Recode Software V0.9 a User Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Schematic Entry
Schematic Entry Copyrights Software, documentation and related materials: Copyright © 2002 Altium Limited This software product is copyrighted and all rights are reserved. The distribution and sale of this product are intended for the use of the original purchaser only per the terms of the License Agreement. This document may not, in whole or part, be copied, photocopied, reproduced, translated, reduced or transferred to any electronic medium or machine-readable form without prior consent in writing from Altium Limited. U.S. Government use, duplication or disclosure is subject to RESTRICTED RIGHTS under applicable government regulations pertaining to trade secret, commercial computer software developed at private expense, including FAR 227-14 subparagraph (g)(3)(i), Alternative III and DFAR 252.227-7013 subparagraph (c)(1)(ii). P-CAD is a registered trademark and P-CAD Schematic, P-CAD Relay, P-CAD PCB, P-CAD ProRoute, P-CAD QuickRoute, P-CAD InterRoute, P-CAD InterRoute Gold, P-CAD Library Manager, P-CAD Library Executive, P-CAD Document Toolbox, P-CAD InterPlace, P-CAD Parametric Constraint Solver, P-CAD Signal Integrity, P-CAD Shape-Based Autorouter, P-CAD DesignFlow, P-CAD ViewCenter, Master Designer and Associate Designer are trademarks of Altium Limited. Other brand names are trademarks of their respective companies. Altium Limited www.altium.com Table of Contents chapter 1 Introducing P-CAD Schematic P-CAD Schematic Features ................................................................................................1 About -

Lossless Compression of Internal Files in Parallel Reservoir Simulation
Lossless Compression of Internal Files in Parallel Reservoir Simulation Suha Kayum Marcin Rogowski Florian Mannuss 9/26/2019 Outline • I/O Challenges in Reservoir Simulation • Evaluation of Compression Algorithms on Reservoir Simulation Data • Real-world application - Constraints - Algorithm - Results • Conclusions 2 Challenge Reservoir simulation 1 3 Reservoir Simulation • Largest field in the world are represented as 50 million – 1 billion grid block models • Each runs takes hours on 500-5000 cores • Calibrating the model requires 100s of runs and sophisticated methods • “History matched” model is only a beginning 4 Files in Reservoir Simulation • Internal Files • Input / Output Files - Interact with pre- & post-processing tools Date Restart/Checkpoint Files 5 Reservoir Simulation in Saudi Aramco • 100’000+ simulations annually • The largest simulation of 10 billion cells • Currently multiple machines in TOP500 • Petabytes of storage required 600x • Resources are Finite • File Compression is one solution 50x 6 Compression algorithm evaluation 2 7 Compression ratio Tested a number of algorithms on a GRID restart file for two models 4 - Model A – 77.3 million active grid blocks 3.5 - Model K – 8.7 million active grid blocks 3 - 15.6 GB and 7.2 GB respectively 2.5 2 Compression ratio is between 1.5 1 compression ratio compression - From 2.27 for snappy (Model A) 0.5 0 - Up to 3.5 for bzip2 -9 (Model K) Model A Model K lz4 snappy gzip -1 gzip -9 bzip2 -1 bzip2 -9 8 Compression speed • LZ4 and Snappy significantly outperformed other algorithms -

Arrow: Integration to 'Apache' 'Arrow'
Package ‘arrow’ September 5, 2021 Title Integration to 'Apache' 'Arrow' Version 5.0.0.2 Description 'Apache' 'Arrow' <https://arrow.apache.org/> is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. This package provides an interface to the 'Arrow C++' library. Depends R (>= 3.3) License Apache License (>= 2.0) URL https://github.com/apache/arrow/, https://arrow.apache.org/docs/r/ BugReports https://issues.apache.org/jira/projects/ARROW/issues Encoding UTF-8 Language en-US SystemRequirements C++11; for AWS S3 support on Linux, libcurl and openssl (optional) Biarch true Imports assertthat, bit64 (>= 0.9-7), methods, purrr, R6, rlang, stats, tidyselect, utils, vctrs RoxygenNote 7.1.1.9001 VignetteBuilder knitr Suggests decor, distro, dplyr, hms, knitr, lubridate, pkgload, reticulate, rmarkdown, stringi, stringr, testthat, tibble, withr Collate 'arrowExports.R' 'enums.R' 'arrow-package.R' 'type.R' 'array-data.R' 'arrow-datum.R' 'array.R' 'arrow-tabular.R' 'buffer.R' 'chunked-array.R' 'io.R' 'compression.R' 'scalar.R' 'compute.R' 'config.R' 'csv.R' 'dataset.R' 'dataset-factory.R' 'dataset-format.R' 'dataset-partition.R' 'dataset-scan.R' 'dataset-write.R' 'deprecated.R' 'dictionary.R' 'dplyr-arrange.R' 'dplyr-collect.R' 'dplyr-eval.R' 'dplyr-filter.R' 'expression.R' 'dplyr-functions.R' 1 2 R topics documented: 'dplyr-group-by.R' 'dplyr-mutate.R' 'dplyr-select.R' 'dplyr-summarize.R' -

