Lsd2 – Joint Denoising and Deblurring 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
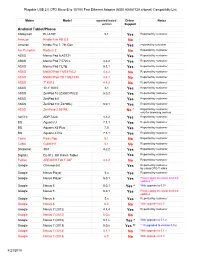
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A Chipset) Compatiblity List
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A chipset) Compatiblity List Maker Model reported/tested Driver Notes version Support Android Tablet/Phone Alldaymall EU-A10T 5.1 Yes Reported by customer Amazon Kindle Fire HD 8.9 No Amazon Kindle Fire 7, 7th Gen Yes reported by customer Am Pumpkin Radium 2 No Reported by customer ASUS Memo Pad 8 AST21 Yes Reported by customer ASUS Memo Pad 7 572CL 4.4.2 Yes Reported by customer ASUS Memo Pad 7 LTE 5.1.1 Yes Reported by customer ASUS MeMO Pad 7 ME176C2 4.4.2 No Reported by customer ASUS MeMO Pad HD 7 ME173X 4.4.1 No Reported by customer ASUS 7" K013 4.4.2 No Reported by customer ASUS 10.1" K010 4.4 Yes Reported by customer ASUS ZenPad 10 (Z300C/P023) 5.0.2 Yes Reported by customer ASUS ZenPad 8.0 Yes Reported by customer ASUS ZenPad 7.0(Z370KL) 6.0.1 Yes Reported by customer ASUS ZenFone 2 551ML No * Reported by customer, only for browsing worked ΛzICHI ADP-722A 4.4.2 Yes Reported by customer BQ Aquaris U 7.1.1 Yes Reported by customer BQ Aquaris X5 Plus 7.0 Yes Reported by customer BQ Aquaris X Pro 7.1.1 Yes Reported by customer Covia Fleas Pop 5.1 No Reported by customer Cubot Cubot H1 5.1 No Reported by customer Datawind 3G7 4.2.2 Yes Reported by customer Digital2 D2-912_BK 9-Inch Tablet Yes Reported by customer Fujitsu ARROWS Tab F-02F 4.4.2 No Reported by customer Google Chromecast Yes Reported by customer, by using OTG Y cable Google Nexus Player 5.x Yes Reported by customer Google Nexus Player 6.0.1 Yes Please apply the latest Android updates *** Google -

Advisor Bulletin May 18/05/2020 Current Global Economic Outlook
Advisor Bulletin May 18/05/2020 Current Global Economic Outlook ➢ A global recession is possible. ➢ Stock markets have factored in a recession. ➢ Economies will likely improve from here. ➢ As countries start to re- open businesses, this should help to re start economies. We are moving past the crisis ➢ The Bloomberg U.S. Financial Conditions Index tracks the overall level of financial stress in the U.S. money, bond, and equity markets to help assess the availability and cost of credit. ➢ S&P 500 tends to follow the Index higher. ➢ Financial conditions in the U.S., as measured by Bloomberg, show that the brief risk of a liquidity- driven crisis has been almost totally recovered. Federal Reserve is ready to act. Powell pointed to uncertainty over how well future outbreaks of the virus can be controlled and how quickly a vaccine or therapy can be developed, and said policymakers needed to be ready to address “a range” of possible outcomes. “It will take some time to get back to where we were,” Powell said in a webcast interview with Adam Posen, the director of the Peterson Institute for International Economics. “There is a sense, growing sense I think, that the recovery may come more slowly than we would like. But it will come, and that may mean that it’s necessary for us to do more.” For a central banker who spent part of his career as a deficit hawk and has tried to avoid giving advice to elected officials, the remarks marked an extraordinary nod to the risks the U.S. -

United States International Trade Commission Washington, Dc
