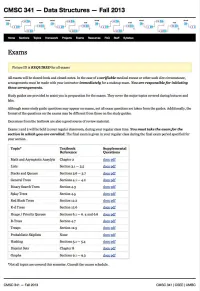
Handout Data Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
CMSC 341 Data Structure Asymptotic Analysis Review
CMSC 341 Data Structure Asymptotic Analysis Review These questions will help test your understanding of the asymptotic analysis material discussed in class and in the text. These questions are only a study guide. Questions found here may be on your exam, although perhaps in a different format. Questions NOT found here may also be on your exam. 1. What is the purpose of asymptotic analysis? 2. Define “Big-Oh” using a formal, mathematical definition. 3. Let T1(x) = O(f(x)) and T2(x) = O(g(x)). Prove T1(x) + T2(x) = O (max(f(x), g(x))). 4. Let T(x) = O(cf(x)), where c is some positive constant. Prove T(x) = O(f(x)). 5. Let T1(x) = O(f(x)) and T2(x) = O(g(x)). Prove T1(x) * T2(x) = O(f(x) * g(x)) 6. Prove 2n+1 = O(2n). 7. Prove that if T(n) is a polynomial of degree x, then T(n) = O(nx). 8. Number these functions in ascending (slowest growing to fastest growing) Big-Oh order: Number Big-Oh O(n3) O(n2 lg n) O(1) O(lg0.1 n) O(n1.01) O(n2.01) O(2n) O(lg n) O(n) O(n lg n) O (n lg5 n) 1 9. Determine, for the typical algorithms that you use to perform calculations by hand, the running time to: a. Add two N-digit numbers b. Multiply two N-digit numbers 10. What is the asymptotic performance of each of the following? Select among: a. O(n) b. -

Through the Concept of Data Structures, the Self- Balancing Binary Search Tree
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 06 Issue: 01 | Jan 2019 www.irjet.net p-ISSN: 2395-0072 THROUGH THE CONCEPT OF DATA STRUCTURES, THE SELF- BALANCING BINARY SEARCH TREE Asniya Sadaf Syed Atiqur Rehman1, Avantika kishor Bakale2, Priyanka Patil3 1,2,3Department of Computer Science and Engineering, Prof Ram Meghe College of Engineering and Management, Badnera -------------------------------------------------------------------------***------------------------------------------------------------------------ ABSTRACT - In the word of computing tree is a known way of implementing balancing tree as binary hierarchical data structure which stores information tree they are originally discovered by Bayer and are naturally in the form of hierarchy style. Tree is a most nowadays extensively (diseased) in the standard powerful and advanced data structure. This paper is literature or algorithm Maintaining the invariant of red mainly focused on self -balancing binary search tree(BST) black tree through Haskell types system using the nested also known as height balanced BST. A BST is a type of data data types this give small list noticeable overhead. Many structure that adjust itself to provide the consistent level gives small list overhead can be removed by the use of of node access. This paper covers the different types of BST existential types [4]. their analysis, complexity and application. 3.1. AVL TREE Key words: AVL Tree, Splay Tree, Skip List, Red Black Tree, BST. AVL Tree is best example of self-balancing search tree; this means that AVL Tree is also binary search tree 1. INTRODUCTION which is also balancing tree. A binary tree is said to be Tree data structures are the similar like Maps and Sets, balanced if different between the height of left and right. -

Data Structures and Algorithms Binary Heaps (S&W 2.4)
Data structures and algorithms DAT038/TDA417, LP2 2019 Lecture 12, 2019-12-02 Binary heaps (S&W 2.4) Some slides by Sedgewick & Wayne Collections A collection is a data type that stores groups of items. stack Push, Pop linked list, resizing array queue Enqueue, Dequeue linked list, resizing array symbol table Put, Get, Delete BST, hash table, trie, TST set Add, ontains, Delete BST, hash table, trie, TST A priority queue is another kind of collection. “ Show me your code and conceal your data structures, and I shall continue to be mystified. Show me your data structures, and I won't usually need your code; it'll be obvious.” — Fred Brooks 2 Priority queues Collections. Can add and remove items. Stack. Add item; remove the item most recently added. Queue. Add item; remove the item least recently added. Min priority queue. Add item; remove the smallest item. Max priority queue. Add item; remove the largest item. return contents contents operation argument value size (unordered) (ordered) insert P 1 P P insert Q 2 P Q P Q insert E 3 P Q E E P Q remove max Q 2 P E E P insert X 3 P E X E P X insert A 4 P E X A A E P X insert M 5 P E X A M A E M P X remove max X 4 P E M A A E M P insert P 5 P E M A P A E M P P insert L 6 P E M A P L A E L M P P insert E 7 P E M A P L E A E E L M P P remove max P 6 E M A P L E A E E L M P A sequence of operations on a priority queue 3 Priority queue API Requirement. -