Summer 2010 PPAXAXCENTURIONCENTURION Boston Police Patrolmen’S Association, Inc
Boston Police Patrolmen’s Association, Inc. PRST. STD. 9-11 Shetland Street U.S. POSTAGE Flagwoman in Boston, Massachusetts 02119 PAID PERMIT NO. 2226 South Boston at WORCESTER, MA $53.00 per hour! Where’s the Globe photographer? See the back and forth with the Globe’s Scot Lehigh. See pages A10 & A11 Nation’s First Police Department • Established 1854 Volume 40, Number 3 • Summer 2010 PPAXAXCENTURIONCENTURION Boston Police Patrolmen’s Association, Inc. Boston Emergency Medical Technicians NATIONAL ASSOCIATION OF POLICE ORGANIZATIONS A DISGRACE!!! Police Picket Patrick City gives Woodman family, Thousands attend two-day picket, attorney Gov. Patrick jeered, AZ Gov. Brewer cheered By Jim Carnell, Pax Editor $3 million housands of Massachusetts municipal settlement Tpolice officers showed up to demon- strate at the National Governor’s Associa- By Jim Carnell, Pax Editor tion meeting held recently in Boston, hosted n yet another discouraging, insulting by our own little Lord Fauntleroy, Gover- slap at working police officers, the city I nor Deval Patrick. recently gave the family of David On Friday, July 9th, about three thousand Woodman and cop-hating Attorney officers appeared outside of Fenway Park Howard Friedman $3 million dollars, to greet the Governors and their staffs at an despite the fact that a formal lawsuit had event featuring our diminutive Governor. not even been filed. Governor Patrick has focused his (and his Woodman died at the Beth Israel allies in the bought-and-sold local media) Hospital eleven days after his initial en- attention upon police officers in particular, counter with police following the Celtics’ attacking police officer’s pay, benefits and 2008 victory. -

