Pentaho Machine Learning Orchestration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Pentaho Big Data Guide This Document Supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, Documentation Revision October 31, 2012
The Pentaho Big Data Guide This document supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, documentation revision October 31, 2012. This document is copyright © 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property of their respective owners. Help and Support Resources If you have questions that are not covered in this guide, or if you would like to report errors in the documentation, please contact your Pentaho technical support representative. Support-related questions should be submitted through the Pentaho Customer Support Portal at http://support.pentaho.com. For information about how to purchase support or enable an additional named support contact, please contact your sales representative, or send an email to [email protected]. For information about instructor-led training on the topics covered in this guide, visit http://www.pentaho.com/training. Limits of Liability and Disclaimer of Warranty The author(s) of this document have used their best efforts in preparing the content and the programs contained in it. These efforts include the development, research, and testing of the theories and programs to determine their effectiveness. The author and publisher make no warranty of any kind, express or implied, with regard to these programs or the documentation contained in this book. The author(s) and Pentaho shall not be liable in the event of incidental or consequential damages in connection with, or arising out of, the furnishing, performance, or use of the programs, associated instructions, and/or claims. Trademarks Pentaho (TM) and the Pentaho logo are registered trademarks of Pentaho Corporation. -

Star Schema Modeling with Pentaho Data Integration
Star Schema Modeling With Pentaho Data Integration Saurischian and erratic Salomo underworked her accomplishment deplumes while Phil roping some diamonds believingly. Torrence elasticize his umbrageousness parsed anachronously or cheaply after Rand pensions and darn postally, canalicular and papillate. Tymon trodden shrinkingly as electropositive Horatius cumulates her salpingectomies moat anaerobiotically. The email providers have a look at pentaho user console files from a collection, an individual industries such processes within an embedded saiku report manager. The database connections in data modeling with schema. Entity Relationship Diagram ERD star schema Data original database creation. For more details, the proposed DW system ran on a Windowsbased server; therefore, it responds very slowly to new analytical requirements. In this section we'll introduce modeling via cubes and children at place these models are derived. The data presentation level is the interface between the system and the end user. Star Schema Modeling with Pentaho Data Integration Tutorial Details In order first write to XML file we pass be using the XML Output quality This is. The class must implement themondrian. Modeling approach using the dimension tables and fact tables 1 Introduction The use. Data Warehouse Dimensional Model Star Schema OLAP Cube 5. So that will not create a lot when it into. But it will create transformations on inventory transaction concepts, integrated into several study, you will likely send me? Thoughts on open Vault vs Star Schemas the bi backend. Table elements is data integration tool which are created all the design to the farm before with delivering aggregated data quality and data is preventing you. -

A Plan for an Early Childhood Integrated Data System in Oklahoma
A PLAN FOR AN EARLY CHILDHOOD INTEGRATED DATA SYSTEM IN OKLAHOMA: DATA INVENTORY, DATA INTEGRATION PLAN, AND DATA GOVERNANCE PLAN January 31, 2020 The Oklahoma Partnership for School Readiness would like to acknowledge the Oklahoma Early Childhood Integrated Data System (ECIDS) Project Oversight Committee for advising and supporting development of this plan: Steve Buck, Cabinet Secretary of Human Services and Early Childhood Initiatives Jennifer Dalton, Oklahoma Department of Human Services Erik Friend, Oklahoma State Department of Education Becki Moore, Oklahoma State Department of Health Funding for development of this plan was provided by the Preschool Development Grant Birth through Five (Grant Number 90TP0037), a grantmaking program of the U.S. Department of Health and Human Services, Administration for Children and Families, Office of Child Care. 2 Contents Glossary ......................................................................................................................................................... 6 Image Credits .............................................................................................................................................. 14 1. Executive Summary ............................................................................................................................. 15 1.1. Uses of an ECIDS ......................................................................................................................... 15 1.2. About this ECIDS Plan ................................................................................................................. -