Lecture 04 Linear Structures Sort
Algorithmics (6EAP) MTAT.03.238 Linear structures, sorting, searching, etc Jaak Vilo 2018 Fall Jaak Vilo 1 Big-Oh notation classes Class Informal Intuition Analogy f(n) ∈ ο ( g(n) ) f is dominated by g Strictly below < f(n) ∈ O( g(n) ) Bounded from above Upper bound ≤ f(n) ∈ Θ( g(n) ) Bounded from “equal to” = above and below f(n) ∈ Ω( g(n) ) Bounded from below Lower bound ≥ f(n) ∈ ω( g(n) ) f dominates g Strictly above > Conclusions • Algorithm complexity deals with the behavior in the long-term – worst case -- typical – average case -- quite hard – best case -- bogus, cheating • In practice, long-term sometimes not necessary – E.g. for sorting 20 elements, you dont need fancy algorithms… Linear, sequential, ordered, list … Memory, disk, tape etc – is an ordered sequentially addressed media. Physical ordered list ~ array • Memory /address/ – Garbage collection • Files (character/byte list/lines in text file,…) • Disk – Disk fragmentation Linear data structures: Arrays • Array • Hashed array tree • Bidirectional map • Heightmap • Bit array • Lookup table • Bit field • Matrix • Bitboard • Parallel array • Bitmap • Sorted array • Circular buffer • Sparse array • Control table • Sparse matrix • Image • Iliffe vector • Dynamic array • Variable-length array • Gap buffer Linear data structures: Lists • Doubly linked list • Array list • Xor linked list • Linked list • Zipper • Self-organizing list • Doubly connected edge • Skip list list • Unrolled linked list • Difference list • VList Lists: Array 0 1 size MAX_SIZE-1 3 6 7 5 2 L = int[MAX_SIZE] -

Priority Queues and Binary Heaps Chapter 6.5
Priority Queues and Binary Heaps Chapter 6.5 1 Some animals are more equal than others • A queue is a FIFO data structure • the first element in is the first element out • which of course means the last one in is the last one out • But sometimes we want to sort of have a queue but we want to order items according to some characteristic the item has. 107 - Trees 2 Priorities • We call the ordering characteristic the priority. • When we pull something from this “queue” we always get the element with the best priority (sometimes best means lowest). • It is really common in Operating Systems to use priority to schedule when something happens. e.g. • the most important process should run before a process which isn’t so important • data off disk should be retrieved for more important processes first 107 - Trees 3 Priority Queue • A priority queue always produces the element with the best priority when queried. • You can do this in many ways • keep the list sorted • or search the list for the minimum value (if like the textbook - and Unix actually - you take the smallest value to be the best) • You should be able to estimate the Big O values for implementations like this. e.g. O(n) for choosing the minimum value of an unsorted list. • There is a clever data structure which allows all operations on a priority queue to be done in O(log n). 107 - Trees 4 Binary Heap Actually binary min heap • Shape property - a complete binary tree - all levels except the last full. -