Parquet Data Format Performance
Parquet data format performance Jim Pivarski Princeton University { DIANA-HEP February 21, 2018 1 / 22 What is Parquet? 1974 HBOOK tabular rowwise FORTRAN first ntuples in HEP 1983 ZEBRA hierarchical rowwise FORTRAN event records in HEP 1989 PAW CWN tabular columnar FORTRAN faster ntuples in HEP 1995 ROOT hierarchical columnar C++ object persistence in HEP 2001 ProtoBuf hierarchical rowwise many Google's RPC protocol 2002 MonetDB tabular columnar database “first” columnar database 2005 C-Store tabular columnar database also early, became HP's Vertica 2007 Thrift hierarchical rowwise many Facebook's RPC protocol 2009 Avro hierarchical rowwise many Hadoop's object permanance and interchange format 2010 Dremel hierarchical columnar C++, Java Google's nested-object database (closed source), became BigQuery 2013 Parquet hierarchical columnar many open source object persistence, based on Google's Dremel paper 2016 Arrow hierarchical columnar many shared-memory object exchange 2 / 22 What is Parquet? 1974 HBOOK tabular rowwise FORTRAN first ntuples in HEP 1983 ZEBRA hierarchical rowwise FORTRAN event records in HEP 1989 PAW CWN tabular columnar FORTRAN faster ntuples in HEP 1995 ROOT hierarchical columnar C++ object persistence in HEP 2001 ProtoBuf hierarchical rowwise many Google's RPC protocol 2002 MonetDB tabular columnar database “first” columnar database 2005 C-Store tabular columnar database also early, became HP's Vertica 2007 Thrift hierarchical rowwise many Facebook's RPC protocol 2009 Avro hierarchical rowwise many Hadoop's object permanance and interchange format 2010 Dremel hierarchical columnar C++, Java Google's nested-object database (closed source), became BigQuery 2013 Parquet hierarchical columnar many open source object persistence, based on Google's Dremel paper 2016 Arrow hierarchical columnar many shared-memory object exchange 2 / 22 Developed independently to do the same thing Google Dremel authors claimed to be unaware of any precedents, so this is an example of convergent evolution. -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Pdfnews 10/04, Page 2 –
Precursor PDF News 10:4 Adobe InDesign to Challenge Quark At last week’s Seybold conference in Boston, Adobe Systems finally took the wraps off its upcoming “Quark-killer” called InDesign. The new-from-the-ground-up page layout program is set for a summer debut. InDesign will be able to open QuarkXPress 3 and 4 documents and will even offer a set of Quark keyboard shortcuts. The beefy new program will also offer native Photoshop, Illustrator and PDF file format support. The PDF capabilities in particular will change workflows to PostScript 3 output devices. Pricing is expected to be $699 U.S. Find out more on- line at: http://www.adobe.com/prodindex/indesign/main.html PageMaker 6.5 Plus: Focus on Business With the appearance on InDesign, Adobe PageMaker Plus has been targeted toward business customers with increased integration with Microsoft Office products, more templates and included Photoshop 5.0 Limited Edition in the box. Upgrade prices are $99 U.S. PageMaker Plus is expected to ship by the end of March. Find out more on-line at: http://www.adobe.com/prodindex/pagemaker/main.html Adobe Acrobat 4.0 Also at Seybold, Adobe announced that Acrobat 4.0 will ship in late March for $249 ($99 for upgrades) The new version offers Press Optimization for PDF file creation and provides the ability to view a document with the fonts it was created with or fonts native to the viewing machine. Greater post file creation editing capabilities are also built-in And, of course, the new version is 100% hooked in to PostScript 3. -

Bicriteria Data Compression∗
Bicriteria data compression∗ Andrea Farruggia, Paolo Ferragina, Antonio Frangioni, and Rossano Venturini Dipartimento di Informatica, Universit`adi Pisa, Italy ffarruggi, ferragina, frangio, [email protected] Abstract lem, named \compress once, decompress many times", In this paper we address the problem of trading that can be cast into two main families: the com- optimally, and in a principled way, the compressed pressors based on the Burrows-Wheeler Transform [6], size/decompression time of LZ77 parsings by introduc- and the ones based on the Lempel-Ziv parsing scheme ing what we call the Bicriteria LZ77-Parsing problem. [35, 36]. Compressors are known in both families that The goal is to determine an LZ77 parsing which require time linear in the input size, both for compress- minimizes the space occupancy in bits of the compressed ing and decompressing the data, and take compressed- file, provided that the decompression time is bounded space which can be bound in terms of the k-th order by T . Symmetrically, we can exchange the role of empirical entropy of the input [25, 35]. the two resources and thus ask for minimizing the But the compressors running behind those large- decompression time provided that the compressed space scale storage systems are not derived from those scien- is bounded by a fixed amount given in advance. tific results. The reason relies in the fact that theo- We address this goal in three stages: (i) we intro- retically efficient compressors are optimal in the RAM duce the novel Bicriteria LZ77-Parsing problem which model, but they elicit many cache/IO misses during formalizes in a principled way what data-compressors the decompression step. -
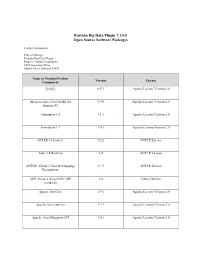
Pentaho Big Data Plugin 7.1.0.0 Open Source Software Packages
Pentaho Big Data Plugin 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho Big Data Plugin Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component [ini4j] 0.5.1 Apache License Version 2.0 An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 Annotation 1.0 1.1.1 Apache License Version 2.0 Annotation 1.1 1.0.1 Apache License Version 2.0 ANTLR 3 Complete 3.5.2 ANTLR License Antlr 3.4 Runtime 3.4 ANTLR License ANTLR, ANother Tool for Language 2.7.7 ANTLR License Recognition AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Ant Core 1.9.1 Apache License Version 2.0 Apache Ant Launcher 1.9.1 Apache License Version 2.0 Apache Aries Blueprint API 1.0.1 Apache License Version 2.0 Name of Product/Product Version License Component Apache Aries Blueprint CM 1.0.5 Apache License Version 2.0 Apache Aries Blueprint Core 1.4.2 Apache License Version 2.0 Apache Aries Blueprint Core 1.0.0 Apache License Version 2.0 Compatiblity Fragment Bundle Apache Aries JMX API 1.1.1 Apache License Version 2.0 Apache Aries JMX Blueprint API 1.1.0 Apache License Version 2.0 Apache Aries JMX Blueprint Core 1.1.0 Apache License Version 2.0 Apache Aries JMX Core 1.1.2 Apache License Version 2.0 Apache Aries JMX Whiteboard 1.0.0 Apache License Version 2.0 Apache Aries Proxy API 1.0.1 Apache License Version 2.0 Apache Aries Proxy Service 1.0.4 Apache License Version 2.0 Apache Aries Quiesce API 1.0.0 Apache License Version 2.0 Apache -

