POLS/CSSS 510: Maximum Likelihood Methods for the Social Sciences Problem Set 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Repeal of Baseball's Longstanding Antitrust Exemption: Did Congress Strike out Again?
Repeal of Baseball's Longstanding Antitrust Exemption: Did Congress Strike out Again? INTRODUCrION "Baseball is everybody's business."' We have just witnessed the conclusion of perhaps the greatest baseball season in the history of the game. Not one, but two men broke the "unbreakable" record of sixty-one home-runs set by New York Yankee great Roger Maris in 1961;2 four men hit over fifty home-runs, a number that had only been surpassed fifteen times in the past fifty-six years,3 while thirty-three players hit over thirty home runs;4 Barry Bonds became the only player to record 400 home-runs and 400 stolen bases in a career;5 and Alex Rodriguez, a twenty-three-year-old shortstop, joined Bonds and Jose Canseco as one of only three men to have recorded forty home-runs and forty stolen bases in a 6 single season. This was not only an offensive explosion either. A twenty- year-old struck out twenty batters in a game, the record for a nine inning 7 game; a perfect game was pitched;' and Roger Clemens of the Toronto Blue Jays won his unprecedented fifth Cy Young award.9 Also, the Yankees won 1. Flood v. Kuhn, 309 F. Supp. 793, 797 (S.D.N.Y. 1970). 2. Mark McGwire hit 70 home runs and Sammy Sosa hit 66. Frederick C. Klein, There Was More to the Baseball Season Than McGwire, WALL ST. J., Oct. 2, 1998, at W8. 3. McGwire, Sosa, Ken Griffey Jr., and Greg Vaughn did this for the St. -

Em Reading: Hit a Home Run with Reading
Hit a Home Run with Reading! • Keep ’em Reading • Grades by | Carol Thompson K–2, 3–5 Library Incentive Program and Party Join the World Series anticipation with this read- ing incentive and encourage your students to hit a home run. This month-long unit will prove to a fun learning experience. Objective: To get kids to read Incentive Summary This is a great incentive for October (World Series) or springtime incentive. Using the theme of base- ball, students are encouraged to hit a home run Activities and celebrate their favorite teams and players while • Read various baseball books. (Suggested learning about the history of America’s best-loved Resources on page 4.) sport. Readers keep up with their stats on a base- • Locate fan Web sites and have students write ball field record sheet and earn tickets to the com- a letter to a favorite player, manager, or coach. munity minor league baseball team on the school Teach and/or review proper form for friendly night. The school also hosts an old-fashioned hot letter. Letters can be e-mailed too. dog and apple pie cookout. • Act out the book Casey at the Bat or use it as a reader’s theater. • Have a favorite team dress-up day where stu- Bulletin Board dents wear their baseball/softball uniforms Here’s a sample of our “Hit a Home Run with (including hats which are normally against Reading!” bulletin board. Get creative. Baseball dress code so the kids love it!). bats and baseballs can create great letters. It also • Have the High School baseball or softball team looks good to use old book covers on this bulletin players or coaches come and read to classes board for a 3-D effect. -

Media Kit 2013
Media Kit 2013 Table of Contents 1. Company Profile – The Fergie Jenkins Foundation Basics 2. Biography – Fergie Jenkins, Chairman 3. Biography – Carl Kovacs, President 4. Background Information 5. Sample Media Release 6. Charities and Organizations we Support – Canada & the United States 7. Corporate Sponsors – Canada & the United States 8. Frequently Asked Questions “Humanitarian Aid Sees No Borders and Neither Do We” 67 Commerce Place • Suite 3 • St. Catharines, ON • L2R 6P7 • Ph: 905.688.9418 • Fax: 905.688.0025 • www.fergiejenkins.ca Introduction The Fergie Jenkins Foundation is a North American charitable organization (Registered Charity Business No. 87102 5920 RR0001), based in St. Catharines, Ontario. Chaired by former Major League Baseball pitcher and Hall of Famer Ferguson “Fergie” Jenkins, the Foundation participates in charitable initiatives across North America, raising money for more than 400 other organizations. Company The Fergie Jenkins Foundation Inc. 67 Commerce Pl, Suite 3 St. Catharines, ON, L2R 6P7 905-688-9418 Personnel Ferguson Jenkins, Chairman Carl Kovacs, President John Oddi, Executive Director Mike Treadgold, Communications Coordinator Ryan Nava, Community Relations Director Rachel Pray, Executive Assistant Brett Varey, Special Events Coordinator Dexter McQueen, Sport Management Associate Kerrigan McNeill, Public Relations Associate Jillian Buttenham, Museum Associate Jessica Chase, Museum Associate Background The Fergie Jenkins Foundation was founded in 1999 by Jenkins, Kovacs and Brent Lawler, with the goal of raising funds for charities across North America. At its inception, the Foundation adopted the mission statement, “Serving Humanitarian Need Through the Love of Sport,” a phrase that can be found on all company letterheads and signage at charity events. -

