Ice Hockey Checking Detection from Indoor Localization Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
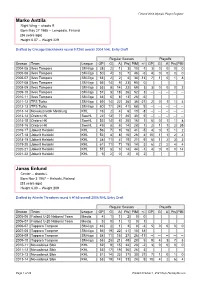
Finland Olympic Player Register At
Finland 2018 Olympic Player Register Marko Anttila Right Wing -- shoots R Born May 27 1985 -- Lempaala, Finland [36 years ago] Height 6.07 -- Weight 229 Drafted by Chicago Blackhawks round 9 #260 overall 2004 NHL Entry Draft Regular Season Playoffs Season Team League GP G A Pts PIM +/- GP G A Pts PIM 2004-05 Ilves Tampere SM-liiga 28 2 1 3 10 -1 3 0 0 0 0 2005-06 Ilves Tampere SM-liiga 50 4 3 7 46 -6 4 0 0 0 0 2006-07 Ilves Tampere SM-liiga 53 2 2 4 34 -13 7 1 0 1 8 2007-08 Ilves Tampere SM-liiga 56 14 9 23 90 0 2008-09 Ilves Tampere SM-liiga 53 8 14 22 69 3 3 0 0 0 2 2009-10 Ilves Tampere SM-liiga 57 8 18 26 52 3 -- -- -- -- -- 2010-11 Ilves Tampere SM-liiga 33 5 8 13 26 -5 2011-12 TPS Turku SM-liiga 59 14 22 36 36 -21 2 0 1 1 4 2012-13 TPS Turku SM-liiga 60 17 24 41 68 9 -- -- -- -- -- 2013-14 Novokuznetsk Metallurg KHL 16 2 4 6 10 -8 -- -- -- -- -- 2013-14 Orebro HK SweHL 22 13 7 20 30 5 -- -- -- -- -- 2014-15 Orebro HK SweHL 52 14 6 20 16 1 6 0 1 1 8 2015-16 Orebro HK SweHL 49 8 6 14 28 1 2 1 1 2 35 2016-17 Jokerit Helsinki KHL 56 7 9 16 41 -5 4 0 1 1 2 2017-18 Jokerit Helsinki KHL 52 8 8 16 26 4 10 1 1 2 4 2018-19 Jokerit Helsinki KHL 38 11 4 15 21 9 6 1 2 3 3 2019-20 Jokerit Helsinki KHL 61 11 7 18 14 3 6 2 2 4 4 2020-21 Jokerit Helsinki KHL 57 8 6 14 44 -1 4 0 0 0 14 2021-22 Jokerit Helsinki KHL 9 2 0 2 0 2 Jonas Enlund Center -- shoots L Born Nov 3 1987 -- Helsinki, Finland [33 years ago] Height 6.00 -- Weight 209 Drafted by Atlanta Thrashers round 6 #165 overall 2006 NHL Entry Draft Regular Season Playoffs Season Team League -

Careers Are Remembered by Olympic Success
Publisher: International Ice Hockey Federation, Editor-in-Chief: Jan-Ake Edvinsson Editors: Kimmo Leinonen, Szymon Szemberg Layout: Szymon Szemberg, Assistant Editor: Jenny Wiedeke September 2003 - Vol 7 - No 4 Edward Groeger Edward Photo: HOME OPENER. IIHF President René Fasel (left) is all smiles as IOC President Jacques Rogge drops the puck for the inaugural face-off between Fasel and the Mayor of Zurich, Elmar Ledergerber. The August 21 ceremony, which officially inaugurated the new IIHF offices, is witnessed by Christian Huber, the President Councillor of the Government of Kanton Zurich, and by Juan Antonio Samaranch, Lifetime IOC Honorary President. See more on the inauguration on page 11. Careers are remembered by Olympic success The 115th IOC Session in Prague, Czech Republic on July 1 was Olympic Winter Games. Indeed, the Olympics - and the Olympic ice hockey tourna- thrilling for sports fans and ice hockey fans in particular. And just ment - have an inner strength that goes beyond individual participation. like in hockey, there could only be one winner. Out of three very good bids for the 2010 Olympic Winter Games, Vancouver came out Heroes are made in the Olympics, regardless of what merit you bring with you coming into the Games. On August 11, a shock hit the world of hockey when Herb victorious. Brooks died in a car