UNITED STATES INTERNATIONAL TRADE COMMISSION WASHINGTON, DC ) In the Matter of ) ) ) Investigation No. 337-TA-_____ CERTAIN CONSUMER ELECTRONICS ) AND DISPLAY DEVICES WITH ) GRAPHICS PROCESSING AND ) GRAPHICS PROCESSING UNITS ) THEREIN ) ) ) COMPLAINT UNDER SECTION 337 OF THE TARIFF ACT OF 1930, AS AMENDED Complainant: Proposed Respondents: NVIDIA Corporation Samsung Electronics Co., Ltd. 2701 San Tomas Expressway 1320-10 Seocho 2-dong Santa Clara, California 95050 Seocho-gu, Seoul 137-965 Telephone: (408) 486-2000 South Korea Telephone: +82-2-2255-0114 Counsel for Complainant: Samsung Electronics America, Inc. I. Neel Chatterjee 85 Challenger Road Orrick, Herrington & Sutcliffe LLP Ridgefield Park, New Jersey 07660 1000 Marsh Road Telephone: (201) 229-4000 Menlo Park, California 94025 Telephone: 650-614-7400 Samsung Telecommunications America, LLC Facsimile: 650-614-7401 1301 Lookout Drive Richardson, Texas 75802 Robert J. Benson Telephone: (972) 761-7000 Orrick, Herrington & Sutcliffe LLP 2050 Main Street, Suite 1100 Samsung Semiconductor, Inc. Irvine, California 92614 3655 North First Street Telephone: 949-567-6700 San Jose, California 95134 Facsimile: 949-567-6710 Telephone: (408) 544-4000 Jordan L. Coyle Qualcomm, Inc. Christopher J. Higgins 5775 Morehouse Drive Orrick, Herrington & Sutcliffe LLP San Diego, CA 92121 1152 15th Street, NW Telephone: (858) 587-1121 Washington, D.C 2005 Telephone: 202-339-8400 Facsimile: 202-339-8500 Ron E. Shulman Latham & Watkins LLP 140 Scott Drive Menlo Park, CA 94025 Telephone: (650) 328-4600 Facsimile: (650) 463-2600 Maximilian A. Grant Bert C. Reiser Latham & Watkins LLP 555 Eleventh Street, NW Suite 1000 Washington, DC 20004 Telephone: (202) 637-2200 Facsimile: (202) 637-2201 Julie M. -
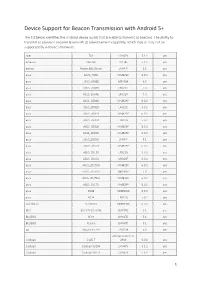
Device Support for Beacon Transmission with Android 5+
Device Support for Beacon Transmission with Android 5+ The list below identifies the Android device builds that are able to transmit as beacons. The ability to transmit as a beacon requires Bluetooth LE advertisement capability, which may or may not be supported by a device’s firmware. Acer T01 LMY47V 5.1.1 yes Amazon KFFOWI LVY48F 5.1.1 yes archos Archos 80d Xenon LMY47I 5.1 yes asus ASUS_T00N MMB29P 6.0.1 yes asus ASUS_X008D MRA58K 6.0 yes asus ASUS_Z008D LRX21V 5.0 yes asus ASUS_Z00AD LRX21V 5.0 yes asus ASUS_Z00AD MMB29P 6.0.1 yes asus ASUS_Z00ED LRX22G 5.0.2 yes asus ASUS_Z00ED MMB29P 6.0.1 yes asus ASUS_Z00LD LRX22G 5.0.2 yes asus ASUS_Z00LD MMB29P 6.0.1 yes asus ASUS_Z00UD MMB29P 6.0.1 yes asus ASUS_Z00VD LMY47I 5.1 yes asus ASUS_Z010D MMB29P 6.0.1 yes asus ASUS_Z011D LRX22G 5.0.2 yes asus ASUS_Z016D MXB48T 6.0.1 yes asus ASUS_Z017DA MMB29P 6.0.1 yes asus ASUS_Z017DA NRD90M 7.0 yes asus ASUS_Z017DB MMB29P 6.0.1 yes asus ASUS_Z017D MMB29P 6.0.1 yes asus P008 MMB29M 6.0.1 yes asus P024 LRX22G 5.0.2 yes blackberry STV100-3 MMB29M 6.0.1 yes BLU BLU STUDIO ONE LMY47D 5.1 yes BLUBOO XFire LMY47D 5.1 yes BLUBOO Xtouch LMY47D 5.1 yes bq Aquaris E5 HD LRX21M 5.0 yes ZBXCNCU5801712 Coolpad C106-7 291S 6.0.1 yes Coolpad Coolpad 3320A LMY47V 5.1.1 yes Coolpad Coolpad 3622A LMY47V 5.1.1 yes 1 CQ CQ-BOX 2.1.0-d158f31 5.1.1 yes CQ CQ-BOX 2.1.0-f9c6a47 5.1.1 yes DANY TECHNOLOGIES HK LTD Genius Talk T460 LMY47I 5.1 yes DOOGEE F5 LMY47D 5.1 yes DOOGEE X5 LMY47I 5.1 yes DOOGEE X5max MRA58K 6.0 yes elephone Elephone P7000 LRX21M 5.0 yes Elephone P8000 -

