Proceedings of the 55Th Annual Meeting of the Association for Computational Linguistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Women in Science 2016-2017.Pdf (8.365Mb)
:,r,',lli'T1'f'..,�';r> ;.. :'I'll,"! -,.. n:,1 ...'-:I, ✓ "' ,.- '" Women 1n Science 2016-2017 Vol. XIII � Yeshiva University �-}�� _,+'� STERN COLLEGE FOR WOMEN Table of Contents Acknowledgments......................................................... ............4 Introductory Remarks....................................... .......................... 5 Department of Biology .............................................................. 13 Department of Chemistry and Biochemistry ..................................... 21 Department of Physics ............................................................... 24 Department of Psychology......................................................... 33 Department of Speech Pathology & Audiology ................................. 37 Combined Programs........................................................ .........39 The Anne Scheiber Fellowship Program...................................... ....42 Students' Accomplishments..................................................... ...44 Students' Publications and Presentations .........................................48 Derech Ha Teva, A Journal of Torah and Science ...............................80 Abstract Booklet of Student Research...................... .......................92 Student Co-editors Sara Shkedy Rachel Somorov 2 women in science stern college for women 3 Acknowledgments Introductory Remarks The Departments of Biology, Chemistry/Biochemistry, Physics, Psychology, and Speech Pathology/ Audiology share a proactive approach in promoting We -

237 9.7 AFTERWORD How Are Emotions Embodied in the Social
OUP UNCORRECTED PROOF – FIRSTPROOFS, Wed Apr 18 2018, NEWGEN 2 37 Afterword237 reactions, albeit not on a conceptual level (Condon even flourish in the face of the consequences of & Feldman Barrett, 2013). This suggests that this caring. accessing the positive core of compassion might require some degree of conditioning and training CONCLUSION in order to successfully employ it in daily life. Social emotions such as empathy and com- Several research groups have begun passion are a central aspect of our social lives. investigating how compassion can be trained Through the shared embodiment of emotional through the utilization of meditation techniques states such as in the phenomena of emotion adapted from the Buddhist tradition to a secular contagion and empathy, we gain access to and setting in meditation- naïve participants (e.g., communicate core aspects of our emotional Fredrickson, Cohn, Coffey, Pek, & Finkel, 2008; experiences. However, many barriers exist to this Jazaieri et al., 2013; Klimecki et al., 2013; Klimecki, empathic resonance, including other core social Leiberg, Ricard, & Singer, 2014; Mascaro, Rilling, mechanisms such as our tendency to discrimi- Negi, & Raison, 2013; Weng et al., 2013). In nate in- groups from out- groups. Even when we addition to showing that compassion training is do achieve empathic connection with someone, possible outside of the strict regimes of Buddhist this can become a source of stress, because, un- practice, these results show that such training deniably, sharing affective states with others can has a number of beneficial effects. For instance, be costly. However, as we hope to have shown, in our laboratory, we have found that compas- we are not incurably bound by our biases, but sion training increased positive affect when can actively modulate the occurrence, strength, participants were exposed to highly distressing and type of empathic connection we share with videos depicting people suffering, and that this others. -

Notices of the American Mathematical Society Is in Federal Support of Science and Published Monthly Except Bimonthly in May, June, Technology
