory 4 Block Structure • Super block (SB) 64x64 • Quad-tree split into coding blocks (CB) >= 8x8 • Multiple prediction blocks (PB) per CB • Intra: 1 PB per CB • Inter: 1, 2 (rectangular) or 4 (square) PBs per CB • 1 or 4 transform blocks (TB) per CB 5 Coding-block modes • Intra • Inter0 MV index, no residual information • Inter1 MV index, residual information • Inter2 Explicit motion vector information, residual information -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -
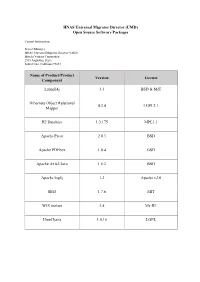
UMD) Open Source Software Packages
HNAS Universal Migrator Director (UMD) Open Source Software Packages Contact Information: Project Manager HNAS Universal Migrator Director (UMD) Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Launch4j 3.3 BSD & MIT Hibernate Object Relational 4.3.4 LGPL2.1 Mapper H2 Database 1.3.175 MPL1.1 Apache Pivot 2.0.3 BSD Apache PDFbox 1.8.4 BSD Apache Axis2/Java 1.6.2 BSD Apache log4j 1.2 Apache v2.0 Slf4J 1.7.6 MIT WIX toolset 3.8 Ms-RL JfreeCharts 1.0.16 LGPL The text of the open source software licenses listed in this document is provided in the Open Source Software License Terms document on www.hitachivantara.com. Note that the source code for packages licensed under the GNU General Public License or similar type of license that requires the licensor to make the source code publicly available (“GPL Software”) may be available for download as indicated. If the source code for GPL Software is not included in the software or available for download, please send requests for source code for GPL Software to the contact person listed above for this product. The material in this document is provided “AS IS,” without warranty of any kind, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. Unless specified in an applicable open source license, access to this material grants you no right or license, express or implied, statutorily or otherwise, under any patent, trade secret, copyright, or any other intellectual property right of Hitachi Vantara Corporation (“Hitachi”). -

Study and Comparison of Different Edge Detectors for Image
Global Journal of Computer Science and Technology Graphics & Vision Volume 12 Issue 13 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc. (USA) Online ISSN: 0975-4172 & Print ISSN: 0975-4350 Study and Comparison of Different Edge Detectors for Image Segmentation By Pinaki Pratim Acharjya, Ritaban Das & Dibyendu Ghoshal Bengal Institute of Technology and Management Santiniketan, West Bengal, India Abstract - Edge detection is very important terminology in image processing and for computer vision. Edge detection is in the forefront of image processing for object detection, so it is crucial to have a good understanding of edge detection operators. In the present study, comparative analyses of different edge detection operators in image processing are presented. It has been observed from the present study that the performance of canny edge detection operator is much better then Sobel, Roberts, Prewitt, Zero crossing and LoG (Laplacian of Gaussian) in respect to the image appearance and object boundary localization. The software tool that has been used is MATLAB. Keywords : Edge Detection, Digital Image Processing, Image segmentation. GJCST-F Classification : I.4.6 Study and Comparison of Different Edge Detectors for Image Segmentation Strictly as per the compliance and regulations of: © 2012. Pinaki Pratim Acharjya, Ritaban Das & Dibyendu Ghoshal. This is a research/review paper, distributed under the terms of the Creative Commons Attribution-Noncommercial 3.0 Unported License http://creativecommons.org/licenses/by-nc/3.0/), permitting all non-commercial use, distribution, and reproduction inany medium, provided the original work is properly cited. Study and Comparison of Different Edge Detectors for Image Segmentation Pinaki Pratim Acharjya α, Ritaban Das σ & Dibyendu Ghoshal ρ Abstract - Edge detection is very important terminology in noise the Canny edge detection [12-14] operator has image processing and for computer vision. -

2. Enterprise Architecture 2.4 User Interaction Capabilities
VA Enterprise Design Patterns: 2. Enterprise Architecture 2.4 User Interaction Capabilities Office of Technology Strategies (TS) Architecture, Strategy, and Design (ASD) Office of Information and Technology (OI&T) Version 1.0 Date Issued: October 2015 THIS PAGE INTENTIONALLY LEFT BLANK FOR PRINTING PURPOSES APPROVAL COORDINATION Digitally signed by TIMOTHY L MCGRAIL 111224 TIMOTHY L DN: dc=gov, dc=va, o=internal, ou=people, MCGRAIL 0.9.2342.19200300.100.1.1=tim. [email protected], cn=TIMOTHY L MCGRAIL 111224 Date: 111224 Date: 2015.11.17 08:23:43 -05'00' Tim McGrail Senior Program Analyst ASD Technology Strategies Digitally signed by PAUL A. TIBBITS PAUL A. 116858 DN: dc=gov, dc=va, o=internal, ou=people, TIBBITS 0.9.2342.19200300.100.1.1=paul.tibbits@ va.gov, cn=PAUL A. TIBBITS 116858 Date: Reason: I am approving this document. 116858 Date: 2015.11.30 12:29:02 -05'00' Paul A. Tibbits, M.D. DCIO Architecture, Strategy, and Design REVISION HISTORY Version Date Organization Notes 0.1 2/27/2015 ASD TS Initial Draft Updated draft to reflect additional research and inputs 0.3 5/8/2015 ASD TS from vendor engagements and Stakeholders, with QA provided by TS DP Contractor Team Updated draft to reflect feedback from the Public 0.5 5/22/2015 ASD TS Forum held on 13 May 2015, and QA provided by ASD TS Updated version to align to the latest template for 0.7 10/13/15 ASD TS Enterprise Design Patterns and to account for internal QA review 0.9 REVISION HISTORY APPROVALS Version Date Approver Role 0.1 2/27/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.3 5/8/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.5 5/22/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.7 10/13/15 Joseph Brooks ASD TS Design Pattern Government Lead 1.0 11/17/15 Tim McGrail ASD TS Design Pattern Final Review TABLE OF CONTENTS 1.0 INTRODUCTION ........................................................................................................................................ -