Locally Non-Rigid Registration for Mobile HDR Photography
Locally Non-rigid Registration for Mobile HDR Photography Orazio Gallo1 Alejandro Troccoli1 Jun Hu1;2 Kari Pulli1;3 Jan Kautz1 1NVIDIA 2Duke University 3Light (a) Our HDR result (b) Single homography (c) Bao et al. (d) Our result Figure 1: When capturing HDR stacks without a tripod, parallax and non-rigid scene changes are the main sources of artifacts. The picture in (a) is an HDR image generated by our algorithm from a stack of two pictures taken with a hand-held camera (notice that the volleyball is hand-held as well). A common and efficient method to register the images is to use a single homography, but parallax will still cause ghosting artifacts, see (b). One can then resort to non-rigid registration methods; here we use the fastest method of which we are aware, but artifacts due to erroneous registration are still visible (c). Our method is several times faster and, for scenes with parallax and small non-rigid displacements, produces better results (d). diance in each picture of the stack. In practice, however, any viable strategy to merge LDR images needs to cope Abstract with both camera motion and scene changes. Indeed there is a rich literature on the subject, with different methods of- Image registration for stack-based HDR photography is fering a different compromise between computational com- challenging. If not properly accounted for, camera motion plexity and reconstruction accuracy. and scene changes result in artifacts in the composite im- On one end of the spectrum there are light-weight meth- age. Unfortunately, existing methods to address this prob- ods, generally well-suited to run on mobile devices. -

Stanislaus County Library Offers Downloadable Audiobooks, Movies, Music, and Television Shows Through Hoopla Digital
Stanislaus County Library offers downloadable audiobooks, movies, music, and television shows through Hoopla Digital. You may stream the movies, music, television shows, eBooks, comics, or audiobooks to your computer or mobile device. You may also download audiobooks to your mobile device. Instructions for accessing Hoopla Digital To sign up, go to www.hoopladigital.com and click “Sign Up” in the upper right corner. Continue to the registration page. You will need your library card number and PIN (generally this is the last 4 digits of your phone number). • Select Stanislaus County Library for the library options. If it doesn’t display in the list of nearest libraries, select from the “Choose a library” drop down menu. • Enter your library card and PIN. The PIN required even though it states “optional.” • Enter your email address • Enter your email address a second time • Enter a password • Enter that password again and continue Once you are logged in you can browse the collection, make a selection, and borrow. Only 6 total checkouts are permitted per month per user. Once your account has been created, you can log back in by signing in with the email address and password created on account sign up. If you need to reset your password an email will be sent to the email address used to sign up. If you do not receive an email within a few minutes, please check your spam folder. Each Hoopla customer must have a unique email address. Only one library card is allowed per email address. Checkout Period • All audiobooks check out for a period of 21 days. -