OF THE AMERICAN SOCIETY Young Scientists' Network Advocacy and an Electronic Newsletter Ease New Doctorates' Job Search Woes page 462 DeKalb Meeting (M?Y 20-23) page 481 MAY/JUNE 1993, VOLUME 40, NUMBER 5 Providence, Rhode Island, USA ISSN 0002-9920 Calendar of AMS Meetings and Conferences This calendar lists all meetings and conferences approved prior to the date this issue should be submitted on special forms which are available in many departments of went to press. The summer and annual meetings are joint meetings of the Mathematical mathematics and from the headquarters office of the Society. Abstracts of papers to Association of America and the American Mathematical Society. Abstracts of papers be presented at the meeting must be received at the headquarters of the Society in presented at a meeting of the Society are published in the journal Abstracts of papers Providence, Rhode Island, on or before the deadline given below for the meeting. Note presented to the American Mathematical Society in the issue corresponding to that of that the deadline for abstracts for consideration for presentation at special sessions is the Notices which contains the program of the meeting, insofar as is possible. Abstracts usually three weeks earlier than that specified below. Meetings ······R ••••*••asl¥1+1~ 11-1-m••• Abstract Program Meeting# Date Place Deadline Issue 882 t May 2G-23, 1993 DeKalb, Illinois Expired May-June 883 t August 15-19, 1993 (96th Summer Meeting) Vancouver, British Columbia May 18 July-August (Joint Meeting with the Canadian -

Physcian Directory Coney Island Health Professional by License And
NYC Health + Hospitals Physcian Directory Corporate Finance Coney Island Updated as of March 25, 2016 Health Professional By License and NPI FACILITY NAME DOCTOR LAST NAME DOCTOR FIRST NAME Coney Island AANONSEN DEBORAH Coney Island AARON ROBERT Coney Island ABAYEV ZURAB Coney Island ABBERBOCK GARY Coney Island ABBOUD AIMAN Coney Island ABDELSHAFYABDEL NULL Coney Island ABDELSHAFYIBRAHM NULL Coney Island ABDUL WAHID Coney Island ABDULLAH MUHAMMAD Coney Island ABEDIN RASHED Coney Island ABI FADEL Coney Island ABRAHAM SASHA Coney Island ABRAHAMS MICHAEL Coney Island Abraitis Stephanie Coney Island ABRAMOV ALEXANDR Coney Island ABRAMOV MICHAEL Coney Island ABRAMOVA INNA Coney Island ABRAMOVICH GALINA Coney Island ABRAMSON ALLA Coney Island ABRASS ANDREW Coney Island ABUELENIN DANIEL Coney Island ACHARYA NIKHIL Coney Island ACOSTA MICHELLE Coney Island ADAMS FRANCIS Coney Island ADAMS LAUREN Coney Island ADANIEL TINDALO Page 1 of 136 NYC Health + Hospitals Physcian Directory Corporate Finance Coney Island Updated as of March 25, 2016 Health Professional By License and NPI FACILITY NAME DOCTOR LAST NAME DOCTOR FIRST NAME Coney Island ADDEO JOSEPH Coney Island ADDEPALLI RAJ Coney Island ADEDEJI ADEDAYO Coney Island ADEISHVILI GRIGOL Coney Island ADEYEMI BABATUNDE Coney Island ADIMOOLAM SEETHARAMAN Coney Island ADLER MAYER Coney Island ADLER ROBERT Coney Island ADZIMAH JOSEPH Coney Island AFROZE SALMA Coney Island AFSHARI MICHAEL Coney Island AGABEKIAN TATIANA Coney Island AGARONOV VITALIY Coney Island AGARWAL SHEENU Coney Island AGAYEVA KAMILA -
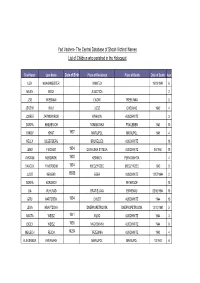
The Central Database of Shoah Victims' Names List of Children Who
Yad Vashem- The Central Database of Shoah Victims' Names List of Children who perished in the Holocaust First Name Last Name Date of Birth Place of Residence Place of Death Date of Death Age LIZA KHAKHMEISTER VINNITZA 19/09/1941 6 MILEN BECK SUBOTICA 2 JZIO WIESMAN LWOW TREBLINKA 8 JERZYK WILK LODZ CHELMNO 1942 4 JOSELE ZARNOWIECKI KRAKOW AUSCHWITZ 3 SONYA KHILKEVICH ROMANOVKA FRAILEBEN 1941 10 YAKOV KHAIT 1937 MARIUPOL MARIUPOL 1941 4 NELLY SILBERBERG BRUXELLES AUSCHWITZ 10 JENO FISCHER 1934 DUNAJSKA STREDA AUSCHWITZ 06/1944 10 AVRAAM NERDINSKI 1938 KISHINEV PERVOMAYSK 4 YAACOV YAVERBOIM 1934 MIEDZYRZEC MIEDZYRZEC 1942 9 JUDIT KEMENY 15555 EGER AUSCHWITZ 12/07/1944 2 SONYA KOROBOV PETERGOF 10 LIA MUHLRAD BRATISLAVA BIRKENAU 05/10/1944 10 GITU HARTSTEIN 1934 CHUST AUSCHWITZ 1944 10 LENA KRAVTZOVA DNEPROPETROVSK DNEPROPETROVSK 13/10/1941 5 AGOTA WEISZ 1941 IKLOD AUSCHWITZ 1944 3 IBOLY WEISZ 1936 NAGYBANYA AUSCHWITZ 1944 8 MEILECH REICH 14254 TRZEBINIA AUSCHWITZ 1943 4 ALEKSANDR AVERBAKH MARIUPOL MARIUPOL 10/1941 6 Yad Vashem- The Central Database of Shoah Victims' Names List of Children who perished in the Holocaust First Name Last Name Date of Birth Place of Residence Place of Death Date of Death Age SALOMON LOTERSPIL 1941 LUBLIN LUBLIN 2 MISHA GORLACHOV 1932 RYASNA RYASNA 1941 9 YEVGENI PUPKIN NOVY OSKOL NOVY OSKOL 4 REVEKKA KRUK 1934 ODESSA ODESSA 1941 7 VOVA ZAYONCHIK 1936 KIEV BABI YAR 29/09/1941 5 MAYA LABOVSKAYA 1931 KIYEV BABI YAR 1941 10 MILOS PLATOVSKY 1932 PROBULOW 1942 10 VILIAM HOENIG 15/12/1939 TREBISOV SACHSENHAUSEN 12/11/1944 -