Modern Lossless Compression Techniques: Review, Comparison and Analysis
JAC : A Journal Of Composition Theory ISSN : 0731-6755 Modern Lossless Compression Techniques: Review, Comparison and Analysis B ASHA KIRAN, M MOUNIKA,B L SRINIVAS Dept of EEE , MRIET. Abstract— With the world drifting more and more enables its storage and transmission over a limited towards the social network, the size and amount of bandwidth channel. Fig.1 shows basic components of a data shared over the internet is increasing day by day. data compression system. The input data is processed by a Since the network bandwidth is always limited, we Data Compressor, which usually iterates over the data require efficient compression algorithms to facilitate twice. In the first iteration, the compression algorithm fast and efficient sharing of data over the network. In tries to gain knowledge about the data which in turn is this paper, we discuss algorithms of widely used used for efficient compression in the second iteration. The traditional and modern compression techniques. In an compressed data along with the additional data used for effort to find the optimum compression algorithm, we efficient compression is then stored or transmitted through compare commonly used modern compression a network to the receiver. The receiver then decompresses algorithms: Deflate, Bzip2, LZMA, PPMd and the data using a decompression algorithm. Though data PPMonstr by analyzing their performance on Silesia compression can reduce the bandwidth usage of a network corpus. The corpus comprises of files of varied type and the storage space, it requires additional computational and sizes, which accurately simulates the vast diversity resources for compression and decompression of data, and of files shared over the internet. -

High-Throughput Variable-To-Fixed Entropy Codec Using Selective, Stochastic Code Forests
Received March 5, 2020, accepted April 27, 2020, date of publication April 29, 2020, date of current version May 14, 2020. Digital Object Identifier 10.1109/ACCESS.2020.2991314 High-Throughput Variable-to-Fixed Entropy Codec Using Selective, Stochastic Code Forests MANUEL MARTÍNEZ TORRES 1, MIGUEL HERNÁNDEZ-CABRONERO 2, IAN BLANES 2, (Senior Member, IEEE), AND JOAN SERRA-SAGRISTÀ 2, (Senior Member, IEEE) 1Karlsruhe Institute of Technology, 76131 Karlsruhe, Germany 2Information and Communications Engineering, Universitat Autònoma de Barcelona, 08193 Bellaterra, Spain Corresponding author: Miguel Hernández-Cabronero ([email protected]) This was supported in part by the Postdoctoral Fellowship Program Beatriu de Pinós through the Secretary of Universities and Research (Government of Catalonia) under Grant 2018-BP-00008, in part by the Horizon 2020 Program of Research and Innovation of the European Union under the Marie Skªodowska-Curie under Grant 801370, in part by the Spanish Government under Grant RTI2018-095287-B-I00, and in part by the Catalan Government under Grant 2017SGR-463. ABSTRACT Efficient high-throughput (HT) compression algorithms are paramount to meet the stringent constraints of present and upcoming data storage, processing, and transmission systems. In particular, latency, bandwidth and energy requirements are critical for those systems. Most HT codecs are designed to maximize compression speed, and secondarily to minimize compressed lengths. On the other hand, decompression speed is often equally or more critical than compression speed, especially in scenarios where decompression is performed multiple times and/or at critical parts of a system. In this work, an algorithm to design variable-to-fixed (VF) codes is proposed that prioritizes decompression speed.