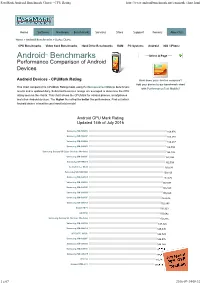
Passmark Android Benchmark Charts - CPU Rating
PassMark Android Benchmark Charts - CPU Rating http://www.androidbenchmark.net/cpumark_chart.html Home Software Hardware Benchmarks Services Store Support Forums About Us Home » Android Benchmarks » Device Charts CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone Android TM Benchmarks ----Select A Page ---- Performance Comparison of Android Devices Android Devices - CPUMark Rating How does your device compare? Add your device to our benchmark chart This chart compares the CPUMark Rating made using PerformanceTest Mobile benchmark with PerformanceTest Mobile ! results and is updated daily. Submitted baselines ratings are averaged to determine the CPU rating seen on the charts. This chart shows the CPUMark for various phones, smartphones and other Android devices. The higher the rating the better the performance. Find out which Android device is best for your hand held needs! Android CPU Mark Rating Updated 14th of July 2016 Samsung SM-N920V 166,976 Samsung SM-N920P 166,588 Samsung SM-G890A 166,237 Samsung SM-G928V 164,894 Samsung Galaxy S6 Edge (Various Models) 164,146 Samsung SM-G930F 162,994 Samsung SM-N920T 162,504 Lemobile Le X620 159,530 Samsung SM-N920W8 159,160 Samsung SM-G930T 157,472 Samsung SM-G930V 157,097 Samsung SM-G935P 156,823 Samsung SM-G930A 155,820 Samsung SM-G935F 153,636 Samsung SM-G935T 152,845 Xiaomi MI 5 150,923 LG H850 150,642 Samsung Galaxy S6 (Various Models) 150,316 Samsung SM-G935A 147,826 Samsung SM-G891A 145,095 HTC HTC_M10h 144,729 Samsung SM-G928F 144,576 Samsung -

NVIDIA Launches World's Most Advanced Tablet Built for Gamers
NVIDIA Launches World's Most Advanced Tablet Built for Gamers SHIELD Family Expands as World's Most Advanced Mobile Processor, 192-Core Tegra K1, Serves Up Unmatched Tablet Experience, Amazing Gaming SANTA CLARA, CA -- NVIDIA today launched the newest members of the NVIDIA® SHIELD™ family: the SHIELD tablet and the SHIELD wireless controller. Designed and built by NVIDIA, the SHIELD tablet is first and foremost a high-performance tablet that is packed with exceptional features. Powered by the world's most advanced mobile processor -- the NVIDIA Tegra® K1, with 192 GPU cores -- SHIELD tablet is supplemented by regular, over-the-air software upgrades that bring new capabilities and levels of performance. The SHIELD tablet is unique in that it was built specifically for gamers. It features a bright, 8-inch, full HD display, booming front-facing speakers with rich sound, and an optional cover that both protects the screen and can be used as a kick-stand to prop up the device at the best viewing angle. To transform it into a complete gaming machine, NVIDIA has built the SHIELD wireless controller, which provides the precision, low latency and ergonomics that serious gamers demand. The SHIELD tablet also offers optional LTE for gamers to take their online gaming anywhere. "If you're a gamer and you use a tablet, the NVIDIA SHIELD tablet was created specifically for you," said Jen-Hsun Huang, NVIDIA's co-founder and chief executive officer. "It delivers exceptional tablet performance and unique gaming capabilities to keep even the most avid gamers deeply immersed, anywhere they play." As with the original member of the SHIELD family, the SHIELD portable, the SHIELD tablet is the portal to compelling content that gamers will love, including the best SHIELD-supported Android games, as well as the ability to wirelessly stream users' PC gaming libraries. -