accident. In February 1980 a virtually unknown Brooks brought a group of college no-names to Lake Placid and proved that miracles can happen. II As president of the RENÉ FASEL EDITORIAL International Ice Hockey II None of his players became superstars and Brooks never won a championship in Federation, I cannot deny that going to Canada with an Olympic ice hockey tourna- the pro-ranks after Lake Placid, but their careers will always be measured by what ment presents a huge opportunity for our sport. -

Page 2.Qxd 19.3.2010 14:52 Uhr Seite 12
10-0552_IIHF_IceTimes_April2010.qxp:Page 2.qxd 19.3.2010 14:52 Uhr Seite 12 12 Volume 14 Number 2 April 2010 Norway’s Hove always on call April 2010 Volume 14 Number 2 The golden girl among women’s Published by International Ice Hockey Federation Editor-in-Chief Horst Lichtner Editor Szymon Szemberg Design Jenny Wiedeke international officials By Andrew Podnieks Olympics take the game to the next level Aina Hove's rise to the top of the referees' pool in women's hockey has been swift. The Norwegian didn't referee her first top division game until 2007, and two years later she was in the gold- medal game. But she has been surrounded by hockey her whole life. Her brother was a player; her husband has been a linesman; and, her sister, Marta, was a linesman in 2006 in Turin. Hove tal- ked about her career the day after she officiated the Canada- United States game for gold on February 25, 2010. Norway's men's team isn't a powerhouse, so for a woman it must have MAKING A STAND: Aina Hove has gotten the nod to been even tougher to play. How did you come to love hockey? officiate the last two gold medal games at major inter- national women’s events. In 2009, she called the USA- When I was a kid in Trondheim, my dad made an outdoor rink for the kids Canada final at the Women’s World Championship, to play on. It was a soccer field in the summer. I had nice red, figure ska- while in February, she again got the call to whistle the tes, like any girl. -

Vancouver Canucks Media Guide 2008.09 Schedule
2008.09 VANCOUVER CANUCKS MEDIA GUIDE 2008.09 SCHEDULE NATIONAL TV TV CANUCKS TV TV PAY-PER-VIEW (CBC OR TSN) JANUARY SUNMON TUE WED THUFRI SAT 12NSH ATL 3 TV 5:00 TV 4:30 HOME AWAY 4 DAL 567 EDM 8 SJ 91STL 0 SJ SEPTEMBER PS DENOTES PRESEASON GAMES SUN MON TUEWED THU FRI SAT TV 7:00 TV 7:00 7:30 TV 7:00 TV 7:00 14 15 16 17 18 19 20 11 12 13 NJ 14 15 PHX 16 17 TV 7:00 TV 7:00 21 22EDM 23 EDM 24 25 26 27 SJ 18 CBS 19 20SJ 21 22 23 24 TV TV PS 6:00 PS 7:00 PS 7:30 TV 5:00 TV 7:30 ALL-STAR BREAK 28 ANA 29 30 25 26 27 28 NSH 29 30 31 MIN TV PS 5:00 TV 7:30 TV 7:00 OCTOBER FEBRUARY SUN MON TUEWED THU FRI SAT SUNMON TUE WED THUFRI SAT 12CGY SJ 34 123 CAR 456 7 CHI TV PS 7:00 PS 7:00 TV 7:00 TV 7:00 5 ANA 678 9 CGY 10 11 CGY 8910 STL 11 12PHX 13 DAL 14 PS 7:00 TV 7:30 TV 7:00 TV 5:30 TV 6:00 TV 5:30 12 13 WAS 14 15 16DET 17 BUF 18 15 MTL 16 17 CGY 18 19 OTT 20 21 TOR TV 4:00 TV 4:30 TV 4:30 TV 7:00 TV 6:30 TV 4:30 TV 4:00 19 CHI 20 21 CBS 22 23 24 25 EDM 22 23 24 MTL 25 26 27 TB 28 TV 4:00 TV 4:00 TV 7:00 TV 4:30 TV 7:00 26 27 28 BOS 29 30LA 31 ANA TV 7:00 TV 7:30 TV 7:00 NOVEMBER