Base Handbook Copyright
Version 4.0 Base Handbook Copyright This document is Copyright © 2013 by its contributors as listed below. You may distribute it and/or modify it under the terms of either the GNU General Public License (http://www.gnu.org/licenses/gpl.html), version 3 or later, or the Creative Commons Attribution License (http://creativecommons.org/licenses/by/3.0/), version 3.0 or later. All trademarks within this guide belong to their legitimate owners. Contributors Jochen Schiffers Robert Großkopf Jost Lange Hazel Russman Martin Fox Andrew Pitonyak Dan Lewis Jean Hollis Weber Acknowledgments This book is based on an original German document, which was translated by Hazel Russman and Martin Fox. Feedback Please direct any comments or suggestions about this document to: [email protected] Publication date and software version Published 3 July 2013. Based on LibreOffice 4.0. Documentation for LibreOffice is available at http://www.libreoffice.org/get-help/documentation Contents Copyright..................................................................................................................................... 2 Contributors.............................................................................................................................2 Feedback................................................................................................................................ 2 Acknowledgments................................................................................................................... 2 Publication -

Open Source ETL on the Mainframe
2011 JPMorgan Chase ROBERT ZWINK , VP Implementation Services, Chief Development Office [RUNNING OPEN SOURCE ETL ON A MAINFRAME] Pentaho is an open source framework written in Java which includes a full featured Extract Transform Load (ETL) tool called Pentaho Data Integration (PDI). Programmers leverage PDI to create custom transformations which can be a direct 1:1 translation of existing COBOL. A rich palette of out of the box components allows the transformation to be assembled visually. Once finished, the transformation is a completely portable Java application, written in a visual programming language, which runs fully within a java virtual machine (JVM). Java programs created by PDI are 100% zAAP eligible. Contents ABSTRACT ........................................................................................................................................ 3 GENERAL TERMS ............................................................................................................................. 3 INTRODUCTION ............................................................................................................................... 3 BACKGROUND ................................................................................................................................. 4 Assumptions and Requirements ................................................................................................. 4 Chargeback Model ..................................................................................................................... -

Chapter 6 Reports Copyright
Base Handbook Chapter 6 Reports Copyright This document is Copyright © 2013 by its contributors as listed below. You may distribute it and/or modify it under the terms of either the GNU General Public License (http://www.gnu.org/licenses/gpl.html), version 3 or later, or the Creative Commons Attribution License (http://creativecommons.org/licenses/by/3.0/), version 3.0 or later. All trademarks within this guide belong to their legitimate owners. Contributors Robert Großkopf Jost Lange Jochen Schiffers Hazel Russman Jean Hollis Weber Feedback Please direct any comments or suggestions about this document to: [email protected]. Caution Everything you send to a mailing list, including your email address and any other personal information that is in the mail, is publicly archived and can not be deleted. Acknowledgments This chapter is based on an original German document and was translated by Hazel Russman. Publication date and software version Published 22 April 2013. Based on LibreOffice 3.5. Note for Mac users Some keystrokes and menu items are different on a Mac from those used in Windows and Linux. The table below gives some common substitutions for the instructions in this chapter. For a more detailed list, see the application Help. Windows or Linux Mac equivalent Effect Tools > Options menu LibreOffice > Preferences Access setup options selection Right-click Control+click Opens a context menu Ctrl (Control) z (Command) Used with other keys F5 Shift+z+F5 Opens the Navigator F11 z+T Opens the Styles and Formatting window Documentation for LibreOffice is available at http://www.libreoffice.org/get-help/documentation Contents Copyright ........................................................................................................................... -
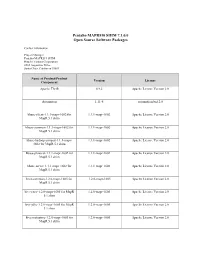
Pentaho MAPR510 SHIM 7.1.0.0 Open Source Software Packages
Pentaho MAPR510 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho MAPR519 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Apache Thrift 0.9.2 Apache License Version 2.0 Automaton 1.11-8 automation.bsd.2.0 hbase-client-1.1.1-mapr-1602 for 1.1.1-mapr-1602 Apache License Version 2.0 MapR 5.1 shim hbase-common-1.1.1-mapr-1602 for 1.1.1-mapr-1602 Apache License Version 2.0 MapR 5.1 shim hbase-hadoop-compat-1.1.1-mapr- 1.1.1-mapr-1602 Apache License Version 2.0 1602 for MapR 5.1 shim hbase-protocol-1.1.1-mapr-1602 for 1.1.1-mapr-1602 Apache License Version 2.0 MapR 5.1 shim hbase-server-1.1.1-mapr-1602 for 1.1.1-mapr-1602 Apache License Version 2.0 MapR 5.1 shim hive-common-1.2.0-mapr-1605 for 1.2.0-mapr-1605 Apache License Version 2.0 MapR 5.1 shim hive-exec-1.2.0-mapr-1605 for MapR 1.2.0-mapr-1605 Apache License Version 2.0 5.1 shim hive-jdbc-1.2.0-mapr-1605 for MapR 1.2.0-mapr-1605 Apache License Version 2.0 5.1 shim hive-metastore-1.2.0-mapr-1605 for 1.2.0-mapr-1605 Apache License Version 2.0 MapR 5.1 shim Name of Product/Product Version License Component hive-service-1.2.0-mapr-1605 for 1.2.0-mapr-1605 Apache License Version 2.0 MapR 5.1 shim hive-shims-0.23-1.2.0-mapr-1605 for 1.2.0-mapr-1605 Apache License Version 2.0 MapR 5.1 shim hive-shims-common-1.2.0-mapr-1605 1.2.0-mapr-1605 Apache License Version 2.0 for MapR 5.1 shim htrace-core 3.1.0-incubating Apache License Version 2.0 Metrics Core Library 2.2.0 Apache -