Search Trees
Lecture III Page 1 “Trees are the earth’s endless effort to speak to the listening heaven.” – Rabindranath Tagore, Fireflies, 1928 Alice was walking beside the White Knight in Looking Glass Land. ”You are sad.” the Knight said in an anxious tone: ”let me sing you a song to comfort you.” ”Is it very long?” Alice asked, for she had heard a good deal of poetry that day. ”It’s long.” said the Knight, ”but it’s very, very beautiful. Everybody that hears me sing it - either it brings tears to their eyes, or else -” ”Or else what?” said Alice, for the Knight had made a sudden pause. ”Or else it doesn’t, you know. The name of the song is called ’Haddocks’ Eyes.’” ”Oh, that’s the name of the song, is it?” Alice said, trying to feel interested. ”No, you don’t understand,” the Knight said, looking a little vexed. ”That’s what the name is called. The name really is ’The Aged, Aged Man.’” ”Then I ought to have said ’That’s what the song is called’?” Alice corrected herself. ”No you oughtn’t: that’s another thing. The song is called ’Ways and Means’ but that’s only what it’s called, you know!” ”Well, what is the song then?” said Alice, who was by this time completely bewildered. ”I was coming to that,” the Knight said. ”The song really is ’A-sitting On a Gate’: and the tune’s my own invention.” So saying, he stopped his horse and let the reins fall on its neck: then slowly beating time with one hand, and with a faint smile lighting up his gentle, foolish face, he began.. -

CS210-Data Structures-Module-29-Binary-Heap-II
Data Structures and Algorithms (CS210A) Lecture 29: • Building a Binary heap on 풏 elements in O(풏) time. • Applications of Binary heap : sorting • Binary trees: beyond searching and sorting 1 Recap from the last lecture 2 A complete binary tree How many leaves are there in a Complete Binary tree of size 풏 ? 풏/ퟐ 3 Building a Binary heap Problem: Given 풏 elements {푥0, …, 푥푛−1}, build a binary heap H storing them. Trivial solution: (Building the Binary heap incrementally) CreateHeap(H); For( 풊 = 0 to 풏 − ퟏ ) What is the time Insert(푥,H); complexity of this algorithm? 4 Building a Binary heap incrementally What useful inference can you draw from Top-down this Theorem ? approach The time complexity for inserting a leaf node = ?O (log 풏 ) # leaf nodes = 풏/ퟐ , Theorem: Time complexity of building a binary heap incrementally is O(풏 log 풏). 5 Building a Binary heap incrementally What useful inference can you draw from Top-down this Theorem ? approach The O(풏) time algorithm must take O(1) time for each of the 풏/ퟐ leaves. 6 Building a Binary heap incrementally Top-down approach 7 Think of alternate approach for building a binary heap In any complete 98 binaryDoes treeit suggest, how a manynew nodes approach satisfy to heapbuild propertybinary heap ? ? 14 33 all leaf 37 11 52 32 nodes 41 21 76 85 17 25 88 29 Bottom-up approach 47 75 9 57 23 heap property: “Every ? node stores value smaller than its children” We just need to ensure this property at each node. -

Programmatic Testing of the Standard Template Library Containers
Programmatic Testing of the Standard Template Library Containers y z Jason McDonald Daniel Ho man Paul Stro op er May 11, 1998 Abstract In 1968, McIlroy prop osed a software industry based on reusable comp onents, serv- ing roughly the same role that chips do in the hardware industry. After 30 years, McIlroy's vision is b ecoming a reality. In particular, the C++ Standard Template Library STL is an ANSI standard and is b eing shipp ed with C++ compilers. While considerable attention has b een given to techniques for developing comp onents, little is known ab out testing these comp onents. This pap er describ es an STL conformance test suite currently under development. Test suites for all of the STL containers have b een written, demonstrating the feasi- bility of thorough and highly automated testing of industrial comp onent libraries. We describ e a ordable test suites that provide go o d co de and b oundary value coverage, including the thousands of cases that naturally o ccur from combinations of b oundary values. We showhowtwo simple oracles can provide fully automated output checking for all the containers. We re ne the traditional categories of black-b ox and white-b ox testing to sp eci cation-based, implementation-based and implementation-dep endent testing, and showhow these three categories highlight the key cost/thoroughness trade- o s. 1 Intro duction Our testing fo cuses on container classes |those providing sets, queues, trees, etc.|rather than on graphical user interface classes. Our approach is based on programmatic testing where the number of inputs is typically very large and b oth the input generation and output checking are under program control. -