MARCH SUN MON TUE WED THU FRISAT SUNMON TUEWED THUFRI SAT 1 1 CBS 2 3 MIN 4 567 SJ TV 5:00 TV 7:00 TV 7:00 2 DET 3 4 NSH 5 6 PHX 7 8 MIN 8 9 LA 10 11 ANA 12 13 LA 14 TV 7:00 TV 7:00 TV 7:00 TV 7:00 91011 12 COL 13 14 15 TOR TV 7:30 TV 7:00 TV 7:00 TV 7:00 TV 4:00 15 COL 16 17 DAL 18 19 STL 20 21 PHX 16 17 18 19 20 21 22 NYI NYR MIN PIT TV 7:00 TV 7:00 TV 7:00 TV 7:00 TV 4:00 TV 4:30 TV 5:00 TV 11AM 22 23 24 DAL 25 26STL 27 COL 28 23 24 DET 25 26 27 CGY 28 29 CGY TV 5:30 TV 5:30 TV 6:00 TV 7:00 TV 7:00 TV 7:00 30 29 CHI 30 31 MIN TV 4:00 TV 5:00 DECEMBER APRIL SUN MON TUE WED THU FRISAT SUNMON TUEWED THUFRI SAT 1 CBS 2345DET MIN 6 COL 1 2 ANA 3 4 EDM TV 4:00 TV 4:30 TV 5:00 7:00 TV 7:00 TV 7:00 7 COL 8 9 NSH 10 11 12 13 EDM 5 COL 6 7 CGY 8 9 LA 10 11 COL TV 5:00 TV 5:00 TV 7:00 TV 7:00 TV 7:00 TV 7:00 TV 12PM 14 FLA 15 16 17 EDM 18 19 20 CHI 12 13 14 15 16 17 18 TV 7:00 TV 7:30 TV 7:00 21 22 ANA 23 SJ 24 25 26 EDM 27 * GAME DATES, OPPONENTS & TIMES SUBJECT TO CHANGE. -

2007 SC Playoff Summaries
DETROIT RED WINGS STANLEY CUP CHAMPIONS 2 0 0 8 Chris Chelios, Daniel Cleary, Pavel Datsyuk, Aaron Downey, Dallas Drake, Kris Draper, Valtteri Filppula, Johan Franzen, Dominik Hasek, Darren Helm, Tomas Holmstrom, Jiri Hudler, Tomas Kopecky, Niklas Kronwall, Brett Lebda, Nicklas Lidstrom CAPTAIN, Andreas Lilja, Kirk Maltby, Darren McCarty, Derek Meech, Chris Osgood, Brian Rafalski, Mikael Samuelsson, Brad Stuart, Henrik Zetterberg Michael Ilitch OWNER/GOVERNOR Ken Holland GENERAL MANAGER, Mike Babcock HEAD COACH © Steve Lansky 2010 bigmouthsports.com NHL and the word mark and image of the Stanley Cup are registered trademarks and the NHL Shield and NHL Conference logos are trademarks of the National Hockey League. All NHL logos and marks and NHL team logos and marks as well as all other proprietary materials depicted herein are the property of the NHL and the respective NHL teams and may not be reproduced without the prior written consent of NHL Enterprises, L.P. Copyright © 2010 National Hockey League. All Rights Reserved. 2008 EASTERN CONFERENCE QUARTER—FINAL 1 MONTRÉAL CANADIENS 104 v. 8 BOSTON BRUINS 94 GM BOB GAINEY, HC GUY CARBONNEAU v. GM PETER CHIARELLI, HC CLAUDE JULIEN CANADIENS WIN SERIES IN 7 Thursday, April 10 1900 h et on HNIC Saturday, April 12 1900 h et on HNIC BOSTON 1 @ MONTREAL 4 BOSTON 2 @ MONTREAL 3 OVERTIME FIRST PERIOD FIRST PERIOD 1. MONTREAL, Sergei Kostitsyn 1 (Patrice Brisebois) 0:34 1. MONTREAL, Roman Hamrlik 1 (Bryan Smolinski, Steve Begin) 18:30 2. MONTREAL, Andrei Kostitsyn 1 (Tomas Plekanec) 2:02 GWG 3. BOSTON, Shane Hnidy 1 (Andrew Ference, Phil Kessel) 8:34 Penalties – Markov M 5:52, Streit M 11:00, Chara B 14:03, Reich B Higgins M 20:00 Penalties – Hnidy B 5:43, Markov M 14:16, Murray B Komisarek M 17:46 SECOND PERIOD 2. -

10 Chicago Blackhawks 2009