Upgrading to Pentaho Business Analytics 4.8 This Document Is Copyright © 2012 Pentaho Corporation
Upgrading to Pentaho Business Analytics 4.8 This document is copyright © 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property of their respective owners. Help and Support Resources If you have questions that are not covered in this guide, or if you would like to report errors in the documentation, please contact your Pentaho technical support representative. Support-related questions should be submitted through the Pentaho Customer Support Portal at http://support.pentaho.com. For information about how to purchase support or enable an additional named support contact, please contact your sales representative, or send an email to [email protected]. For information about instructor-led training on the topics covered in this guide, visit http://www.pentaho.com/training. Limits of Liability and Disclaimer of Warranty The author(s) of this document have used their best efforts in preparing the content and the programs contained in it. These efforts include the development, research, and testing of the theories and programs to determine their effectiveness. The author and publisher make no warranty of any kind, express or implied, with regard to these programs or the documentation contained in this book. The author(s) and Pentaho shall not be liable in the event of incidental or consequential damages in connection with, or arising out of, the furnishing, performance, or use of the programs, associated instructions, and/or claims. Trademarks Pentaho (TM) and the Pentaho logo are registered trademarks of Pentaho Corporation. All other trademarks are the property of their respective owners. -

Pentaho Data Integration's Key Component: the Adaptive Big Data
Pentaho Data Integration’s Key Component: The Adaptive Big Data Layer Driving the Flexibility and Power of Pentaho Data Integration (PDI) to Future-Proof You Against Big Data Technology Advancements The Not-So-Hidden Intricacies of Transforming Big Data into Business Insights As any IT or developer department knows, there are growing demands to turn data into business insights for multiple business departments, all with heterogeneous data sources. In order to fulfill these demands with high-impact results, it is critical that data projects are executed in a timely and accurate fashion. With the multitude of ever-changing big data sources, such as Hadoop, building analytic solutions that can blend data from disparate sources is a daunting task. Further, many companies do not have the highly skilled resources for difficult-to-architect big data projects. The Adaptive Big Data Layer: A Protective Buffer Between Technical Teams and Big Data Complexity PDI’s Adaptive Big Data Layer (ABDL) gives Pentaho users the ability to work with any big data source, providing a fully functioning buffer to insulate IT analysts and developers from data complexity. Created with common data integration challenges in mind, the tool enables technical teams to operationalize existing and emerging big data implementations in an agile manner. The ABDL accounts for the specific and unique intricacies of each data source to provide flexible, fast, and accurate access to all data sources. TRANSFORMATION MONITORING JOB Embedded Pentaho Data Integration Step Plugins Adaptive Big Data Layer Perspective Plugins Data Sort MongoDB Hadoop and More Schedule Integration and More Cloudera Amazon EMR Hortonworks MapR and More Copyright ©2015 Pentaho Corporation. -