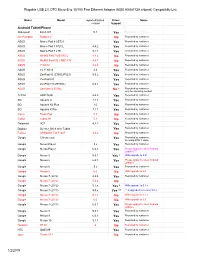
(ASIX AX88772A Chipset) Compatiblity List 1/2/2019
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A chipset) Compatiblity List Maker Model reported/tested Driver Notes version Support Android Tablet/Phone Alldaymall EU-A10T 5.1 Yes Reported by customer Am Pumpkin Radium 2 No Reported by customer ASUS Memo Pad 8 AST21 Yes Reported by customer ASUS Memo Pad 7 572CL 4.4.2 Yes Reported by customer ASUS Memo Pad 7 LTE 5.1.1 Yes Reported by customer ASUS MeMO Pad 7 ME176C2 4.4.2 No Reported by customer ASUS MeMO Pad HD 7 ME173X 4.4.1 No Reported by customer ASUS 7" K013 4.4.2 No Reported by customer ASUS 10.1" K010 4.4 Yes Reported by customer ASUS ZenPad 10 (Z300C/P023) 5.0.2 Yes Reported by customer ASUS ZenPad 8.0 Yes Reported by customer ASUS ZenPad 7.0(Z370KL) 6.0.1 Yes Reported by customer ASUS ZenFone 2 551ML No * Reported by customer, only for browsing worked ΛzICHI ADP-722A 4.4.2 Yes Reported by customer BQ Aquaris U 7.1.1 Yes Reported by customer BQ Aquaris X5 Plus 7.0 Yes Reported by customer BQ Aquaris X Pro 7.1.1 Yes Reported by customer Covia Fleas Pop 5.1 No Reported by customer Cubot Cubot H1 5.1 No Reported by customer Datawind 3G7 4.2.2 Yes Reported by customer Digital2 D2-912_BK 9-Inch Tablet Yes Reported by customer Fujitsu ARROWS Tab F-02F 4.4.2 No Reported by customer Google Chromecast Yes Reported by customer, by using OTG Y cable Google Nexus Player 5.x Yes Reported by customer Google Nexus Player 6.0.1 Yes Please apply the latest Android updates *** Google Nexus 5 5.0.1 Yes * With upgrade to 5.01 Google Nexus 5 6.0.1 Yes Please apply the latest -
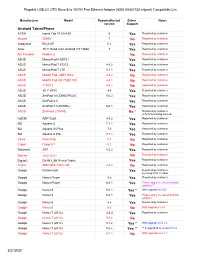
AX88772 Compatibility List USB2-OTGE100
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A chipset) Compatiblity List Manufacturer Model Reported/tested Driver Notes version Support Android Tablet/Phone ACER Iconia Tab 10 A3-A30 6 Yes Reported by customer Alcatel 5009A 7 No Reported by customer Alldaymall EU-A10T 5.1 Yes Reported by customer Anoc 10.1" Quad Core Android 7.0 Tablet 7 Yes Reported by customer Am Pumpkin Radium 2 No Reported by customer ASUS Memo Pad 8 AST21 Yes Reported by customer ASUS Memo Pad 7 572CL 4.4.2 Yes Reported by customer ASUS Memo Pad 7 LTE 5.1.1 Yes Reported by customer ASUS MeMO Pad 7 ME176C2 4.4.2 No Reported by customer ASUS MeMO Pad HD 7 ME173X 4.4.1 No Reported by customer ASUS 7" K013 4.4.2 No Reported by customer ASUS 10.1" K010 4.4 Yes Reported by customer ASUS ZenPad 10 (Z300C/P023) 5.0.2 Yes Reported by customer ASUS ZenPad 8.0 Yes Reported by customer ASUS ZenPad 7.0(Z370KL) 6.0.1 Yes Reported by customer ASUS ZenFone 2 551ML No * Reported by customer, only for browsing worked ΛzICHI ADP-722A 4.4.2 Yes Reported by customer BQ Aquaris U 7.1.1 Yes Reported by customer BQ Aquaris X5 Plus 7.0 Yes Reported by customer BQ Aquaris X Pro 7.1.1 Yes Reported by customer Covia Fleas Pop 5.1 No Reported by customer Cubot Cubot H1 5.1 No Reported by customer Datawind 3G7 4.2.2 Yes Reported by customer Denver TAQ-10283 No Reported by customer Digital2 D2-912_BK 9-Inch Tablet Yes Reported by customer Fujitsu ARROWS Tab F-02F 4.4.2 No Reported by customer Google Chromecast Yes Reported by customer, by using OTG Y cable Google -