PRESENTED BY CHICAGO BLACKHAWKS MEDIA GUIDE BLACKHAWKS CHICAGO 2009 - 10 CHICAGO BLACKHAWKS MEDIA GUIDE BLACKHAWKS CHICAGO 2009 - 10 2009 - 10 CHICAGO BLACKHAWKS MEDIA GUIDE #2%$)43 #2%$)43 Editors ..........................Brandon Faber, Adam Kempenaar, Paul Kennedy, Adam Rogowin and John Sandberg Design, Layout and Production ......................................................................................................John Sandberg Cover Design ...................................................................................................................................Chris Weibring Editorial Assistance ..................................................................................................Brad Boron and Lauren Lang Photography ....................................................................................... Bill Smith, Rudy Ayasse and Getty Images Printing ..................................................................................................................... The Graphic Arts Studio, Inc. © 2009 Chicago Blackhawks The information contained in this publication was compiled by the Chicago Blackhawks and is provided as a courtesy to our media and fans, and may be used only for personal and editorial purposes. Any commercial use of this information without the prior written consent of the Chicago Blackhawks is prohibited. CHICAGOBLACKHAWKS.COM 1 4!",%/&#/.4%.43 Credits ................................................ 1 Game-by-Game Summaries ........80-91 Brandon Pirri ....................................111 -

Main Partners of Olympic Team Finland Content Greetings from Rio 2016
TEAM FINLAND XXIII Olympic Winter Games PyeongChang 2018 Main Partners of Olympic Team Finland Content Greetings from Rio 2016 . 4. Alpine Skiing . 6 Biathlon . 8 Cross-Country . 14 Curling . .22 . Figure Skating . .24 . Freestyle . 25 Ice Hockey, Men . 28 Ice Hockey, Women . 54. Nordic Combined . 78 Ski Jumping . 82 Snowboarding . 86 Speed Skating . 92 Abbreviations and notes . 96 Management . 104 Support Staff . 105 Medical Team . .106 Schedule . 108 Map . 110 Edited by: Sports Museum of Finland, Information Service Vesa Tikander Photographs: Finnish Olympic Committee, Tailorframe . PyeongChang 2018 Layout: Hanna Rättö Press: Grano Oy Publisher: Finnish Olympic Committee ©Copyright Sports Museum of Finland and Finnish Olympic Committee ISBN 978-952-5794-72-4 (NID) ISBN 978-952-5794-73-1 (PDF) Sport Museum of Finland Information Service: vesa tikander@urheilumuseo. fi. Finnish Olympic Committee: www .olympiakomitea fi. International Olympic Committee: www .olympic .org PyeongChang 2018: www .pyeongchang2018 .com Greetings from Summer Olympians and Paralympians Mira Potkonen Boxing, Olympic Bronze Medalist 2016 Olympic Games offer a chance to do something unique, something that you have always dreamed of . The most important thing is to keep the faith, maintain inner peace, and concentrate on your own routines . I highly appreciate winter athletes and follow closely winter Olympics . Among all the great winter sports, snowboarding is my favorite . Good luck for the Finnish team in PyeongChang, fight on! 4 Jarkko Nieminen Tennis, Olympian 2004, 2008 and 2012 Olympics are the most inspiring of all the sporting events . For an individual athlete, Olympics offer a chance to become a part of a great team, feel exceptional friendship, and share unforgettable experien- ces with the other athletes .