Functional Data Structures with Isabelle/HOL
Functional Data Structures with Isabelle/HOL Tobias Nipkow Fakultät für Informatik Technische Universität München 2021-6-14 1 Part II Functional Data Structures 2 Chapter 6 Sorting 3 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 4 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 5 sorted :: ( 0a::linorder) list ) bool sorted [] = True sorted (x # ys) = ((8 y2set ys: x ≤ y) ^ sorted ys) 6 Correctness of sorting Specification of sort :: ( 0a::linorder) list ) 0a list: sorted (sort xs) Is that it? How about set (sort xs) = set xs Better: every x occurs as often in sort xs as in xs. More succinctly: mset (sort xs) = mset xs where mset :: 0a list ) 0a multiset 7 What are multisets? Sets with (possibly) repeated elements Some operations: f#g :: 0a multiset add mset :: 0a ) 0a multiset ) 0a multiset + :: 0a multiset ) 0a multiset ) 0a multiset mset :: 0a list ) 0a multiset set mset :: 0a multiset ) 0a set Import HOL−Library:Multiset 8 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 9 HOL/Data_Structures/Sorting.thy Insertion Sort Correctness 10 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 11 Principle: Count function calls For every function f :: τ 1 ) ::: ) τ n ) τ define a timing function Tf :: τ 1 ) ::: ) τ n ) nat: Translation of defining equations: E[[f p1 ::: pn = e]] = (Tf p1 ::: pn = T [[e]] + 1) Translation of expressions: T [[g e1 ::: ek]] = T [[e1]] + ::: + T [[ek]] + Tg e1 ::: ek All other operations (variable access, constants, constructors, primitive operations on bool and numbers) cost 1 time unit 12 Example: @ E[[ [] @ ys = ys ]] = (T@ [] ys = T [[ys]] + 1) = (T@ [] ys = 2) E[[ (x # xs)@ ys = x #(xs @ ys) ]] = (T@ (x # xs) ys = T [[x #(xs @ ys)]] + 1) = (T@ (x # xs) ys = T@ xs ys + 5) T [[x #(xs @ ys)]] = T [[x]] + T [[xs @ ys]] + T# x (xs @ ys) = 1 + (T [[xs]] + T [[ys]] + T@ xs ys) + 1 = 1 + (1 + 1 + T@ xs ys) + 1 13 if and case So far we model a call-by-value semantics Conditionals and case expressions are evaluated lazily. -

Leftist Trees
DEMO : Purchase from www.A-PDF.com to remove the watermark5 Leftist Trees 5.1 Introduction......................................... 5-1 5.2 Height-Biased Leftist Trees ....................... 5-2 Definition • InsertionintoaMaxHBLT• Deletion of Max Element from a Max HBLT • Melding Two Max HBLTs • Initialization • Deletion of Arbitrary Element from a Max HBLT Sartaj Sahni 5.3 Weight-Biased Leftist Trees....................... 5-8 University of Florida Definition • Max WBLT Operations 5.1 Introduction A single-ended priority queue (or simply, a priority queue) is a collection of elements in which each element has a priority. There are two varieties of priority queues—max and min. The primary operations supported by a max (min) priority queue are (a) find the element with maximum (minimum) priority, (b) insert an element, and (c) delete the element whose priority is maximum (minimum). However, many authors consider additional operations such as (d) delete an arbitrary element (assuming we have a pointer to the element), (e) change the priority of an arbitrary element (again assuming we have a pointer to this element), (f) meld two max (min) priority queues (i.e., combine two max (min) priority queues into one), and (g) initialize a priority queue with a nonzero number of elements. Several data structures: e.g., heaps (Chapter 3), leftist trees [2, 5], Fibonacci heaps [7] (Chapter 7), binomial heaps [1] (Chapter 7), skew heaps [11] (Chapter 6), and pairing heaps [6] (Chapter 7) have been proposed for the representation of a priority queue. The different data structures that have been proposed for the representation of a priority queue differ in terms of the performance guarantees they provide. -