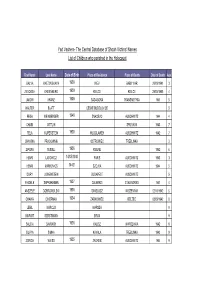
The Central Database of Shoah Victims' Names List of Children Who Perished in the Holocaust
Yad Vashem- The Central Database of Shoah Victims' Names List of Children who perished in the Holocaust First Name Last Name Date of Birth Place of Residence Place of Death Date of Death Age GALYA KATZOVSKAYA 1938 KIEV BABIY YAR 29/09/1941 3 ZEVOOSH GREENBERG 1939 KIELCE KIELCE 29/05/1943 4 JAKOW KRANZ 1936 SADAGORA TRANSNISTRIA 1941 5 WALTER BLATT CESKE BUDEJOVICE 5 FEGA WEINBERGER 1940 ZNACEVO AUSCHWITZ 1944 4 CHAIM GITTLIN SPILYAVA 1943 7 FELA KUPERSTEIN 1935 WLOCLAWEK AUSCHWITZ 1942 7 CHANINA PRACOWNIK OSTROWIEC TREBLINKA 3 ZIPORA TESSEL 1936 RIBENE 1942 6 HENRI LATOWICZ 14/05/1940 PARIS AUSCHWITZ 1943 3 HENRI MARKOVICS 14461 SZOJVA AUSCHWITZ 1944 5 DURY LOWENSTEIN BUDAPEST AUSCHWITZ 5 FEIGELE SHPRAKHMAN 1937 CALARASI STALINGRAD 1941 4 ANSZELE DOBROWOLSKI 1936 SWISLOCZ WISZEWNIK 02/11/1942 6 CHAWA CIMERMAN 1934 ZARNOWIEC BELZEC 08/09/1942 8 LEIBL MARCUS WARSZA 9 MARGIT GERSTMANN BRUX 9 SALCIA BAJRACH 1936 KALISZ WARSZAWA 1942 6 SILVYA SIMHA KAVALA TREBLINKA 1943 9 ZORICA WEISS 1935 ZAGREB AUSCHWITZ 1944 9 Yad Vashem- The Central Database of Shoah Victims' Names List of Children who perished in the Holocaust First Name Last Name Date of Birth Place of Residence Place of Death Date of Death Age LUCIEN KAPLANSKY 1935 PARIS AUSCHWITZ 1943 8 MARGIT HOLD 1937 KISMAJTENY AUSCHWITZ 1944 7 SAINDEL IAGER AUSCHWITZ 4 TAMAS GROSZ 1943 AUSCHWITZ 1944 1 LASZLO GROSS 1934 AUSCHWITZ 1944 10 JEHUDA KAHAN VISEU AUSCHWITZ 9 BLIME WIEDER 1939 TURNA NAD BODVOU AUSCHWITZ 1944 5 FAJGLA ROSENZWEIG 12420 SOSNOWIEC AUSCHWITZ 1942 8 FRIMET OPACZYNSKI 1937 KRAKOW -

WIS 15-16 Vol 12 with Color Cover.Pdf
Women in Science 2015–2016 Vol. XII Yeshiva University STERN COLLEGE FOR WOMEN 2 women in science Table of Contents Acknowledgments…………………………………………………………...4 Introductory Remarks………………………………………………………..5 Department of Biology……………………………………………………..12 Department of Chemistry and Biochemistry……………………………….20 Department of Physics……………………………………………………...24 Department of Psychology…………………………………………………26 Department of Speech Pathology & Audiology……………………………30 Combined Programs………………………………………………………..32 The Anne Scheiber Fellowship Program…………………………………...35 Students’ Accomplishments………………………………………………..37 Students’ Publications and Presentations…………………………………..41 Derech HaTeva, A Journal of Torah and Science………………………….72 Abstract Booklet of Student Research……………………………………...83 Student Co-editors Talia Bean and Yael Steinberg stern college for women 3 Acknowledgments We would like to thank the many people involved in Women in Science: Dr. Harvey Babich, Dept. Chair of Biology at Stern College for Women, for inspiring the creation of this publication. Dean Karen Bacon, the Dr. Monique C. Katz Dean of Undergraduate Arts and Sciences, for her support of the many programs and opportunities described herein that continue to empower Stern women in their pursuit of the sciences. The student authors included in the Abstract Booklet of Student Research for their dedication to science research. Ms. Meirah Shedlo, Academic Coordinator, for the layout of the publication. The publishing company, Advanced Copy Center, Brooklyn, NY for production of a quality journal. Mr. Shmuel Ormianer, Project Manager, for the cover design of this publication. 4 women in science Introductory Remarks The Departments of Biology, Chemistry/Biochemistry, Physics, Psychology, and Speech Pathology/Audiology each unique in its specific discipline, share a proactive approach in promoting the academic success of students at Stern College for Women (SCW) and in helping them achieve their career goals.