* Text Features
The Boston Red Sox Saturday, April 18, 2020 * The Boston Globe Fenway Park is ready to play ball, even though we are not Stan Grossfeld The grass is perfect and the old ballpark is squeaky clean — it was scrubbed and disinfected for viral pathogens for three days in March. Spending a few hours at Fenway Park is good for the soul. The ballpark is totally silent. The mound and home plate are covered by tarps and the foul lines aren’t drawn yet, but it feels as if there still could be a game played today. The sun’s warmth reflecting off The Wall feels good. The tug of the past is all around but the future is the great unknown. In Fenway, zoom is still a word to describe a Chris Sale fastball, not a video conferencing app. Old friend Terry Francona and the Cleveland Indians would have been here this weekend and there would’ve been big hugs by the batting cage and the rhythmic crack of bat meeting ball. But now gaining access is nearly impossible and includes health questions and safety precautions and a Fenway security escort. Visitors must wear a respiratory mask, gloves, and practice social distancing, larger than the lead Dave Roberts got on Mariano Rivera in the 2004 ALCS. Carissa Unger of Green City Growers in Somerville is planting organic vegetables for Fenway Farms, located on the rooftop of the park. She is one of the few allowed into the ballpark. The harvest this year all will be donated to a local food pantry. -
![[Read] Doc: the Life of Roy Halladay | Ebook](https://docslib.b-cdn.net/cover/7579/read-doc-the-life-of-roy-halladay-ebook-817579.webp)
[Read] Doc: the Life of Roy Halladay | Ebook
Doc: The Life of Roy Halladay Hall of Famer, Cy Young winner, and All-Star will forever be used to describe the illustrious career of Roy Halladay. With a repertoire of masterful pitches wielded with impeccable command, he piled up accolades during his 16 major league seasons, the very image of stability and dominance whenever he took the mound. Doc is a celebration and a profound remembrance of a beloved player, friend, and family man. Todd Zolecki traces Halladay's remarkable journey, from garnering the attention of major league scouts as a teenager in Colorado, to Halladay's methodical reinvention and ascent to ace status in Toronto, to the signature no-hitter he authored in his playoff debut with the Philadelphia Phillies. Also examined are Halladay's distinctive, disciplined approach to pitching, his impact as a teammate and community member, and the baseball world's honoring of these qualities in Cooperstown in 2019. Thoroughly and thoughtfully reported, with input and reflections from Halladay's teammates, coaches, competitors, and more, this is an essential biography for baseball fans everywhere. https://ift.realfiedbook.com/?book=1629377503 Read Online PDF Doc: The Life of Roy Halladay, Download PDF Doc: The Life of Roy Halladay, Download Full PDF Doc: The Life of Roy Halladay, Download PDF and EPUB Doc: The Life of Roy Halladay, Read PDF ePub Mobi Doc: The Life of Roy Halladay, Reading PDF Doc: The Life of Roy Halladay, Download Book PDF Doc: The Life of Roy Halladay, Read online Doc: The Life of Roy Halladay, Download Doc: The -