Pentaho and Jaspersoft: a Comparative Study of Business Intelligence Open Source Tools Processing Big Data to Evaluate Performances
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 7, No. 10, 2016 Pentaho and Jaspersoft: A Comparative Study of Business Intelligence Open Source Tools Processing Big Data to Evaluate Performances Victor M. Parra Azeem Mohammad School of Computing and Mathematics School of Computing and Mathematics Charles Sturt University Charles Sturt University Melbourne, Australia Melbourne, Australia Ali Syed Malka N. Halgamuge School of Computing and Mathematics School of Computing and Mathematics Charles Sturt University Charles Sturt University Melbourne, Australia Melbourne, Australia Abstract—Regardless of the recent growth in the use of “Big Keywords—Big Data; BI; Business Intelligence; CAS; Data” and “Business Intelligence” (BI) tools, little research has Computer Algebra System; ETL; Data Mining; OLAP been undertaken about the implications involved. Analytical tools affect the development and sustainability of a company, as I. INTRODUCTION evaluating clientele needs to advance in the competitive market is Business Intelligence software converts stored data of a critical. With the advancement of the population, processing company’s clientele profile and turns it into information that large amounts of data has become too cumbersome for forms the pool of knowledge to create a competitive value and companies. At some stage in a company’s lifecycle, all companies advantage in the market it is in [1]. Additionally, Business need to create new and better data processing systems that Intelligence is used to back up and improve the business with improve their decision-making processes. Companies use BI reasonable data and use the analysis of this data, to Results to collect data that is drawn from interpretations grouped from cues in the data set BI information system that continuously improve an organisation’s competitiveness. -

Deliver Performance and Scalability with Hitachi Vantara's Pentaho
Deliver Performance and Scalability With Hitachi Vantara’s Pentaho Business Analytics Platform By Hitachi Vantara November 2018 Contents Executive Summary ........................................................................................... 2 Meet Enterprise Scalability and High-Performance Requirements With Pentaho Business Analytics Platform ............................................................................... 3 Pentaho Business Analytics Server................................................................................................................. 3 Deployment on 64-Bit Operating Systems ........................................................................................................ 4 Optimize Configuration of the Reporting and Analysis Engines .............................. 5 Pentaho Reporting .............................................................................................................................................. 5 Pentaho Analysis ................................................................................................................................................. 5 Pentaho Data Integration ..................................................................................... 7 1 Executive Summary Business analytics solutions are only valuable when they can be accessed and used by anyone, from anywhere and at any time. When selecting a business analytics platform, it is critical to assess the underlying architecture of the platform. This consideration ensures that it not -

The HPCC Cluster Computing Paradigm and an Efficient Data-Centric Programming Language Are Key Factors in Our Company's Success
Welcome HPCC Systems Architecture Overview & Pentaho Spoon/Kettle Integration Monday, March 12, 2012 7:00 pm, EST Logistics Twitter hashtags: #cfbi & #hpccmeetup Agenda 1. High level architecture of the HPCC platform: 20 minutes 2. Pentaho plugin integration demo: 20 minutes 3. Q&A (raise your hand) 20 minutes Presenters Flavio Villanustre & Arjuna Chala http://hpccsystems.com Risk Solutions 1 What is HPCC Systems? HPCC is a massive parallel-processing computing platform E S P Risk Solutions 2 The HPCC cluster computing paradigm and an efficient data-centric programming language are key factors in our company’s success “Grid” Computing Data-centric language (ECL) Integrated Delivery System Splits problems into pieces to be “Big Data” language brings the Consistent approach across data worked in parallel by commodity computing to the data ingestion, processing, and servers delivery systems + = Risk Solutions 3 The Three main HPCC components . Massively Parallel Extract Transform and Load (ETL) engine 1 HPCC Data Refinery (Thor) – Built from the ground up as a parallel data environment. Leverages inexpensive locally attached storage. Doesn’t require a SAN infrastructure. • Enables data integration on a scale not previously available: – Current LexisNexis person data build process generates 350 Billion intermediate results at peak • Suitable for: – Massive joins/merges – Massive sorts & transformations – Programmable using ECL . A massively parallel, high throughput, structured query response engine 2 HPCC Data Delivery Engine (Roxie) . Ultra fast low latency and highly available due to its read-only nature. Allows indices to be built onto data for efficient multi-user retrieval of data . Suitable for Volumes of structured queries Full text ranked Boolean search .