The Power of Interoperability: Why Objects Are Inevitable
The Power of Interoperability: Why Objects Are Inevitable Jonathan Aldrich Carnegie Mellon University Pittsburgh, PA, USA [email protected] Abstract 1. Introduction Three years ago in this venue, Cook argued that in Object-oriented programming has been highly suc- their essence, objects are what Reynolds called proce- cessful in practice, and has arguably become the dom- dural data structures. His observation raises a natural inant programming paradigm for writing applications question: if procedural data structures are the essence software in industry. This success can be documented of objects, has this contributed to the empirical success in many ways. For example, of the top ten program- of objects, and if so, how? ming languages at the LangPop.com index, six are pri- This essay attempts to answer that question. After marily object-oriented, and an additional two (PHP reviewing Cook’s definition, I propose the term ser- and Perl) have object-oriented features.1 The equiva- vice abstractions to capture the essential nature of ob- lent numbers for the top ten languages in the TIOBE in- jects. This terminology emphasizes, following Kay, that dex are six and three.2 SourceForge’s most popular lan- objects are not primarily about representing and ma- guages are Java and C++;3 GitHub’s are JavaScript and nipulating data, but are more about providing ser- Ruby.4 Furthermore, objects’ influence is not limited vices in support of higher-level goals. Using examples to object-oriented languages; Cook [8] argues that Mi- taken from object-oriented frameworks, I illustrate the crosoft’s Component Object Model (COM), which has unique design leverage that service abstractions pro- a C language interface, is “one of the most pure object- vide: the ability to define abstractions that can be ex- oriented programming models yet defined.” Academ- tended, and whose extensions are interoperable in a ically, object-oriented programming is a primary focus first-class way. -

Feature-Based Image Comparison and Its Application in Wireless Visual Sensor Networks
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 5-2011 Feature-based Image Comparison and Its Application in Wireless Visual Sensor Networks Yang Bai University of Tennessee Knoxville, Department of EECS, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Other Computer Engineering Commons, and the Robotics Commons Recommended Citation Bai, Yang, "Feature-based Image Comparison and Its Application in Wireless Visual Sensor Networks. " PhD diss., University of Tennessee, 2011. https://trace.tennessee.edu/utk_graddiss/946 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Yang Bai entitled "Feature-based Image Comparison and Its Application in Wireless Visual Sensor Networks." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in Computer Engineering. Hairong Qi, Major Professor We have read this dissertation and recommend its acceptance: Mongi A. Abidi, Qing Cao, Steven Wise Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) Feature-based Image Comparison and Its Application in Wireless Visual Sensor Networks A Dissertation Presented for the Doctor of Philosophy Degree The University of Tennessee, Knoxville Yang Bai May 2011 Copyright c 2011 by Yang Bai All rights reserved. -

Computer Vision: Edge Detection
Edge Detection Edge detection Convert a 2D image into a set of curves • Extracts salient features of the scene • More compact than pixels Origin of Edges surface normal discontinuity depth discontinuity surface color discontinuity illumination discontinuity Edges are caused by a variety of factors Edge detection How can you tell that a pixel is on an edge? Profiles of image intensity edges Edge detection 1. Detection of short linear edge segments (edgels) 2. Aggregation of edgels into extended edges (maybe parametric description) Edgel detection • Difference operators • Parametric-model matchers Edge is Where Change Occurs Change is measured by derivative in 1D Biggest change, derivative has maximum magnitude Or 2nd derivative is zero. Image gradient The gradient of an image: The gradient points in the direction of most rapid change in intensity The gradient direction is given by: • how does this relate to the direction of the edge? The edge strength is given by the gradient magnitude The discrete gradient How can we differentiate a digital image f[x,y]? • Option 1: reconstruct a continuous image, then take gradient • Option 2: take discrete derivative (finite difference) How would you implement this as a cross-correlation? The Sobel operator Better approximations of the derivatives exist • The Sobel operators below are very commonly used -1 0 1 1 2 1 -2 0 2 0 0 0 -1 0 1 -1 -2 -1 • The standard defn. of the Sobel operator omits the 1/8 term – doesn’t make a difference for edge detection – the 1/8 term is needed to get the right gradient -

Video Compression Optimized for Racing Drones
Video compression optimized for racing drones Henrik Theolin Computer Science and Engineering, master's level 2018 Luleå University of Technology Department of Computer Science, Electrical and Space Engineering Video compression optimized for racing drones November 10, 2018 Preface To my wife and son always! Without you I'd never try to become smarter. Thanks to my supervisor Staffan Johansson at Neava for providing room, tools and the guidance needed to perform this thesis. To my examiner Rickard Nilsson for helping me focus on the task and reminding me of the time-limit to complete the report. i of ii Video compression optimized for racing drones November 10, 2018 Abstract This thesis is a report on the findings of different video coding tech- niques and their suitability for a low powered lightweight system mounted on a racing drone. Low latency, high consistency and a robust video stream is of the utmost importance. The literature consists of multiple comparisons and reports on the efficiency for the most commonly used video compression algorithms. These reports and findings are mainly not used on a low latency system but are testing in a laboratory environment with settings unusable for a real-time system. The literature that deals with low latency video streaming and network instability shows that only a limited set of each compression algorithms are available to ensure low complexity and no added delay to the coding process. The findings re- sulted in that AVC/H.264 was the most suited compression algorithm and more precise the x264 implementation was the most optimized to be able to perform well on the low powered system.