Ferguson Jenkins: Biography from Answers.Com 4/17/10 6:38 PM
Ferguson Jenkins: Biography from Answers.com 4/17/10 6:38 PM Ferguson Jenkins Britannica Concise Encyclopedia: Ferguson Jenkins Fergie Jenkins (born Dec. 13, 1943, Chatham, Ont., Can.) Canadian-born U.S. baseball pitcher. In high school Jenkins excelled in amateur baseball, basketball, and hockey. He began his major league career with the Philadelphia Phillies in the early 1960s, before playing for the Chicago Cubs, the Texas Rangers, and the Boston Red Sox, winning at least 20 games in each of six consecutive seasons (1967 – 72) and setting several season records. He was awarded the Cy Young award in 1971 for his 24 – 13 won-lost record and 2.77 earned run average. For more information on Fergie Jenkins, visit Britannica.com. Black Biography: Fergie Jenkins baseball player Personal Information Born Ferguson Arthur Jenkins on December 13, 1943, in Chatham, Ontario, Canada; married Kathy Williams, 1965 (divorced); married Maryanne (died 1991); married Lydia Farrington, 1993; children: Kelly, Delores, Kimberly, Raymond (stepson), Samantha (died 1993). Memberships: Major League Baseball Players Alumni Association Career Philadelphia Phillies (National League), professional baseball player, 1965-66; Chicago Cubs (National League), professional baseball player, 1966-73, 1982-83; Texas Rangers (American League), professional baseball player, 1974-75, 1978-81; Boston Red Sox (American League), professional baseball player, 1976-77. Team Canada, pitching coach for Pan-Am Games, 1987; Texas Rangers (Oklahoma City 89ers minor league team), pitching coach, 1988-89; Cincinnati Reds, roving minor league coach, 1992-93; Chicago Cubs, minor league coach, 1995-96; Canadian Baseball League, commissioner, 2003-. http://www.answers.com/topic/ferguson-jenkins?&print=true Page 1 of 12 Ferguson Jenkins: Biography from Answers.com 4/17/10 6:38 PM Life's Work "Pitchers are a breed apart...," wrote Eliot Asinof in a Time biography of pitching great Fergie Jenkins. -

National Pastime a REVIEW of BASEBALL HISTORY
THE National Pastime A REVIEW OF BASEBALL HISTORY CONTENTS The Chicago Cubs' College of Coaches Richard J. Puerzer ................. 3 Dizzy Dean, Brownie for a Day Ronnie Joyner. .................. .. 18 The '62 Mets Keith Olbermann ................ .. 23 Professional Baseball and Football Brian McKenna. ................ •.. 26 Wallace Goldsmith, Sports Cartoonist '.' . Ed Brackett ..................... .. 33 About the Boston Pilgrims Bill Nowlin. ..................... .. 40 Danny Gardella and the Reserve Clause David Mandell, ,................. .. 41 Bringing Home the Bacon Jacob Pomrenke ................. .. 45 "Why, They'll Bet on a Foul Ball" Warren Corbett. ................. .. 54 Clemente's Entry into Organized Baseball Stew Thornley. ................. 61 The Winning Team Rob Edelman. ................... .. 72 Fascinating Aspects About Detroit Tiger Uniform Numbers Herm Krabbenhoft. .............. .. 77 Crossing Red River: Spring Training in Texas Frank Jackson ................... .. 85 The Windowbreakers: The 1947 Giants Steve Treder. .................... .. 92 Marathon Men: Rube and Cy Go the Distance Dan O'Brien .................... .. 95 I'm a Faster Man Than You Are, Heinie Zim Richard A. Smiley. ............... .. 97 Twilight at Ebbets Field Rory Costello 104 Was Roy Cullenbine a Better Batter than Joe DiMaggio? Walter Dunn Tucker 110 The 1945 All-Star Game Bill Nowlin 111 The First Unknown Soldier Bob Bailey 115 This Is Your Sport on Cocaine Steve Beitler 119 Sound BITES Darryl Brock 123 Death in the Ohio State League Craig -
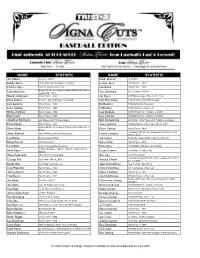
Printer-Friendly Version (PDF)
NAME STATISTIC NAME STATISTIC Jim Abbott No-Hitter 9/4/93 Ralph Branca 3x All-Star Bobby Abreu 2005 HR Derby Champion; 2x All-Star George Brett Hall of Fame - 1999 Tommie Agee 1966 AL Rookie of the Year Lou Brock Hall of Fame - 1985 Boston #1 Overall Prospect-Named 2008 Boston Minor Lars Anderson Tom Browning Perfect Game 9/16/88 League Off. P.O.Y. Sparky Anderson Hall of Fame - 2000 Jay Bruce 2007 Minor League Player of the Year Elvis Andrus Texas #1 Overall Prospect -shortstop Tom Brunansky 1985 All-Star; 1987 WS Champion Luis Aparicio Hall of Fame - 1984 Bill Buckner 1980 NL Batting Champion Luke Appling Hall of Fame - 1964 Al Bumbry 1973 AL Rookie of the Year Richie Ashburn Hall of Fame - 1995 Lew Burdette 1957 WS MVP; b. 11/22/26 d. 2/6/07 Earl Averill Hall of Fame - 1975 Ken Caminiti 1996 NL MVP; b. 4/21/63 d. 10/10/04 Jonathan Bachanov Los Angeles AL Pitching prospect Bert Campaneris 6x All-Star; 1st to Player all 9 Positions in a Game Ernie Banks Hall of Fame - 1977 Jose Canseco 1986 AL Rookie of the Year; 1988 AL MVP Boston #4 Overall Prospect-Named 2008 Boston MiLB Daniel Bard Steve Carlton Hall of Fame - 1994 P.O.Y. Philadelphia #1 Overall Prospect-Winning Pitcher '08 Jesse Barfield 1986 All-Star and Home Run Leader Carlos Carrasco Futures Game Len Barker Perfect Game 5/15/81 Joe Carter 5x All-Star; Walk-off HR to win the 1993 WS Marty Barrett 1986 ALCS MVP Gary Carter Hall of Fame - 2003 Tim Battle New York AL Outfield prospect Rico Carty 1970 Batting Champion and All-Star 8x WS Champion; 2 Bronze Stars & 2 Purple Hearts Hank -