What's New in Mobile? Shield Tablet Update for Ieee Cesoc
WHAT’S NEW IN MOBILE? SHIELD TABLET UPDATE FOR IEEE CESOC Chris Pedersen December, 2014 MOBILE READY FOR DIFFERENTIATION VAN SPORTS CAR WORK STATION LAPTOP TRUCK GAMING DIFFERENTIATION TWO WAYS Product Platform ULTIMATE ANDROID GAMING “NVIDIA's Shield Just Became The Best Handheld Gaming Console Available” — Forbes “Even if you don't take advantage of its gaming prowess, the Nvidia Shield Games Tablet is one of the most versatile -- and affordable -- high-performance 8- inch Android slates you can buy” — CNET SHIELD PORTABLE SHIELD TABLET SHIELD CONTROLLER ULTIMATE ANDROID GAMER EXPERIENCES PLAY GAMES ANYWHERE TURN TABLET INTO CONSOLE PLAY PC GAMES ANYWHERE STREAM TO TWITCH STREAM PC GAMES FROM CLOUD PAINT IN 3D GAMESTREAM FAST AP – TK1 iPad mini 3 Tab S 8.4 SHIELD Tablet 5 4 3 2 1 0 3DMarkUnlimited GLB 2.7 TREX Basemark ES 3.0 Basemark X 1.1 GFXBench 3.0 Total (Rush) (High) Manhattan Tab S – Exynos 5 Octa; iPad mini 3 – A7 64bit ADVANCED GPU BRINGS AMAZING VISUALS TO MOBILE TEGRA K1 GEFORCE Kepler Graphics TITAN OpenGL ES 3.1 AEP OpenGL 4.4 DX12 Tessellation CUDA 6.0 Power <2W 250W DESIGNED FOR ANDROID AND STREAMED PC GAMES GEFORCE GAMING FROM THE CLOUD 12x PERFORMANCE 2x FASTER START TIME 2x FRAME RATE (lower is better) 60 fps 52 2,448 secs GFlops 30 fps 23 secs 192 GFlops PlayStation GRID PlayStation GRID PlayStation GRID Now Now Now SHIELD TABLET SOFTWARE UPGRADE ANDROID 5.0 LOLLIPOP DABBLER 2.0 GRID SHIELD HUB 2.00 OTA 2.0 OTA 1.2.1 1.50 1.00 0.50 0.00 Available App Memory PC Mark (Memory) Y-CABLE SUPPORT MEMORY & PERF OPTIMIZATIONS 4K VIDEO CONSOLE MODE SHIELD VIDEO DEMO Click to Play COMPUTATIONAL PHOTOGRAPHY YOU DON'T TAKE A PHOTOGRAPH, YOU MAKE IT. -
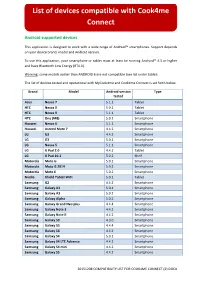
List of Devices Compatible with Cook4me Connect
List of devices compatible with Cook4me Connect Android supported devices This appliCation is designed to work with a wide range of Android™ smartphones. Support depends on your deviCe brand, model and Android version. To use this appliCation, your smartphone or tablet must at least be running Android™ 4.3 or higher and have Bluetooth Low Energy (BT4.0). Warning: some models earlier than ANDROID 6 are not compatible (see list under table): The list of deviCes tested and operational with MyCook4me and Cook4me ConneCt is set forth below. Brand Model Android version Type tested Asus Nexus 7 5.1.1 Tablet HTC Nexus 9 5.0.1 Tablet HTC Nexus 9 5.1.1 Tablet HTC One (M8) 5.0.1 Smartphone Huawei Nexus 6 5.1.1 Smartphone Huawei Ascend Mate 7 4.4.2 Smartphone LG G3 4.4.2 Smartphone LG G3 5.0.1 Smartphone LG Nexus 5 5.1.1 Smartphone LG G Pad 7.0 4.4.2 Tablet LG G Pad 10.1 5.0.2 Shelf Motorola Moto G 5.0.2 Smartphone Motorola Moto G 2014 5.0.2 Smartphone Motorola Moto E 5.0.2 Smartphone Nvidia Shield Tablet WiFi 5.0.1 Tablet Samsung G2 4.4.2 Smartphone Samsung Galaxy A3 5.0.1 Smartphone Samsung Galaxy A3 5.0.2 Smartphone Samsung Galaxy Alpha 5.0.2 Smartphone Samsung Galaxy Grand Neo plus 4.4.4 Smartphone Samsung Galaxy Note 3 4.4.2 Smartphone Samsung Galaxy Note II 4.4.2 Smartphone Samsung Galaxy S3 4.3.0 Smartphone Samsung Galaxy S3 4.4.4 Smartphone Samsung Galaxy S4 4.4.2 Smartphone Samsung Galaxy S4 5.0.1 Smartphone Samsung Galaxy S4 LTE Advance 4.4.2 Smartphone Samsung Galaxy S4 mini 4.4.2 Smartphone Samsung Galaxy S5 4.4.2 Smartphone 20151208