Empirical Comparison of Scons and GNU Make
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Empirical Comparison of Scons and GNU Make
Großer Beleg Empirical Comparison of SCons and GNU Make Ludwig Hähne August 21, 2008 Technical University Dresden Department of Computer Science Institute for System Architecture Chair for Operating Systems Professor: Prof. Dr. rer. nat. Hermann Härtig Tutor: Dipl.-Inf. Norman Feske Dipl.-Inf. Christian Helmuth Erklärung Hiermit erkläre ich, dass ich diese Arbeit selbstständig erstellt und keine anderen als die angegebenen Hilfsmittel benutzt habe. Dresden, den 26. Juni 2008 Ludwig Hähne Abstract Build systems are an integral part of every software developer’s tool kit. Next to the well-known Make build system, numerous alternative solutions emerged during the last decade. Even though the new systems introduced superior concepts like content signa- tures and promise to provide better build accuracy, Make is still the de facto standard. This paper examines GNU Make and SCons as representatives of two conceptually distinct approaches to conduct software builds. General build-system concepts and their respective realizations are discussed. The performance and scalability are empirically evaluated by confronting the two competitors with comparable real and synthetic build tasks. V Contents 1 Introduction 1 2 Background 3 2.1 Design Goals . .3 2.1.1 Convenience . .3 2.1.2 Correctness . .3 2.1.3 Performance . .3 2.1.4 Scalability . .4 2.2 Software Rebuilding . .4 2.2.1 Dependency analysis . .4 2.2.1.1 File signatures . .4 2.2.1.2 Fine grained dependencies . .5 2.2.1.3 Dependency declaration . .5 2.2.1.4 Dependency types . .5 2.2.2 Build infrastructure . .6 2.2.3 Command scheduling . .6 2.3 Build System Features . -

Release 0.11 Todd Gamblin
Spack Documentation Release 0.11 Todd Gamblin Feb 07, 2018 Basics 1 Feature Overview 3 1.1 Simple package installation.......................................3 1.2 Custom versions & configurations....................................3 1.3 Customize dependencies.........................................4 1.4 Non-destructive installs.........................................4 1.5 Packages can peacefully coexist.....................................4 1.6 Creating packages is easy........................................4 2 Getting Started 7 2.1 Prerequisites...............................................7 2.2 Installation................................................7 2.3 Compiler configuration..........................................9 2.4 Vendor-Specific Compiler Configuration................................ 13 2.5 System Packages............................................. 16 2.6 Utilities Configuration.......................................... 18 2.7 GPG Signing............................................... 20 2.8 Spack on Cray.............................................. 21 3 Basic Usage 25 3.1 Listing available packages........................................ 25 3.2 Installing and uninstalling........................................ 42 3.3 Seeing installed packages........................................ 44 3.4 Specs & dependencies.......................................... 46 3.5 Virtual dependencies........................................... 50 3.6 Extensions & Python support...................................... 53 3.7 Filesystem requirements........................................ -
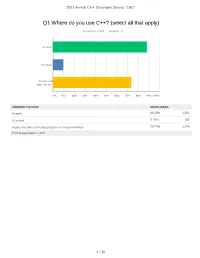
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Increasing Developer Productivity by Improving Build Performance and Automating Logging Code Injection
A Dissertation for the Degree of Ph.D. in Engineering Increasing Developer Productivity by Improving Build Performance and Automating Logging Code Injection February 2021 Graduate School of Science and Technology Keio University Takafumi Kubota Acknowledgment I would like to thank my advisor, Prof. Kenji Kono. His constant guidance helped me in all the time of research. I would like to express my sincere gratitude to Ph.D. Takeshi Yoshimura, Ph.D. Yusuke Suzuki, and Naohiro Aota for their in- valuable insight. This dissertation would not have been possible without their advice and encouragement. I am grateful to the members of my thesis committee as well: Prof. Shingo Takada, Prof. Motomichi Toyama, and Prof. Hideya Iwasaki. This dissertation was greatly improved by their valuable feedback. I am also thankful to my colleagues in the sslab. Their surprising enthusiasm and skills have always inspired me. I appreciate the nancial supports from the Core Research for Evolutional Science and Technology of Japan Science and Technology Agency and scholar- ships of our university. Finally, I thank my family, my parents, and sister for their support all these years. Without their support and encouragement, many accomplishments in my life including this dissertation would not have been possible. 2 Abstract As software is growing in size and complexity, it is critical to develop software eciently and reliably. For example, Continuous Integration (CI) has become a de-facto practice of the daily development in large software projects, in which builds and tests are automated, resulting in numerous developers’ modications are eciently integrated in a mainline. However, as an obstacle for improving development eciency, software en- gineers spend lots of time outside of the actual development of the software.