Bob Gibson April 2004 No. 96 the Greatest Big-Game Pitcher of His Era, Bob Gibson Is a Native of Omaha Who Continues to Call the Metropolitan Area His Home
Bob Gibson April 2004 No. 96 The greatest big-game pitcher of his era, Bob Gibson is a native of Omaha who continues to call the metropolitan area his home. Over 17 seasons with the St. Louis Cardinals, he posted World Series records of seven consecutive wins and 17 strikeouts in a game, both unbroken records today. Gibson led the Cardinals to two World Series championships and was twice named MVP of the World Series. He won nine straight Gold Glove awards, two Cy Young awards and pitched a no-hitter in 1971. In 1968, he was named the National League Most Valuable Player, after posting a 22-9 record, 1.12 ERA, throwing 13 shutouts and recording 268 strikeouts. He was elected to the National Baseball Hall of Fame on the first ballot in 1981 and in 1999 was voted by baseball fans to Major League Baseball’s All-Century Team. The Hall of Fame called Gibson “the very definition of intimidation, competitiveness and dignity.“ Gibson was a star in both basketball and baseball at Omaha Technical High School and also was a two-sport star athlete at Creighton University. His first professional sports experience was in basketball, where he spent a year as a member of the Harlem Globetrotters. His roommate was Meadowlark Lemon. He was drafted by the St. Louis Cardinals and soon moved from the minor leagues to the major league roster. Two of his roasters via videotape were famous former Gibson teammates: New York Yankees Manager Joe Torre and Fox Sports broadcaster Tim McCarver. Both were St. -