CS 270 Algorithms
CS 270 Algorithms Week 10 Oliver Kullmann Binary heaps Sorting Heapification Building a heap 1 Binary heaps HEAP- SORT Priority 2 Heapification queues QUICK- 3 Building a heap SORT Analysing 4 QUICK- HEAP-SORT SORT 5 Priority queues Tutorial 6 QUICK-SORT 7 Analysing QUICK-SORT 8 Tutorial CS 270 General remarks Algorithms Oliver Kullmann Binary heaps Heapification Building a heap We return to sorting, considering HEAP-SORT and HEAP- QUICK-SORT. SORT Priority queues CLRS Reading from for week 7 QUICK- SORT 1 Chapter 6, Sections 6.1 - 6.5. Analysing 2 QUICK- Chapter 7, Sections 7.1, 7.2. SORT Tutorial CS 270 Discover the properties of binary heaps Algorithms Oliver Running example Kullmann Binary heaps Heapification Building a heap HEAP- SORT Priority queues QUICK- SORT Analysing QUICK- SORT Tutorial CS 270 First property: level-completeness Algorithms Oliver Kullmann Binary heaps In week 7 we have seen binary trees: Heapification Building a 1 We said they should be as “balanced” as possible. heap 2 Perfect are the perfect binary trees. HEAP- SORT 3 Now close to perfect come the level-complete binary Priority trees: queues QUICK- 1 We can partition the nodes of a (binary) tree T into levels, SORT according to their distance from the root. Analysing 2 We have levels 0, 1,..., ht(T ). QUICK- k SORT 3 Level k has from 1 to 2 nodes. Tutorial 4 If all levels k except possibly of level ht(T ) are full (have precisely 2k nodes in them), then we call the tree level-complete. CS 270 Examples Algorithms Oliver The binary tree Kullmann 1 ❚ Binary heaps ❥❥❥❥ ❚❚❚❚ ❥❥❥❥ ❚❚❚❚ ❥❥❥❥ ❚❚❚❚ Heapification 2 ❥ 3 ❖ ❄❄ ❖❖ Building a ⑧⑧ ❄ ⑧⑧ ❖❖ heap ⑧⑧ ❄ ⑧⑧ ❖❖❖ 4 5 6 ❄ 7 ❄ HEAP- ⑧ ❄ ⑧ ❄ SORT ⑧⑧ ❄ ⑧⑧ ❄ Priority 10 13 14 15 queues QUICK- is level-complete (level-sizes are 1, 2, 4, 4), while SORT ❥ 1 ❚❚ Analysing ❥❥❥❥ ❚❚❚❚ QUICK- ❥❥❥ ❚❚❚ SORT ❥❥❥ ❚❚❚❚ 2 ❥❥ 3 ♦♦♦ ❄❄ ⑧ Tutorial ♦♦ ❄❄ ⑧⑧ ♦♦♦ ⑧ 4 ❄ 5 ❄ 6 ❄ ⑧⑧ ❄❄ ⑧ ❄ ⑧ ❄ ⑧⑧ ❄ ⑧⑧ ❄ ⑧⑧ ❄ 8 9 10 11 12 13 is not (level-sizes are 1, 2, 3, 6). -

Parallelization of Bulk Operations for STL Dictionaries
Parallelization of Bulk Operations for STL Dictionaries Leonor Frias1?, Johannes Singler2 [email protected], [email protected] 1 Dep. de Llenguatges i Sistemes Inform`atics,Universitat Polit`ecnicade Catalunya 2 Institut f¨urTheoretische Informatik, Universit¨atKarlsruhe Abstract. STL dictionaries like map and set are commonly used in C++ programs. We consider parallelizing two of their bulk operations, namely the construction from many elements, and the insertion of many elements at a time. Practical algorithms are proposed for these tasks. The implementation is completely generic and engineered to provide best performance for the variety of possible input characteristics. It features transparent integration into the STL. This can make programs profit in an easy way from multi-core processing power. The performance mea- surements show the practical usefulness on real-world multi-core ma- chines with up to eight cores. 1 Introduction Multi-core processors bring parallel computing power to the customer at virtu- ally no cost. Where automatic parallelization fails and OpenMP loop paralleliza- tion primitives are not strong enough, parallelized algorithms from a library are a sensible choice. Our group pursues this goal with the Multi-Core Standard Template Library [6], a parallel implementation of the C++ STL. To allow best benefit from the parallel computing power, as many operations as possible need to be parallelized. Sequential parts could otherwise severely limit the achievable speedup, according to Amdahl’s law. Thus, it may be profitable to parallelize an operation even if the speedup is considerably less than the number of threads. The STL contains four kinds of generic dictionary types, namely set, map, multiset, and multimap.