The Don Drysdale Collection, 1857 'Laws of Baseball
FOR IMMEDIATE RELEASE Terry Melia – 949-831-3700, [email protected] THE DON DRYSDALE COLLECTION, 1857 ‘LAWS OF BASEBALL’ DOCUMENTS AND SANDY KOUFAX’S 1956 BROOKLYN DODGERS HOME JERSEY HEADLINE SCP AUCTIONS’ 2016 SPRING PREMIER Online auction of more than 1,300 lots starts today at www.SCPAuctions.com Laguna Niguel, Calif. (April 6, 2016) – SCP Auctions’ 2016 Spring Premier online auction begins today and runs through Saturday, April 23, at www.scpauctions.com. The Don Drysdale Estate Collection, led by the late Hall of Famer’s 1962 Cy Young award and 1963 and ’65 Dodgers World Series championship rings, leads the way in this blockbuster auction that includes 1,310 outstanding lots. Other top lots include an impeccably preserved 1956 Sandy Koufax game-worn Brooklyn Dodgers home jersey; a 1936 Winter Olympics gold medal presented to Great Britain hockey goalie Jimmy Foster; a full, PSA-graded ticket run from Super Bowl 1 through 50; and the historic 1989 agreement banning Pete Rose from baseball for life, signed by both Rose and late MLB Commissioner Bart Giamatti. The Don Drysdale Personal Memorabilia Collection Drysdale’s most prominent awards and game-worn uniforms are up for bid including his 1963 and ’65 World Series championship rings; 1956 National League championship ring; 1962 MLB Cy Young Award; a host of game-worn Dodger uniforms from his playing days in both Brooklyn (1956, rookie season) as well as Los Angeles (1965, ‘66 and ’69); and the actual game-used baseball from the final inning pitched of his then-MLB record streak of throwing 58-and-two-thirds innings of scoreless baseball in 1968. -

For the Benefit of Presented By
For the Benefit of We Proudly Support Presented by The U.S. Military All proceeds from this special event benefit the Broome County Urban League, The Boys and Girls Clubs of Binghamton, Catholic Charities and CHOW. Each year, approximately 35 professional baseball players and other celebrities come to Binghamton to participate in this tournament and to support these charities. You won’t want to miss this chance to meet and golf with some of baseball’s greatest players –all while supporting institutions that are vital to the needs of our community and its children. Jim “Mudcat” Grant Legacy All-Star Golf Tournament Thursday, September 2, 2021 At The Links at Hiawatha Landing www.allstar-golf.com Special Guests from Past Years Members of The Black Aces (the African-American major league baseball pitchers who won 20 or more games in a single season) including: Fergie Jenkins Al Downing JR Richard 1991 Baseball Hall of Fame LHP 1961-77 Yankees, A’s, RHP 1971-80 Astros Pitcher 1965-83 Phillies, Cubs, Brewers, Dodgers Rangers, Red Sox Here are some of the celebrities who have attended the tournament over the years. Ron Blomberg George Foster Vern Law Johnny Roland Duke Sims DH-1B-OF 1969-78 OF 1969-89 Giants, Reds, Mets, RHP 1950-67 Pirates NFL 1966-73 St. Louis Cardinals C-1B-OF 1964-74 Indians , Yankees, White Sox White Sox 1960 Cy Young Award Rookie of the Year in 1966 Dodgers, Tigers, Yankees, Rangers Jim Boeheim Tony Jeter Dave Lemanczyk John Schmitt Lee Smith Head Coach TE 1966 -70 Pittsburgh Steelers RHP 1973-80 Tigers, Blue Jays, Center -

Spalding's Official Base Ball Guide, 1911
Library of Congress Spalding's official base ball guide, 1911 Untitled Section ~~~~ 'as, .. sgo , " > \ Et"^Xt 'I'w'A. ' h r:: _ _ _ .... ..: ' - ... r DR. GEORGE ORTON On athletics, college athletics, Particularly track and field, foot ball, soccer 'foot ball. and,, training of the youth, it would be hard to find one better qualified than Dr. Orton; has had the necessary athletic experience and the ability to impart that experience intelligently to the youth of the land; for years was the American, British and Canadima champion runner. I - SPALDING ATHLETIC LIBRARY Group I. Base Ball No. 229How to Catch. Every boy who has hopes of being a No. 1-Spalding's Official clever catcher should read how well- Base Ball Guide, known players cover their position. The leading Base Ball Pictures of all the noted catchers in annual of the country, and the big leagues. Price 10 cents. the official authority of the game. Contains the No. 225-How to Play First - official playing rules, with Base. an explanatory index of the Illustrated with pictures of all the rules compiled by Mr. A. G. prominent first basemen. Price 10cents. Spalding; pictures of all the teams Spalding's official base ball guide, 1911 http://www.loc.gov/resource/spalding.00156 Library of Congress in the National, No. 226-How to Play Second American and minor leagues; re- Base. views of the season; college Base Ball, The ideas of the best second basemen and a great deal of interesting in- have been incorporated in this book for formation. Price 10 cents, the especial benefit of boys who want No.